2024-9-8 23:0:15 Author: hackernoon.com(查看原文) 阅读量:5 收藏
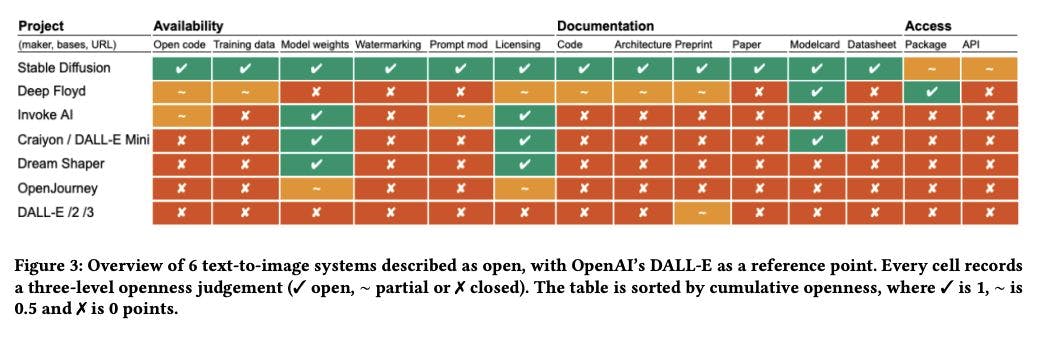
Figure demonstrating how quantitative openness judgments can be turned into actionable metrics by assigning weights to specific features to create a gradient of evaluation.
What You’ll Learn
In this blog, we dive deep into the complexities of AI openness, focusing on how Open Source principles apply—or fail to apply—to Large Language Models (LLMs) like BloomZ and Llama 2. By the end of this article, you’ll understand the historical context of Open Source licensing, the current challenges in defining "openness" in AI, and the phenomenon of "open-washing", which is misleading consumers and developers alike. We also introduce a comprehensive evaluation framework that integrates the Open Source AI Definition (OSAID) with complementary insights from other frameworks to help you make more informed decisions about AI models. Finally, we’ll conclude with actionable best practices to develop the composite judgment to quantitatively measure transparency for any “Open Source” large language model.
It’s also helpful to explore alternatives that complement widely accepted definitions. As we will discuss, some perspectives—including recent analyses—suggest that frameworks like the Open Source AI Definition (OSAID) benefit from additional dimensions, particularly in how they address issues like data transparency. The Model Openness Framework and its roots in Open Science principles offer a complementary perspective that may serve as an additional guidepost for evaluating AI openness. We are still in the earliest days of regulatory compliance in this space.
Why This Matters
The world of AI is complex and rapidly evolving, often pushing open-source principles to their limits. Understanding these nuances is vital for developers, researchers, and consumers who want to ensure that AI systems are not only innovative but also transparent, ethical, and accountable. With the rise of "open-washing"—where AI models are falsely marketed as open source—it’s more important than ever to have a robust framework for evaluating these claims. By being equipped with this knowledge, you can make informed decisions that align with the true values of openness and transparency in AI development.
The Historical Context of Open Source Licensing
To understand where we’re going, it’s essential to know where we’ve been. The Open Source movement was born out of a rebellion against the growing dominance of proprietary software in the 1980s when the Free Software Foundation (FSF) and introduced the GNU General Public License (GPL). This license was a game-changer, guaranteeing users the freedom to use, modify, and share software—essentially putting power back into the hands of developers and users.
Fast forward to the late 1990s, and the Open Source Initiative (OSI) was established to promote and protect Open Source software by certifying licenses that complied with the Open Source Definition (OSD). The OSD laid down the law for what could and couldn’t be called "open source," ensuring that the term wasn’t watered down or misused.
The Example of Large Language Models (LLMs) and the Limits to "Openness"
Enter the world of AI, where the lines between open and closed systems become even blurrier. Large Language Models (LLMs), such as GPT-3 or its successors, serve as prime examples of how "open source" can be a deceptive term in the AI landscape. LLMs are sophisticated AI systems trained on massive datasets to generate human-like text. These models have sparked significant interest and investment due to their ability to perform a wide range of tasks, from translation to creative writing. However, despite the impressive capabilities of these models, the concept of "openness" often falls short when examined closely.
