2024-9-6 09:7:34 Author: hackernoon.com(查看原文) 阅读量:2 收藏
The multiple systems are built with billions of processes running into them. Software developers write tons of code every day, pack it into releases, and deploy it to production.
It would be awesome if everything you code would work every day, every minute without any troubles. But it doesn’t.
Let’s go through the different kinds of errors and different approaches and try to find the optimal way how to handle errors properly.
The Context
Before diving deep into the problem, let’s see what “error” even could mean in software development practice.
In our experience, we could say:
- It’s exceptional behavior! Something went wrong, and your code failed with an exception. I bet it's because someone passed invalid arguments to this method.
- Hey, external API wasn’t available when we sent the HTTP request. That’s why the feature didn’t work.
- It’s some data users typed in a form but they do not meet your business requirements.
- Someone made a typo in the code and the program crashed even before it started.
- Some code was deployed but consumed too much memory, so the Out-Of-Memory killer just shut it down repeatedly.
I believe you met some of these concerns in your daily work, and I bet you can make this list much longer.
As we face many different situations in the code, in the running application, and in the interaction between systems, we can try to identify and describe them.
When It’s Time to Panic
As a developer, you pretty much know what it is. Some running code fails with exceptions (mostly a specific instance of Exception Class) with some extra details such as exception class name, message (sometimes not descriptive enough), and stack trace.
When you see in the code things like: throw new Error('Parameter is not a number!'); rise ArgumentError, “variable can’t is below zero” and then somewhere in the code, you see try, catch, finally or rescue, ensure constructions meaning that the developer is aware of possible exceptions and handles them.
Alternatively, Go language doesn't have classical exceptions that we used to work with. Instead, It has panic construction, but it would be wrong to use panic every time we meet some errors. The word panic itself means something bad, an inappropriate situation that can't even be resolved now. And the word exception may even be close to it. The recover operator can be used to recover from the panic, but not in all cases.
Exceptions it’s a kind of error, that happens in application runtime. It may or may not be related to an exclusive situation that led to error. I like to think about exceptions like: it's something, that should not happen. If it happens, well, it's better to let the rest world know about this.
The “rest world” can be a file log, or a remote error tracking system like Sentry, DataDog, Airbrake, or even your Slack channel.
Then the thing is “it should not happen.” On a daily basis.
Let’s imagine we have a simple feature contact form that you may face on every website. The user wants to reach out to an organization, so he fills in the contact form and presses the "Submit" button.
A moment later, he saw a something went wrong a message like that:

In the Ruby on Rails application, it would mean that a <Exception> has been raised and not handled properly (HTTP status is 500). The user is not able to see the response from the contact form or even the website. Well, if it would be a payment form when he was going to pay a couple of thousand bucks, this kind of response could mean Panic for him. Especially when the user gets an SMS that money has been transferred already.
