
TriCore firmware is important for security researchers since it is found in a wide range of car 2024-9-12 20:37:0 Author: binary.ninja(查看原文) 阅读量:13 收藏
TriCore firmware is important for security researchers since it is found in a wide range of car components. While we originally announced the availability of a separate paid TriCore plugin in our 4.1 release, we have since updated it and are excited to now ship TriCore to all Binary Ninja Ultimate customers! This not only makes it cheaper and enables access to other architectures, but makes getting access easier than ever. If you haven’t heard of Ultimate yet, check out our other announcement from today!
For those unfamiliar, TriCore is a super-scalar 32-bit CPU architecture primarily used in automotive/industrial applications. It behaves much like a traditional RISC-like architecture, coupled with many DSP focused features, namely it’s coprocessor, pipelining and SIMD design.
As always, when lifting a new architecture in Binary Ninja new quirks present themselves. As we try and fit the architectures instruction set into our Lifted IL, we come across new patterns that require higher levels of our analysis to be refactored to improve readability.
TriCore features a pair of general register files (data and address) using a very common extension technique (which we will refer to as “pairing”) where two registers (even and odd) are used to represent a wider semantic register (extended).
d4: 0xfffffff
d5: 0x0e0e0e0e
e4: 0x0e0e0e0efffffff
When lifting, it is crucial to preserve this information. If we don’t, we either treat the extended register as separate from the actual backed register, losing the ability to perform accurate data-flow analysis, or we have to duplicate the lift in a very error-prone way.
Instead, we utilize Binary Ninja’s split register support, which has seen many improvements due to its frequent use within TriCore. This means you will also see the same benefits in HLIL across all architectures that use split/paired registers.

TriCore has its quirks, particularly the fact that it has a separate register file for working with addresses (and consequently, separate ALU). While handling this is as simple as adding more registers to the architecture, it can present challenges in other areas, as we explore below.
Because the calling convention can skip either register file, using a fixed register list for parameter selection would result in unused parameters, or worse, usage of the parameters through all call-sites. To address this, we opted to use our built-in heuristics, allowing the analysis to determine the set of parameters without explicitly specifying the ordering. In the future, we plan to better support this calling convention paradigm.
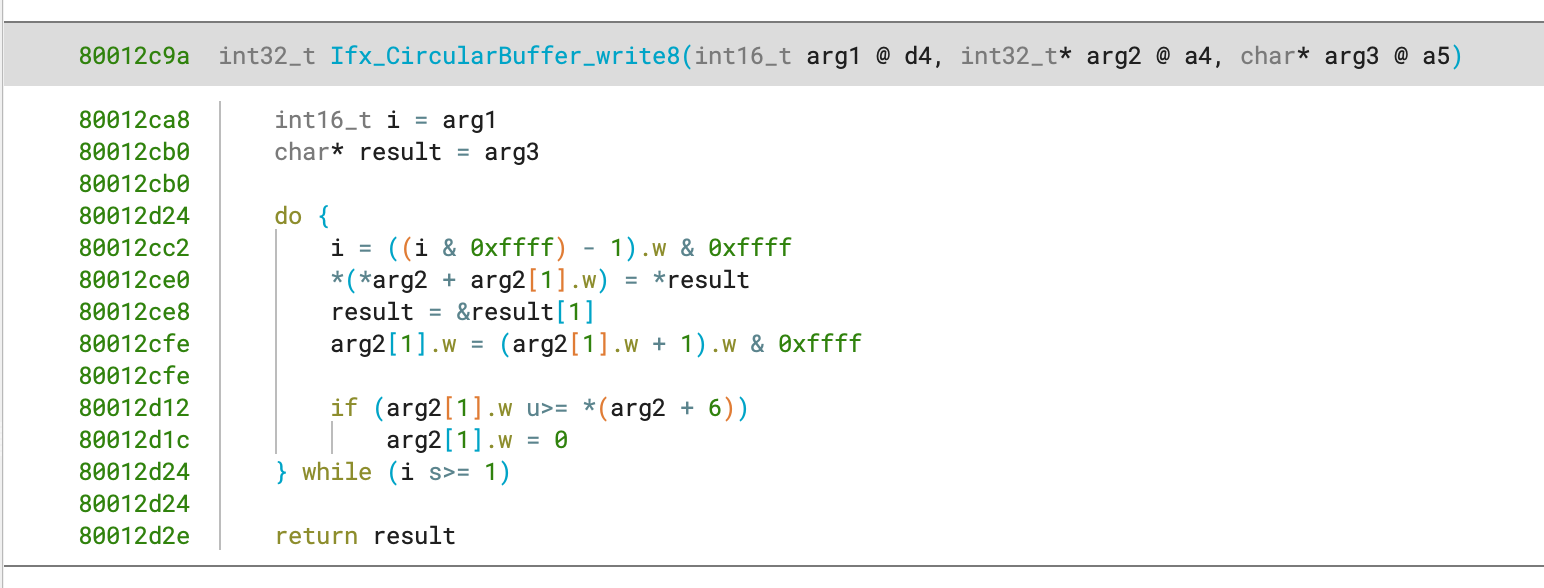
The function’s return register also poses an issue because both data and address registers are integers, and only one integer register group is selectable in the default analysis. To overcome this, the function recognizer for TriCore identifies the return pattern for returning with an address register and corrects the function’s calling convention.
