2024-9-12 18:0:16 Author: hackernoon.com(查看原文) 阅读量:3 收藏
Authors:
(1) Suriya Gunasekar, Microsoft Research;
(2) Yi Zhang, Microsoft Research;
(3) Jyoti Aneja, Microsoft Research;
(4) Caio C´esar Teodoro Mendes, Microsoft Research;
(5) Allie Del Giorno, Microsoft Research;
(6) Sivakanth Gopi, Microsoft Research;
(7) Mojan Javaheripi, Microsoft Research;
(8) Piero Kauffmann, Microsoft Research;
(9) Gustavo de Rosa, Microsoft Research;
(10) Olli Saarikivi, Microsoft Research;
(11) Adil Salim, Microsoft Research;
(12) Shital Shah, Microsoft Research;
(13) Harkirat Singh Behl, Microsoft Research;
(14) Xin Wang, Microsoft Research;
(15) S´ebastien Bubeck, Microsoft Research;
(16) Ronen Eldan, Microsoft Research;
(17) Adam Tauman Kalai, Microsoft Research;
(18) Yin Tat Lee, Microsoft Research;
(19) Yuanzhi Li, Microsoft Research.
Table of Links
- Abstract and 1. Introduction
- 2 Training details and the importance of high-quality data
- 2.1 Filtering of existing code datasets using a transformer-based classifier
- 2.2 Creation of synthetic textbook-quality datasets
- 2.3 Model architecture and training
- 3 Spikes of model capability after finetuning on CodeExercises, 3.1 Finetuning improves the model’s understanding, and 3.2 Finetuning improves the model’s ability to use external libraries
- 4 Evaluation on unconventional problems with LLM grading
- 5 Data pruning for unbiased performance evaluation
- 5.1 N-gram overlap and 5.2 Embedding and syntax-based similarity analysis
- 6 Conclusion and References
- A Additional examples for Section 3
- B Limitation of phi-1
- C Examples for Section 5
Abstract
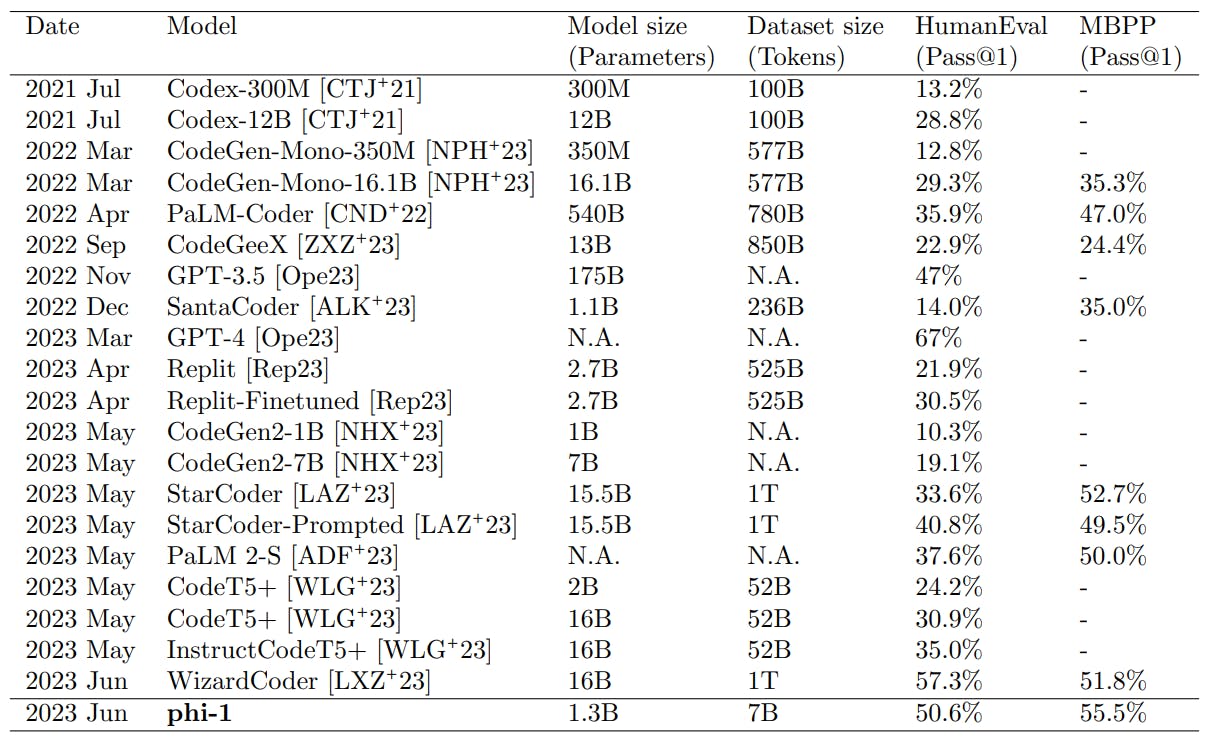
We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, using a selection of “textbook quality” data from the web (6B tokens) and synthetically generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as phi-1 that still achieves 45% on HumanEval.
