作者们实现了 ChatAFL,让 LLM 生成机器可读的协议格式,按照协议格式进行变异和 fuzzing,在覆盖率到达某个程度不变时,让 LLM 生成可以触发新状态/覆盖率的输入。
来看看别人是怎么借助 LLM 优化协议 fuzz 的,这一篇应该是 NDSS 2024 的论文,作者们来自新加坡国立大学和莫纳什大学的 MPI-SP。(我也想蹭热点呜呜呜)
看看概要。
- RFC 文档用人类语言定义了协议(很难讲人类语言转换为机器语言)
- LLM 学习了数百万计的文档,可以转换成机器可读的协议信息
- 作者们实现了 ChatAFL
看看第一章
- LLM 引导的协议模糊测试,包含三个部分:
- 使用 LLM 为协议提取机器可读的语法,用于结构感知的突变;
- (猜想)有点类似于协议状态机的提取
- 使用 LLM 增加初始种子中消息的多样性;
- 使用 LLM 突破稳定期,让 LLM 生成可以到达新状态的信息。
- 使用 LLM 为协议提取机器可读的语法,用于结构感知的突变;
- 看上去,似乎也很适合黑盒协议 fuzz?
- 开源代码:https://github.com/ChatAFLndss/ChatAFL
接下来看看第二章,作者提出的挑战:
- 依赖初始种子
- 这个确实
- 未知的消息结构
- 按照介绍的意思是说,如果没有机器可读的结构信息,fuzzer 就不能根据结构进行有趣的更改。
- 未知的状态空间
- 同上,没有可读的状态空间信息就无法探索状态空间。
看看作者们的动机,怎样通过 LLM 解决上述的三个问题:
- 要求 LLM 在给定的种子信息中添加随机信息
- 那是怎么问的呢,猜想一下,“这是一个 RTSP 协议的指令序列,请根据 RTSP 协议的结构帮我随机修改其中的结构”,这样子吗?
- 要求 LLM 为协议提供机器可读的结构信息
- 让 LLM 根据 fuzzer 和被测实体之间的信息交换,返回一条能够进入新状态空间的信息
(第三章就是在证明上面三个问题都能被 LLM 解决)
然后看看作者们的 Prompt:
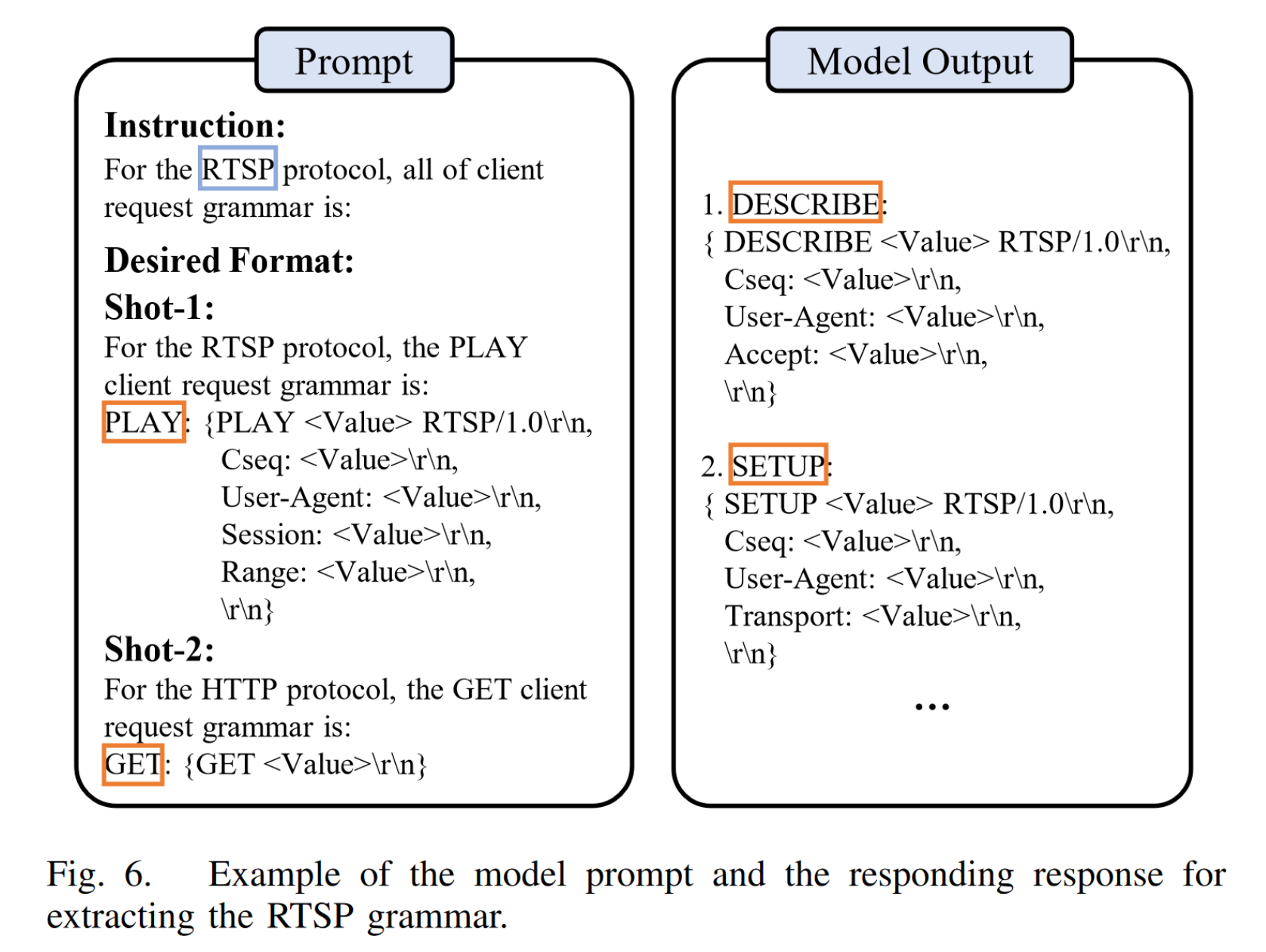
提取语法:
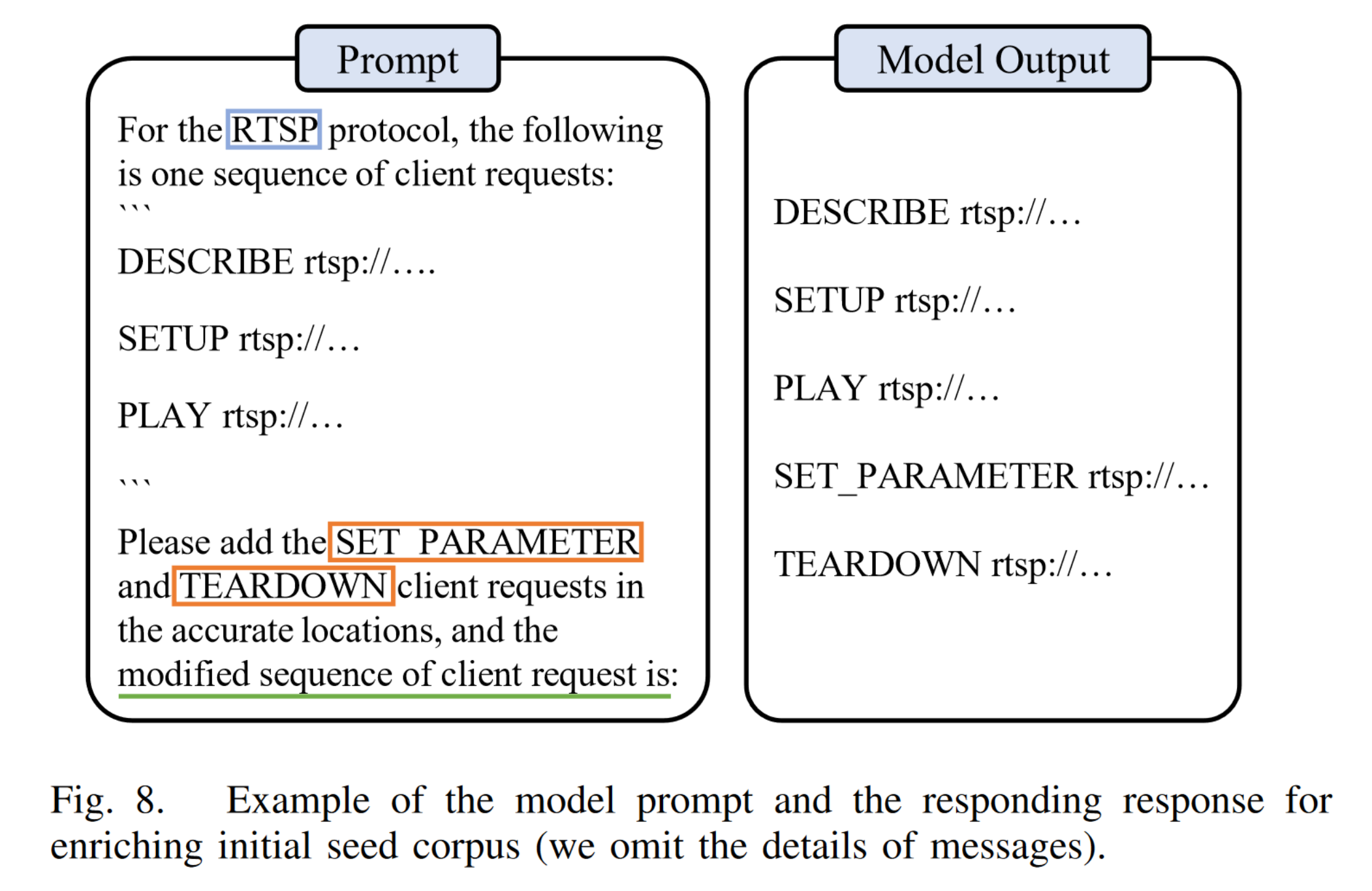
增强种子:
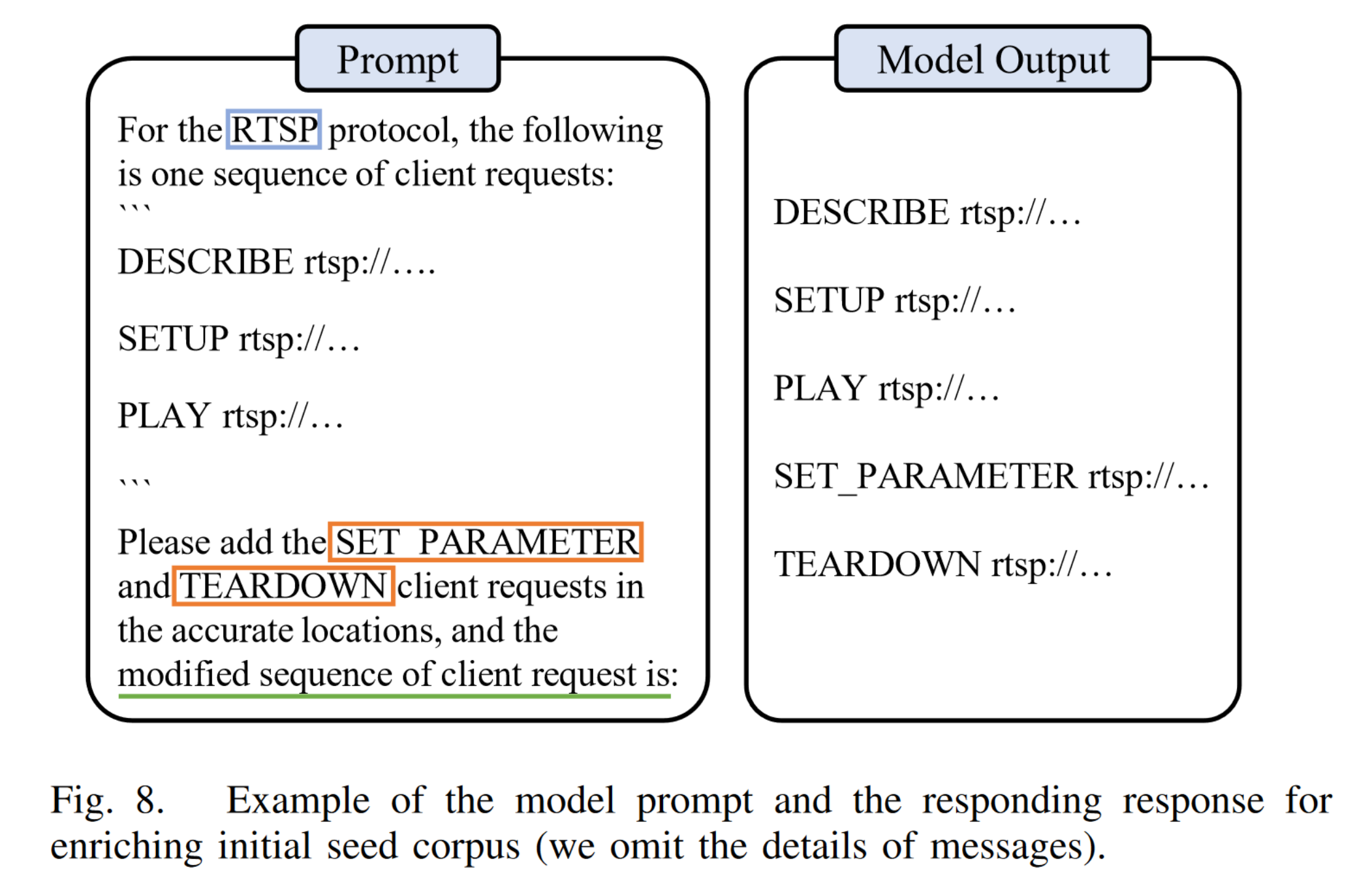
提升覆盖率/状态空间:

- 这么一看似乎只要学习协议就可以了,覆盖率的提升/状态的提升有没有反哺给模型呢?
- 看上去没有,那么这可能是未来的点吗?
- 除此之外,有没有可能 antifuzz 呢?
- 似乎不大行,这是一个 prompt 就能解决的事
- 除非能穿透 openai,直接攻击到他们的核心服务
- 似乎不大行,这是一个 prompt 就能解决的事
状态和覆盖率对 fuzz 的反哺
根据第第 4 章,状态/覆盖率用于检测是否到达某个极限的值(被作者们称为覆盖高原 coverage plateau),到达这个状态之后会让 LLM 返回一条能进入新状态的信息(也就是上文中的第三条)
- 理论上覆盖率、状态变量、状态值都可以用于触发,这样可以在黑盒上做类似的工作?(只需要状态)
与其他 LLM Fuzz 的区别
- Codamosa:第一个将 LLM 引入 fuzz,自动生成 Python 模块的测试用例;
- TitanFuzz/FuzzGPT:为深度学习库生成测试用例;
- ChatFuzz:让 LLM 修改人类编写的测试用例。