2024-09-27
16 min read

We’ve been working on something new — a platform for running containers across Cloudflare’s network. We already use it in production for Workers AI, Workers Builds, Remote Browsing Isolation, and the Browser Rendering API. Today, we want to share an early look at how it’s built, why we built it, and how we use it ourselves.
In 2024, Cloudflare Workers celebrates its 7th birthday. When we first announced Workers, it was a completely new model for running compute in a multi-tenant way — on isolates, as opposed to containers. While, at the time, Workers was a pretty bare-bones functions-as-a-service product, we took a big bet that this was going to become the way software was going to be written going forward. Since introducing Workers, in addition to expanding our developer products in general to include storage and AI, we have been steadily adding more compute capabilities to Workers:
With each of these, we’ve faced a question — can we build this natively into the platform, in a way that removes, rather than adds complexity? Can we build it in a way that lets developers focus on building and shipping, rather than managing infrastructure, so that they don’t have to be a distributed systems engineer to build distributed systems?
In each instance, the answer has been YES. We try to solve problems in a way that simplifies things for developers in the long run, even if that is the harder path for us to take ourselves. If we didn’t, you’d be right to ask — why not self-host and manage all of this myself? What’s the point of the cloud if I’m still provisioning and managing infrastructure? These are the questions many are asking today about the earlier generation of cloud providers.
Pushing ourselves to build platform-native products and features helped us answer this question. Particularly because some of these actually use containers behind the scenes, even though as a developer you never interact with or think about containers yourself.
If you’ve used AI inference on GPUs with Workers AI, spun up headless browsers with Browser Rendering, or enqueued build jobs with the new Workers Builds, you’ve run containers on our network, without even knowing it. But to do so, we needed to be able to run untrusted code across Cloudflare’s network, outside a v8 isolate, in a way that fits what we promise:
You shouldn’t have to think about regions or data centers. Routing, scaling, load balancing, scheduling, and capacity are our problem to solve, not yours, with tools like Smart Placement.
You should be able to build distributed systems without being a distributed systems engineer.
Every millisecond matters — Cloudflare has to be fast.
There wasn’t an off-the-shelf container platform that solved for what we needed, so we built it ourselves — from scheduling to IP address management, pulling and caching images, to improving startup times and more. Our container platform powers many of our newest products, so we wanted to share how we built it, optimized it, and well, you can probably guess what’s next.
Global scheduling — “The Network is the Computer”
