
Eli Bendersky 2024年9月12日
随着过去一年大型语言模型(LLM)及其相关工具(如嵌入模型)的能力显著增长,越来越多的开发者开始考虑将 LLM 集成到他们的应用程序中。

由 于LLM 通常需要专用硬件和大量的计算资源,它们最常见的形式是作为提供 API 访问的网络服务。这就是领先的 LLM 如 OpenAI 或Google Gemini 的 API 的工作方式;即使是运行你自己的 LLM 工具,如 Ollama,也会将 LLM 包装在 REST API 中供本地使用。此外,利用 LLM 的开发者通常还需要辅助工具,如向量数据库,这些通常也作为网络服务部署。
换句话说,LLM 驱动的应用程序很像其他现代云原生应用程序:它们需要对 REST 和 RPC 协议、并发性和性能有出色的支持。这些恰好是Go 擅长的领域,使它成为编写 LLM 驱动应用程序的绝佳语言。
这篇博客文章通过一个简单的例子,展示了如何使用 Go 为 LLM 驱动的应用程序工作。它首先描述了演示应用程序要解决的问题,然后展示了几个变体的应用程序,它们都完成了相同的任务,但使用了不同的包来实现。这篇帖子的所有演示代码都可以在线获取。
用于问答的 RAG 服务器
LLM 驱动应用程序的一种常见技术是 RAG - Retrieval Augmented Generation。RAG 是为特定领域的交互定制 LLM 知识库的最可扩展方式之一。
我们将用 Go 构建一个 RAG 服务器。这是一个 HTTP 服务器,为用户提供两个操作:
- 向知识库添加文档
- 向 LLM 提问有关这个知识库的问题
在典型的现实世界场景中,用户会向服务器添加一批文档,然后开始提问。例如,一家公司可以用内部文档填充 RAG 服务器的知识库,并使用它为内部用户提供 LLM 驱动的问答能力。
以下是显示我们服务器与外部世界交互的图:
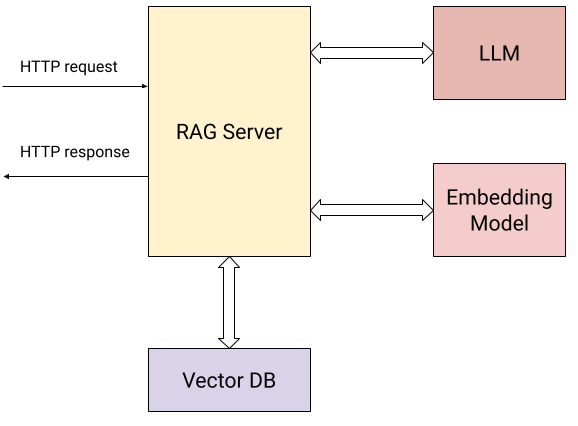
除了用户发送 HTTP 请求(上述两个操作)之外,服务器还与以下内容交互:
- 一个嵌入模型,用于计算提交的文档和用户问题的向量嵌入。
- 一个向量数据库,用于存储和高效检索嵌入。
一个 LLM,用于根据从知识库收集的上下文提出问题。
具体来说,服务器向用户公开两个HTTP端点:/add/: POST {“documents”: [{“text”: “…”}, {“text”: “…”}, …]}: 向服务器提交一系列文本文档,以便添加到其知识库中。对于此请求,服务器:
- 使用嵌入模型为每个文档计算向量嵌入。
- 将文档及其向量嵌入存储在向量数据库中。
- /query/: POST {“content”: “…”}: 向服务器提交一个问题。对于此请求,服务器:
- 使用嵌入模型计算问题的向量嵌入。
- 使用向量数据库的相似性搜索找到知识库中最相关文档。
- 使用简单的提示工程将问题重新表述为在步骤(2)中找到的最相关文档作为上下文,并将其发送给LLM,将答案返回给用户。
我们的演示使用的服务包括:
- Google Gemini API 用于 LLM 和嵌入模型。
- Weaviate 作为本地托管的向量数据库;Weaviate 是一个用 Go 实现的开源向量数据库。
- 应该很容易用其他等效服务替换这些。事实上,这就是第二个和第三个服务器变体的全部内容!我们将从直接使用这些工具的第一个变体开始。
直接使用 Gemini API 和 Weaviate
Gemini API 和 Weaviate 都有方便的 Go SDK(客户端库),我们的第一个服务器变体直接使用这些。这个变体的完整代码在这个目录中。
我们不会在这篇博客文章中复制整个代码,但在阅读时请注意以下几点:
- 结构:代码结构对于任何写过Go HTTP服务器的人来说都很熟悉。Gemini和Weaviate的客户端库被初始化,客户端存储在传递给HTTP处理程序的状态值中。
路由注册:使用 Go 1.22 中引入的路由增强功能,我们的服务器的 HTTP 路由很容易设置:
1
2
3mux := http.NewServeMux()
mux.HandleFunc("POST /add/", server.addDocumentsHandler)
