为了实现符合车规级高可用的公有云运行方案,我们在公有云服务普及多可用区和 Serverless 极致弹性的基础上,利用同城三云双活方案,来捅破公有云高可用的理论极限!非常感谢火山引擎团队能够用突出的产品力和专业的服务精神全力支持与配合整个方案的推进工作!
——长城汽车C端平台技术总监 陈天予
据 IDC 调研数据显示,在汽车云基础设施市场中,公有云占比高达 59%。云作为汽车行业的创新性基础设施,汽车上云已经成为事实趋势。然而,单一云服务对国内主流汽车企业带来了高度依赖与绑定的风险。为了提高汽车企业的业务可靠性,多云已经成为汽车企业的一大上云趋势。
长城汽车是一家全球化智能科技公司,一直以来积极拥抱数智化变革,通过云计算等先进技术,不断优化提高用户体验。作为车企品牌与用户之间的高度信息与机会互动的生态载体,车企移动端 APP 与小程序业务的稳定性与质量直接关乎存量车主用户留存与潜客试驾转化。当前,长城汽车的移动端 APP 与小程序业务分布在不同的云环境,这对故障时的业务快速迁移、业务持续高可用带来了较大挑战。
为应对该挑战,长城汽车选择与火山引擎进行营销侧移动业务的双云双活探索与论证,依托火山引擎云原生产品方案,构建多云双活应用架构,实现了不同云环境中应用的自动部署、扩展和管理。同时,通过建立完善的全生命周期多云观测体系,在应对业务故障时实现流量的无缝切换,减少故障感知,满足长城汽车对多云部署下敏捷性、弹性、高可用性的多方面需求:
统一多云应用管理,满足业务连续性的需求:通过将业务和控制解耦(分别部署在火山引擎与其他云上),减少故障爆炸半径,基于多云容器管理能力实现应用的自动部署和扩展,将应用发布统一收口与管理,屏蔽各朵云之间的差异与细节,确保服务的高可用性和快速恢复; 构建多云流量治理体系,降低故障影响范围:解决跨云流量调度的多云服务寻址、就近路由访问、自动故障转移、多云流量观测等核心问题,保障流量优先在本 region 内闭环,避免额外的跨云带宽和业务性能损耗,通过精准流量调控策略实现自动 failover 收缩故障影响范围; 建立多云观测体系,避免数据孤岛:面向运维人员,提供各朵云之间观测数据的统一可视化界面,实现多云观测体系、指标、监控工具的统一化,规避数据孤岛问题。
容灾架构从最早期的单活形态(同城主备)发展到同城多活形态,再演化到异地多活,随着容灾能力的提升,伴随的是更复杂的技术架构、更高的业务改造成本和更高昂的资源成本。
相比自建基础设施,公有云厂商往往能提供 SLA 更有保障的服务,因此对于云上用户来说,容灾能力的建设目标非常明确:即能够应对和处理单云单地域的故障,从而保障业务的连续性。同城不同云厂商机房间的网络延时较短,数据库、缓存和消息等在数据容灾方面容易实现得多,所以同城多云多活架构是企业提升业务韧性最有效、最经济、最务实的手段之一。
下面是长城汽车营销云同城多云双活架构的整体方案:
业务分别部署在火山引擎与其他公有云上,控制流能力部署在第三朵云上,将业务与控制解耦部署,尽可能减少故障爆炸半径; 容器化应用视角屏蔽掉各朵云之间的差异与细节,借助多云容器管理能力构建多云统一应用发布能力,将应用发布统一收口与管理; 双云双活分业务逐步开展上线,微服务之间除了南北向调用依赖外,也会存在东西向调用依赖,故需构建多云流量治理体系,实现双云双活业务的正常运行; 运维视角统一各朵云之间观测数据的可视化入口,结束多云杂散的观测体系、指标及入口,建立以应用为中心的多云观测体系; 在同城多活架构下,因网络条件较好,为避免数据不一致等问题,数据层采用单写多读、多云数据单向同步、故障时主备切换的方案。
多云发布:构建以应用为核心的开发能力
企业在执行多云战略的过程中,最核心的是要围绕自身的业务应用。在多云环境中,屏蔽多云带来的环境差异、让开发人员可以聚焦业务本身将有助于业务敏捷。
火山引擎多云容器应用发布为客户提供了一种灵活、高效的跨云平台部署和管理容器化应用的能力。它解决了传统单一云服务可能遇到的资源瓶颈、地域限制和单点故障风险问题,通过在不同云环境中实现应用的自动部署、扩展和管理,充分保障服务的高可用性和快速恢复,实现业务连续性。这种发布策略满足了企业对敏捷性、弹性、高可用性的多方面诉求,为企业在快速变化的市场中保持竞争力带来了重要价值。