But why could it happen?
Unfortunately, there can be a million reasons: the database is unstable, the email server or even some production deployment could happen at the moment. Well, usually 500 error code, means that something really bad happened and it really could be a “panic.”
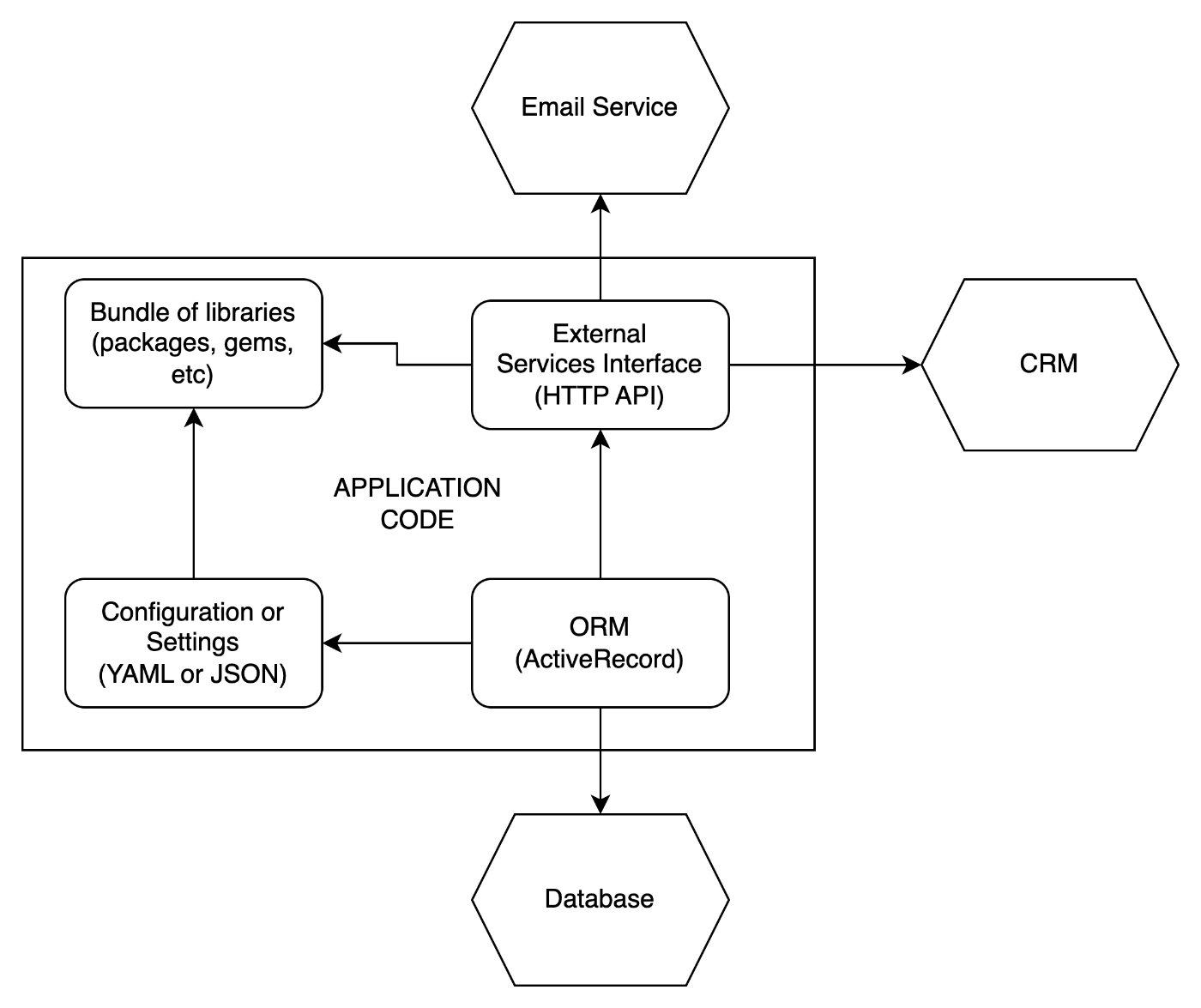
Now, let’s see what we have in the application inside. Let’s split this into layers:

It’s a pretty simple monolithic application or website, that you may work on:
- Relational database, like Postgresql that you interact with using ActiveRecord
- Some packages (e.g., ruby gems) that you plugged into the project.
- Some classes and libraries that communicate with external systems by API (e.g., HTTP REST API)
- Configuration layer that reads needed settings and credentials when your server starts.
The regular application may be much more complex, but even here, we can have a lot of things that “could go wrong.”
Let’s imagine a few different use cases that could lead to this 500 error when a user submits the form.
- An external CRM system is not available. The client code works with JSON, but when we send a request to create a new contact in CRM, it returns a 502 from Nginx. Our classes used to work with JSON and called
JSON.parse(response.body), but as the response was from CRM nginx, not the regular API JSON from the web server, it raised the exceptionJSON::ParserErrorthat we didn’t handle. - Some external gem (library) wasn’t configured properly. E.g., when we initialized the library, we didn’t pass the valid argument because it was missing in
settings.yamlfile. - Client’s data validation error: e.g., the user sends some wrong data instead of the email field. It even maybe a piece of SQL to check if there is an SQL injection. The service didn’t expect that and passed the value to PG which broke the syntax construction of the query. Or, the many other reasons: wrong data type for the
phonefield: the database configured and expected to store integer value, but it was a string with meta symbols. Wrong validation or type casting led to the exception.
Of course, when the user gets this kind of error, it’s a really bad, exceptional situation. That’s why it was raised as an exception internally.
But the problem is, that we as developers, can catch and handle most of the exceptional situations. We should think about two things:
Don't write code that may break the user's (customers) journey if it's possible
If you’re writing some application code that different users will use, think twice about using exceptions. Think about working with exceptions like if it means the <panic>, the end of the world for your application or part of it.
The second:
Even if an error happens the user should clearly understand why it happens and be able to interact with the application.
In the image above, the user sees that the application crashed on his request. The only choice he has is to go back to the previous page or try to restart the page (that may lead to the same error).
Ideally, when you work on features that can be exposed to your application customer, keep in mind to display errors correctly. Handle the exceptional situations, display them in readable mode, and try to not break the UI and UX.
