2024-9-9 20:40:13 Author: hackernoon.com(查看原文) 阅读量:1 收藏
Change is the only constant, and we have to adapt
Crafting a system that lasts forever is extremely difficult in our ever-changing digital world, and any working product will require maintenance and updates to remain maintainable and evolvable.
Entropy is everywhere.
💾 Physical hardware deteriorates over time. Bits on a disk can degrade due to corrosion, dust, electric leakage, or physical scratches. And even though modern cloud storage solutions can offer you great resilience, you’ll never find a 100% guarantee of data safety. The technology uses a number of solutions, such as checksums to verify the integrity of stored data, or RAID arrays and replication methods.
🌊 Software systems are very dynamic. Imperfect humans design solutions, evolve languages and frameworks used for crafting, introduce and fix security breaches, build on top of features inherited from predecessors, and forget to track if any space is left on DB disks.
We’re shaping sand castles under the heavy rain. Entropy growth is inescapable, even if you’re not touching the software, because it always has dependencies and some environment.
🛰️ Even Mars rovers receive software updates. Similar to how smartphones receive updates, NASA’s rovers receive over-the-air software updates. These updates are transmitted from Earth via the Deep Space Network, a collection of large antennas communicating with interplanetary spacecraft. Curiosity and Opportunity received updates to enhance capabilities and fix issues. (link)
⚙️ Proactive maintenance is essential to keeping systems healthy. And just as geneticists work to understand and fix genetic disorders, software engineers must diagnose and address the factors leading to software decay, ensuring the longevity and reliability of their creations.
Even if you freeze your system - the context will continue changing - potential difference will grow - causing the rust and erosion.
Legacy systems often suffer significantly from software erosion. These systems, which may have been developed decades ago, frequently rely on outdated programming languages and frameworks that are no longer supported. For example, many financial institutions still use COBOL, a language developed in the 1950s. While these systems are stable, they become increasingly difficult to maintain and integrate with modern technologies. This creates a risk of failure as experienced COBOL programmers retire and new developers are unfamiliar with the language.
Impact of Software Rot on Security. Software rot can have serious security implications. As software ages and dependencies are not updated, vulnerabilities can accumulate, making the system an easy target for attackers. The Equifax data breach in 2017, one of the largest in history, was partly due to an unpatched vulnerability in the Apache Struts framework, which the company had failed to update in a timely manner. This breach exposed sensitive information of 147 million people.
Understanding the factors that accelerate or decelerate software erosion is essential. This article aims to define these factors and provide a checklist for planning, building, and maintaining software systems to minimize decay. By proactively managing erosion, we can extend the lifespan and reliability of our software systems.
Causes of software rust and ways to deal with them
Changing context
Relying on external systems, which can change or degrade over time, introduces potential channels for software erosion and technical debt.
A historical example of this is seen in many early computer games that used the CPU clock speed as a timer. These games were designed to run at specific speeds, correlating game actions directly to the CPU's clock cycles. As hardware evolved and CPUs became significantly faster, these games ran much quicker than intended, often becoming unplayable. For instance, a game that expected a CPU speed of 4.77 MHz would run many times faster on a 2 GHz processor, disrupting gameplay mechanics.
A more recent example is the “TLS apocalypse.” Transport Layer Security (TLS) protocols are essential for secure internet communications. However, older versions like TLS 1.0 and TLS 1.1 were deprecated due to security vulnerabilities. This deprecation meant that software relying on these outdated protocols could no longer establish secure connections. Many older systems that were not updated to support TLS 1.2 found themselves unable to connect to servers that required the newer protocols.
Maintain accountability for external dependencies and monitor their changes. Regularly update dependencies in a controlled environment with thorough testing.
Code Dependencies
Almost any software system has code dependencies, relying on external libraries and frameworks to provide additional functionality and streamline development. If not managed carefully, these dependencies can also introduce significant technical debt.
