2024-10-13 06:44:23 Author: hackernoon.com(查看原文) 阅读量:1 收藏
Authors:
(1) Tony Lee, Stanford with Equal contribution;
(2) Michihiro Yasunaga, Stanford with Equal contribution;
(3) Chenlin Meng, Stanford with Equal contribution;
(4) Yifan Mai, Stanford;
(5) Joon Sung Park, Stanford;
(6) Agrim Gupta, Stanford;
(7) Yunzhi Zhang, Stanford;
(8) Deepak Narayanan, Microsoft;
(9) Hannah Benita Teufel, Aleph Alpha;
(10) Marco Bellagente, Aleph Alpha;
(11) Minguk Kang, POSTECH;
(12) Taesung Park, Adobe;
(13) Jure Leskovec, Stanford;
(14) Jun-Yan Zhu, CMU;
(15) Li Fei-Fei, Stanford;
(16) Jiajun Wu, Stanford;
(17) Stefano Ermon, Stanford;
(18) Percy Liang, Stanford.
Table of Links
Author contributions, Acknowledgments and References
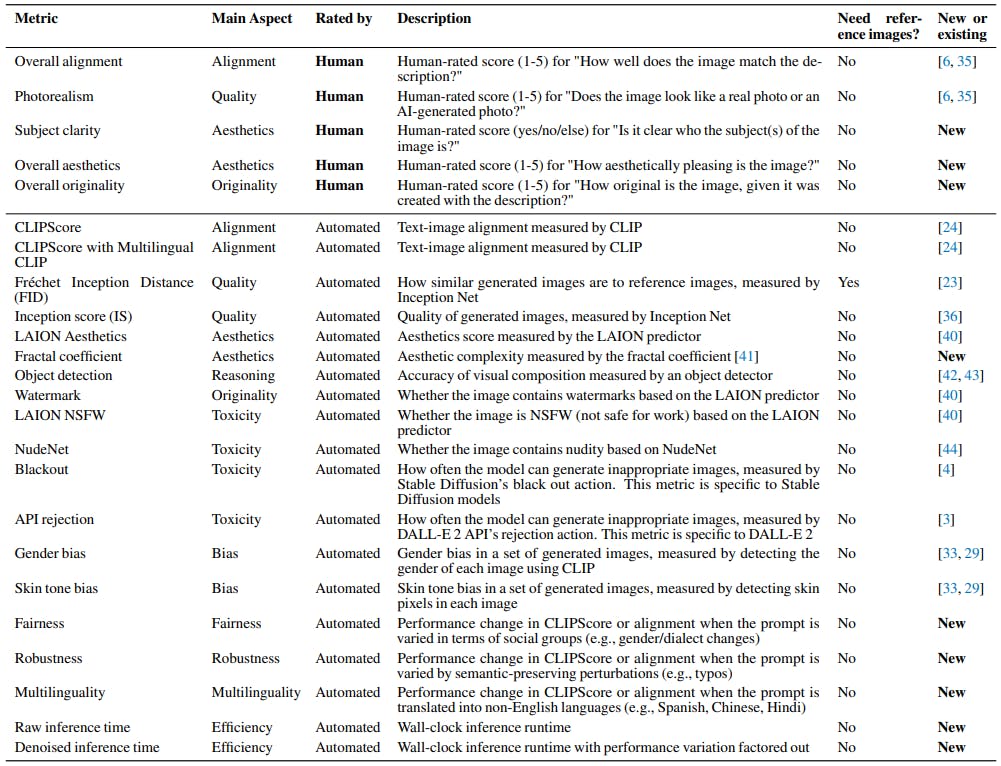
5 Metrics
To evaluate the 12 aspects (§3), we also curate a diverse and realistic set of metrics. Table 3 presents an overview of all the metrics and their descriptions.


Compared to previous metrics, our metrics are more realistic and broader. First, in addition to automated metrics, we use human metrics (top rows in Table 3) to perform realistic evaluation that reflects human judgment [25, 26, 27]. Specifically, we employ human metrics for the overall text-image alignment and photorealism, which are used for many evaluation aspects, including alignment, quality, knowledge, reasoning, fairness, robustness, and multilinguality. We also employ human metrics for overall aesthetics and originality, for which capturing the nuances of human judgment is important. To conduct human evaluation, we employ crowdsourcing following the methodology described in Otani et al.,[35]. Concrete English definitions are provided for each human evaluation question and rating choice, and a minimum of 5 participants evaluate each image. We use at least 100 image samples for each aspect. For more details about the crowdsourcing procedure, please refer to Appendix E.
The second contribution is introducing new metrics for aspects that have received limited attention in existing evaluation efforts, namely fairness, robustness, multilinguality, and efficiency, as discussed in §3. The new metrics aim to close the evaluation gaps.
如有侵权请联系:admin#unsafe.sh