一
去花!
IDA简单分析
unidbg模拟执行
public class SecurityUtil extends AbstractJni {
private final AndroidEmulator emulator;
private final VM vm;
private final Module module;
private final DvmObject NativeLibHelper;SecurityUtil() {
emulator = AndroidEmulatorBuilder.for32Bit()
.setProcessName("xxxxx.android.xxxx") //你懂的
.addBackendFactory(new Unicorn2Factory(true))
.build(); // 创建模拟器实例,要模拟32位或者64位,在这里区分final Memory memory = emulator.getMemory(); // 模拟器的内存操作接口
memory.setLibraryResolver(new AndroidResolver(23)); // 设置系统类库解析
vm = emulator.createDalvikVM();
vm.setVerbose(true); // 设置是否打印Jni调用细节
vm.setJni(this);
new AndroidModule(emulator, vm).register(memory);DalvikModule dm = vm.loadLibrary(new File("libxxmain.so"), true); //
module = dm.getModule();dm.callJNI_OnLoad(emulator); // 手动执行JNI_OnLoad函数
NativeLibHelper = vm.resolveClass("xxxxx/android/xxxxxxxx/SecurityUtil").newObject(null);//你懂的
}
public void Sign(){
String traceFile = "traceCode.txt";
PrintStream traceStream;
try {
traceStream = new PrintStream(new FileOutputStream(traceFile), true);
emulator.traceCode(module.base,module.base+module.size).setRedirect(traceStream);
} catch (FileNotFoundException e) {
e.printStackTrace();
}byte[] bytes = {100,52,54,102,54,101,100,55,55,57,57,55,51,56,102,97,48,52,57,54,97,56,50,57,53,52,97,49,50,51,54,101};
ByteArray barr = new ByteArray(vm,bytes);
StringObject str = new StringObject(vm,"getdata");
String stringObject = NativeLibHelper.callJniMethodObject(emulator,"s***leSign([BLjava/lang/String;)Ljava/lang/String;",barr,str).toString().replace("\"","");
Inspector.inspect(stringObject.getBytes(StandardCharsets.UTF_8),"result");
return;
}
public static void main(String[] args) {
SecurityUtil securityUtil = new SecurityUtil();
securityUtil.Sign();
}
}
从tracecode分析花指令
ida python 去除间接跳转块
from capstone import *
from keystone import *cs = Cs(CS_ARCH_ARM, CS_MODE_THUMB)
ks = Ks(keystone.KS_ARCH_ARM, keystone.KS_MODE_THUMB)def generate(code, addr):
# 参数2是地址,很多指令是地址相关的,比如 B 指令,如果地址无关直接传 0 即可,比如 nop。
encoding, _ = ks.asm(code, addr)
return encodingdef get_opcode(machine_code, code_address):
#利用capstone反汇编代码
assembly = []
for insn in cs.disasm(machine_code, code_address):
if insn.mnemonic != "":
assembly.append(insn.mnemonic)
assembly.append(insn.op_str)return assembly
def patch_b(addr, target_addr):
code = f"B {hex(target_addr)}"
bCode = generate(code, addr)# 此处本意是在获取到真实跳转地址后立即patch 后在执行过程中发现
# 当前面被patch后会影响后面其他位置真实位置的计算 故作罢
if (bCode != None):
#ida_bytes.patch_bytes(addr, bytes(bCode))
# print("patch:", hex(addr)," code:",code)
print(hex(addr)+“|”+code)def patch(addr):
if idc.get_wide_word(addr) == 0xb503: # PUSH {R0,R1,LR}
addr_ = addr + 2
if idc.get_wide_word(addr_) == 0x4801: # ldr r0, [pc, #4] 从pc+4处取出
lr = ""
jump_code_addr = addr_ + 4 + 4
if (jump_code_addr % 4 == 2):
jump_code_addr = jump_code_addr - 2 # 做四字节对其
jump_code = idc.get_wide_dword(jump_code_addr)# 开始判断ldr r0, [pc, #4]的下一句是否为BL
addr_ = addr_ + 2
code = idc.get_wide_dword(addr_).to_bytes(4, byteorder='little') # 小端序取出四个字节
opcode = get_opcode(code, addr_)if len(opcode) != 0 and opcode[0] == 'bl': # 判断是否跳转语句
jump_addr_1 = int(opcode[1][1:], 16)
code = idc.get_wide_dword(jump_addr_1).to_bytes(4, byteorder='little')
opcode = get_opcode(code, jump_addr_1)if len(opcode) != 0 and opcode[0] == 'bl': # 判断是否有二次跳转
jump_addr_2 = int(opcode[1][1:], 16)
code = idc.get_wide_dword(jump_addr_2).to_bytes(4, byteorder='little')
opcode = get_opcode(code, jump_addr_2)if len(opcode) != 0 and opcode[0] == 'bx':
lr = jump_addr_1 + 4elif len(opcode) != 0 and opcode[0] == 'bx':
lr = addr_ + 4
# print("lr:"+lr)
if lr != "":
r1 = idc.get_wide_dword(lr + (jump_code << 2))
real_jump_addr = lr + r1
patch_b(addr, real_jump_addr)if __name__ == '__main__':
for i in range(0x9EB8, 0x218Acc): #patch 整个.data段
patch(i)
0xe556|B 0x17a82
0xeb02|B 0x16ca8
0xeb48|B 0x14972
...