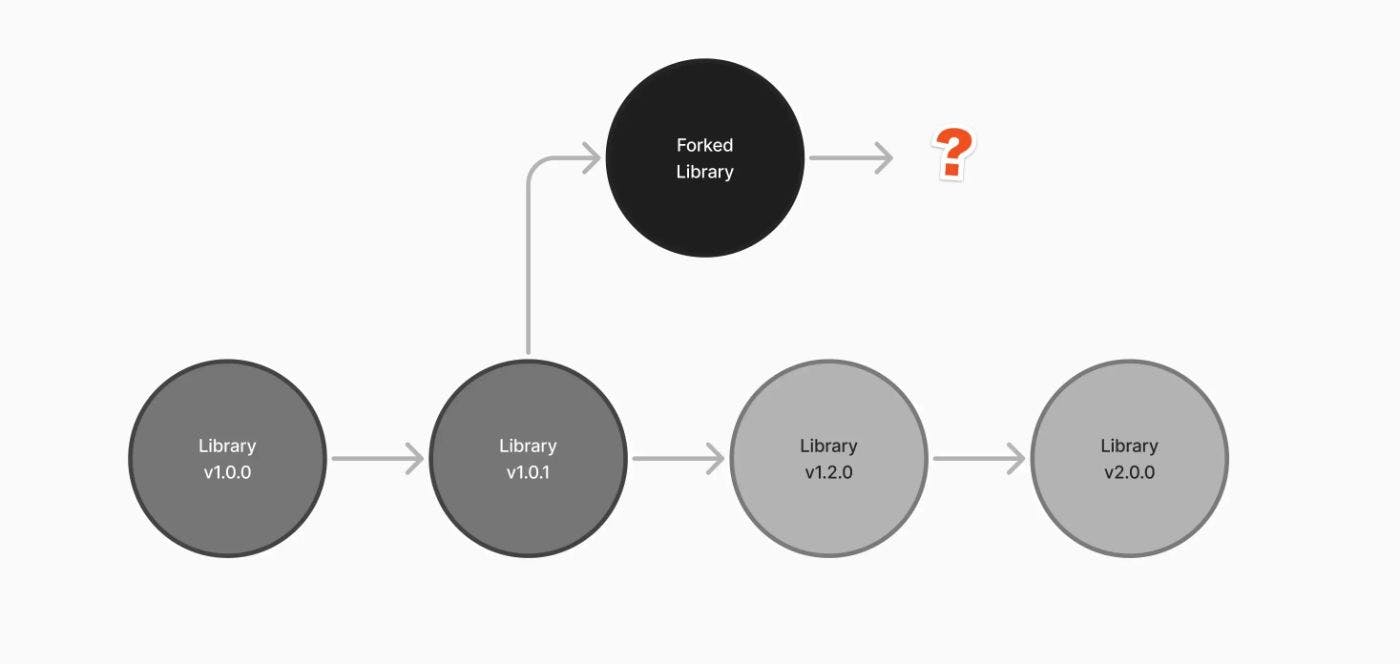
Modifying Dependencies 💣
Sometimes, you may find that existing dependencies lack certain features or capabilities. There might be an option to fork some open-source dependency. However, this approach can add a substantial burden to your technical debt. When you fork a dependency, you become responsible for maintaining your version, ensuring it stays updated with any bug fixes or improvements made to the original library. This can be daunting, especially as the original library evolves, potentially introducing conflicts and compatibility issues with your fork.

Deviating from Framework Recommendations 💣
Developers sometimes deviate from framework design recommendations to implement custom solutions. While this might solve immediate problems, it can create significant challenges when it comes to updating the framework in the future. Custom solutions can lead to incompatibilities with new framework versions, making updates much more complex and time-consuming.
Dependency Management: to lock or not to lock 💣
In managing dependencies, you might use tools like package.json in Node.js, allowing for patch updates through semantic versioning (semver). However, relying on semver alone can be risky. Not all library maintainers strictly adhere to semantic versioning principles, meaning updates that are supposed to be non-breaking can still introduce unexpected issues. This uncertainty highlights the need for a controlled approach to dependency updates.
{
"dependencies": {
"webpack": "*" // Allows any version
"react": ">=16.0.0 <17.0.0", // Allows any version between 16.x.x but not 17.0.0
"lodash": "^4.17.21", // Allows minor updates
"mongoose": "~5.13.8", // Allows patch updates
"express": "4.17.1", // Fixed version, no updates
}
}
But you need updates anyway. Locking dependencies to specific versions indefinitely is not a viable solution. There are crucial reasons to update dependencies regularly: new features, performance improvements, bug fixes, and security patches. Neglecting these updates can lead to software rot, as your application becomes increasingly outdated and vulnerable over time.
