一. 背景
随着全球范围内数据隐私问题的日益凸显,隐私保护已从单纯的合规要求,演变为企业系统设计中必须优先考虑的核心要素之一。越来越多的法规(如GDPR、CPRA)要求企业在数据处理过程中将隐私设计纳入系统开发生命周期的早期阶段。
Kim Wuyts(后简称Wuyts)认为,尽管如今隐私和安全已经被视为两个独立的领域,但它们在现代系统中的交集依然非常紧密;同时,现有的数字系统中通常已对数据安全进行了考虑,因而一个值得思考的方向是如何通过将隐私设计引入到安全设计的过程中,来提升整体系统的安全性和隐私保护能力。
二 隐私设计
2.1
隐私的核心要素
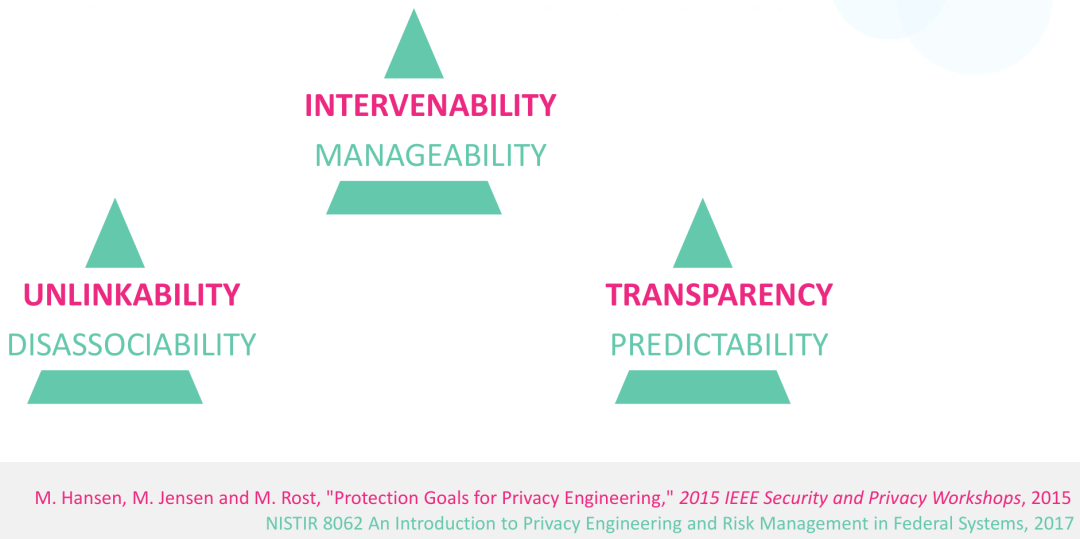
隐私设计并不仅仅是确保数据的机密性,如图1所示,如2015年文献《Protection Goals for Privacy Engineering》与NIST在2017年[1]所总结,隐私的核心要素包含:
图1:隐私的三大核心要素
不可关联性/可分离性(Unlinkability/ Disassociability):确保个人及其活动或数据无法轻易被关联到其身份或其他活动。
可干预性/可管理性(Intervenability/ Manageability):用户应能够对其个人数据进行管理和干预,比如能够撤销同意、修改或删除不准确的数据。
透明性/可预测性(Transparency/ Predictability): 用户应当能够充分理解其个人数据的使用方式,系统需要向用户清晰地解释数据处理的流程和潜在的影响。
这些要素共同构成了隐私保护的核心,它不仅仅是防止数据泄露,还需要确保用户对其数据的知情权和控制权等。
2.2
隐私与安全
如表1所示,尽管隐私和安全的关注点有所不同,但它们可以通过设计实现相互强化。
表1:安全性与隐私性的主要思考维度
隐私如何增强安全:隐私设计的重点在于减少数据收集和存储,确保数据按预期使用。通过减少不必要的数据收集,隐私设计能够降低数据泄露的潜在风险。比如,数据最小化原则不仅符合隐私保护的要求,也间接减少了系统中可能被攻击者利用的敏感数据,增强了系统的整体安全性。
2.3
威胁建模分析
为了更好地分析和理解系统中的隐私与安全威胁,如表2所示,Wuyts列举了多个知名的威胁模型框架。这些框架帮助企业系统化地识别潜在威胁,并确定适当的应对措施。
表2:知名威胁建模框架
LINDDUN[2]是最知名的隐私建模框架之一,其具体包含:
关联(Linking):个人数据可以通过组合其他数据来提取更多的信息;当不同来源的数据组合在一起时,可能会揭示出用户的身份或其他隐私信息;
识别(Identifying):数据可以被绑定到某个自然人,个人可以通过这些数据被直接识别出来,侵犯隐私;
不可否认性(Non Repudiation):无法否认某个行为或事件的参与,一旦数据被记录,个人很难否认自己与某些活动或事件有关联;这在安全维度上是必要的,但在隐私维度中某些情况下可能是不合理的;
检测(Detecting):基于观察,可能会推测出额外信息;即使没有明确的个人信息,也可能通过一些推测手段得出个人的敏感信息;
数据披露(Data Disclosure):个人数据被处理得超出预期的范围,导致敏感信息被泄露,超出了用户的控制范围;
不知情(Unawareness):用户可能对数据的收集、使用和共享情况不知情,无法有效保护自己的隐私;
不合规(Non Compliance):系统或组织缺乏或未实施隐私保护的最佳时间,导致不符合隐私法律法规的行为;
除了LINDDUN,Wuyts还介绍了其他威胁模型框架,如STRIDE(专注于安全的威胁建模)。她指出,企业在进行威胁建模时,不能仅仅局限于单一的安全或隐私视角,而应该将两者结合,进行联合分析。通过这种方式,企业可以更全面地识别潜在威胁,并制定更有效的应对策略。
三 隐私增强方案
面对隐私和安全威胁,Wuyts强调了隐私增强技术(Privacy Enhancing Technologies, PETs)的重要性。PETS为隐私保护提供了一系列有效的技术工具,帮助企业在系统设计中主动实施隐私保护。
3.1
常见的隐私设计策略
Wuyts介绍了几种常见的隐私设计策略,这些策略可以帮助企业在设计阶段就有效地保护用户隐私:
最小化(Minimize):尽量减少数据的收集和存储,尤其是敏感个人信息。
抽象化(Abstract):通过模糊数据或聚合数据来替代精确的个人数据,减少隐私风险。