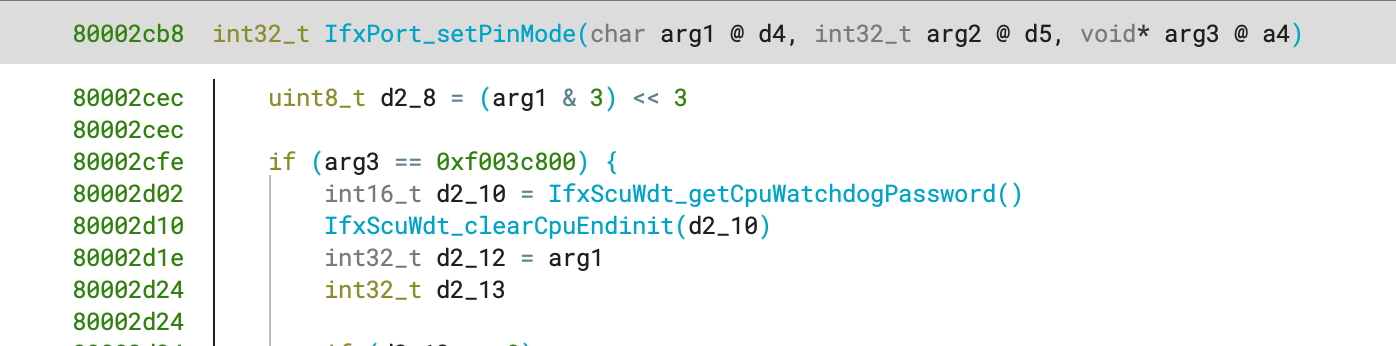
While lifting this architecture, it quickly became apparent that we would need to emit optimized lift variants where possible. As compilers generate more efficient sequences of instructions, the operations chosen might have a more complex semantic lift. To address this issue, we identify and solve for constants, eliminating noise before insertion into Lifted IL. For example, we have added four different optimized lift variants for the INSERT operation to cover cases such as when the width of the insert is 0, where the instruction is used just as a mask.
Before INSERT simplification:
d15 = (d15 & 0xffffbfff) | (1 << 0xe & 0)