0x1c03b2|B 0x1c0312
0x1c03d4|B 0x1c020c
from keystone import * ks = Ks(keystone.KS_ARCH_ARM, keystone.KS_MODE_THUMB)
def generate(code, addr):
encoding, _ = ks.asm(code, addr)
return encodingdef patch_b(code, addr):
bCode = generate(code, addr)
if (bCode != None):
ida_bytes.patch_bytes(addr, bytes(bCode))if __name__ == '__main__':
with open('patch.txt', 'r') as file:
for line in file:
parts = line.split('|')
addr = parts[0]
code = parts[1].rstrip('\n')
patch_b(code,int(addr,16))
验证patch结果
二
分析结果前32位
在unidbg中固定输出结果
src/main/java/com/github/unidbg/unix/UnixSyscallHandler.java
将类中gettimeofday()方法中的取时间固定
// long currentTimeMillis = System.currentTimeMillis();
long currentTimeMillis = 0000000000000L;当时间固定后 发现结果也随之固定了
0000: 35 32 36 36 42 42 39 42 46 36 35 42 43 35 33 45 5266BB9BF65BC53E
0010: 46 32 33 39 39 44 33 41 30 44 30 30 42 44 35 44 F2399D3A0D00BD5D
0020: 30 30 30 30 30 30 30 30 31 32 43 34 31 41 46 36 0000000012C41AF6
0030: 34 35 43 42 30 32 44 38 35 38 44 33 45 42 44 35 45CB02D858D3EBD5
0040: 46 46 44 38 32 45 35 44 31 35 30 FFD82E5D150
观察到结果的33-40位居然是00000000 这会跟上面固定的时间有关吗再次改变时间:
long currentTimeMillis = 1234567898765L;0000: 32 44 41 43 41 37 41 31 36 43 44 44 41 34 31 37 2DACA7A16CDDA417
0010: 33 37 30 43 31 45 42 39 43 43 34 30 34 45 44 32 370C1EB9CC404ED2
0020: 44 41 30 32 39 36 34 39 31 32 43 43 42 31 33 43 DA02964912CCB13C
0030: 41 46 34 36 43 45 31 37 32 38 33 38 45 44 32 46 AF46CE172838ED2F
0040: 36 33 31 36 38 39 37 44 37 34 30 6316897D740发现这次结果的33-40位变成了DA029649 把他转为小端序再转16进制 发现是1234567898
即十位数的时间戳综上可知 结果的33-40位是十位数的时间戳 41-43位则是固定的12c
确认算法类型
// 截取部分
private static long II(long a, long b, long c, long d, long x, long s,
long ac) {
a += (I(b, c, d)&0xFFFFFFFFL) + x + ac;
a = ((a&0xFFFFFFFFL) << s) | ((a&0xFFFFFFFFL) >>> (32 - s));
a += b;
return (a&0xFFFFFFFFL);
}
private static long I(long x, long y, long z) {
return y ^ (x | (~z));
}由md5的最后一轮计算 可知
a = II(a, b, c, d, M4, 6, t[60]) //a = b+((a+I(b,c,d)+M4 +t[60])<<<6) <<<6表示循环左移6
b = II(d, a, b, c, M11, 10, t[61]) //b = a+((d+I(a,b,c)+M11+t[61])<<<10)
c = II(c, d, a, b, M2, 15, t[62]) //c = d+((c+I(d,a,b)+M2 +t[62])<<<15)
d = II(b, c, d, a, M9, 21, t[63]) //d = c+((b+I(c,d,a)+M9 +t[63])<<<15)因为逻辑运算左右移的互补关系 左移(x) = 右移(32-x)
把这些计算代入到上方ida中的伪c代码 流程十分的契合 结果的前32位大概率就是md5哈希校验了
寻找明文
// 第一轮
a = FF(a, b, c, d, M0, 7, 0xd76aa478)
b = FF(d, a, b, c, M1, 12, 0xe8c7b756)
c = FF(c, d, a, b, M2, 17, 0x242070db)
d = FF(b, c, d, a, M3, 22, 0xc1bdceee)
a = FF(a, b, c, d, M4, 7, 0xf57c0faf)