The third principle:
If an unhandled exception has happened - you should be aware of it.
Gather all information about exceptions: name of exception, description, stack trace. Better if you were aware of it as soon as possible to decide if it should be fixed right now. You can catch it on a few levels:
- Write exception output to log file or external log storage like ELK. Most modern application frameworks do it automatically for you. Unfortunately, if you don’t read the log file all the time, or don’t sample/parse it regularly during minutes, you can’t catch it.
- Use the error tracker. Usually, it’s an external system, that injects some code (using an external library or package) into your application and catches all exceptions sending all related information to it over the network. Most of them are not free and can be expensive, but you can check open-source alternatives.
- Set up alerts. HTTP 404 is not a critical error, but if your user got HTTP 500 - it mostly means something bad happened and often it means you have to fix it immediately.
To assume that I would say: Let exceptions be exceptional, don’t use them too much.
When to Use Exceptions?
The good time to use exceptions - when you write the code that will be used by other software developers. I mean when you work on library code. Packages, libraries, etc. When your code should be embedded in another code, properly used and configured, the exceptions can be a good choice. However, you need to think about next:
- Gather exceptions in one place. It’s good to have a generic class or file that has a list of all exceptions with descriptions and comments. The developer that uses your library can easily read and navigate through it.
- Your exceptions must say that the way how the software developer uses your library is wrong. E.g. your library code is badly configured and may have a type mismatch or something else. It’s not a problem to throw an exception if you expect to always have a function parameter, but didn’t get it - your code can’t work without this parameter, it’s nonsense! It’s an exceptional situation!
In dynamically typed languages like Ruby or Javascript, almost all errors and exceptions we have happen during application runtime. That’s why your library code must be strict. If a variable expects a String value, but a developer passed Integer let him know about that. A good developer should understand how your library works. If you write good documentation and define a list of needed <parameters>, <variables>, and <types> for your library, then the developer easily can use your code.
Handle Form Errors
Let’s go back to the example before - the user filled out a contact form and pressed the submit button. The application handles the user’s input data, parses it, validates it, and tries to store it in the database. Then it may send an email to the website owner, call some API from the CRM system, and do a lot of things.
Because the application receives the user’s data, the data itself may meet or not meet the system's expectations. Usually, the application validates the user’s input and if some data is wrong we let the user know.
Let's say, the contact form has 3 fields: full name, email, and phone. Your validation code expects the following:
- all 3 fields must be filled
- email field must have valid the <email> form (pass the regex validation)
- phone should be correct, and have a country code. The size is not more than 15 chars.
- full name can’t be less than 3 symbols. and not more than 255.
A lot of rules, you say. I agree, but let's say the business and software developers will find the balance between effectiveness and user experience later.
Let’s answer the architectural question: how to handle the wrong user’s input? Should we use exceptions? should we use something else?
I think, the software industry answered this question many years ago:
- The developer should use a FormObject or at least a Model-level validator. Using the external “Contract” instance with the fields, types, and validation rules is even better.
- The validator must run all validator cases through all input fields and gather all errors in one place.
- All errors should be properly rendered to the user, so he can read them carefully and fix them.
All this makes the validation errors quite complex. Each field can have multiple validation rules, and fail some or even all of them.
Also, you can have a validation chain: some validation code can be executed only if the previous validator passed.
For instance, if the user didn’t fill in the full_name field, we can have a choice:
- Just return an error for the
full_namea field like "Please write out your full and last name". - Display a collection of errors:
-
"Please write out your full and last name"
-
“Your full name must be more than 3 symbols”
-
As a user, I’d prefer to see all informative error messages, so I can fix them all next time.
So, why can’t we use exceptions here? Let’s see:
def create_contact(params)
raise ArgumentError, 'full_name must be filled' if params[:full_name].blank?
raise ArgumentError, 'full_name must be more than 3 symbols' if params[:full_name].size <= 3
raise ArgumentError, 'email must be filled' if params[:email].blank?
# Some additional validations for email and password
raise ArgumentError, 'email must be filled' if params[:phone].blank?
Contact.create!(params)
end
The first exception will break the “validation chain” and return the error to the user. So, you won’t be able to gather the rest errors and display all of them. If the user sends all 3 empty fields, he gets only an error regarding full_name. Then new errors will come after the next submits.
That’s why is important to check form parameters for all possible errors once.