After INSERT simplification:
While you can often rely on simplifications in higher IL levels, doing so can cause LLIL to become bloated with unnecessary and harder-to-comprehend patterns, both for the reverser and later automated analysis.
SVD Mapper
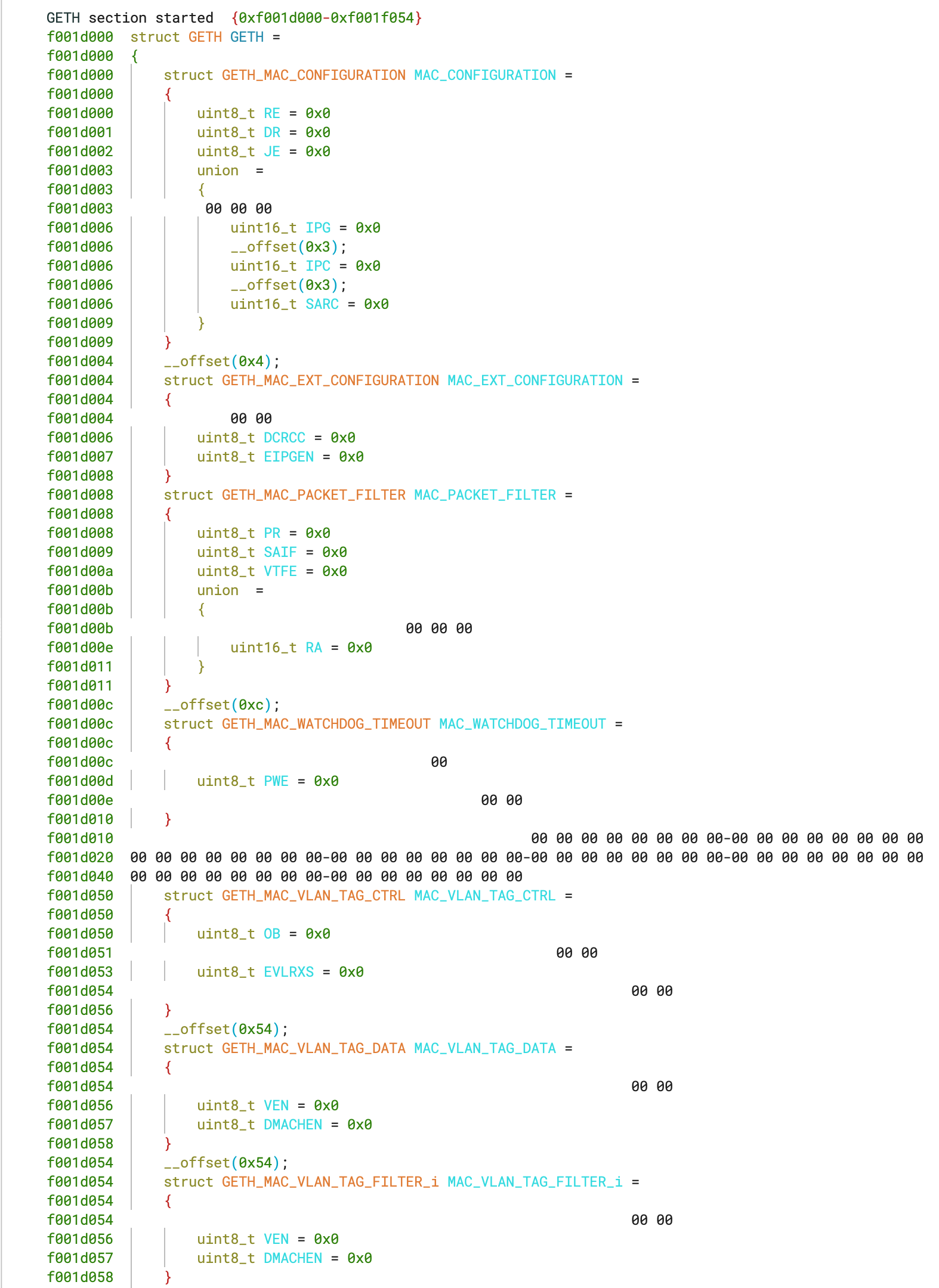
Understanding memory-mapped I/O (MMIO) access patterns and identifying their usage is crucial in firmware reverse engineering. Vendors like Infineon offer SVD files that outline the memory regions and structure of MMIO peripherals. By enabling Binary Ninja to load these SVD files with the new SVD loader plugin, memory regions are added to the view with peripheral structures populated, significantly improving analysis.