b = FF(d, a, b, c, M5, 12, 0x4787c62a)
c = FF(c, d, a, b, M6, 17, 0xa8304613)
d = FF(b, c, d, a, M7, 22, 0xfd469501)
a = FF(a, b, c, d, M8, 7, 0x698098d8)
b = FF(d, a, b, c, M9, 12, 0x8b44f7af)
c = FF(c, d, a, b, M10, 17, 0xffff5bb1)
d = FF(b, c, d, a, M11, 22, 0x895cd7be)
a = FF(a, b, c, d, M12, 7, 0x6b901122)
b = FF(d, a, b, c, M13, 12, 0xfd987193)
c = FF(c, d, a, b, M14, 17, 0xa679438e)
d = FF(b, c, d, a, M15, 22, 0x49b40821)private static long F(long x, long y, long z) {
return (x & y) | ((~x) & z);
}// 其中 Mj表示明文块j
FF = a=b+((a+F(b,c,d)+Mj+ti)<<<s)
只需要找到Mj 即找到了明文
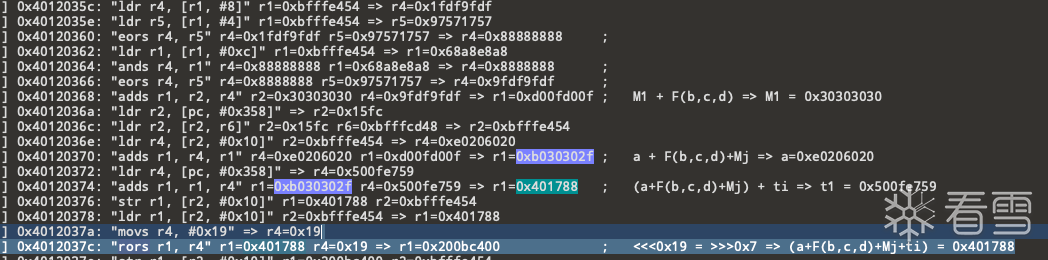
"ldr r4, [pc, #0x358]" => r4=0x1fdf9fdf
"ldr r4, [pc, #0x358]" => r4=0x97571757
"ldr r4, [pc, #0x35c]" => r4=0x68a8e8a8发现参与计算的几个数都是直接通过pc指针+偏移进行读取 为固定值 猜测这就是md5的初始模数
0x120360 "eors r4, r5" r4=0x1fdf9fdf r5=0x97571757 => r4=0x88888888
0x120364 "ands r4, r1" r4=0x88888888 r1=0x68a8e8a8 => r4=0x8888888
0x120366 "eors r4, r5" r4=0x8888888 r5=0x97571757 => r4=0x9fdf9fdf
(b & c) ^ ((~b) & d) => [(c ^ d) & b] ^ d
发现上述计算等价于F(b,c,d)
至此 确定了md5计算的初始模数a,b,c,d
A = 0xe0206020
B = 0x68a8e8a8
C = 0x1fdf9fdf
D = 0x97571757
00000000 30 30 30 30 30 30 30 30 5a 62 30 61 64 76 4a 32 |00000000Zb0advJ2|
00000010 52 74 43 69 6a 4e 72 38 64 55 70 49 35 31 50 5a |RtCijNr8dUpI51PZ|
00000020 6e 68 62 55 4b 67 33 57 4c 4d 68 4f 6d 53 33 41 |nhbUKg3WLMhOmS3A|
00000030 75 55 50 55 78 6b 39 35 68 77 37 68 64 4a 79 34 |uUPUxk95hw7hdJy4|
00000040 63 4a 72 4c 70 4d 50 64 78 54 72 49 68 31 67 37 |cJrLpMPdxTrIh1g7|
00000050 79 4c 50 75 48 44 4a 61 78 6b 36 6c 51 4d 71 6d |yLPuHDJaxk6lQMqm|
00000060 80 76 79 31 00 00 00 00 00 00 00 00 00 00 00 00 |.vy1............|
00000070 00 00 00 00 00 00 00 00 00 00 03 18 00 00 00 00 |................|转为大端序
00000000 30 30 30 30 30 30 30 30 61 30 62 5a 32 4a 76 64 |00000000a0bZ2Jvd|
00000010 69 43 74 52 38 72 4e 6a 49 70 55 64 5a 50 31 35 |iCtR8rNjIpUdZP15|
00000020 55 62 68 6e 57 33 67 4b 4f 68 4d 4c 41 33 53 6d |UbhnW3gKOhMLA3Sm|
00000030 55 50 55 75 35 39 6b 78 68 37 77 68 34 79 4a 64 |UPUu59kxh7wh4yJd|
00000040 4c 72 4a 63 64 50 4d 70 49 72 54 78 37 67 31 68 |LrJcdPMpIrTx7g1h|
00000050 75 50 4c 79 61 4a 44 48 6c 36 6b 78 6d 71 4d 51 |uPLyaJDHl6kxmqMQ|
00000060 31 79 76 80 00 00 00 00 00 00 00 00 00 00 00 00 |1yv.............|
00000070 00 00 00 00 00 00 00 00 18 03 00 00 00 00 00 00 |................|发现完美符合md5明文拓展后的特征(明文以0x80结尾,倒数第8字节存放明文长度*8)
0x500fe759L /* 1 */
0x6fa2f477L /* 2 */
0xa34533faL /* 3 */
...