Lock dependencies strictly in critical services to prevent uncontrolled automatic updates. Allow patches or minor updates only if you understand the risks and are prepared for them.
Establish a process for regular, controlled dependency updates, along with thorough testing.
Document the dependency update process. Explain to future colleagues why certain dependencies are locked and describe the steps to update them.
Technology choices
Aligning Tech Choices with Team Skills
Selecting technologies that your team is already familiar with can lead to more efficient development and fewer mistakes. Conversely, adopting an unfamiliar technology stack can lead to slower progress, higher chances of bugs, and increased technical debt due to avoidable mistakes made in the early stages of the project. If your team has extensive experience with JavaScript, opting for frameworks like React Native or Node.js to cover your fullstack needs can be more beneficial than choosing a less familiar technology, even if the latter might have certain advantages.
Don't take unnecessary "loans" at the start of work. Build a strategy and include different stages in it, solve problems as they arise.
Build vs. Buy Decisions
Another critical aspect is deciding which components to build in-house and which third-party systems to integrate. Building components in-house offers greater control and customization but comes with higher development and maintenance costs. On the other hand, third-party systems can save time and resources but might introduce dependencies and potential long-term costs associated with licensing, support, and integration.
When making build vs. buy decisions, consider the following:
- Core Competencies: Focus on building core components that differentiate your product and add unique value.
- Resource Availability: Ensure you have the necessary skills and resources to develop and maintain the in-house components.
- Cost-Benefit Analysis: Evaluate the long-term costs and benefits of third-party systems versus building your own solutions.
Keeping the Tech “Zoo” Under Control
Introducing new tools, third-party systems, languages, and frameworks adds to your maintainability budget. Every new addition to your technology stack increases complexity and requires ongoing maintenance, updates, and support. This “tech zoo” can quickly become unmanageable if not controlled, leading to increased technical debt and software erosion.
Standardize tools and frameworks. Constraints will simplify training, shorten the learning curve for new team members, and ensure greater consistency across projects.
Document decisions. Explaining the choice of certain technologies will help future team members understand the logic behind the decisions and maintain consistency.
Software design issues
Now let’s focus on the code itself. Decisions you’re making crafting code, the way you organize it and think about the its evolvability, the way you modularize it and build new features upon as the system grows - can drastically accelerate or slow down the entropy speed.
🏃 Code design decisions in the long run
If you’re building an application where some data may be modified by users - you need to ensure that they won’t be able to bring the system into a broken state with any stream of actions.
Imagine that you are developing a task management application. You are writing a CRUD API for users and tasks. The system allows you to create new users, tasks, and assign tasks to users. Then, let's say, you need to support deleting users.
How should the system work if we delete a user to whom tasks are assigned? What if the system also has statistics on task completion by users? What should be displayed in the application inside the task instead of the name of the deleted user? Finally, what if later there is a requirement to assign one task to several users? A small system of two entities, and how many different cases and questions.
Surely, some of them will not even be answered in advance. At the same time, some decisions will be very expensive to "roll back" and change at a distance. Let's highlight several principles that will help in designing more stable business logic.

While it’s impossible to predict the future modifications that might arise, there are a few mental tricks you can do to help describe and design system’s behavior at the earlier stage:
Think about your system as a finite automata, sketch all possible states of data, actions, and UI
Think about many-to-many relations designing application Data Entities and their Relations. It might be much easier to support processing an array of related task assignees as you build the system, even if array might have just one user. And it might be impossibly hard to add such support in a few years to a large system working in production.
🙈 Evolving the existing software, not knowing 100% of it
Another practical example. Let's imagine an application that displays a list of articles. Let's say that previously the functionality was added to customize the order of articles in the search results, with the ability to specify a number for each article - 1, 2, 3, to use them for sorting. Then the team decides to change the way articles are displayed - add labels to them and display them grouped by these labels. If each group needs its own sorting order, the previous logic will need to be rebuilt. Otherwise, we will be left with unused code, increasing the complexity of the codebase.
People in the team will change, product managers will build the system on top of the existing foundation. It is vital that the product owner and engineer always understand the existing system, otherwise it will be like driving a car with your eyes closed, or trying to build a skyscraper on a wooden foundation.