1 Introduction
The art of training large artificial neural networks has made extraordinary progress in the last decade, especially after the discovery of the Transformer architecture [VSP+ 17], yet the science behind this success remains limited. Amidst a vast and confusing array of results, a semblance of order emerged around the same time as Transformers were introduced, namely that performance improves somewhat predictably as one scales up either the amount of compute or the size of the network [HNA+ 17], a phenomenon which is now referred to as scaling laws [KMH+ 20]. The subsequent exploration of scale in deep learning was guided by these scaling laws [BMR+ 20], and discoveries of variants of these laws led to rapid jump in performances [HBM+ 22]. In this work, following the footsteps of Eldan and Li [EL23], we explore the improvement that can be obtained along a different axis: the quality of the data. It has long been known that higher quality data leads to better results, e.g., data cleaning is an important part of modern dataset creation [RSR+ 20], and it can yield other side benefits such as somewhat smaller datasets [LYR+ 23, YGK+ 23] or allowing for more passes on the data [MRB+ 23]. The recent work of Eldan and Li on TinyStories (a high quality dataset synthetically generated to teach English to neural networks) showed that in fact the effect of high quality data extends well past this: improving data quality can dramatically change the shape of the scaling laws, potentially allowing to match the performance of large-scale models with much leaner training/models. In this work we go beyond the initial foray of Eldan and Li to show that high quality data can even improve the SOTA of large language models (LLMs), while dramatically reducing the dataset size and training compute. Importantly, smaller models requiring less training can significantly reduce the environmental cost of LLMs [BGMMS21].
We focus our attention on LLMs trained for code, and specifically writing simple Python functions from their docstrings as in [CTJ+ 21]. The evaluation benchmark proposed in the latter work, HumanEval, has been widely adopted for comparing LLMs’ performance on code. We demonstrate the power of high 1

quality data in breaking existing scaling laws by training a 1.3B-parameter model, which we call phi-1, for roughly 8 passes over 7B tokens (slightly over 50B total tokens seen) followed by finetuning on less than 200M tokens. Roughly speaking we pretrain on “textbook quality” data, both synthetically generated (with GPT-3.5) and filtered from web sources, and we finetune on “textbook-exercise-like” data. Despite being several orders of magnitude smaller than competing models, both in terms of dataset and model size (see Table 1), we attain 50.6% pass@1 accuracy on HumanEval and 55.5% pass@1 accuracy on MBPP (Mostly Basic Python Programs), which are one of the best self-reported numbers using only one LLM generation. In Section 2, we give some details of our training process, and we discuss evidence for the importance of our data selection process in achieving this result. Moreover, despite being trained on much fewer tokens compared to existing models, phi-1 still displays emergent properties. In Section 3 we discuss these emergent properties, and in particular we confirm the hypothesis that the number of parameters plays a key role in emergence (see e.g., [WTB+ 22]), by comparing the outputs of phi-1 with those of phi-1-small, a model trained with the same pipeline but with only 350M parameters. The methodology used in this section is reminiscent of the Sparks of AGI paper [BCE+ 23] that argued for moving away from static benchmarks to test LLMs’ performance. Finally in Section 4 we discuss alternative benchmarks to evaluate the model and in Section 5 we study possible contamination of our training data with respect to HumanEval. We release the model for usage and evaluation by the broader community, but omit some details of the synthetic data generation, for proprietary reasons.
More related works Our work is part of the recent program of using LLMs for program synthesis, see [CTJ+ 21, NPH+ 22] for more references on this. Our approach is also part of the emerging trend of using existing LLMs to synthesize data for the training of new generations of LLMs, [WKM+ 22, TGZ+ 23, MMJ+ 23, LGK+ 23, JWJ+ 23]. There is an ongoing debate about whether such “recursive training” might lead to narrower scope for the resulting LLM [SSZ+ 23, GWS+ 23], see [MMJ+ 23] for a counterviewpoint. Note that in this paper we focus on a narrow task, similarly to [JWJ+ 23], in which case it seems plausible to attain better performance than the teacher LLM on that specific task (as is argued in the latter paper).
如有侵权请联系:admin#unsafe.sh