In the research paper “Rethinking Open Source Generative AI: Open-Washing and the EU AI Act,” In their analysis, researchers Dr. Liesenfeld and his team compare BloomZ and Llama 2, two prominent LLMs, as examples of varying degrees of openness in AI. This comparison offers a practical demonstration of how to apply an openness matrix to generative AI models:

BloomZ: A Case Study in True Openness
BloomZ represents a model that genuinely embraces the principles of open source, setting a high standard for transparency and accessibility in AI.
- Availability: BloomZ makes the source code for training, fine-tuning, and running the model available, representing a high degree of openness. The LLM data used to train BloomZ is extensively documented, making it transparent about its data sources and processes. Both the base model weights and the instruction-tuned version are openly available, allowing for replication and scrutiny by the broader community.
- Documentation: The BloomZ project is well-documented, with detailed descriptions available in multiple scientific papers and an active GitHub repository. The data curation and fine-tuning processes are comprehensively covered, providing insights into the model’s architecture, training data, and responsible use. Peer-reviewed papers further support its transparency, including an estimation of the carbon footprint, which is rarely documented in AI projects.
- Access and Licensing: BloomZ is distributed through the Petals API, and its source code is released under the Apache 2.0 license, an OSI-approved license. The model weights are covered under the Responsible AI License (RAIL), which imposes restrictions to prevent harmful use, adding a layer of ethical responsibility.
Llama 2: The Pitfalls of Open-Washing
In stark contrast, Llama 2 exemplifies the concept of "open-washing," where the label of open-source is applied without fully meeting the principles of openness.
-
Availability: In stark contrast, Llama 2 does not make its source code available. Only the scripts for running the model are shared, and the LLM data is vaguely described, with limited details provided in a corporate preprint. Access to the base model weights is restricted, requiring a consent form, and the data used for instruction tuning remains undisclosed, further limiting transparency.
-
Documentation: The documentation for Llama 2 is minimal, with the source code itself not being open. The architecture is described in less detail, scattered across corporate websites and a single preprint. Unlike BloomZ, Llama lacks comprehensive documentation of its training datasets, instruction tuning, and fine-tuning processes.
-
Access and Licensing: Llama 2 is available behind a privacy-defying signup form, and its licensing is handled under Meta’s own Community License. This license is less stringent than BloomZ’s RAIL, with a lower bar for how generated content is represented, leaving room for potentially misleading applications.
The comparison between BloomZ and Llama 2 highlights the stark differences in their approach to openness. BloomZ is a prime example of a model that genuinely embraces the principles of open source, with transparency in its code, data, and documentation. In contrast, Llama 2 exemplifies "open-washing," where the model is labeled as open source but falls short in most aspects of true openness, with only the model weights being accessible under restrictive terms. This comparison underscores the need for a more nuanced understanding of openness in AI and the importance of evaluating models based on a comprehensive set of criteria rather than relying on superficial claims of openness.
The Challenge of Open-Washing
"Open-washing" is the practice of slapping an open-source label on something that isn’t truly open. In the AI world, open-washing is rampant, with companies offering up bits and pieces of their AI systems while keeping the most crucial components under lock and key.
The research paper delves into the dirty details of open-washing in AI, highlighting some of the key challenges:
Composite Openness: Openness in AI isn’t a one-size-fits-all concept. It’s a puzzle with many pieces, and each piece contributes to the overall transparency of the system. However, too often, companies only release some of the pieces, leading to a misleading sense of openness. The research introduces the concept of gradient openness, emphasizing that openness in AI should be viewed as a spectrum rather than a binary state. Different components of an AI system—source code, data, models—can be open to varying degrees, and it’s crucial to assess each component individually. By understanding this gradient, we can better evaluate the true openness of AI systems and avoid being misled by partial transparency.
Selective Openness: Some AI models are released with just enough openness to get by—usually the model weights—but the critical components, like the data and training process, remain proprietary. This selective openness is a half-baked attempt at transparency that does more harm than good. By only providing partial access, companies can claim openness without actually providing the full transparency needed for meaningful collaboration and understanding.
Regulatory Loopholes: The EU AI Act, a well-intentioned regulatory framework, may inadvertently encourage open-washing by allowing AI models released under open licenses to bypass detailed documentation requirements. This loophole could lead to a flood of AI systems that are "open" in name only, with little to no real transparency. While the intention behind such regulations is to promote openness, without careful implementation and oversight, they can be exploited to create the illusion of openness without the substance.
Julia Ferraioli also touches on the issue of open-washing in her blog post, noting, "The crux of the problem is that terms like 'open source' are being stretched and redefined to fit the agendas of large companies that are more interested in marketing than in true transparency and collaboration." This insight reinforces the need for a robust evaluation framework to sift through these misleading claims.

