2024-9-25 20:30:20 Author: hackernoon.com(查看原文) 阅读量:5 收藏
Authors:
(1) Chengrun Yang, Google DeepMind and Equal contribution;
(2) Xuezhi Wang, Google DeepMind;
(3) Yifeng Lu, Google DeepMind;
(4) Hanxiao Liu, Google DeepMind;
(5) Quoc V. Le, Google DeepMind;
(6) Denny Zhou, Google DeepMind;
(7) Xinyun Chen, Google DeepMind and Equal contribution.
Table of Links
2 Opro: Llm as the Optimizer and 2.1 Desirables of Optimization by Llms
3 Motivating Example: Mathematical Optimization and 3.1 Linear Regression
3.2 Traveling Salesman Problem (TSP)
4 Application: Prompt Optimization and 4.1 Problem Setup
5 Prompt Optimization Experiments and 5.1 Evaluation Setup
5.4 Overfitting Analysis in Prompt Optimization and 5.5 Comparison with Evoprompt
7 Conclusion, Acknowledgments and References
B Prompting Formats for Scorer Llm
C Meta-Prompts and C.1 Meta-Prompt for Math Optimization
C.2 Meta-Prompt for Prompt Optimization
D Prompt Optimization Curves on the Remaining Bbh Tasks
E Prompt Optimization on Bbh Tasks – Tabulated Accuracies and Found Instructions
E PROMPT OPTIMIZATION ON BBH TASKS – TABULATED ACCURACIES AND FOUND INSTRUCTIONS
E.1 PALM 2-L-IT AS OPTIMIZER, OPTIMIZATION STARTING FROM THE EMPTY STRING
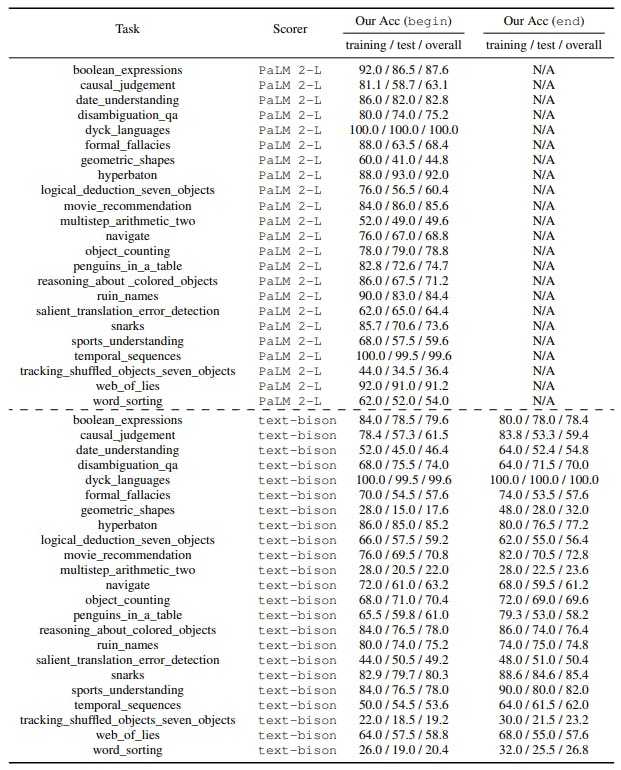
Table 8 and 9 show the instructions found by prompt optimization. A comparison of their accuracies with baselines “Let’s think step by step.” (Kojima et al., 2022), “Let’s work this out in a step by step way to be sure we have the right answer.” (Zhou et al., 2022b), and the empty string is in Table 7; a visualization is in Section 5.2 Figure 5.



E.2 G P T-3.5-T U R B O AS OPTIMIZER, OPTIMIZATION STARTING FROM THE EMPTY STRING
Table 11, 12 and 13 show the instructions found by prompt optimization. Their accuracies are listed in Table 10. Figure 25 visualizes the difference between their accuracies and those of the baselines “Let’s think step by step.” and the empty string. The optimizations find instructions better than the empty starting point, and most of the found instructions are better than “Let’s think step by step”.
One caveat in the A_begin instructions (Table 11) is that a lot of the found instructions are imperative or interrogative sentences that are more suitable to be put into “Q:” rather than “A:”, like “Solve the sequence by properly closing the parentheses.” for dyck_languages and “Which movie option from the given choices ...?” for movie_recommendation. Such styles appear more often here than the PaLM 2-L-IT optimizer results (Table 8), showing PaLM 2-L-IT understands the needed style better. In Section E.3, we show the A_begin optimization results with the non-empty starting point “Let’s solve the problem.”. Most results there are declarative sentences – more suitable for A_begin.





E.3 PALM 2-L AS SCORER, G P T-3.5-T U R B O AS OPTIMIZER, OPTIMIZATION STARTING FROM “LET’S SOLVE THE PROBLEM.”
Figure 26 and Table 14 compare the accuracies of found instructions vs “Let’s solve the problem.”, “Let’s think step by step.”, and the instructions in Table 11. Table 15 details the found instructions.
The “Let’s” pattern appears more often in the found instructions because of the starting points, and the instructions are more often declarative that are more suitable for A_begin, even if some are semantically far from “Let’s solve the problem”. In fact, “Let’s” was adopted by Zhou et al. (2022b) as a fixed pattern in generated prompts, possibly because of the same reason.



如有侵权请联系:admin#unsafe.sh