Update the documentation as the system is developed and evolved, so that you always have a concise and clear “model” of the existing functions
Don’t be afraid to question new business requirements if they don’t fit with the existing foundation. Help the team avoid implementing requirements that are not fully developed. Spending time clarifying requirements can save months of additional or unnecessary work, and it is always cheaper to make adjustments earlier.
⚖️ Balancing distance and coupling of software system parts
The way you organize your services and define boundaries between them may drastically affect the maintainability and evolvability costs.
Let's say you have a set of services, each responsible for different functions. However, to send emails, several services can independently integrate, say, the SendGrid SDK. While this straightforward approach may be quick to implement initially, several problems will arise over time:
- 💣 Multiple Points of Maintenance: As the SendGrid SDK evolves, each microservice with its integration will need to be updated independently. Every time SendGrid releases an update, your team will have to update and test each service separately to ensure compatibility and functionality.
- 💣 Inconsistent Implementations: Different teams might implement the email sending functionality in slightly different ways, leading to inconsistencies and potential bugs.
- 💣 Coupling: Each service becomes tightly coupled to the specifics of the SendGrid SDK, making future changes more complex. For instance, if you decide to switch to a different email provider, you will need to update each service individually.
A much more stable way would be to create a dedicated emailing service:
- Single Point of Integration: Only the emailing service integrates with the SendGrid SDK. This isolates the SDK-specific logic in one place, making it easier to update and maintain.
- Simplified Contracts: Other microservices interact with the emailing service via a simple, well-defined API. For example, a service needing to send an email would make a request to the emailing service, providing necessary details like recipient, subject, and body. The emailing service handles all interactions with SendGrid.
{
"to": "[email protected]",
"subject": "Welcome!",
"body": "Thank you for signing up."
}
- Encapsulation: All email-related logic, including error handling, retries, and formatting, is encapsulated within the emailing service. This encapsulation reduces the complexity in other services and ensures consistent email-sending behavior across the application.
- Ease of Updates: When the SendGrid SDK needs to be updated, you only need to update the emailing service.
- Flexibility: If you decide to switch to a different email provider, you only need to update the emailing service. The rest of your system remains unaffected, as long as the API contract between services is maintained.
A great speech about balancing software complexity with distance and coupling:
How to Estimate Current Entropy Level - A List of Handy Questions
- Dependencies age. How old and outdated are dependencies in your repositories? How often are you updating them? Can you safely ensure system stability after dependencies upgrade?
- Evolvability and fragility. How easy is it to add new features to the system? Have your TTM been slowing down over the last quarters? How other do you have bugs when you modify or add new functions?
- Issues detection. At what stage do you mostly catch bugs - development, staging, production?
- Engineering onboarding time. How much time is needed for a new team member to start contributing into his area? To understand the overall system architecture?
- Bugs and tech debt backlogs size. Are you keeping up to keep them under control in parallel to building new stuff?
Slowing down erosion - checklist!
Tech Platform and DevOps
- ⚔ Choose a stack that fits your engineering team and current growth phase. Lock it wisely.
- 👀 Use monitoring tools to continuously analyze system performance and health. Implement automated testing. "Listen" to both your hardware and software.
- 🔎 Integrate automated quality control into CI/CD — testing, code review, etc. — tools in this area are rapidly evolving these days.
Development and architecture
- 🧱 Decompose the system into loosely coupled services, arm yourself with the principles of SOLID, Clean and Event-Driven architecture, Domain-Driven Design, 12 factor app, and other best design practices.
- ⛓ Lock code dependencies and establish a clear process for their continuous update.
- 📦 Create templates for solving common problems - microservice skeletons, common utilities, component libraries, etc.
- 🏙 Thoughtful and gradual product evolution - leave buffers after creating an MVP in the “ASAP” mode, make sure you fully understand the existing scope before building on top of it.
Processes and Culture
- 🥷 Establish an "architectural board" with strong engineers from your teams to ensure they make consistent decisions and slow down the growth of entropy.
- 🚦 Implement refactoring sprints: regularly allocate time to close gaps and eliminate your technical debt.
- 💪 Develop a culture of ownership and responsibility in the team, encourage engineers to care about their code and be responsible for its performance and stability.
如有侵权请联系:admin#unsafe.sh