2024-10-1 22:4:9 Author: hackernoon.com(查看原文) 阅读量:1 收藏
In e-commerce and product-led companies, managing product categorization can be tricky, especially when categories include both products and subcategories, or when products belong to multiple categories. Just imagine an electronics store where "💻 Laptops" is a category, but within that, there are subcategories like "🎮 Gaming Laptops" and "👨💻 Business Laptops," each containing overlapping products. With all the nested categories, ensuring the retrieval of products for a specific category is technically quite the task. Especially given the fact that you need to avoid situations where the same product appears in the output multiple times: in addition to retrieving the list of products, you also need to go through deduplication.
The method I’m about to describe has a major impact on performance, and without it, there would be a significant drop in efficiency. The issue is complex, but once you get the solution right, replicating this again will be no harder than any other ordinary task. I’ll talk you through establishing proper data storage for easy access, separating the data for reading and modification using relational databases for product relationships, using NoSQL databases for faster queries, and graph theory to handle advanced category nesting. Step-by-step, through the thorn bushes to maximum optimization.
Ways to optimize data storage for reading and modification – separately
So first of all, in order to request data effectively you need to store it efficiently, in a way where it can be conveniently and quickly queried. Otherwise, querying products by a specific category can take a long time, and this directly affects the speed of product display on the website, customer experience. Which in turn could lead to losing customers to a fixable issue such as the site loading time being too long.
The
First, we start by sorting out data storage for modification. This will be a relational database with a table for products and a table for categories, and also tables for linking categories and products. There are two ways to store information on which products (or subcategories) belong to which categories:
- Store the details of the elements (products and/or subcategories) within each category.
- Store the information on the product or category itself with the information specifying which category it belongs to.
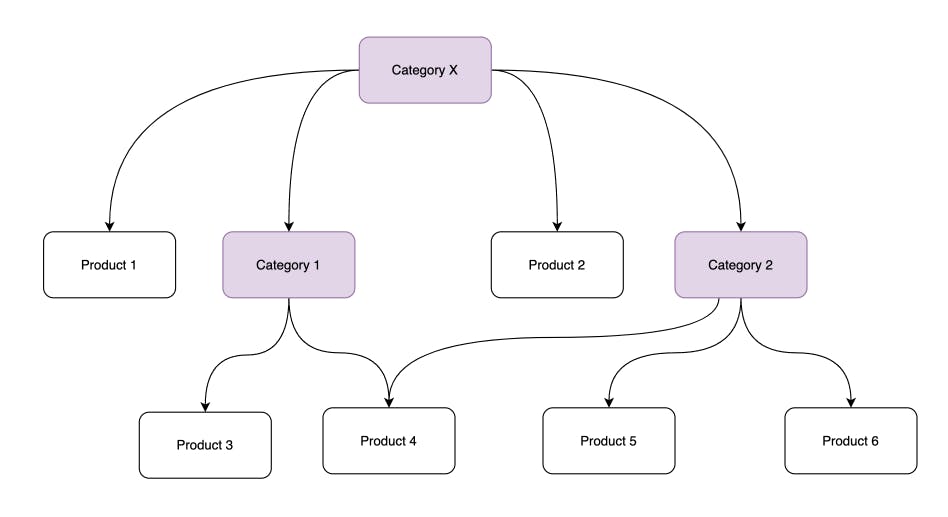
Regardless of the method, querying products in a direct category is quite straightforward. But if you're querying a category that contains other nested categories, things get more difficult. You’ll either need to run a complex query or perform a series of queries. For example, if your request is "Show everything in category X":
- You might receive results such as Product 1, Category 1, Product 2, and Category 2
- The challenge here is that you don’t know if there are enough products (say, 50), so you'll need to retrieve everything from the category, which could involve hundreds or even thousands of products and subcategories.
- For each subcategory (like Category 1 and Category 2 in this example), query the database again to get the products they contain.
- Concatenate and then remove any duplicates.
- Select the first 50 products the user asked for.