The information is mapped in and structured like below.
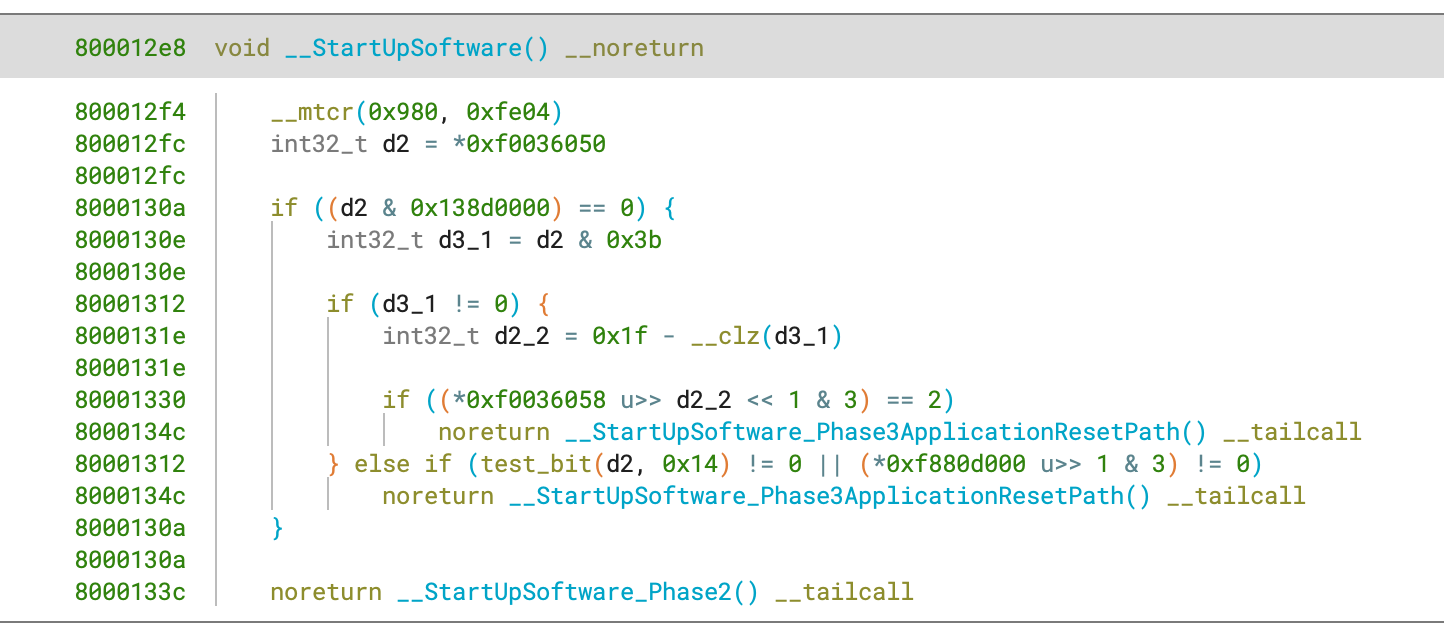
Using this information results in some nice analysis improvements:
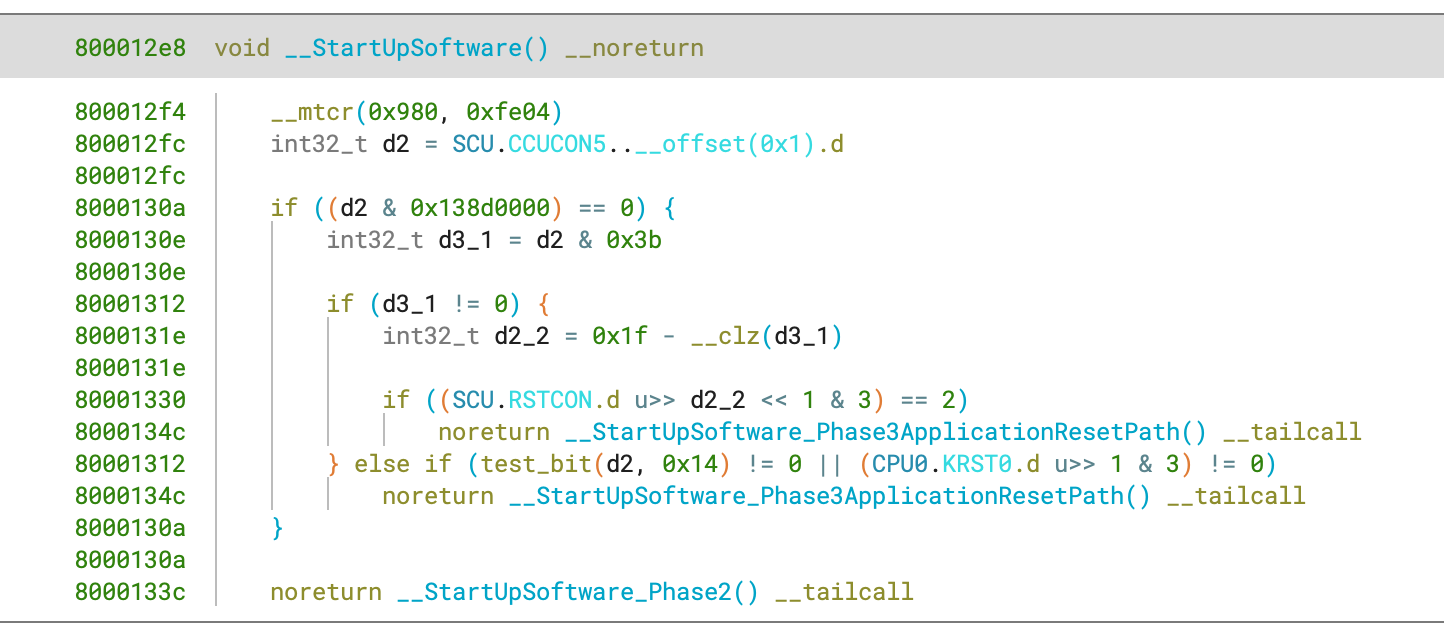
This plugin is available to all customers through the Plugin Manager as “SVD Mapper” and the source code is available under an Apache 2.0 license.
Try it out now!
If you are on the Ultimate dev branch you should already have access to TriCore (as well as C-SKY and nanoMIPS!), so go ahead and try it out! If you have any feedback on how we can improve, please let us know.
如有侵权请联系:admin#unsafe.sh