0xadb2919aL /* 63 */
0x6ce390b0L /* 64 */
public class magicMD5 { static final String[] hexs = {"0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "A", "B", "C", "D", "E", "F"};
private static final long A = 0xe0206020L;
private static final long B = 0x68a8e8a8L;
private static final long C = 0x1fdf9fdfL;
private static final long D = 0x97571757L;//下面这些S11-S44实际上是一个4*4的矩阵,在四轮循环运算中用到
static final int S11 = 7;
static final int S12 = 12;
static final int S13 = 17;
static final int S14 = 22;static final int S21 = 5;
static final int S22 = 9;
static final int S23 = 14;
static final int S24 = 20;static final int S31 = 4;
static final int S32 = 11;
static final int S33 = 16;
static final int S34 = 23;static final int S41 = 6;
static final int S42 = 10;
static final int S43 = 15;
static final int S44 = 21;//java不支持无符号的基本数据(unsigned)
private long[] result = {A, B, C, D};//存储hash结果,共4×32=128位,初始化值为(幻数的级联)public static void main(String[] args) {
magicMD5 md = new magicMD5();
System.out.println(md.digest("30303030303030306130625a324a76646943745238724e6a497055645a5031355562686e5733674b4f684d4c4133536d5550557535396b786837776834794a644c724a6364504d70497254783767316875504c79614a44486c366b786d714d51317976"));
}private String digest(String inputHexStr) {
byte[] inputBytes = hexToByteArray(inputHexStr);
int byteLen = inputBytes.length;//长度(字节)
int groupCount = 0;//完整分组的个数
groupCount = byteLen / 64;//每组512位(64字节)
long[] groups = null;//每个小组(64字节)再细分后的16个小组(4字节)//处理每一个完整 分组
for (int step = 0; step < groupCount; step++) {
groups = divGroup(inputBytes, step * 64);
trans(groups);//处理分组,核心算法
}//处理完整分组后的尾巴
int rest = byteLen % 64;//512位分组后的余数
byte[] tempBytes = new byte[64];
if (rest <= 56) {
for (int i = 0; i < rest; i++)
tempBytes[i] = inputBytes[byteLen - rest + i];
if (rest < 56) {
tempBytes[rest] = (byte) (1 << 7);
for (int i = 1; i < 56 - rest; i++)
tempBytes[rest + i] = 0;
}
long len = (long) (byteLen << 3);
for (int i = 0; i < 8; i++) {
tempBytes[56 + i] = (byte) (len & 0xFFL);
len = len >> 8;
}
groups = divGroup(tempBytes, 0);
trans(groups);//处理分组
} else {
for (int i = 0; i < rest; i++)
tempBytes[i] = inputBytes[byteLen - rest + i];
tempBytes[rest] = (byte) (1 << 7);
for (int i = rest + 1; i < 64; i++)
tempBytes[i] = 0;
groups = divGroup(tempBytes, 0);
trans(groups);//处理分组for (int i = 0; i < 56; i++)
tempBytes[i] = 0;
long len = (long) (byteLen << 3);
for (int i = 0; i < 8; i++) {
tempBytes[56 + i] = (byte) (len & 0xFFL);
len = len >> 8;
}
groups = divGroup(tempBytes, 0);
trans(groups);//处理分组
}//将Hash值转换成十六进制的字符串
String resStr = "";
long temp = 0;
for (int i = 0; i < 4; i++) {
for (int j = 0; j < 4; j++) {
temp = result[i] & 0x0FL;
String a = hexs[(int) (temp)];
result[i] = result[i] >> 4;
temp = result[i] & 0x0FL;
resStr += hexs[(int) (temp)] + a;
result[i] = result[i] >> 4;
}
}
return resStr;
}/**
* 从inputBytes的index开始取512位,作为新的分组
* 将每一个512位的分组再细分成16个小组,每个小组64位(8个字节)
*
* @param inputBytes
* @param index
* @return
*/
private static long[] divGroup(byte[] inputBytes, int index) {
long[] temp = new long[16];
for (int i = 0; i < 16; i++) {
temp[i] = b2iu(inputBytes[4 * i + index]) |
(b2iu(inputBytes[4 * i + 1 + index])) << 8 |
(b2iu(inputBytes[4 * i + 2 + index])) << 16 |
(b2iu(inputBytes[4 * i + 3 + index])) << 24;
}
return temp;
}/**
* 这时不存在符号位(符号位存储不再是代表正负),所以需要处理一下
*
* @param b
* @return
*/
public static long b2iu(byte b) {
return b < 0 ? b & 0x7F + 128 : b;
}private void trans(long[] groups) {
long a = result[0], b = result[1], c = result[2], d = result[3];
/*第一轮*/
a = FF(a, b, c, d, groups[0], S11, 0x500fe759L); /* 1 */
d = FF(d, a, b, c, groups[1], S12, 0x6fa2f477L); /* 2 */
c = FF(c, d, a, b, groups[2], S13, 0xa34533faL); /* 3 */
b = FF(b, c, d, a, groups[3], S14, 0x46d88dcfL); /* 4 */
a = FF(a, b, c, d, groups[4], S11, 0x72194c8eL); /* 5 */
