
2024-10-11 04:1:4 Author: hackernoon.com(查看原文) 阅读量:1 收藏
Authors:
(1) Jianhui Pang, from the University of Macau, and work was done when Jianhui Pang and Fanghua Ye were interning at Tencent AI Lab ([email protected]);
(2) Fanghua Ye, University College London, and work was done when Jianhui Pang and Fanghua Ye were interning at Tencent AI Lab ([email protected]);
(3) Derek F. Wong, University of Macau;
(4) Longyue Wang, Tencent AI Lab, and corresponding author.
Table of Links
3 Anchor-based Large Language Models
3.2 Anchor-based Self-Attention Networks
4 Experiments and 4.1 Our Implementation
4.2 Data and Training Procedure
7 Conclusion, Limitations, Ethics Statement, and References
3.2 Anchor-based Self-Attention Networks

Anchor-based Attention Masks. To accomplish this, we devise anchor-based attention masks, as illustrated in Figure 2. Assuming that the current token in the sequence is a non-anchor token, we allow attention towards previous non-anchor tokens within the same sequence and anchor tokens from preceding sequences, while blocking attention towards non-anchor tokens from previous sequences. This approach ensures that non-anchor tokens can only access information from anchor tokens in previous sequences and the current sequence’s information. Conversely, when the current token is an anchor token, which is the last token in the sequence, we exclusively permit its attention towards previous non-anchor tokens within the same sequence, blocking all other attention. This constraint forces the anchor token to aggregate information solely from its current sequence. Consequently, we replace Eq. (3) with anchor-based attention masks in Eq. (4) to determine the mask of the i-th token in the input text concerning the j-th token (assuming that the i-th token belongs to the k-th sequence).

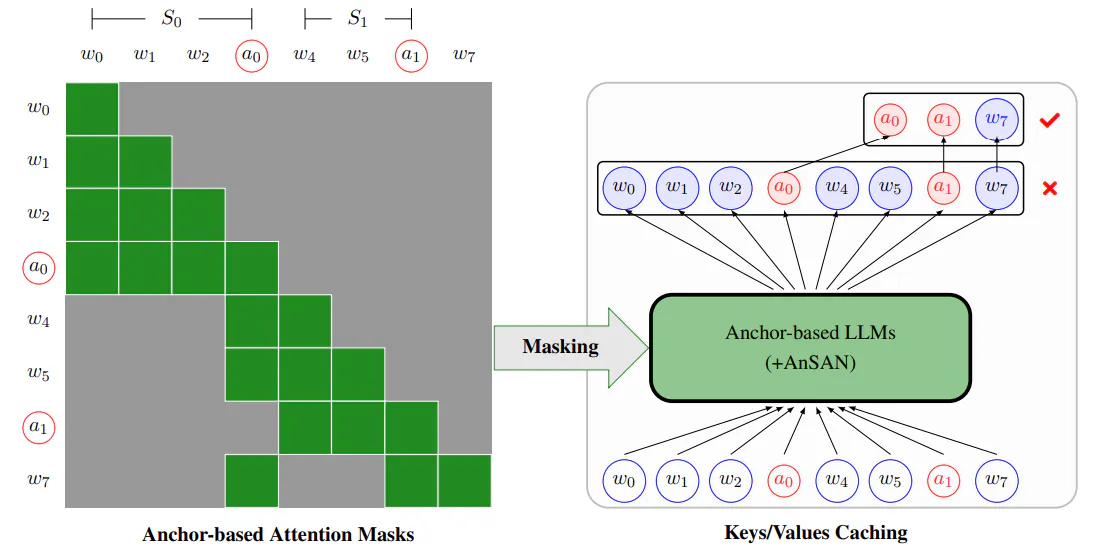
Anchor Token Selection. By implementing the AnSAN mechanism for training LLMs, we can compel the model to compress sequence information into the anchor token and generate new tokens based on the anchor token information from previous sequences and non-anchor token information from the current sequence.
The challenge now lies in selecting an appropriate anchor token. In our experiment, we propose two implementation methods: one using the endpoint as the anchor token, and the other appending a new token specifically as the anchor token.
如有侵权请联系:admin#unsafe.sh