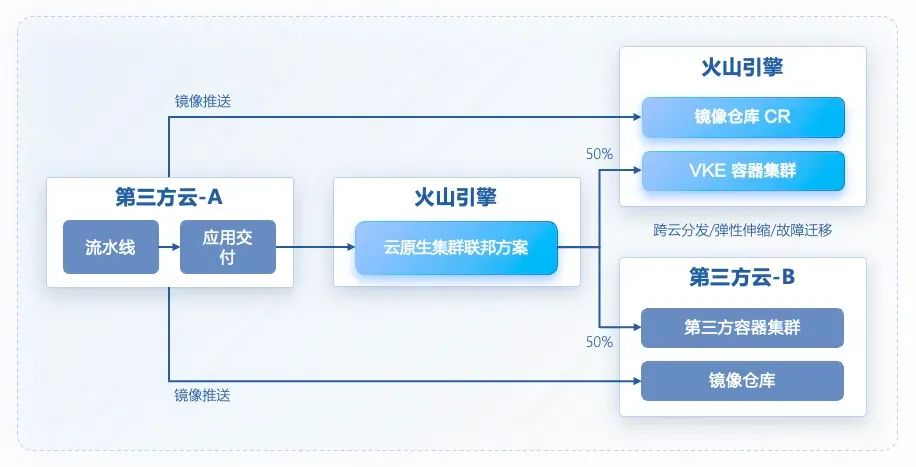
在上图的多云发布的方案中,本着控制与业务解耦的整体原则,客户使用 A 厂商的 CI/CD 产品提供代码托管、流水线、应用交付等控制流,并用火山引擎云原生集群联邦方案承接多云纳管、跨云调度、故障迁移等核心业务流。实现了由 A 厂商将编排应用下发到火山引擎云原生集群联邦方案,再将应用涉及的 Kubernetes 工作负载及配置资源分发到火山引擎容器服务 VKE 和 B 厂商容器集群的多云业务集群中。该方案提供的关键能力与优势包括:
跨云应用分发:通过火山引擎云原生集群联邦方案注册纳管 VKE 等多云集群,并将多集群构建为集群联邦,形成统一调度资源池,集群联邦会作为 CD 流水线统一多云分发入口; 原生资源兼容:集群联邦资源完全兼容 Kubernetes 的标准 API、Helm Chart 以及自定义 CRD,而且可以使用联邦集群 KubeConfig 通过 kubectl 终端进行管理及流水线集成,这种一致性云原生使用体验降低了业务多云化改造成本; 开箱即用的策略:云原生集群联邦方案内置了开箱即用的调度策略,可按照复制、动态/静态权重进行多集群应用分发,支持应用关联资源自动跟随分发、冲突资源接管等策略。客户项目中工作负载采用了工作负载静态权重调度模式,即按固定比例将负载实例拆分到 VKE 和其他云的容器集群中运行; 多云差异适配:应用资源分发到不同云环境中通常需要进行差异化的配置,如仓库地址等,云原生集群联邦方案可针对分发到指定集群的应用资源进行自动覆写操作,并封装镜像仓库地址、启动命令、标签、注解等差异化策略,大大提升了多云差异配置效率; 跨云弹性伸缩:在多集群管控面统一制定弹性伸缩策略(包括指标、阈值、弹性范围等),应用副本会在 VKE 和其他云的容器集群中跨多云集群进行 HPA 扩缩容,指标阈值判断会考虑所有集群中的副本,扩缩容的副本也会遵循两个集群的副本权重定义; 应用容灾迁移:应用实例分发到多云集群环境后如果发生故障(例:因节点故障导致无法调度等),云原生集群联邦方案会将故障实例自动重调度到其他健康集群中,结合服务网格跨集群容灾能力,最大限度提升业务的高可用性。
上述方案中的多集群调度引擎 KubeAdmiral 目前已经开源,也已经过字节跳动内部超大规模(数十万节点、千万级核资源)集群管理实践打磨,火山引擎云原生集群联邦方案基于该引擎进行产品化能力增强,为用户提供性能高、稳定性强的多集群资源分发管理体验。
多云流量治理:多地多中心统一调配和管理
双云多活部署架构可以很好解决单云/单 region 资源瓶颈及单个云厂商故障快速容灾切换问题,但在实际业务架构改造或多云迁移过程中,无法做到多云全量业务的对等部署,需要解决单云/单 region 部署服务的互联互通和跨云服务访问,保障多云场景下业务流程闭环。同时,当本 region 内的单个服务实例异常时,服务消费方需要及时感知并屏蔽服务提供方异常实例将流量自动调度至对端相同服务的可用实例,避免因长时间等待造成服务雪崩。
结合上述实际业务场景,火山引擎云原生团队提供云原生集群联邦方案、微服务引擎 MSE、API 网关产品组合方案,助力用户快速落地多云双活应用架构,解决跨云流量调度的多云服务寻址、就近路由访问、自动故障转移、多云流量观测等核心问题,保障流量优先在本 region 内闭环避免额外的跨云带宽和业务性能损耗,通过精准流量调控策略实现自动 failover 收缩故障影响范围。该方案的核心优势和关键能力包括以下内容:
多云注册打通:在业务多云部署后,为了确保应用在多云部署后能够互联互通,首先需要能够打通多云间的服务发现。同时为了保证注册中心组件可靠性和数据一致性,一般会推荐在单云本地部署注册中心。因此就需要具备多个注册中心进行双向同步,保证每个注册中心都具备全量服务发现数据。火山引擎微服务引擎 MSE 提供兼容主流注册中心(Nacos、Eureka 等)的同步引擎,构建注册数据双向同步链路,可实现多云场景下统一服务发现。如果采用 Kubernetes svc 服务寻址方式,为了在跨集群场景中不改变原有的服务发现的方式,MSE 会将不同集群的 svc 进行合并——在不同集群下,只要是在相同 namespace 下的同名 svc,都会被认为是相同的服务,能够被对端集群消费方服务正常服务发现。
跨云流量调度:在业务多云部署的过程中,由于数据一致性、资源负载成本、业务改造等原因,部分有状态业务、第三方开发业务等只能单云集中化部署,对于单云部署的应用,在应用层还需要提供跨云服务调用能力,保证在当前云上没有部署下游服务时,能够自动访问到对端云上部署的服务。同时,如果本云中已经部署了下游服务,则需要优先调用本云。MSE 具备跨云流量调度能力,当服务实例启动时,会将实例的归属地域自动写入注册中心元数据信息,消费方在路由调用时根据服务寻址列表的地域归属实现亲和路由,保证流量优先在本云闭环,同时 MSE 支持无侵入 java agent 和 sidecar 接入方式,用户仅需在 deployment 引入 MSE 注解即可完成实例接入,无需代码改造,极大降低业务迁移改造成本。
自动故障转移:在业务多云部署后,由于业务发布、底层依赖故障等诸多原因,可能会造成单云上部署的某个服务不可用。在出现服务级别故障时,我们需要能够根据健康检测和熔断策略自动发现故障,将请求调用到健康实例,并在故障恢复后自动回切。MSE 支持消费方在服务调用时会根据请求状态码识别下游实例健康状态,达到指定阈值后主动剔除异常实例,当本云内的相同服务实例均检测异常时,将自动 failover 至对端相同服务可用实例保障业务逻辑闭环;同时,本云的访问实例达到隔离时间后,将自动注入少量流量判断其恢复状态,若达到健康阈值则恢复原有的就近路由调用,避免跨云调度额外带宽损耗。
多云观测:一站式跨云资源观测
相比单个云上部署的应用、在多云环境构建应用的可观测性会变得更复杂,主要会面临以下挑战:
基础环境差异:不同云环境针对相同监控对象(例如主机、容器、应用等)提供的性能指标可能不同,即便有相同指标,它们在不同环境中也可能具备不同的名称和标签,难以关联使用; 观测工具不统一:由于技术选择和历史负担等因素,不同环境中可能采用不同的监控工具。例如企业可能在私有云中使用商业化的观测产品,而在公有云中选择云厂商提供的观测产品或基于开源组件自建 ,导致多种组件共存,数据无法互访; 观测数据孤岛:因技术选择不一致,监控信息通常分散存储,获取指标需要对接多个数据源;观测数据分散在不同的地理位置,无法有效聚合和统一展示。
以上挑战都导致最终观测数据难以统一查询、聚合和可视化,导致无法对多云的观测数据进行统一查询和使用,无法构建一个全局视角的监控大盘,管理员也无法一目了然地了解所有集群的状态和性能。
对于云上业务来说,观测领域核心关注的主要是指标、trace 与日志三类观测数据。指标数据可以借助火山引擎托管 Prometheus VMP 实现多云指标的统一采集和监控告警,trace 与日志数据可以借助火山引擎日志服务 TLS 实现多云环境下的统一分析和查询,帮助企业轻松管理跨云资源。
指标数据多云观测
在业务多云部署后,企业用户往往需要统一多云集群监控运维方式,使用多云一致的数据采集能力抹平环境差异、降低采集组件改造和维护成本,同时也需要统一的数据查询入口,最终形成统一的监控视图。这种设计有助于运维人员从全局视角对分布在不同环境的集群和应用进行统一监控运维,一目了然地了解业务在不同云上的用量和健康情况。
火山引擎托管 Prometheus VMP 通过与平台的无缝集成,实现了监控数据采集、元数据、存储、视图和告警五个方面的统一指标监控能力:
统一监控采集:VMP 可以在不同的云环境中部署统一的数据采集组件 VMP Agent,后者能够统一采集节点、容器、GPU 等监控指标,也支持在通过 ServiceMonitor 配置服务发现,采集业务自定义指标;