d = FF(d, a, b, c, groups[5], S12, 0xc0e2850bL); /* 6 */
c = FF(c, d, a, b, groups[6], S13, 0x2f550532L); /* 7 */
b = FF(b, c, d, a, groups[7], S14, 0x7a23d620L); /* 8 */
a = FF(a, b, c, d, groups[8], S11, 0xeee5dbf9L); /* 9 */
d = FF(d, a, b, c, groups[9], S12, 0x0c21b48eL); /* 10 */
c = FF(c, d, a, b, groups[10], S13, 0x789a1890L); /* 11 */
b = FF(b, c, d, a, groups[11], S14, 0x0e39949fL); /* 12 */
a = FF(a, b, c, d, groups[12], S11, 0xecf55203L); /* 13 */
d = FF(d, a, b, c, groups[13], S12, 0x7afd32b2L); /* 14 */
c = FF(c, d, a, b, groups[14], S13, 0x211c00afL); /* 15 */
b = FF(b, c, d, a, groups[15], S14, 0xced14b00L); /* 16 *//*第二轮*/
a = GG(a, b, c, d, groups[1], S21, 0x717b6643L); /* 17 */
d = GG(d, a, b, c, groups[6], S22, 0x4725f061L); /* 18 */
c = GG(c, d, a, b, groups[11], S23, 0xa13b1970L); /* 19 */
b = GG(b, c, d, a, groups[0], S24, 0x6ed3848bL); /* 20 */
a = GG(a, b, c, d, groups[5], S21, 0x514a537cL); /* 21 */
d = GG(d, a, b, c, groups[10], S22, 0x85215772L); /* 22 */
c = GG(c, d, a, b, groups[15], S23, 0x5fc4a5a0L); /* 23 */
b = GG(b, c, d, a, groups[4], S24, 0x60b6b8e9L); /* 24 */
a = GG(a, b, c, d, groups[9], S21, 0xa6848ec7L); /* 25 */
d = GG(d, a, b, c, groups[14], S22, 0x445244f7L); /* 26 */
c = GG(c, d, a, b, groups[3], S23, 0x73b04ea6L); /* 27 */
b = GG(b, c, d, a, groups[8], S24, 0xc23f57ccL); /* 28 */
a = GG(a, b, c, d, groups[13], S21, 0x2e86aa24L); /* 29 */
d = GG(d, a, b, c, groups[2], S22, 0x7b8ae0d9L); /* 30 */
c = GG(c, d, a, b, groups[7], S23, 0xe00a41f8L); /* 31 */
b = GG(b, c, d, a, groups[12], S24, 0x0a4f0fabL); /* 32 *//*第三轮*/
a = HH(a, b, c, d, groups[5], S31, 0x789f7a63L); /* 33 */
d = HH(d, a, b, c, groups[8], S32, 0x0014b5a0L); /* 34 */
c = HH(c, d, a, b, groups[11], S33, 0xeaf82203L); /* 35 */
b = HH(b, c, d, a, groups[14], S34, 0x7a807b2dL); /* 36 */
a = HH(a, b, c, d, groups[1], S31, 0x23dba965L); /* 37 */
d = HH(d, a, b, c, groups[4], S32, 0xccbb8c88L); /* 38 */
c = HH(c, d, a, b, groups[7], S33, 0x71de0841L); /* 39 */
b = HH(b, c, d, a, groups[10], S34, 0x39daff51L); /* 40 */
a = HH(a, b, c, d, groups[13], S31, 0xaffe3de7L); /* 41 */
d = HH(d, a, b, c, groups[0], S32, 0x6dc464dbL); /* 42 */
c = HH(c, d, a, b, groups[3], S33, 0x538a73a4L); /* 43 */
b = HH(b, c, d, a, groups[6], S34, 0x83ed5e24L); /* 44 */
a = HH(a, b, c, d, groups[9], S31, 0x5eb19318L); /* 45 */
d = HH(d, a, b, c, groups[12], S32, 0x61bedac4L); /* 46 */
c = HH(c, d, a, b, groups[15], S33, 0x98c73fd9L); /* 47 */
b = HH(b, c, d, a, groups[2], S34, 0x43c91544L); /* 48 *//*第四轮*/
a = II(a, b, c, d, groups[0], S41, 0x734c6165L); /* 49 */
d = II(d, a, b, c, groups[7], S42, 0xc44fbcb6L); /* 50 */
c = II(c, d, a, b, groups[14], S43, 0x2cf16086L); /* 51 */
b = II(b, c, d, a, groups[5], S44, 0x7bf6e318L); /* 52 */
a = II(a, b, c, d, groups[12], S41, 0xe23e1ae2L); /* 53 */
d = II(d, a, b, c, groups[3], S42, 0x08698fb3L); /* 54 */
c = II(c, d, a, b, groups[10], S43, 0x788ab75cL); /* 55 */
b = II(b, c, d, a, groups[1], S44, 0x02e11ef0L); /* 56 */
a = II(a, b, c, d, groups[8], S41, 0xe8cd3d6eL); /* 57 */
d = II(d, a, b, c, groups[15], S42, 0x7949a5c1L); /* 58 */
c = II(c, d, a, b, groups[6], S43, 0x24640035L); /* 59 */
b = II(b, c, d, a, groups[13], S44, 0xc96d5280L); /* 60 */
a = II(a, b, c, d, groups[4], S41, 0x70363da3L); /* 61 */
d = II(d, a, b, c, groups[11], S42, 0x3a5fb114L); /* 62 */
c = II(c, d, a, b, groups[2], S43, 0xadb2919aL); /* 63 */
b = II(b, c, d, a, groups[9], S44, 0x6ce390b0L); /* 64 *//*加入到之前计算的结果当中*/
result[0] += a;
result[1] += b;
result[2] += c;
result[3] += d;
result[0] = result[0] & 0xFFFFFFFFL;
result[1] = result[1] & 0xFFFFFFFFL;
result[2] = result[2] & 0xFFFFFFFFL;
result[3] = result[3] & 0xFFFFFFFFL;
}/**
* 下面是处理要用到的线性函数
*/
private static long F(long x, long y, long z) {
return (x & y) | ((~x) & z);