Cloudflare serves the entire world — region: earth. Rather than asking developers to provision resources in specific regions, data centers and availability zones, we think “The Network is the Computer”. When you build on Cloudflare, you build software that runs on the Internet, not just in a data center.
When we started working on this, Cloudflare’s architecture was to just run every service via systemd on every server (we call them “metals” — we run our own hardware), allowing all services to take advantage of new capacity we add to our network. That fits running NGINX and a few dozen other services, but cannot fit a world where we need to run many thousands of different compute heavy, resource hungry workloads. We’d run out of space just trying to load all of them! Consider a canonical AI workload — deploying Llama 3.1 8B to an inference server. If we simply ran a Llama 3.1 8B service on every Cloudflare metal, we’d have no flexibility to use GPUs for the many other models that Workers AI supports.
We needed something that would allow us to still take advantage of the full capacity of Cloudflare’s entire network, not just the capacity of individual machines. And ideally not put that burden on the developer.
The answer: we built a control plane on our own Developer Platform that lets us schedule a container anywhere on Cloudflare’s Network:
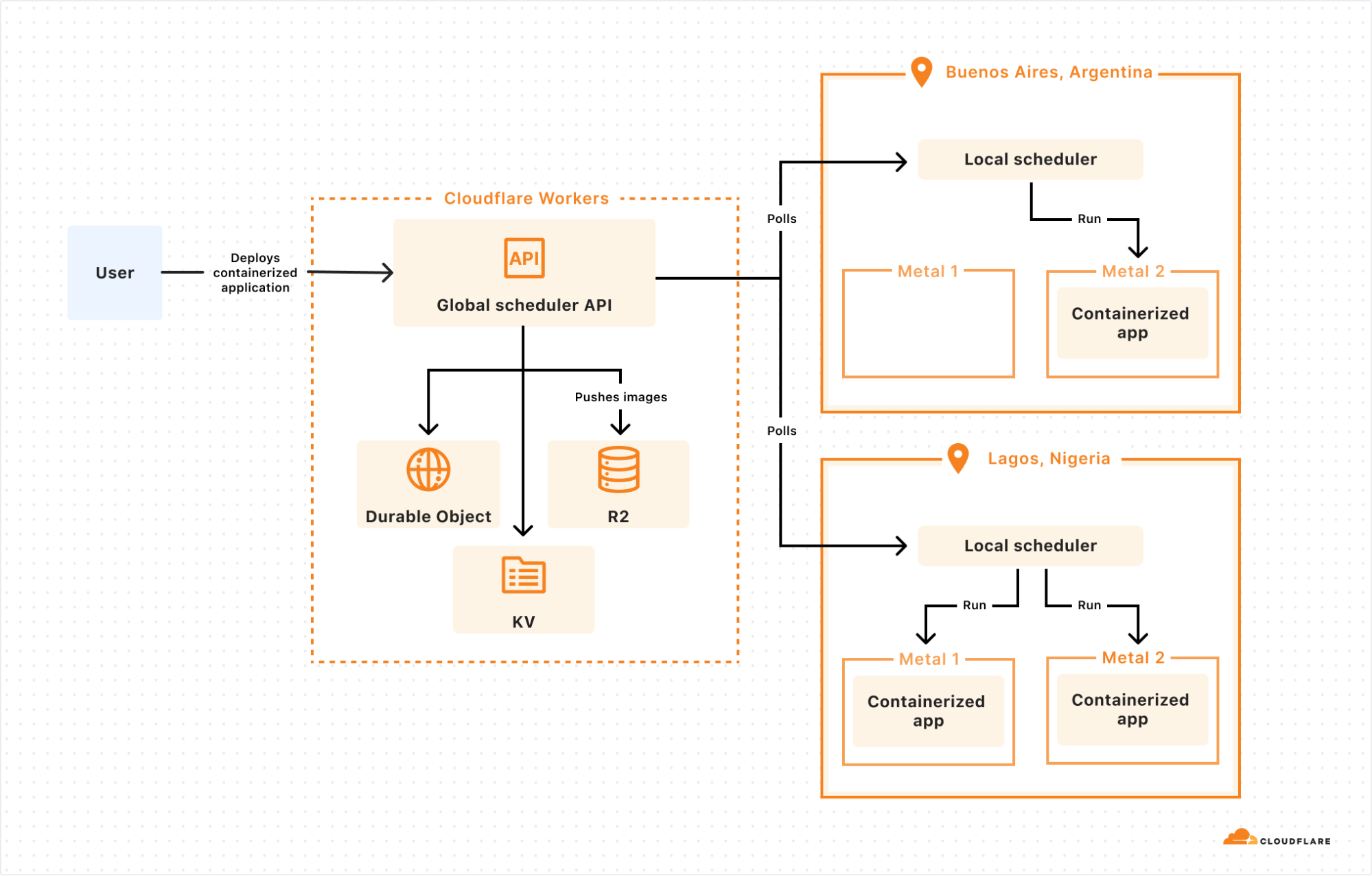
The global scheduler is built on Cloudflare Workers, Durable Objects, and KV, and decides which Cloudflare location to schedule the container to run in. Each location then runs its own scheduler, which decides which metals within that location to schedule the container to run on. Location schedulers monitor compute capacity, and expose this to the global scheduler. This allows Cloudflare to dynamically place workloads based on capacity and hardware availability (e.g. multiple types of GPUs) across our network.
Why does global scheduling matter?
When you run compute on a first generation cloud, the “contract” between the developer and the platform is that the developer must specify what runs where. This is regional scheduling, the status quo.
Let’s imagine for a second if we applied regional scheduling to running compute on Cloudflare’s network, with locations in 330+ cities, across 120+ countries. One of the obvious reasons people tell us they want to run on Cloudflare is because we have compute in places where others don’t, within 50ms of 95% of the world’s Internet-connected population. In South America, other clouds have one region in one city. Cloudflare has 19:
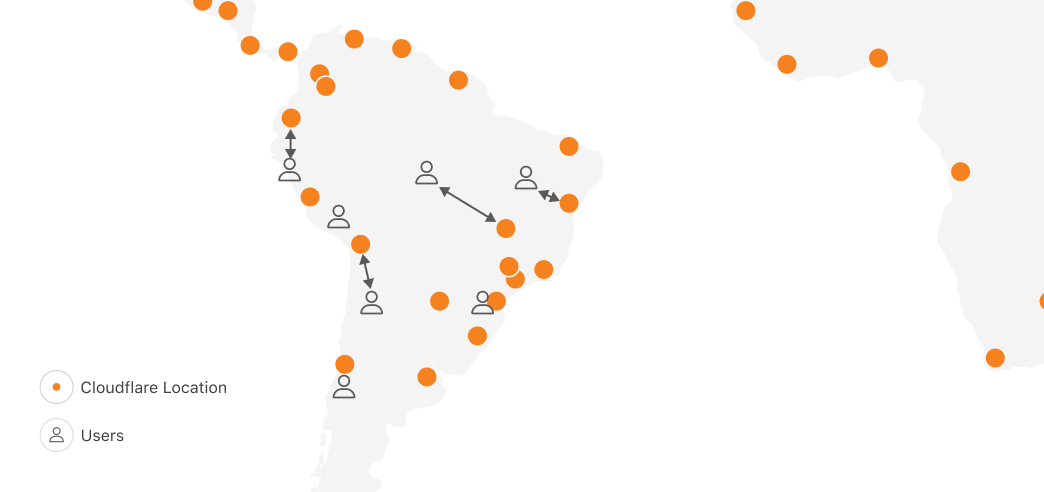
Running anywhere means you can be faster, highly available, and have more control over data location. But with regional scheduling, the more locations you run in, the more work you have to do. You configure and manage load balancing, routing, auto-scaling policies and more. Balancing performance and cost in a multi-region setup is literally a full-time job (or more) at most companies who have reached meaningful scale on traditional clouds.
