大规模扫描: 向250万个主机发送5亿次HTTP请求
我的使用场景是道德黑客,我需要在短时间内向250万个主机发送5亿次不符合RFC标准的HTTP/1.1请求——理想情况下是在几小时内完成。
我深入研究了HTTP/1.1和Go,以优化这一过程。我使用Kubernetes进行水平扩展,并优化代码以尽可能高效地利用每个CPU核心。我甚至修改了Go的HTTP库以加快处理速度。
我选择Go是因为它简单、支持并发性强,而且速度快。再加上我的小脑袋能理解它。
是的,我也尝试过用Rust来实现,但不幸的是,我的大脑对于异步tokio类型的魔法认识过小。而Go则让JS开发者能够完成整个项目,这对这门语言来说是一个相当大的表态。
5亿次HTTP/1.1请求意味着什么?
你可能在想,5亿次请求到底算不算多。事实上是相当多的。
如果你使用curl从单台机器逐个发送这些请求,每个请求耗时0.5秒,那么完成这些请求将需要7.9年的时间。
在现实世界中,速度会慢得多,服务器会对你进行速率限制,响应时间甚至可能超过0.5秒。
从数据传输的角度来看,这并不算多:
500亿次请求 * 1 KB(平均请求大小)≈ 478 GB
500亿次响应 * 5 KB(平均响应大小)≈ 2.33 TB
问题的关键在于另一个地方…
发送一个单独的HTTP/1.1请求意味着什么呢?
从你的角度来看,这只是一个简单的调用:
resp, err := http.Get("https://example.com")
但在幕后?HTTP库为你做了很多事情:
HTTP客户端解析DNS
HTTP客户端通过TCP连接到另一台机器
HTTP客户端进行TLS握手(生成和交换加密密钥)
HTTP客户端准备要发送的HTTP请求(规范化、编码)
HTTP客户端发送HTTP请求(头部和主体)
HTTP客户端等待响应并读取
HTTP客户端解析响应(解码、规范化并解析响应)
关闭连接(可选)
注意:这些步骤中的任何一步都可能随时失败,所以你应该准备好多次重试。
发送单个HTTP请求需要多少时间?
我知道你会讨厌这个答案,但它取决于。
有几个因素可能会影响结果:
你和服务器之间的距离
服务器负载
网络速度
到达服务器的路径
请求的大小
响应的大小
我的笔记本测试结果s
我通过向*.wordpress.com的子域发送HTTP/1.1请求来测量所有时间。
我的测试代码是用JS编写的。(我选择了wordpress.com,因为它具有通配符DNS,这样我可以生成随机子域以防止任何缓存)
HTTP请求时间
在我的测试中,我对每个值进行了50次测量。下载的正文大小为40KB,HTTP请求是一个简单的GET请求。
我们可以从中学到什么呢?
解析DNS记录和建立新的TLS连接真的很慢——以一个调用性能良好的网站为例,我的服务器在发送HTTP请求的第一个字节之前大约花费了约160毫秒。
你可能没有注意到它有多慢,因为你的浏览器会建立一次连接,并重复使用它来进行多个HTTP请求(在HTTP/2或HTTP/3的情况下,速度甚至更快)。
好消息是大部分时间都是在等待另一个服务器——我们并没有浪费很多CPU周期。在我的情况下,我希望向不同网络中的许多不同主机发送许多HTTP/1.1请求,因此不能依赖于重用连接。
还有一个之前没有提到的要求——我们不希望超载任何目标服务器。
从理论上讲,我们可以:
打开与服务器的TLS连接
并行发送所有HTTP/1.1请求
关闭连接
重复为另一个服务器
但我们很快会被限制速率或者被禁止访问。
因此,我们唯一的选择是将负载分散到许多服务器上。
如何优化呢?
首先,让我们考虑从整个方程中可以移除的部分。最好的部分就是没有这个部分。
最佳的选择是请求解析和DNS解析。
在我的情况下,我们根本不想准备(解析和规范化)HTTP/1.1请求,整个过程用于道德黑客。
我们手工制作HTTP/1.1请求,只想要一个发送管道。
对于DNS解析,我们可以在开始发送请求之前解析所有DNS记录。
高效的DNS解析是一个不同的领域,我不想去碰它。我只是使用massdns - 它可以在几秒钟内解析成千上万个DNS记录。
这样,我们就可以在发送请求时无需等待DNS解析,直接发送到多个服务器。
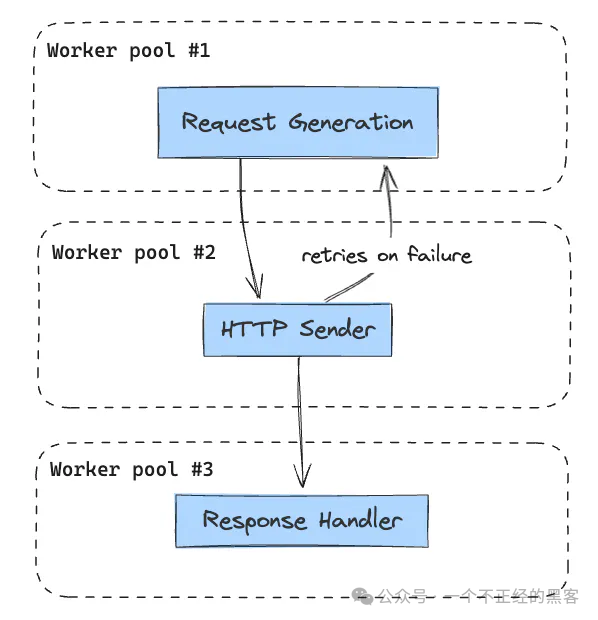
设计HTTP/1.1发送大炮
我喜欢简单,所以我使用了多个工作池,并将它们串联在一起。
1.请求生成池
2.发送器池
3.响应处理器池
我希望尽可能地重用对象和内存,因此避免为每个请求创建新的对象和新的goroutine。
每个工作池都通过一个并发安全的队列分隔开来。
这种设计效果很好,每个组件都是独立的,可以独立扩展。同时,这种设计易于调试和理解
选择正确的HTTP库
我知道Go语言中的net/http库并不是最快的,因此我不得不寻找替代方案。
最终我选择了fasthttp库,这是一个为了速度而优化的低级别HTTP库。
根据基准测试,fasthttp客户端比net/http快多达10倍。