mux.HandleFunc("POST /query/", server.queryHandler)并发性:我们的服务器的 HTTP 处理程序通过网络访问其他服务并等待响应。这对 Go 来说不是问题,因为每个 HTTP 处理程序都在自己的 goroutine 中并发运行。这个 RAG 服务器可以处理大量并发请求,每个处理程序的代码都是线性和同步的。
- 批量 API:由于 /add/ 请求可能提供大量文档添加到知识库,服务器利用嵌入(embModel.BatchEmbedContents)和 Weaviate DB(rs.wvClient.Batch)的批量 API 以提高效率。
使用 LangChainGo
我们的第二个 RAG 服务器变体使用 LangChainGo 来完成相同的任务。
LangChain 是一个流行的 Python 框架,用于构建 LLM 驱动的应用程序。LangChainGo 是它的 Go 框架。该框架有一些工具,可以将应用程序构建为模块化组件,并支持许多 LLM 提供商和向量数据库的通用 API。这允许开发者编写可以与任何提供商一起工作的代码,并很容易地更改提供商。
这个变体的完整代码在这个目录中。在阅读代码时,你会注意到两件事:
- 首先,它比之前的变体稍短。LangChainGo 负责包装向量数据库的完整 API 到通用接口中,初始化和处理 Weaviate 所需的代码更少。
- 其次,LangChainGo API 使得切换提供商相当容易。假设我们想用另一个向量数据库替换 Weaviate;在我们之前的变体中,我们将不得不重写所有与向量数据库接口的代码以使用新的 API。有了像 LangChainGo 这样的框架,我们就不再需要这样做了。只要 LangChainGo 支持我们感兴趣的新向量数据库,我们应该能够替换我们服务器中的几行代码,因为所有数据库都实现了一个通用接口:
1
2
3
4type VectorStore interface {
AddDocuments(ctx context.Context, docs []schema.Document, options ...Option) ([]string, error)
SimilaritySearch(ctx context.Context, query string, numDocuments int, options ...Option) ([]schema.Document, error)
}
使用 Genkit for Go
今年早些时候,Google 为 Go 引入了 Genkit - 一个构建 LLM 驱动应用程序的新开源框架。Genkit 与 LangChain 有一些共同的特点,但在其他方面有所不同。
像LangChain一样,它提供了可以由不同提供商(作为插件)实现的通用接口,从而使从一个提供商切换到另一个提供商变得更简单。然而,它并不试图规定不同的LLM组件如何交互;相反,它专注于生产特性,如提示管理和工程,以及集成开发工具的部署。
我们的第三个RAG服务器变体使用Genkit for Go来完成相同的任务。它的完整代码在这个目录中。
这个变体与LangChainGo非常相似 - 使用LLM、嵌入器和向量数据库的通用接口,而不是直接提供商API,使得从一个切换到另一个变得更容易。此外,使用Genkit将LLM驱动的应用程序部署到生产环境要容易得多;我们没有在我们的变体中实现这一点,但如果你感兴趣,可以阅读文档。
总结 - Go 用于 LLM 驱动的应用程序
这篇文章中的示例只是构建 Go 中 LLM 驱动应用程序的可能性的一小部分。它展示了如何用相对较少的代码构建一个功能强大的 RAG 服务器;最重要的是,由于 Go 的一些基本特性,这些示例具有相当程度的生产准备度。
与LLM服务合作通常意味着向网络服务发送 REST 或 RPC 请求,等待响应,根据该响应向其他服务发送新请求等等。Go 在所有这些方面都表现出色,为管理并发性和处理网络服务的复杂性提供了出色的工具。
此外,Go 作为云原生语言的卓越性能和可靠性使其成为实现 LLM 生态系统更基本构建块的自然选择。一些例子包括 Ollama、LocalAI、Weaviate 或 Milvus 等项目。
