2024-10-3 05:0:17 Author: hackernoon.com(查看原文) 阅读量:3 收藏
Authors:
(1) Yinwei Dai, Princeton University (Equal contributions);
(2) Rui Pan, Princeton University (Equal contributions);
(3) Anand Iyer, Georgia Institute of Technology;
(4) Ravi Netravali, Georgia Institute of Technology.
Table of Links
2 Background and Motivation and 2.1 Model Serving Platforms
3.1 Preparing Models with Early Exits
3.2 Accuracy-Aware Threshold Tuning
3.3 Latency-Focused Ramp Adjustments
5 Evaluation and 5.1 Methodology
5.3 Comparison with Existing EE Strategies
7 Conclusion, References, Appendix
5.3 Comparison with Existing EE Strategies
We compare Apparate with two off-the-shelf EE models: BranchyNet [53] and DeeBERT [57]. BranchyNet extends ResNet models with ramps of the same style as Apparate, while DeeBERT extends BERT-base with deeper ramps (using the entire BERT pooler, as described in §3.1). For each, we follow their prescribed architectures, with ramps after every layer that are always active. We perform one-time tuning of thresholds as recommended by both works, and consider two variants: the default recommendation where all ramps must use the same threshold, and a more flexible version


that removes this restriction (+). For both, threshold tuning is done optimally (via grid search), and is based on uniformly sampled data across the workload. For fair comparison, Apparate’s ramp budget is configured to support ramps at all layers (though it never does so).
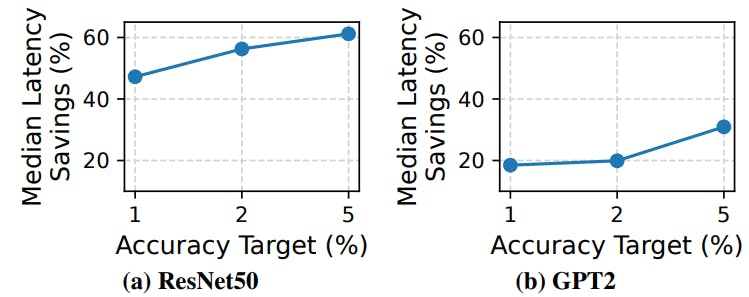
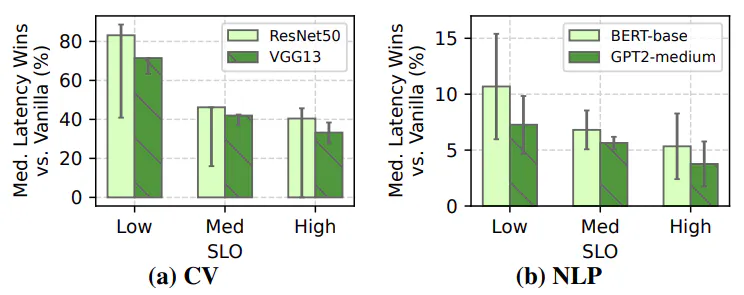
Table 2 presents our results. The main takeaway is that existing EE approaches, even when favorably tuned, yield unacceptable drops in average accuracy up to 23.9% and 17.8% for CV and NLP. In contrast, Apparate consistently meets the imposed accuracy constraint (1% in this experiment) for both workloads. Further, even with such accuracy violations, tail latencies are 0.9-9.4% lower with Apparate than with these systems. The reason is again lack of adaptation: all ramps are always active despite their current efficacy which vary dramatically over time (§2.3), yielding undue overheads for large numbers of non-exiting inputs. In contrast, throughout these experiments, despite having a full ramp budget, Apparate maintained only 9.1-27.2% of all possible ramps.
For fair median latency comparison, we consider an optimally-tuned (opt) version of existing EE models that perform one-time tuning on the actual test dataset, picking the best (latency-wise) thresholds that ensure <1% accuracy drop. As shown, due to its regular and less-constrained adaptation, Apparate outperforms even this oracle version of existing EEs with up to 14.1% higher median latency savings.


如有侵权请联系:admin#unsafe.sh