But most importantly, no matter what tools you bring, you were the one who told the cloud provider, “run this container over here”. The cloud platform can’t move it for you, even if moving it would make your workload faster. This prevents the platform from adding locations, because for each location, it has to convince developers to take action themselves to move their compute workloads to the new location. Each new location carries a risk that developers won’t migrate workloads to it, or migrate too slowly, delaying the return on investment.
Global scheduling means Cloudflare can add capacity and use it immediately, letting you benefit from it. The “contract” between us and our customers isn’t tied to a specific datacenter or region, so we have permission to move workloads around to benefit customers. This flexibility plays an essential role in all of our own uses of our container platform, starting with GPUs and AI.
GPUs everywhere: Scheduling large images with Workers AI
In late 2023, we launched Workers AI, which provides fast, easy to use, and affordable GPU-backed AI inference.
The more efficiently we can use our capacity, the better pricing we can offer. And the faster we can make changes to which models run in which Cloudflare locations, the closer we can move AI inference to the application, lowering Time to First Token (TTFT). This also allows us to be more resilient to spikes in inference requests.
AI models that rely on GPUs present three challenges though:
Models have different GPU memory needs. GPU memory is the most scarce resource, and different GPUs have different amounts of memory.
Not all container runtimes, such as Firecracker, support GPU drivers and other dependencies.
AI models, particularly LLMs, are very large. Even a smaller parameter model, like @cf/meta/llama-3.1-8b-instruct, is at least 5 GB. The larger the model, the more bytes we need to pull across the network when scheduling a model to run in a new location.
Let’s dive into how we solved each of these…
First, GPU memory needs. The global scheduler knows which Cloudflare locations have blocks of GPU memory available, and then delegates scheduling the workload on a specific metal to the local scheduler. This allows us to prioritize placement of AI models that use a large amount of GPU memory, and then move smaller models to other machines in the same location. By doing this, we maximize the overall number of locations that we run AI models in, and maximize our efficiency.
Second, container runtimes and GPU support. Thankfully, from day one we built our container platform to be runtime agnostic. Using a runtime agnostic scheduler, we’re able to support gVisor, Firecracker microVMs, and traditional VMs with QEMU. We are also evaluating adding support for another one: cloud-hypervisor which is based on rust-vmm and has a few compelling advantages for our use case:
GPU passthrough support using VFIO
vhost-user-net support, enabling high throughput between the host network interface and the VM
vhost-user-blk support, adding flexibility to introduce novel network-based storage backed by other Cloudflare Workers products
all the while being a smaller codebase than QEMU and written in a memory-safe language
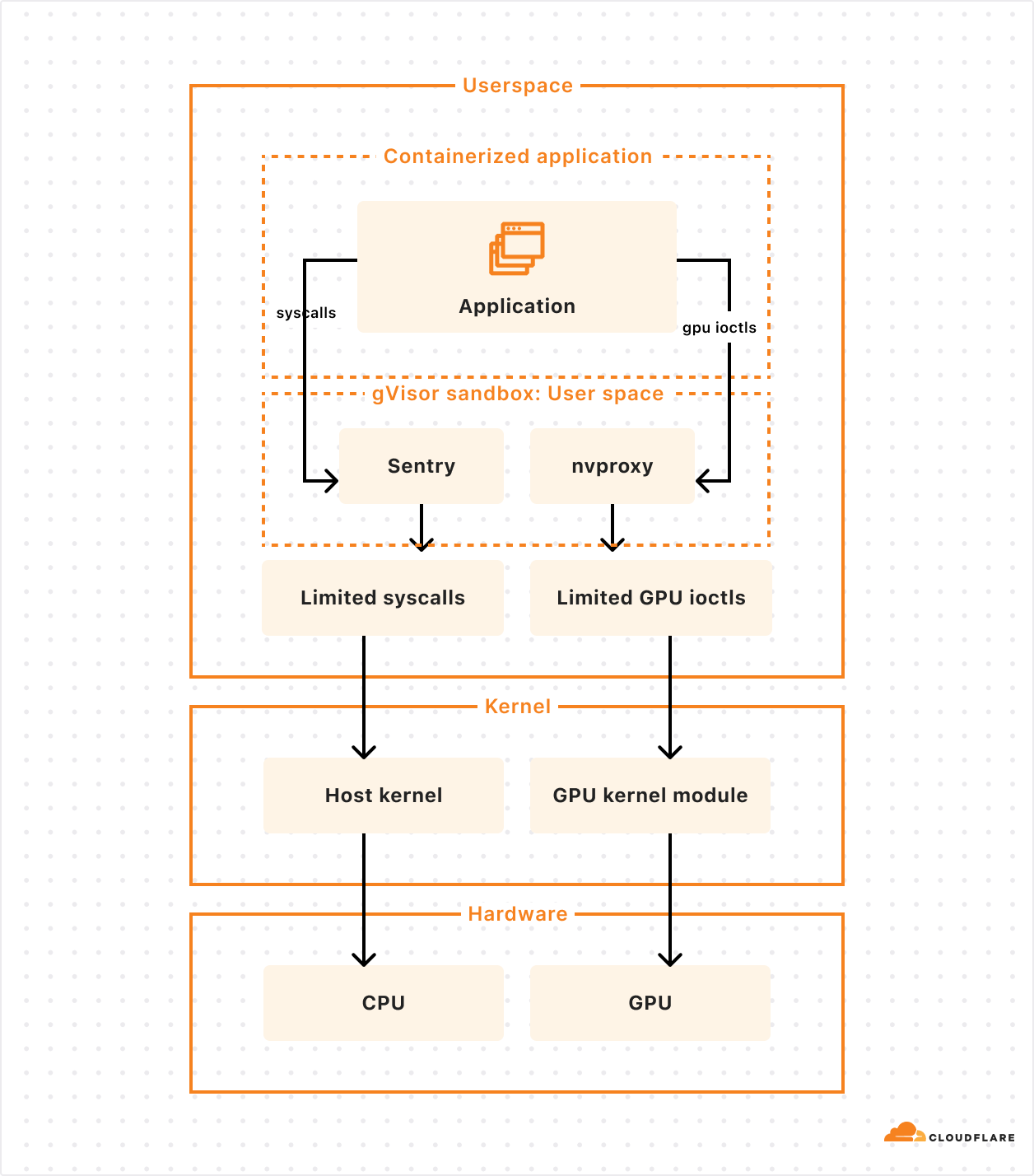
Our goal isn’t to build a platform that makes you as the developer choose between runtimes, and ask, “should I use Firecracker or gVisor”. We needed this flexibility in order to be able to run workloads with different needs efficiently, including workloads that depend on GPUs. gVisor has GPU support, while Firecracker microVMs currently does not.
gVisor’s main component is an application kernel (called Sentry) that implements a Linux-like interface but is written in a memory-safe language (Go) and runs in userspace. It works by intercepting application system calls and acting as the guest kernel, without the need for translation through virtualized hardware.
The resource footprint of a containerized application running on gVisor is lower than a VM because it does not require managing virtualized hardware and booting up a kernel instance. However, this comes at the price of reduced application compatibility and higher per-system call overhead.