我创建了n(HTTP发送器goroutine的数量)个fasthttp.Client对象的实例,并且每个HTTP发送器工作器都从池中获取一个客户端,发送请求,然后释放回池中。
优化库
这个库本身速度很快,但我希望从中挤出每一点性能。
我注意到,在发送HTTP请求之前,库会对每个HTTP请求进行规范化。
这是对CPU周期的浪费,因为我是手工制作HTTP/1.1请求的。
因此,我简单地分叉了该库并删除了规范化步骤。这是一个简单的更改,但节省了大量的CPU周期。
我还实现了自定义的SetRequestRaw方法,允许我发送原始的非RFC兼容的HTTP/1.1请求。
在我的版本中,我可以这样做:https://github.com/vidocsecurity/rawfasthttp
req := rawfasthttp.AcquireRequest()
resp := rawfasthttp.AcquireResponse()rawBytes := []byte("GET / HTTP/1.1\r\nHost: example.com\r\n\r\n")
req.SetRequestRaw(rawBytes)
err := client.Do(req, resp)
跳过DNS解析
对于每个请求,我只需覆盖Dial函数并直接连接到已解析的IP地址。
// 单个自定义拨号器实例
customDialer := &rawfasthttp.TCPDialer{}req := rawfasthttp.AcquireRequest()
resp := rawfasthttp.AcquireResponse()
resolved_ip := "127.0.0.1"
req.SetDial(func(addr string) (net.Conn, error) {
return customDialer.Dial(resolved_ip)
})
// ...
TLS握手优化
在对代码进行性能分析后,我发现TLS握手过程中存在大量的CPU周期浪费。
TLS在生成安全的加密密钥时会消耗大量资源。
由于我正在进行黑客活动,我并不特别关心密钥是否安全。
我只想尽快发送请求。一个简单的解决方案是硬编码密钥,但我没有足够的时间来实现它。这需要我在fasthttp库的分支中进行许多更改,所以我暂时跳过了这一步。
分割工作片段
我有250万个主机,希望向每个主机发送大约200个HTTP请求。因此,我需要对其进行分块处理。
这些片段应该足够小,以至于完成不会超过几分钟,但又足够大,以免浪费时间创建新的连接。
我决定将工作分割为每个片段200个主机。每个片段将由单个工作器执行。
我们的目标是向这200个主机的每个主机发送所有的HTTP/1.1请求,然后转移到下一个片段。
为什么是200个主机?这是我发现对我的用例最为优化的数字。工作器节点容易失败,因此我希望尽量减少可能丢失并需要重试的请求数量。
使用Kubernetes扩展HTTP/1.1发送大炮
我在DigitalOcean上使用Kubernetes来扩展这个HTTP/1.1发送炮。
这并不是我的首选,但由于我需要向互联网发送大量数据,它是唯一一个不需要我卖肾来支付费用的云平台。
DigitalOcean每个droplet慷慨地提供超过2TB的带宽。
自定义自动滚动器
我编写了一个简单的JS脚本,通过调用Kubernetes API根据队列中的目标数量来动态调整部署的规模。
它可以在几分钟内将pod数量从0扩展到60个。
作为服务的DDoS
我生成了如此大量的流量,结果自己被DDoS了 - DigitalOcean的网络无法处理我的淘气行为。
每个HTTP发送炮的pod都在不断地ping队列服务以证明自己仍然活着,但由于我生成了如此大量的流量,ping请求根本就没有发送出去,几分钟后kubelet会将该pod杀掉。
这也是减少每个片段中主机数量的另一个原因。
避免检测
DigitalOcean的另一个很酷的特性是,他们为每个droplet提供新的公共IP地址。这很棒,因为每次扫描时我都会得到新的IP地址。
因此,我可以同时从不同的IP地址发送HTTP/1.1请求,即使Cloudflare封锁了我,第二天我也能获得新的IP地址。
结论
最终的结果相当令人印象s深刻:
每个pod达到了100-400个请求每秒的速度 扩展到了60个pod 在短短几个小时内向250万个主机发送了5亿个HTTP/1.1请求
如果你是一个长期主义者,欢迎加入我的知识星球,我们一起往前走,每日都会更新,精细化运营,微信识别二维码付费即可加入,如不满意,72 小时内可在 App 内无条件自助退款
往期回顾
结果如何?我会在下一篇文章中告诉你。
Thanks for kannthu1: https://www.moczadlo.com/2024/how-i-sent-500-million-http-requests-in-under-24h
如有侵权请联系:admin#unsafe.sh