分离(Separate):将不同类型的数据分开存储和处理,避免集中存储带来的风险。
隐藏(Hide):通过加密或匿名化技术隐藏个人数据,使其在未经授权的情况下无法被读取。
控制(Control):提供用户对数据的控制权,允许其撤回、修改或删除数据。
告知(Inform):确保用户对其数据的处理有充分的知情权和理解。
3.2
PETS的技术实现
虽然原报告中未对具体技术做展开介绍,但笔者以为可对下述技术值得关注:
匿名化和去标识化:通过遮掩获移除个人标识信息,确保数据无法直接关联到个人;典型技术包含-匿名、-多样性、-接近性等;
差分隐私(Differential Privacy):通过引入合适程度的噪声,保障群体分析有效性的同时,确保个体信息从数据集中被推断出来;
合成数据(Synthetic Data):一种基于真实数据生成的虚拟数据集,它保持了与真实数据类似的统计特性,但不包含真实的个人信息;
隐私计算(Privacy-PreservingComputation):隐私计算技术通过确保数据在计算过程中保持加密状态或不暴露原始数据,来实现数据共享和协同计算中的隐私保护;
3.3
PETS实施的现实挑战
尽管PETS为隐私保护提供了强有力的技术支持,但在实施过程中仍面临一些挑战:
技术复杂性:某些PETs(如差分隐私和零知识证明)在实现上可能非常复杂,企业需要投入大量资源。
性能影响:某些隐私增强技术会对系统性能产生影响,因此在设计时需要平衡隐私保护和系统效率。
用户体验:某些隐私保护措施可能影响用户体验,因此如何在保护隐私的同时保持用户的使用便捷性尤为重要。
Wuyts建议,企业应尽早在系统开发的早期阶段引入隐私保护措施,避免在后期进行昂贵的修复。
3.4
企业推进方案
Wuyts在演讲的最后提出,未来隐私和安全将更加紧密地融合在一起。她呼吁企业在设计阶段就将隐私和安全的需求结合起来,而不是将两者视为独立的、事后补救的措施。
为了更好地推动隐私保护和安全的融合,Wuyts提出了一些分阶段的实施建议:
短期目标(Next Week):从小处着手,审查现有的数据收集流程,减少不必要的数据收集,并开始评估隐私风险。
中期目标(In 3 Months):评估团队的隐私技能是否到位,并开展相关的隐私培训,培养隐私设计与安全设计的不同思维模式。
长期目标(In 6-12 Months):在未来6到12个月内,企业应全面评估其系统中的隐私和安全策略,并在开发流程中引入隐私工程实践,确保隐私保护从系统设计伊始就得到充分考虑。
同时,Wuyts强调,隐私保护不仅仅是技术问题,还需要在企业内部建立一种隐私文化。隐私保护应成为每个员工的责任,而不仅仅是合规团队或技术团队的任务。通过这种方式,企业可以更加有效地应对未来的隐私挑战,并提升用户对企业的信任。
四 总结
在这次RSAC演讲中,Wuyts深入探讨了隐私与安全设计之间的相互关系,强调两者并非独立的领域,而是可以通过巧妙的设计实现相互促进。现代企业应着眼于将隐私设计融入到安全设计中,并通过隐私增强技术(PETS)和威胁建模等方式,确保系统在开发的每个阶段都具备隐私保护能力。
参考文献
[1]: https://nvlpubs.nist.gov/nistpubs/ir/2017/nist.ir.8062.pdf
[2]: https://threat-modeling.com/linddun-threat-modeling
内容编辑:创新研究院 顾奇
责任编辑:创新研究院 陈佛忠
本公众号原创文章仅代表作者观点,不代表绿盟科技立场。所有原创内容版权均属绿盟科技研究通讯。未经授权,严禁任何媒体以及微信公众号复制、转载、摘编或以其他方式使用,转载须注明来自绿盟科技研究通讯并附上本文链接。
关于我们
绿盟科技研究通讯由绿盟科技创新研究院负责运营,绿盟科技创新研究院是绿盟科技的前沿技术研究部门,包括星云实验室、天枢实验室和孵化中心。团队成员由来自清华、北大、哈工大、中科院、北邮等多所重点院校的博士和硕士组成。
绿盟科技创新研究院作为“中关村科技园区海淀园博士后工作站分站”的重要培养单位之一,与清华大学进行博士后联合培养,科研成果已涵盖各类国家课题项目、国家专利、国家标准、高水平学术论文、出版专业书籍等。
我们持续探索信息安全领域的前沿学术方向,从实践出发,结合公司资源和先进技术,实现概念级的原型系统,进而交付产品线孵化产品并创造巨大的经济价值。
如有侵权请联系:admin#unsafe.sh