To add GPU support, the Google team introduced nvproxy which works using the same principles as described above for syscalls: it intercepts ioctls destined to the GPU and proxies a subset to the GPU kernel module.
To solve the third challenge, and make scheduling fast with large models, we weren’t satisfied with the status quo. So we did something about it.
Docker pull was too slow, so we fixed it (and cut the time in half)
Many of the images we need to run for AI inference are over 15 GB. Specialized inference libraries and GPU drivers add up fast. For example, when we make a scheduling decision to run a fresh container in Tokyo, naively running docker pull to fetch the image from a storage bucket in Los Angeles would be unacceptably slow. And scheduling speed is critical to being able to scale up and down in new locations in response to changes in traffic.
We had 3 essential requirements:
Pulling and pushing very large images should be fast
We should not rely on a single point of failure
Our teams shouldn’t waste time managing image registries
We needed globally distributed storage, so we used R2. We needed the highest cache hit rate possible, so we used Cloudflare’s Cache, and will soon use Tiered Cache. And we needed a fast container image registry that we could run everywhere, in every Cloudflare location, so we built and open-sourced serverless-registry, which is built on Workers. You can deploy serverless-registry to your own Cloudflare account in about 5 minutes. We rely on it in production.
This is fast, but we can be faster. Our performance bottleneck was, somewhat surprisingly, docker push. Docker uses gzip to compress and decompress layers of images while pushing and pulling. So we started using Zstandard (zstd) instead, which compresses and decompresses faster, and results in smaller compressed files.
In order to build, chunk, and push these images to the R2 registry, we built a custom CLI tool that we use internally in lieu of running docker build and docker push. This makes it easy to use zstd and split layers into 500 MB chunks, which allows uploads to be processed by Workers while staying under body size limits.
Using our custom build and push tool doubled the speed of image pulls. Our 30 GB GPU images now pull in 4 minutes instead of 8. We plan on open sourcing this tool in the near future.
Anycast is the gift that keeps on simplifying — Virtual IPs and the Global State Router
We still had another challenge to solve. And yes, we solved it with anycast. We’re Cloudflare, did you expect anything else?
First, a refresher — Cloudflare operates Unimog, a Layer 4 load balancer that handles all incoming Cloudflare traffic. Cloudflare’s network uses anycast, which allows a single IP address to route requests to a variety of different locations. For most Cloudflare services with anycast, the given IP address will route to the nearest Cloudflare data center, reducing latency. Since Cloudflare runs almost every service in every data center, Unimog can simply route traffic to any Cloudflare metal that is online and has capacity, without needing to map traffic to a specific service that runs on specific metals, only in some locations.
The new compute-heavy, GPU-backed workloads we were taking on forced us to confront this fundamental “everything runs everywhere” assumption. If we run a containerized workflow in 20 Cloudflare locations, how does Unimog know which locations, and which metals, it runs in? You might say “just bring your own load balancer” — but then what happens when you make scheduling decisions to migrate a workload between locations, scale up, or scale down?
Anycast is foundational to how we build fast and simple products on our network, and we needed a way to keep building new types of products this way — where a team can deploy an application, get back a single IP address, and rely on the platform to balance traffic, taking load, container health, and latency into account, without extra configuration. We started letting teams use the container platform without solving this, and it was painfully clear that we needed to do something about it.