In MVC frameworks like Rails, we have some options:
- Model-layer validator:
ActiveRecord/ActiveModelvalidations - standard approach. - Create a separate
FormObjectusing external gems/libraries, such asreform,yaaf, or write yourFormclasses based onActiveModel - Use Schema/Contract objects to explicitly validate incoming parameters, such as
dry-validate,dry-schema, etc.
The problem with all the solutions above is how to gather these validation errors and send them to the client.
Let’s take a look at the interface of the returned value (ActiveModel style):
contact.errors.messages
# => {:full_name=>["can't be blank"]}
contact.errors.full_messages
# => ["Full name can't be blank"]
Probably the most popular format for Rails apps, even if you plugged in reform or something else, they may have the same format (to make the transition and refactoring easier).
For dry-validation, it would be different. You describe the contract class and then you pass parameters to its instance. The result is Dry::Validation::Result an instance. It's not a classical Dry Monad instance, but it has a similar interface method, such as success? or failure?.
The error format is a bit different:
class NewContactContact < Dry::Validation::Contract
params do
required(:email).value(:string)
#...
end
rule(:email) do
key.failure(text: 'must have valid format', code: 'contact.invalid_email') if values[:email] !=~ URI::MailTo::EMAIL_REGEXP
end
end
contract = NewContactContact.new
result = contract.call(email: 'foobarz.1')
result.success? # => false
result.failure? # => true
result.errors.to_h
# => {:age=>[{:text=>"must have valid format", :code=>'contact.errors.invalid_email'}]}
Imagine, that you started your project with ActiveModel validations in your models, then started using something else, and finally decided to start using dry-validation. Some of your API endpoints get responses in one format, and some in another. Handling all of it becomes a difficult routine.
Dealing With Complexity
I would suggest to define an output format for errors. An object, that will be a single source of truth for different kinds of errors, no matter what you use.
I prefer an error interface like this:
// error object
{
code: '<resource>.<error>', //unique error code. It can be used on the frontend to implement own localization
message: 'Contact form has invalid field', //human readable general message.
errors: [
{ field: 'email', errors: ['must have valid format'] },
{ field: 'full_name', messages: ['can not be less than 3 symbols'] }
] //can be optional
}
The problem is that nested fields don’t have specific error `codes` for the clients to handle their localization. E.g., your backend only cares about the `en` locale, and your React teammates implement their own locales. So, you can have an independent backend architecture and data formats.
It can have the following format:
{
code: 'contact_form.create.invalid', // <resource>.<action>.<error> unique error code. It can be used on the frontend to implement own localization
message: 'Contact form has invalid field', //human readable general message.
errors: [
{
field: 'email',
errors: [
{ code: 'contact_form.create.email.format', message: 'must have valid format' },
{ code: 'contact_form.create.email.size', message: 'must not be longer than 255 symbols' }
]
},
{
field: 'full_name',
messages: [
{ code: 'contact_form.create.full_name.presence', message: 'can not be blank' }
]
}
]
}
Or you can use the same format, that we saw in Dry::Validation::Result. It doesn’t matter. What matters is how you handle it in different places in your code base.
Handing Errors in the Business Logic Using Monads
Usually, Ruby developers place the business logic code to PORO (Plain-Old-Ruby-Object), which could mean any OOP pattern inside. Service, Adapter, Factory, Use Case, whatever.
Your class can do some work and may have a different result. It can have its own internal validation for input parameters; it can handle some exceptions internally. What is more important: how to unify the result?
Let’s have a class that can send notifications to a user. The input value is a user ID, and you used to call it in your controller.
notification = SendNotification.new
result = notification.call(user_id: params[:user_id])
What the result do we expect?
result == true #=> if notification was sent
result == false #=> if notification wasn't sent. Why? probably should be `notification.errors` then?
result == nil ...what does it mean? Maybe was an exception and someone handled it and just returned nil...
result == 401 #=> int value with error code, because User wasn't found
The problem is that often, we don’t know what the result can be. If it’s boolean and false, then we should expect an errors or something similar that would explain to us what happened.
The worst thing could happen if we returned nil, because of some guard functions, or failed exceptions, like this:
class SendNotification
def call(user_id:)
return if user_id.blank?
# ... do some logic here
rescue StandardError => e
Rails.logger.error(e)
nil
end
end
From my experience, in dynamic languages is better to keep the same output format. If you call a class that does some business transactions, validations, API requests, or other service jobs, it’s better to have a determined result. Always.
In Elixir (or Erlang), the standard way of result, when it’s wrapped into a Tuple data type and we can use patter-matching, like this:
case result do
{:ok, data} ->
data
{:error, :user_not_found} = error ->
handle_error(error)
end
Functional languages have monads. Rust has a similar structure to a monad, called Result.