}private static long G(long x, long y, long z) {
return (x & z) | (y & (~z));
}private static long H(long x, long y, long z) {
return x ^ y ^ z;
}private static long I(long x, long y, long z) {
return y ^ (x | (~z));
}private static long FF(long a, long b, long c, long d, long x, long s,
long ac) {
a += (F(b, c, d) & 0xFFFFFFFFL) + x + ac;
a = ((a & 0xFFFFFFFFL) << s) | ((a & 0xFFFFFFFFL) >>> (32 - s));
a += b;
return (a & 0xFFFFFFFFL);
}private static long GG(long a, long b, long c, long d, long x, long s,
long ac) {
a += (G(b, c, d) & 0xFFFFFFFFL) + x + ac;
a = ((a & 0xFFFFFFFFL) << s) | ((a & 0xFFFFFFFFL) >>> (32 - s));
a += b;
return (a & 0xFFFFFFFFL);
}private static long HH(long a, long b, long c, long d, long x, long s,
long ac) {
a += (H(b, c, d) & 0xFFFFFFFFL) + x + ac;
a = ((a & 0xFFFFFFFFL) << s) | ((a & 0xFFFFFFFFL) >>> (32 - s));
a += b;
return (a & 0xFFFFFFFFL);
}private static long II(long a, long b, long c, long d, long x, long s,
long ac) {
a += (I(b, c, d) & 0xFFFFFFFFL) + x + ac;
a = ((a & 0xFFFFFFFFL) << s) | ((a & 0xFFFFFFFFL) >>> (32 - s));
a += b;
return (a & 0xFFFFFFFFL);
}private static byte hexToByte(String inHex){
return (byte)Integer.parseInt(inHex,16);
}
public static byte[] hexToByteArray(String inHex){
int hexlen = inHex.length();
byte[] result;
if (hexlen % 2 == 1){
//奇数
hexlen++;
result = new byte[(hexlen/2)];
inHex="0"+inHex;
}else {
//偶数
result = new byte[(hexlen/2)];
}
int j=0;
for (int i = 0; i < hexlen; i+=2){
result[j]=hexToByte(inHex.substring(i,i+2));
j++;
}
return result;
}}
传入明文:00000000a0bZ2JvdiCtR8rNjIpUdZP15UbhnW3gKOhMLA3SmUPUu59kxh7wh4yJdLrJcdPMpIrTx7g1huPLyaJDHl6kxmqMQ1yv
发现结果与
0000: 35 32 36 36 42 42 39 42 46 36 35 42 43 35 33 45 5266BB9BF65BC53E
0010: 46 32 33 39 39 44 33 41 30 44 30 30 42 44 35 44 F2399D3A0D00BD5D
前面固定的unidbg结果一致
分析明文生成
// 代码放结尾 搜索明文的前16个字节
HexDataSearch dataSearch = new HexDataSearch(emulator,"30303030303030306130625a324a7664");
// 30303030303030306130625a324a7664 => 00000000a0bZ2Jvd
emulator.traceWrite(0x4041c000L,0x4041c00FL);
public void hook_pianyi(){
emulator.attach().addBreakPoint(module.base + 0x111DF4, new BreakPointCallback() {
@Override
public boolean onHit(Emulator<?> emulator, long address) {
System.out.println("hook到的偏移:"+emulator.getContext().getIntArg(1));
return true;
}
});
}
简化后过程如下:
0x4010e946: "ldr r2, [pc, #0x364]" => r2=0x41c64e6d
0x4010ea40: "ldr r0, [pc, #0x2a4]" => r0=0x3039// [因为把时间固定为0 故此处也为0 当时这里找了好久 当时间不固定时 这里就是十六进制的时间戳 算是自己给自己挖了个坑往里面跳了
0x4010ea2c: "lsls r1, r1, #2" r1=0x0 => r1=0x0
0x4010ea2e: "adds r1, r3, r1" r3=0xbfffe568 r1=0x0 => r1=0xbfffe568
0x4010e948: "muls r2, r1, r2" r2=0x41c64e6d r1=0xbfffe568 => r2=0x8e4a5d48
0x4010ea44: "adds r0, r1, r0" r1=0x8e4a5d48 r0=0x3039 => r0=0x8e4a8d81
0x4010e7fa: "lsls r1, r0, #1" r0=0x8e4a8d81 => r1=0x1c951b02
0x4010e7fc: "lsrs r1, r1, #0x11" r1=0x1c951b02 => r1=0xe4a
至此 完成了sub_216744函数入参的分析
还原前32位明文
//利用chatgpt 生成的sub_216744 python代码
def sub_216744(a1, a2):
v2 = a1 ^ a2
v3 = 1
v4 = 0if (a2 & 0x80000000) != 0:
a2 = -a2
if (a1 & 0x80000000) != 0:
a1 = -a1if a1 >= a2:
while a2 < 0x10000000 and a2 < a1:
a2 *= 16
v3 *= 16while a2 < 0x80000000 and a2 < a1:
a2 *= 2
v3 *= 2while True:
if a1 >= a2:
a1 -= a2
v4 |= v3
if a1 >= a2 >> 1:
a1 -= a2 >> 1
v4 |= v3 >> 1
if a1 >= a2 >> 2:
a1 -= a2 >> 2
v4 |= v3 >> 2
if a1 >= a2 >> 3:
a1 -= a2 >> 3
v4 |= v3 >> 3if not a1:
breakv3 >>= 4
if not v3:
breaka2 >>= 4
result = v4
if v2 < 0:
return -v4
return resultdef get_plaintext(time):
plaintext_map = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890"
plaintext = ""
time_ = (time<<2) & 0xFFFFFFFF
a = (time_ + 0xbfffe568) & 0xFFFFFFFFfor i in range(0,91):
b = (a * 0x41c64e6d) & 0xFFFFFFFF
c = b + 0x3039
d = (c << 1) & 0xFFFFFFFF
e = d >> 0x11
a = c
# print(hex(e))
result = sub_216744(e,62)
# print(hex(result))
offset = e-(result * 62)