So we started integrating directly into our networking stack, building a sidecar service to Unimog. We’ll call this the Global State Router. Here’s how it works:
An eyeball makes a request to a virtual IP address issued by Cloudflare
Request sent to the best location as determined by BGP routing. This is anycast routing.
A small eBPF program sits on the main networking interface and ensures packets bound to a virtual IP address are handled by the Global State Router.
The main Global State Router program contains a mapping of all anycast IPs addresses to potential end destination container IP addresses. It updates this mapping based on container health, readiness, distance, and latency. Using this information, it picks a best-fit container.
Packets are forwarded at the L4 layer.
When a target container’s server receives a packet, its own Global State Router program intercepts the packet and routes it to the local container.
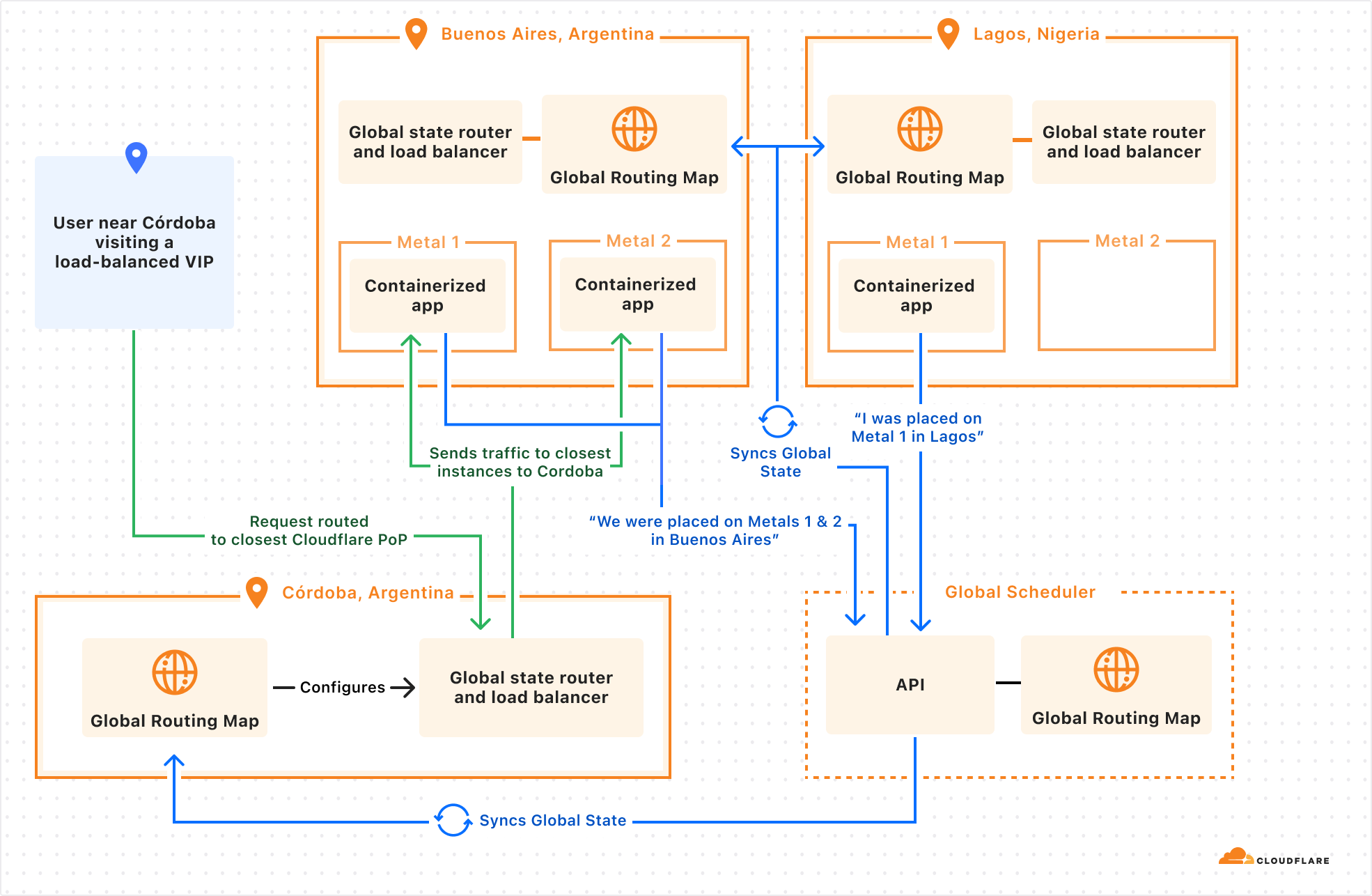
This might sound like just a lower level networking detail, disconnected from developer experience. But by integrating directly with Unimog, we can let developers:
Push a containerized application to Cloudflare.
Provide constraints, health checks, and load metrics that describe what the application needs.
Delegate scheduling and scaling many containers across Cloudflare’s network.
Get back a single IP address that can be used everywhere.