Research Insights: The Realities of Open Source AI
The Model Openness Framework introduced in recent discussions complements some of these insights by offering an Open Science-aligned approach to transparency. While the Open Source AI Definition (OSAID) provides a solid foundation, many in the field—including some researchers—believe that it may not go far enough, particularly when it comes to data transparency. The Model Openness Framework, by comparison, sets a more stringent benchmark, emphasizing not only the openness of code but also the availability of datasets, methodologies, and training processes in line with Open Science values.
Expanding with Gradient Openness
Building on OSAID, the concept of gradient openness adds nuance to the evaluation process. By assessing each component of an AI system—source code, data, models—individually, we can better understand the true level of transparency and openness.
This paper mentioned offers key insights from the research:
-
Challenges of Licensing Adjustments: Traditional Open Source licenses were designed for software, not for the complex, multi-faceted nature of AI. The paper argues that new licensing strategies are needed to address the unique challenges posed by AI. These licenses should ensure that not only the source code but also the data, models, and parameters are covered under Open Source principles. This holistic approach to licensing is crucial for maintaining the integrity of the open source movement in the AI era.
-
Ethical Considerations: Beyond technical openness, the paper also highlights the importance of ethical considerations in AI development and deployment. It points out that ensuring fairness, accountability, and transparency in AI systems is not just a technical challenge but a moral imperative. The ethical dimension of AI development must be integrated into any discussion of openness, as transparency without responsibility can lead to significant harm.
-
A Practical Approach: The researchers outline a few reasonable ways to establish categorical reliability even under a composite license. By integrating the Open Source AI Definition (OSAID) with these deeper insights, we can build a more robust framework for assessing AI systems. This approach allows for a more nuanced and comprehensive evaluation of AI models, ensuring that they meet both technical and ethical standards of openness.

The LLM Versioning Problem: An Overlooked Aspect of Openness
One of the more nuanced challenges in AI openness is the issue of LLM versioning. Unlike traditional software packages, where version updates are typically well-documented and transparent, LLMs can undergo updates that are opaque, leaving users in the dark about what has changed. This lack of transparency is akin to installing an operating system update without knowing what’s been modified—except, in the case of LLMs, the stakes are arguably even higher.
The OS Comparison: Imagine installing an operating system on your computer and regularly receiving updates. Normally, you’d expect to see a changelog, detailing what’s been fixed, improved, or added. This transparency is crucial for users to understand the state of their system. Now, consider an LLM that’s being continually updated without any such transparency. Users may find themselves working with a model that has changed in subtle or significant ways without any clear understanding of those changes. This lack of transparency can lead to issues ranging from degraded performance to ethical concerns, as the model may behave in unexpected ways. The comparison highlights the risks associated with using AI models that are not transparent about their updates, emphasizing the need for clear and accessible versioning information.
The Risks of Opaque Updates: Without transparency, users cannot fully trust the AI systems they are using. Just as you wouldn’t install an OS update without knowing what’s been changed, relying on an LLM that undergoes opaque updates is risky. This is particularly concerning in high-stakes environments where AI is used for decision-making processes that affect real lives. If an LLM update introduces new biases or removes important functionality, the consequences could be severe. The lack of transparency not only undermines user trust but also raises significant ethical and operational risks.
Establishing a Comprehensive Evaluation Framework: Integrating OSIAID
To help navigate these challenges, we introduce a comprehensive evaluation framework that combines the strengths of the Open Source AI Definition (OSIAID) with deeper insights from recent research. This framework aims to provide a more robust method for assessing the openness of AI systems.
OSIAID as a Foundation: The Open Source AI Definition provides a solid foundation for understanding what constitutes an open-source AI system. It lays out clear criteria for transparency, accessibility, and ethical use, ensuring that AI models meet a minimum standard of openness. By adhering to the OSIAID, developers, and users can have confidence that an AI model meets basic standards of openness and transparency.
Expanding with Gradient Openness: Building on OSIAID, the concept of gradient openness adds nuance to the evaluation process. By assessing each component of an AI system—source code, data, models—individually, we can better understand the true level of transparency and openness. These may be indicators of your own organization’s risk appetite and framework or standardized between organizations. This approach allows for a more detailed and accurate assessment of AI models, identifying areas where openness is strong and where it may need improvement.