Ruby has a quite rich list of gems dry-rb that also includes monads.
result = Dry::Monads::Result::Success.new(user_id: 1)
# => result.success?
# => result.success[:user_id]
result = Dry::Monads::Result::Failure.new(code: 'send_notification.user_id.blank', message: 'User not found')
# => result.failure?
# => result.failure[:code]
# => result.failure[:message]
Since ruby 2.7 you also can easily combine this with pattern matching:
case result
in Success(_)
true
in Failure(code: 'send_notification.user_id.blank')
puts result.failure[:message]
in Failure(code: 'send_notification.aws_sns.invalid_credentials')
raise ExternalError, result.failure[:message]
end
As you can see, it’s much more flexible and at the same time informative.
The simple if/else approach also works:
class NotificationsController < ApplicationController
def create
notification = SendNotification.new
result = notification.call(user_id: params[:user_id])
if result.success?
render json: {success: true}
else
render json: # some errors here...
end
end
end
Unified Error Format
Ok, now we have Success/Failure returned values, some structure, some collection of errors from validators, and maybe some result of exception handling. Still a lot of different things that may look different.
Then, we should use an abstract errors collector interface, that can store the failed result and serialize it to the needed format as JSON.
error = GenericError.new(
code: ...,
message: ...,
errors: [...]
).result
error.class #=> Dry::Monads::Result::Failure
error.failure[:code]
error.failure[:message]
error.failure[:errors]
Let’s see an implementation example:
class GenericError
include Dry::Monads[:result]
class NestedError
attr_reader :code, :field, :message
def initialize(field:, code:, message:)
@code = code
@field = field
@message = message
end
def to_h
{
field: field,
code: code,
message: message
}
end
end
attr_reader :code, :message, :errors
def initialize(code:, message:, errors: nil)
@code = code;
@message = message
@errors = []
merge(errors:) if errors.present?
end
def add(field:, code:, message:)
@errors.push(NestedError.new(code:, field:, message:))
end
def result
Failure(
code:,
message:,
errors: errors.map(&:to_h)
)
end
def merge(errors:)
return [] if errors.blank?
case errors
in ActiveModel::Errors
merge_active_model_errors(errors:)
in Dry::Validation::MessageSet
merge_dry_validation_errors(errors:)
end
end
def to_h
{
code:,
message:,
errors: errors.map(&:to_h)
}
end
private
def merge_active_model_errors(errors:)
errors.each do |error|
field = error.attribute
code = "#{field}.#{error.type}"
message = error.message
add(field:, code:, message:)
end
end
def merge_dry_validation_errors(errors:)
errors.each do |error|
field = error.path&.first
code = error.meta[:code] || "#{field}.invalid"
message = error.text
add(field:, code:, message:)
end
end
end
The idea of GenericError class is being used in all places and contexts in the code base.
The current implementation is pretty simple, just to show you an example and what the profit is. It has a local array of errors (@errors instance variable). It supports some strategies to handle complex error objects such as ActiveModel, and dry-validation. You can implement any strategies that you want actually, to handle errors from Reform, Trailblazer, and other libraries. But keep in mind that the Generic class should be simple, so it’s good to extract strategies into separate classes.
Here is an example of usage:
# Just on ActiveModel
customer = Customer.new(...)
customer.valid? # => false
err = GenericError.new(code: 'models.customer.invalid', message: 'Unable to save Customer due to errors', errors: customer.errors)
# you can use #result method to get the Failure monad:
err.result # => Failure({:code=>"models.customer.invalid", :message=>"Unable to save Customer due to errors", :errors=>[{:field=>:email, :code=>"email.blank", :message=>"must exist"}, {:field=>:full_name, :code=>"full_name.blank", :message=>"must exist"}, {:field=>:price, :code=>"price.blank", :message=>"can't be blank"}]})
The main advantage can be reached in the complex classes, such as ServiceObject, UseCase, etc.
- Instantiate GenericError with general information with code: and message: params
- When you use contract validation (e.g.,
dry-validation) and the contract is not valid, you can passerrors:argument - Then you save your ActiveRecord object and handle AR validation errors. If the record is not valid - you can use
#mergemethod and pass AR errors directlyerr.merge(errors: record.errors - As a result, your
err.resultwill catch errors on each level: dry-validation, ActiveRecord, or whatever you implemented.
This approach may look complex for small projects, but in my experience, in large and complex enterprise systems, it’s quite important to have guidelines and code practices for error handling.
如有侵权请联系:admin#unsafe.sh