统一元数据:通过统一的采集组件抹平不同环境元数据差异,同时增加多云场景下用户关心元数据,例如会给不同云厂商的指标增加厂商 label;
统一数据存储:通过在各个云上部署 VMP Agent,可以将多云集群观测数据统一收集到同一个 VMP 工作区中——将数据统一存储到相同的数据源有助于轻松实现多集群数据的统一查询,不需要使用额外的代理组件(如 vmproxy 进行聚合查询);
统一监控视图:基于 Grafana 提供统一的多云多集群监控视图,支持多种资源维度的可视化,包括集群组、集群、节点、命名空间、工作负载和容器等,并支持下钻与关联分析;
统一告警:基于统一观测数据和 VMP 预制的告警模板,可以在 VMP 中为多个集群配置相同的告警规则,如节点水位过高或工作负载重启,大大降低了告警策略的配置维护工作量。
trace&log 数据多云观测
多云采集:
TLS 日志服务支持多云统一采集和管理日志,并且提供日志分析的 iFrame 外嵌能力,将查询分析集成到用户自己的运维系统,简化业务使用方使用成本,提高使用效率 支持 Kubernetes deamonset 方式和 sidecar 方式收集容器日志 支持基于 Otel 标准的 trace 收集能力 实时分析:海量车机系统运行日志信息的实时写入,并通过模糊检索&SQL 函数帮助业务、运营、开发、运维人员快速分析定位问题、满足各业务使用方日志实时分析能力;
函数加工:提供超过 200+函数,包括:SQL 统计函数、聚合函数、字符串函数、IP 函数、编解码函数、时间函数,实现各种复杂场景下的统计分析需求;
观测治理:提供丰富的报表组件与仪表盘,以及多种高级仪表盘:IP 地址热力图、统计图、计量图、矩阵图、时间轴等,为运营监控提供丰富的可视化运营看板,为运维提供端到端的可观测能力;
监控告警:通过灵活的 SQL 查询分析能力结合多渠道告警能力(邮件/电话/短信/钉钉/飞书/企微/自定义渠道等),实现业务维度的服务状态实时监控。
多云网络:根据需求动态调配资源
相比单云部署,多云在网络架构上更加复杂,通过火山引擎专线连接、云企业网、中转路由器、私网连接等网络产品,企业在实施过程中可以构建一张灵活、高可用的混合云网络:
通过 专线连接 方式连接多云之间的业务网络,通过专线 & Ipsec VPN 连接方式连接办公与云上网络。为了解决专线各种故障场景下(如端口异常/光模块故障、网络设备故障、接入点机房故障等)的可靠性问题,我们推荐客户采用双接入点四线负载冗余专线的形式连接:两条物理专线分别接入不同机房的专线接入点,配合云企业网&中转路由器产品构建多线负载冗余,正常情况下多条物理专线同时转发流量,当一条线路故障不通时,另一条线路会承担全部流量的转发,以确保业务正常。同时通过划分专线网关和虚拟接口,并设置合理的 QoS,关键业务流量质量得以被充分保障; 根据长城汽车业务的隔离与管理需求,不同业务之间建设在多个账号多个 VPC 下,建设多云后需要实现多云之间多 VPC 网络环境私网互通与隔离。通过使用云企业网(CEN)和中转路由器(TR)跨地域连接能力,关联专线连接、VPN 连接、VPC 网络实例,我们可以实现多云网络私网互通。同时,通过中转路由器划分多个路由表、配置静态路由策略,我们可以实现自定义组网架构,满足业务网络隔离需求。此外,不同 VPC 对服务资源的私网访问也可以借助私网连接产品建立私密的网络连接来实现。
未来,火山引擎云原生团队将继续推动并深化与长城汽车的合作,在多云容灾等领域进行更深入的合作,更好地保障业务连续性。我们也希望能帮助更多企业积极利用不同云厂商的特点和优势,通过统一多云管理、统一流量调度、统一多云观测,保障系统的高可用和性能优化。
火山引擎云原生团队聚焦应用多云容灾架构专题联合云上多款 PaaS 产品构建多云资源分发、智能 DNS 切换、跨云流量调度、多云容灾观测、双向数据同步的一站式解决方案,致力于帮助客户构建多云应用发布、数据层同城高可用、中间件同城高可用、容灾平台构建、应用单元化改造最佳实践,满足资源弹性伸缩同时保障业务连续稳定。欢迎感兴趣的用户扫码咨询:
如有侵权请联系:admin#unsafe.sh