Addressing Ethical and Legal Implications: The framework also incorporates ethical and legal considerations, ensuring that AI systems are not only technically open but also aligned with broader societal values and legal requirements. By integrating these considerations, the framework ensures that openness is not just about technical transparency but also about meeting the ethical and legal standards that are crucial in AI development.
Julia Ferraioli’s emphasis on the need for clear definitions and a commitment to the principles of Open Source resonates with this approach. She writes, "The Open Source community must hold fast to its values, ensuring that any deviations are met with critical scrutiny and a demand for transparency.” These practices are designed to meet that need, providing a robust and comprehensive framework for evaluating AI systems.
Keep the Regulatory Horizon in Mind
As the landscape of AI regulation continues to evolve, it’s crucial to stay informed and engaged with regulatory developments. The EU AI Act and similar frameworks will play a significant role in shaping the future of AI openness and transparency. By understanding and participating in these discussions, you can help ensure that regulatory frameworks effectively promote transparency and accountability in AI.
- Evaluate Openness Across Multiple Dimensions: Use the framework to assess AI systems on various dimensions of openness, including source code, data, model weights, and documentation. A comprehensive evaluation ensures that you are not misled by superficial claims of openness and can make informed decisions about the AI models you use.
- Beware of Open-Washing: Be cautious of AI models that claim to be open source but only offer partial transparency. Look for signs of selective openness, where only certain components are made available. Understanding these tactics can help you avoid being deceived by models that do not truly adhere to open-source principles.
- Demand Comprehensive Documentation: Insist on detailed documentation for AI systems, including information on training data, fine-tuning processes, and ethical considerations. This transparency is crucial for understanding the model’s capabilities and limitations. Comprehensive documentation allows for better evaluation and use of AI models, ensuring that you are fully informed about the tools you are using.
- Support AI-Specific Licensing: Advocate for the development and adoption of AI-specific licenses that cover not just the code but also the data, models, and parameters. This will help prevent companies from hiding behind partial openness. AI-specific licenses can address the unique challenges of AI development, ensuring that all aspects of the model are open and transparent.
- Engage with Regulatory Frameworks: Stay informed about regulatory developments, such as the EU AI Act, and actively participate in discussions to ensure that these frameworks effectively promote transparency and accountability in AI. Engaging with regulatory frameworks ensures that your voice is heard in the development of policies that will shape the future of AI.
Conclusion: Ensuring AI Openness in a Complex World
The world of AI is complex, messy, and full of challenges that the Open Source movement wasn’t originally designed to handle. But that doesn’t mean we should give up on the ideals of transparency, collaboration, and openness. Instead, we need to adapt, evolve, and ensure that Open Source AI still represents the four freedoms necessary to fit the definition.
As we navigate this new world, the collaboration between the Open Source community, regulatory bodies, and AI developers will be crucial. By addressing the challenges of open-washing, rethinking our approach to licensing, and embracing robust regulatory frameworks, we can build an AI ecosystem that is not only innovative but also ethical and accountable.
AI is here to stay, and it’s up to us to make sure it serves the greater good. Ultimately, I’ll leave you with this important thought directly from the researchers of this important work:
“Perhaps it is no coincidence that publicly funded researchers are leading the way in calling out open-washing: not beholden to corporate interests and without incentives to hype AI, we can take a step back and lay bare what big tech is doing — and devise constructive ways to hold them accountable.” Dr. Liesenfeld.
This research team are actively involved in several initiatives related to the EU AI Act, particularly focusing on what a "sufficiently detailed summary" in AI documentation will entail in practice. This work is being conducted in collaboration with the Mozilla Foundation and the Open Future Foundation. The team is also continuing their academic work on technology assessment and is planning to release a new website later this year that will serve as a public resource for openness assessment, making these tools more accessible to the broader public. This initiative aims to provide clearer standards and frameworks to hold companies accountable for transparency in AI.
The Open Source AI Definition (OSAID) is still open for public review and feedback. If you’d like to participate in shaping the future of Open Source AI, you can submit comments on the current draft here. The final version of the definition will be announced at the All Things Open (ATO) conference, taking place in 2024. Stay tuned for more updates as the community continues to refine this critical framework for open AI development.
At the end of the day, if you are going to take a calculated risk using these LLMs, then you need to measure that risk. I hope this gives you a few ways to do that, and I absolutely want you to reach out to me if you have any quantitative metrics or improvements to the solutions offered above or generally any questions on this topic I wasn’t able to cover here.
如有侵权请联系:admin#unsafe.sh