We’re actively working on this, and are excited to continue building on Cloudflare’s anycast capabilities, and pushing to keep the simplicity of running “everywhere” with new categories of workloads.
Low latency & global — Remote Browser Isolation & Browser Rendering
Our container platform actually started because of a very specific challenge, running Remote Browser Isolation across our network. Remote Browser Isolation provides Chromium browsers that run on Cloudflare, in containers, rather than on the end user’s own computer. Only the rendered output is sent to the end user. This provides a layer of protection against zero-day browser vulnerabilities, phishing attacks, and ransomware.
Location is critical — people expect their interactions with a remote browser to feel just as fast as if it ran locally. If the server is thousands of miles away, the remote browser will feel slow. Running across Cloudflare’s network of over 330 locations means the browser is nearly always as close to you as possible.
Imagine a user in Santiago, Chile, if they were to access a browser running in the same city, each interaction would incur negligible additional latency. Whereas a browser in Buenos Aires might add 21 ms, São Paulo might add 48 ms, Bogota might add 67 ms, and Raleigh, NC might add 128 ms. Where the container runs significantly impacts the latency of every user interaction with the browser, and therefore the experience as a whole.
It’s not just browser isolation that benefits from running near the user: WebRTC servers stream video better, multiplayer games have less lag, online advertisements can be served faster, financial transactions can be processed faster. Our container platform lets us run anything we need to near the user, no matter where they are in the world.
Using spare compute — “off-peak” jobs for Workers CI/CD builds
At any hour of the day, Cloudflare has many CPU cores that sit idle. This is compute power that could be used for something else.
Via anycast, most of Cloudflare’s traffic is handled as close as possible to the eyeball (person) that requested it. Most of our traffic originates from eyeballs. And the eyeballs of (most) people are closed and asleep between midnight and 5:00 AM local time. While we use our compute capacity very efficiently during the daytime in any part of the world, overnight we have spare cycles. Consider what a map of the world looks like at night-time in Europe and Africa:
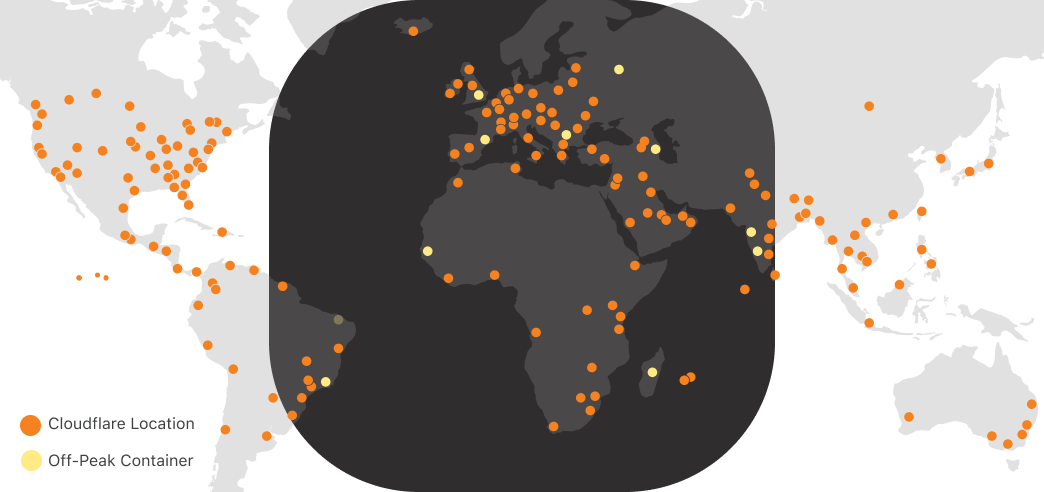
As shown above, we can run containers during “off-peak” in Cloudflare locations receiving low traffic at night. During this time, the CPU utilization of a typical Cloudflare metal looks something like this:
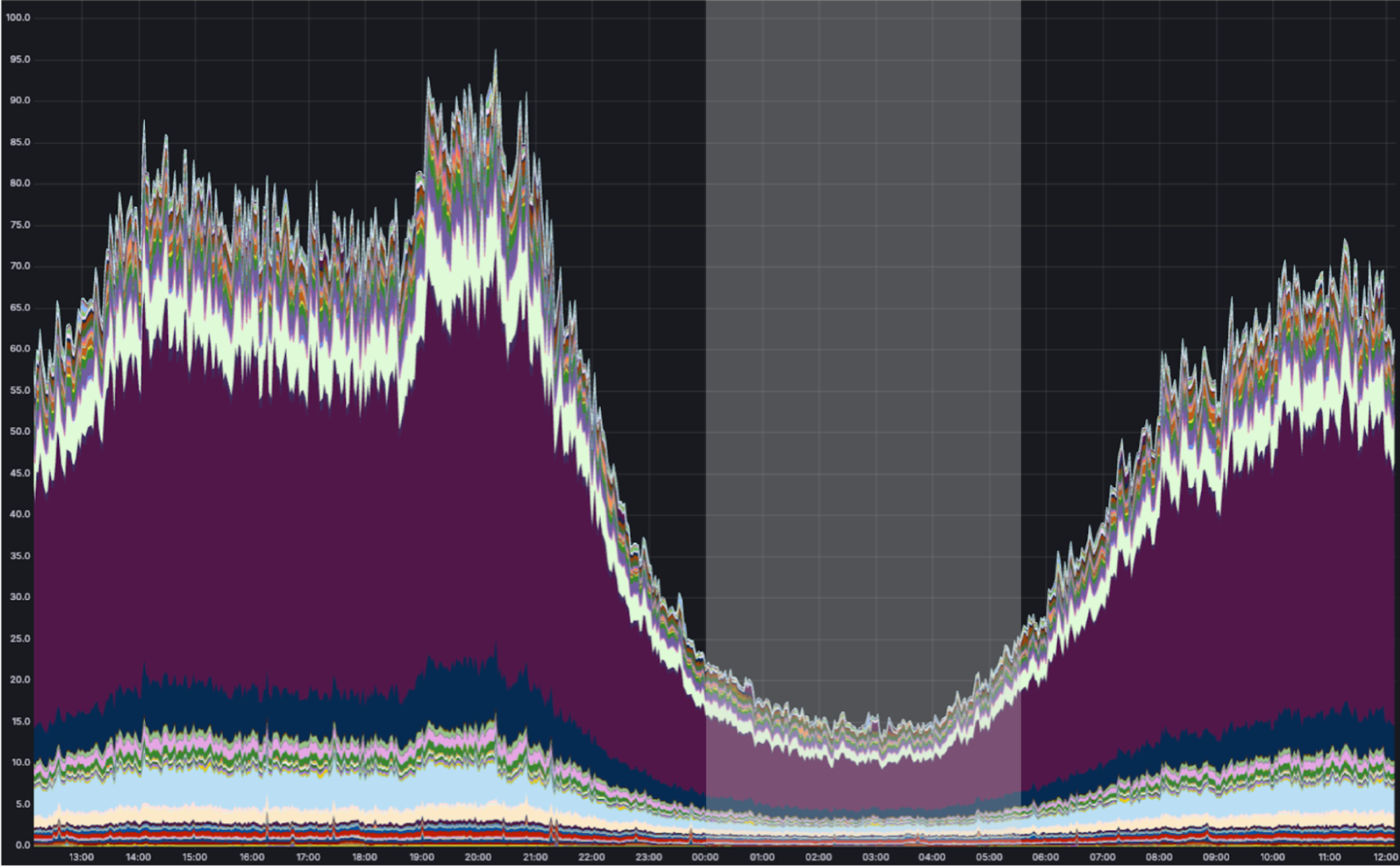
We have many “background” compute workloads at Cloudflare. These are workloads that don’t actually need to run close to the eyeball because there is no eyeball waiting on the request. The challenge is that many of these workloads require running untrusted code — either a dependency on open-source code that we don’t trust enough to run outside of a sandboxed environment, or untrusted code that customers deploy themselves. And unlike Cron Triggers, which already make a best-effort attempt to use off-peak compute, these other workloads can’t run in v8 isolates.