Advanced indexing using transitive closure
As you might imagine, this process of querying, deduplication, and sorting can take a significant amount of time (especially with larger-than-average datasets) and may not meet your SLAs, so, to avoid customer dissatisfaction this problem needs to be addressed early on. The solution is to precompute the indirect inclusion of products in each category; meaning we can record all indirect inclusions for each product in advance. This will allow us to retrieve all products in a category with just one query, even if the product isn’t directly assigned to that category. Plus, if we record the indirect inclusion of a product, we automatically solve the deduplication issue. So, if category A includes categories B and C, and a product exists in both too, we can record that the product is also part of category A. This eliminates duplication, as it no longer matters if the product is included in A through B or through C.
We can call this process indexing. Maintaining it can be difficult because products may change their categories throughout their lifecycle, and categories may change their parent categories. To make this maintenance easier we can turn to discrete mathematics, specifically graph theory. Why? Because the inclusion of products and categories in categories is nothing more than a

Note thatProduct 4 is in both Category 1 and Category 2. Now, let’s add edges that link Product 3, Product 4, Product 5, and Product 6 with Category X.
 There are two edges connecting Category X to Product 4. This is fine because if Product 4 is removed from Category 1, we shouldn’t lose its indirect inclusion in Category X. To simplify, we can record directly in Product 4 that it belongs to Category X, and it doesn’t matter if it’s included through multiple paths. This kind of edge construction is called
There are two edges connecting Category X to Product 4. This is fine because if Product 4 is removed from Category 1, we shouldn’t lose its indirect inclusion in Category X. To simplify, we can record directly in Product 4 that it belongs to Category X, and it doesn’t matter if it’s included through multiple paths. This kind of edge construction is called
Building a service
The next step is making this whole idea come to life. To do this, we’ll need a new microservice (or simply a new service in case you’re working with a monolithic architecture) that monitors when a product or category is added to another category. You can do this using a cloud event handler (such as
You can store a graph like this using two tables: one for edges and one for vertices. It’s best to keep the vertices abstract, meaning they don’t directly represent products or categories. Instead, they are vertices with a string field ref to identify whether it’s a product or a category. You can choose how to encode them in the ref field. For example, you could encode them as Product:<id> and Category:<id>. This format, using a “:” separator, allows the string to be easily used as a key in a MongoDB document (since MongoDB has restrictions on certain symbols, like periods, in field names).
So, the edge in our graph currently has three fields:
from(a reference to the vertex from which the edge originates)to(a reference to the vertex where the edge points)path(the path this edge takes)
In the case of the example above, the two edges between Category X and Product 4 would look like this:
-
from: Vertex(Category:X)
-
to: Vertex(Product:4)
-
path: [Vertex(Category:1)]
And this:
- from: Vertex(Category:X)
- to: Vertex(Product:4)
- path: [Vertex(Category:2)]
The path field allows us to differentiate between these two edges so that if one is removed, we don’t accidentally delete the other.
Next, we need an external trigger to update our graph with new vertices and edges whenever a product or category is added to another category.
For now, we're not concerned with indirect inclusion of categories within other categories. We are only focusing on vertices that represent products. To keep the vertex abstract, we can introduce an isIndexing flag. Once it is set, the service will generate transitive closures (connections) between those vertices and their indirect parent categories.
For the consumer service, presenting business data — categories and their contents — in the language of our service (which is the language of graphs) is enough. Our service will take care of the rest.
This consumer service will send the input graph to our service, which will then create the transitive closures and save the updated graph structure to its database. It’s important that the consumer service only passes graphs of categories and their included products and categories. Our service stores the entire graph so it will transitively generate closures for any products that belong to categories which, in turn, belong to the target category. For example:
- The consumer service passes a graph with Category 1 and its included Product 3 and Product 4 to our service.
- Our service incorporates this graph into its internal graph.
- The consumer service passes a graph with Category X and its included Product 1, Category 1, Product 2, Category 2 to the service.
- Our service incorporates this graph into its internal graph.
- The service detects that Category 1 is already in its graph, meaning it should close (create transitive edges) all products within Category 1 with Category X.
After the update, our service should return the list of changed vertices, which were marked as indexing before (isIndexing=true), and all the edges linked to them. A vertex can change for three reasons:
- The vertex was created. This happens when a product or category is added to the graph for the first time.
- The vertex was modified. The composition of incoming/outgoing edges changes.
- **The vertex was deleted.**When the number of edges to/from a vertex drops to 0. Such a vertex could remain "hanging," but we would rather the service's update algorithm cleans up such vertices to save space.