# print(hex(offset))
plaintext += plaintext_map[offset]
return plaintextif __name__ == '__main__':
time=0
plaintext = get_plaintext(time)
print(plaintext)
# a0bZ2JvdiCtR8rNjIpUdZP15UbhnW3gKOhMLA3SmUPUu59kxh7wh4yJdLrJcdPMpIrTx7g1huPLyaJDHl6kxmqMQ1yv
# 与前面分析的md5明文一致
三
分析结果后32位
处理md5明文
利用上面在trace文件中取出md5明文块的思路 取出后32位md5明文如下(hex):
[a] 66c1b57240d6b64fc1d3e3a89f8c61ce ;固定
[b] 56844ae6d6a488ff2e27f68b505c82a00558e289a0ccd718bb6cddfd0993fc03 ;32个字节 疑似sha256
[c] 630394833e90b050b6b79bc128d74f70 ;固定
[d] f8fffbfb8f8ff48f8bfbf88f8ef8fe888bfffef4f489fe8cfd89fdfd8f89f889 ;0x117a30 处理 java层传入的byte[]逐字节异或0xcd
[f] fdfdfdfdfdfdfdfd ;0x118aec 处理 前面固定的时间逐字节异或0xcd
[g] fcff8e ; 0x118b36 处理 逐字节异或0xcd => 0x12C异或0xcd经过校验 确实为前32位md5相同的计算方式
魔改SHA256还原
确定算法
56844ae6 d6a488ff 2e27f68b 505c82a0 0558e289 a0ccd718 bb6cddfd 0993fc03
=> xor 0xcd =>
9b49872b 1b694532 e3ea3b46 9d914f6d c8952f44 6d011ad5 76a11030 c45e31ce
A = (A + a)
B = (B + b)
C = (C + c)
D = (D + d)
E = (E + e)
F = (F + f)
G = (G + g)
H = (H + h)
寻找明文
步骤一:t1 = h + bigSig1(e) + ch(e, f, g) + k[i] + w[i]
步骤二:t2 = bigSig0(a) + maj(a, b, c)
步骤三:h = g,g = f,f = e,e = d + t1,d = c,c = b,b = a,a = t1 + t2其中bigSig1,bigSig0,maj,ch如下
private static int ch(int x, int y, int z) {
return (x & y) | ((~x) & z);
}private static int maj(int x, int y, int z) {
return (x & y) | (x & z) | (y & z);
}private static int bigSig0(int x) {
return Integer.rotateRight(x, 2) ^ Integer.rotateRight(x, 13)
^ Integer.rotateRight(x, 22);
}private static int bigSig1(int x) {
return Integer.rotateRight(x, 6) ^ Integer.rotateRight(x, 11)
^ Integer.rotateRight(x, 25);
}
import java.nio.ByteBuffer; /**
* Offers a {@code hash(byte[])} method for hashing messages with SHA-256.
*/class magicSHA256 {
private static byte hexToByte(String inHex){
return (byte)Integer.parseInt(inHex,16);
}
public static byte[] hexToByteArray(String inHex){
int hexlen = inHex.length();
byte[] result;
if (hexlen % 2 == 1){
//奇数
hexlen++;
result = new byte[(hexlen/2)];
inHex="0"+inHex;
}else {
//偶数
result = new byte[(hexlen/2)];
}
int j=0;
for (int i = 0; i < hexlen; i+=2){
result[j]=hexToByte(inHex.substring(i,i+2));
j++;
}
return result;
}
public static String bytesToHexString(byte[] bytes) {
StringBuilder builder = new StringBuilder();
for (byte b : bytes) {
builder.append(String.format("%02X", b));
}
return builder.toString();
}public static void main(String[] args) throws Exception {
System.out.println("sha256: " + bytesToHexString(Sha256.hash(hexToByteArray("00a7d31426b0d029a7b585cef9ea07a8cf9f9dcd9dcecf9c9c92929c9893cdca9b9f929dca9399929e9fca9a99989dce0565f2e558f6d636d0d1fda74eb129169e999d9de9e992e9ed9d9ee9e89e98eeed99989292ef98ea9bef9b9be9ef9eef9b9b9b9b9b9b9b9b9a99e8"))));
}
}class Sha256 {
private static final int[] K = {0xc5ef6cb9,0xf65207b0,0x32a5b8ee,0x6ed09884,
0xbe33817a,0xde9452d0,0x155ac185,0x2c791df4,
0x5f62e9b9,0x95e61820,0xa354c69f,0xd2693ee2,
0xf5db1e55,0x07bbf2df,0x1cb94586,0x46feb255,
0x63fe2ae0,0x68db04a7,0x88a4dee7,0xa369e2ed,
0xaa8c6f4e,0xcd11c78b,0xdbd5eafd,0xf19ccbfb,
0x1f5b1273,0x2f54854c,0x376664e9,0x383c3ce6,
0x418548d2,0x52c2d266,0x81af2070,0x934c6a46,
0xa0d249a4,0xa97e6219,0xca492edd,0xd45d4e32,
0xe26f3075,0xf10f499a,0x06a78a0f,0x15176fa4,
0x25daab80,0x2f7f256a,0x452ec851,0x40091282,
0x56f7ab38,0x51fc4505,0x736b76a4,0x970fe351,
0x9ec18237,0x99522f29,0xa02d346d,0xb3d5ff94,
0xbe794f92,0xc9bde96b,0xdcf9896e,0xef4b2cd2,
0xf3eac1cf,0xffc0204e,0x03ad3b35,0x0ba24129,
0x17dbbcdb,0x23352fca,0x399ce0d6,0x41143bd3};private static final int[] H0 = {0xed6ca546, 0x3c02eda4, 0xbb0bb053,
0x222ab61b, 0xd66b115e, 0x1c602bad, 0x98e69a8a, 0xdc858e38};// working arrays
private static final int[] W = new int[64];
private static final int[] H = new int[8];
private static final int[] TEMP = new int[8];/**
* Hashes the given message with SHA-256 and returns the hash.