On Builder Day 2024, we announced Workers Builds in open beta. You connect your Worker to a git repository, and Cloudflare builds and deploys your Worker each time you merge a pull request. Workers Builds run on our containers platform, using otherwise idle “off-peak” compute, allowing us to offer lower pricing, and hold more capacity for unexpected spikes in traffic in Cloudflare locations during daytime hours when load is highest. We preserve our ability to serve requests as close to the eyeball as possible where it matters, while using the full compute capacity of our network.
We developed a purpose-built API for these types of jobs. The Workers Builds service has zero knowledge of where Cloudflare has spare compute capacity on its network — it simply schedules an “off-peak” job to run on the containers platform, by defining a scheduling policy:
scheduling_policy: "off-peak"
Making off-peak jobs faster with prewarmed images
Just because a workload isn’t “eyeball-facing” doesn’t mean speed isn’t relevant. When a build job starts, you still want it to start as soon as possible.
Each new build requires a fresh container though, and we must avoid reusing containers to provide strong isolation between customers. How can we keep build job start times low, while using a new container for each job without over-provisioning?
We prewarm servers with the proper image.
Before a server becomes eligible to receive an “off peak” job, the container platform instructs it to download the correct image. Once the image is downloaded and cached locally, new containers can start quickly in a Firecracker VM after receiving a request for a new build. When a build completes, we throw away the container, and start the next build using a fresh container based on the prewarmed image.
Without prewarming, pulling and unpacking our Workers Build images would take roughly 75 seconds. With prewarming, we’re able to spin up a new container in under 10 seconds. We expect this to get even faster as we introduce optimizations like pre-booting images before new runs, or Firecracker snapshotting, which can restore a VM in under 200ms.
Workers and containers, better together
As more of our own engineering teams rely on our containers platform in production, we’ve noticed a pattern: they want a deeper integration with Workers.
We plan to give it to them.
Let’s take a look at a project deployed on our container platform already, Key Transparency. If the container platform were highly integrated with Workers, what would this team’s experience look like?
Cloudflare regularly audits changes to public keys used by WhatsApp for encrypting messages between users. Much of the architecture is built on Workers, but there are long-running compute-intensive tasks that are better suited for containers.