After receiving the updated list of vertices and their edges from this service, the consumer service (the one responsible for the inclusion of a product or category in a category, and the one that triggered the change) records in the product-related tables where the product now belongs. This could be stored as a JSONB field. Or, in a separate many-to-many table. Here, I’d say stick to the abstract ref. This way you should record encoded ref strings in the products instead of category IDs, as described earlier. If a product has more than one edge with the same ref, the consumer service can manage this information as it decides fit. For basic inclusion, you can just ignore the duplicates and treat the product as belonging to another category if there's at least one edge between them. When querying products for Category X, you only need to encode this category as a ref and check if the product is included in it.
As I said earlier, if you're using MongoDB you can create a new array field in the product documents called includedIn, which will store the list of ref values. You can then build a
As an intermediate result with just a single linear query (that also uses an index), we conveniently get a list of products, either directly or indirectly included in the requested category.
Taking this approach even further
But that's not all. Let’s imagine the business now wants not only to place products in categories but also assign an order to the products within those categories. They want to start prioritizing certain products and placing them higher in the list. Without the solution I described above, this could lead to a significant amount of data being sorted in RAM, with no good reason behind it. As you might remember, in order to retrieve the first 50 products you would need to query all products across all subcategories of the requested category. This included nested subcategories too. You’d then need to sort the products, deduplicate them, and select the first 50. Sorting has the computational complexity of NlogN, which really is a disaster in terms of performance!
Luckily we can easily extend the approach described above further. All we need to do is add information about the product’s order to the edges. When we build both transitive and regular edges, we already know the order, as it’s statically defined and stored in the consumer service. Now it can pass this information to our new service.
Then, our graph takes the following form (remember: we’re indexing only vertices marked with the isIndexing flag, which means product vertices):

\The consumer service can now record not only the categories a product belongs to, but also the order in which they appear, using a dictionary or tuple format. Going back to MongoDB, we can replace the includedIn array with an object where the keys are our ref values, and the values represent the order numbers. For example, for Product 4, it would look something like this:
{
"id": "4",
"name": "Product 4",
"includedIn": {
"Category:1": 1,
"Category:2": 0,
"Category:X": 2,
"Category:X": 4
}
}
But since Product 4 appears in Category X twice, MongoDB cannot store two identical keys with different values. How do we handle this? The solution is quite simple. We need to pick one value; if we query for products in Category X, Product 4 would appear twice (once with index 2 and once with index 4), so we can safely ignore the duplicate and only keep "Category:X": 2. In case you want to sort in ascending order (ASC), take the smallest number. If you want to sort in descending order (DESC), take the largest one. If you want to sort in both ways, we can add 1 or -1 to the reference. For example, Category:X:1:2 and Category:X👎4.
Now comes the fun part. Databases can use indexes to avoid sorting data in general, so instead of performing a sort operation, they can just scan records that are already ordered in the index. This means that if we already know the order of our products, (and we do with the method we’re using), we can create an index on the field that holds this order. This way, the database doesn’t have to sort anything — it’s already done, which saves resources that would otherwise be spent on performance.
The next step is deciding which field to use for the index. In MongoDB, there’s a great solution for this — includedIn.$** field, but we’ll need to adjust the query. Previously, we used the $in operator to check whether a product was included in a category, but now we’ll use the $gte operator. For example, to query products in Category X, we encode it as "Category:X" and run the following query:
{ "includedIn.Category:X": { $gte: 0 }}
And that’s it! As a result, we get all the products from Category X, including those from its subcategories and deeper nested categories, with deduplication and sorting, all in a single, simple, linear O(n) query. Plus, by using an index, we avoid the need for the database to sort the data in RAM!
Finding new ways to tackle old issues
The e-commerce landscape has been growing exponentially together with the ability for us to reach, order, and buy anything and anytime. And at times, the systems are not ready to support and manage this demand for information retrieval. Sometimes, even programmers aren’t. This is why I wanted to share an approach that has worked time and time again. As we’ve seen, using graph theory to handle complex category nesting and prevent duplicates makes sure that search results are accurate and comprehensive; indexing allows for clearer category-product relationships; and creating a dedicated service to track updates optimizes product retrieval, even when dealing with large, multi-layered categories. The result? Faster queries, which can often be the cornerstone of successfully retaining customers before they get annoyed that the load is taking too long.
如有侵权请联系:admin#unsafe.sh