*
* @param message The bytes to hash.
* @return The hash's bytes.
*/
public static byte[] hash(byte[] message) {
// let H = H0
System.arraycopy(H0, 0, H, 0, H0.length);// initialize all words
int[] words = toIntArray(pad(message));// enumerate all blocks (each containing 16 words)
for (int i = 0, n = words.length / 16; i < n; ++i) {// initialize W from the block's words
System.arraycopy(words, i * 16, W, 0, 16);
for (int t = 16; t < W.length; ++t) {
W[t] = smallSig1(W[t - 2]) + W[t - 7] + smallSig0(W[t - 15])
+ W[t - 16];
}// let TEMP = H
System.arraycopy(H, 0, TEMP, 0, H.length);// operate on TEMP
for (int t = 0; t < W.length; ++t) {
int t1 = TEMP[7] + bigSig1(TEMP[4]) + ch(TEMP[4], TEMP[5], TEMP[6]) + K[t] + W[t];
int t2 = bigSig0(TEMP[0]) + maj(TEMP[0], TEMP[1], TEMP[2]);
System.arraycopy(TEMP, 0, TEMP, 1, TEMP.length - 1);
TEMP[4] += t1;
TEMP[0] = t1 + t2;
}// add values in TEMP to values in H
for (int t = 0; t < H.length; ++t) {
H[t] += TEMP[t];
}}
return toByteArray(H);
}/**
* Internal method, no need to call. Pads the given message to have a length
* that is a multiple of 512 bits (64 bytes), including the addition of a
* 1-bit, k 0-bits, and the message length as a 64-bit integer.
*
* @param message The message to pad.
* @return A new array with the padded message bytes.
*/
public static byte[] pad(byte[] message) {
final int blockBits = 512;
final int blockBytes = blockBits / 8;// new message length: original + 1-bit and padding + 8-byte length
int newMessageLength = message.length + 1 + 8;
int padBytes = blockBytes - (newMessageLength % blockBytes);
newMessageLength += padBytes;// copy message to extended array
final byte[] paddedMessage = new byte[newMessageLength];
System.arraycopy(message, 0, paddedMessage, 0, message.length);// write 1-bit
paddedMessage[message.length] = (byte) 0b10000000;// skip padBytes many bytes (they are already 0)
// write 8-byte integer describing the original message length
int lenPos = message.length + 1 + padBytes;
ByteBuffer.wrap(paddedMessage, lenPos, 8).putLong(message.length * 8);return paddedMessage;
}/**
* Converts the given byte array into an int array via big-endian conversion
* (4 bytes become 1 int).
*
* @param bytes The source array.
* @return The converted array.
*/
public static int[] toIntArray(byte[] bytes) {
if (bytes.length % Integer.BYTES != 0) {
throw new IllegalArgumentException("byte array length");
}ByteBuffer buf = ByteBuffer.wrap(bytes);
int[] result = new int[bytes.length / Integer.BYTES];
for (int i = 0; i < result.length; ++i) {
result[i] = buf.getInt();
}return result;
}/**
* Converts the given int array into a byte array via big-endian conversion
* (1 int becomes 4 bytes).
*
* @param ints The source array.
* @return The converted array.
*/
public static byte[] toByteArray(int[] ints) {
ByteBuffer buf = ByteBuffer.allocate(ints.length * Integer.BYTES);
for (int i = 0; i < ints.length; ++i) {
buf.putInt(ints[i]);
}return buf.array();
}private static int ch(int x, int y, int z) {
return (x & y) | ((~x) & z);
}private static int maj(int x, int y, int z) {
return (x & y) | (x & z) | (y & z);
}private static int bigSig0(int x) {
return Integer.rotateRight(x, 2) ^ Integer.rotateRight(x, 13)
^ Integer.rotateRight(x, 22);
}private static int bigSig1(int x) {
return Integer.rotateRight(x, 6) ^ Integer.rotateRight(x, 11)
^ Integer.rotateRight(x, 25);
}private static int smallSig0(int x) {
return Integer.rotateRight(x, 7) ^ Integer.rotateRight(x, 18)
^ (x >>> 3);
}private static int smallSig1(int x) {
return Integer.rotateRight(x, 17) ^ Integer.rotateRight(x, 19)
^ (x >>> 10);
}
}
分析明文组成
[A] 00a7d31426b0d029a7b585cef9ea07a8 固定值
[B] cf9f9dcd9dcecf9c9c92929c9893cdca9b9f929dca9399929e9fca9a99989dce 0x118786 把前面java层传入的参数的ascii码逐字节异或0xab得到
[C] 0565f2e558f6d636d0d1fda74eb12916 固定值
[D] 9e999d9de9e992e9ed9d9ee9e89e98eeed99989292ef98ea9bef9b9be9ef9eef 0x117a30 结果的前32位异或0xab得到
[E] 9b9b9b9b9b9b9b9b9a99e8 0x118aec 时间+12C异或0xab得到
四
写在最后
看雪ID:劫__
https://bbs.kanxue.com/user-home-949812.htm
# 往期推荐
2、恶意木马历险记
球分享
球点赞
球在看
点击阅读原文查看更多
如有侵权请联系:admin#unsafe.sh