We don’t want our teams to have to jump through hoops to deploy a container and integrate with Workers. They shouldn’t have to pick specific regions to run in, figure out scaling, expose IPs and handle IP updates, or set up Worker-to-container auth.
We’re still exploring many different ideas and API designs, and we want your feedback. But let’s imagine what it might look like to use Workers, Durable Objects and Containers together.
In this case, an outer layer of Workers handles most business logic and ingress, a specialized Durable Object is configured to run alongside our new container, and the platform ensures the image is loaded on the right metals and can scale to meet demand.
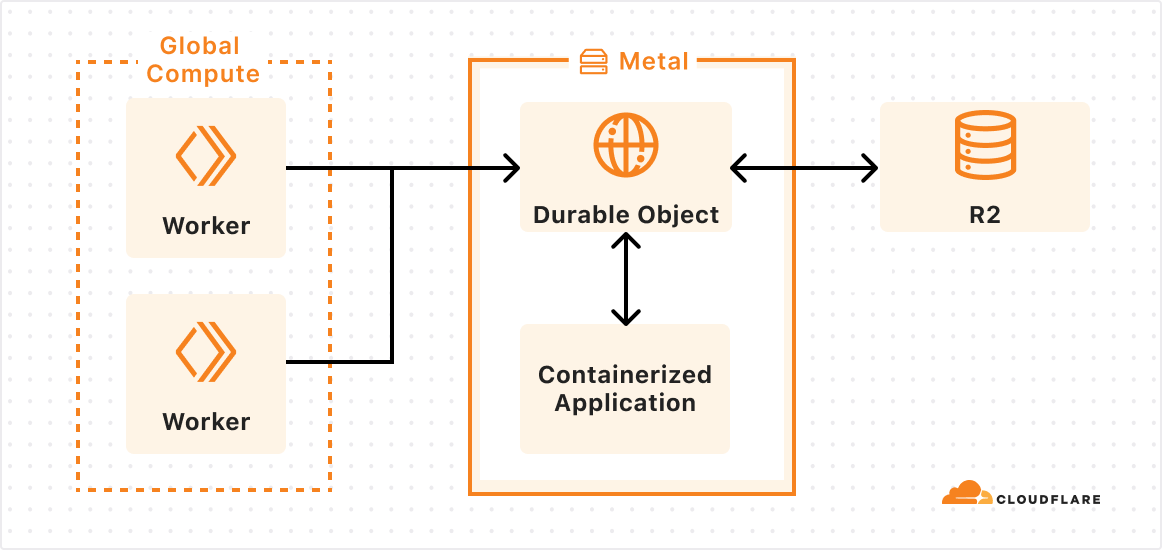
I add a containerized app to the wrangler.toml configuration file of my Worker (or Terraform):
[[container-app]]
image = "./key-transparency/verifier/Dockerfile"
name = "verifier"
[durable_objects]
bindings = { name = "VERIFIER", class_name = "Verifier", container = "verifier" } }
Then, in my Worker, I call the runVerification RPC method of my Durable Object:
fetch(request, env, ctx) {
const id = new URL(request.url).searchParams.get('id')
const durableObjectId = env.VERIFIER.idFromName(request.params.id);
await env.VERIFIER.get(durableObjectId).runVerification()
//...
}
From my Durable Object I can boot, configure, mount storage buckets as directories, and make HTTP requests to the container:
class Verifier extends DurableObject {
constructor(state, env) {
this.ctx.blockConcurrency(async () => {
// starts the container
await this.ctx.container.start();
// configures the container before accepting traffic
const config = await this.state.storage.get("verifierConfig");
await this.ctx.container.fetch("/set-config", { method: "PUT", body: config});
})
}
async runVerification(updateId) {
// downloads & mounts latest updates from R2
const latestPublicKeyUpdates = await this.env.R2.get(`public-key-updates/${updateId}`);
await this.ctx.container.mount(`/updates/${updateId}`, latestPublicKeyUpdates);
// starts verification via HTTP call
return await this.ctx.container.fetch(`/verifier/${updateId}`);
}
}
And… that’s it.
I didn’t have to worry about placement, scaling, service discovery authorization, and I was able to leverage integrations into other services like KV and R2 with just a few lines of code. The container platform took care of routing, placement, and auth. If I needed more instances, I could call the binding with a new ID, and the platform would scale up containers for me.
We are still in the early stages of building these integrations, but we’re excited about everything that containers will bring to Workers and vice versa.
So, what do you want to build?
If you’ve read this far, there’s a non-zero chance you were hoping to get to run a container yourself on our network. While we’re not ready (quite yet) to open up the platform to everyone, now that we’ve built a few GA products on our container platform, we’re looking for a handful of engineering teams to start building, in advance of wider availability in 2025. And we’re continuing to hire engineers to work on this.
We’ve told you about our use cases for containers, and now it’s your turn. If you’re interested, tell us here what you want to build, and why it goes beyond what’s possible today in Workers and on our Developer Platform. What do you wish you could build on Cloudflare, but can’t yet today?
Cloudflare's connectivity cloud protects entire corporate networks, helps customers build Internet-scale applications efficiently, accelerates any website or Internet application, wards off DDoS attacks, keeps hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.