Welcome back to Part 3, the final part of our series on Destructive IoT Malware Emulation. If you’re new here, in Part 1 we described how to set up the environment to emulate the destructive IoT malware, AcidRain. Part 2 explained how and why we hooked some syscalls to fully emulate AcidRain.
Ready for the next big step? We teased in Part 2 that we wanted to see how well the emulation works, but quantitatively.
We already have robust logging for all the syscalls from Qiling itself. Out of personal interest, we wanted additional logging. First, we wanted to log all instructions so we might be able to color the execution path in IDA Pro or Ghidra. Additionally, we wanted a separate log for every process.
Secondly, Qiling has the functionality to create a coverage file by itself, which we can load into IDA Pro or Ghidra.
Sounds cool and fun, right? But as we said before, there’s still a bit to do, so let’s dig into it.
Logging
To begin with, we create a directory for each emulation identified by the timestamp and sample name. Additionally, we create a result file for the entire emulation that contains information of all processes, and this file is named according to the emulation case.
# Create directory for resutls of current emulation
result_path = f"{sys_os.path.dirname(ABSOLUTE_PATH)}/results/{self.timestamp}_{self.binary_name}/"
sys_os.makedirs(result_path, exist_ok=True)
# Create result file for entire emulation
result_path = f"{result_path}results_{self.mtd_type}_{self.root}.json"
open(result_path, 'w').close()
Before we start writing data to a file — which is, by the way, not trivial due to the different processes — we need to collect the data. First, we hook on the code level to collect each instruction address in an array. For each instruction, we check for a syscall with the opcode 0x0000000c. The ID of the syscall is stored in the v0 register in the MIPS architecture. Using this ID, we search for the syscall name in our MIPS syscall table and save this information in an array as well.
def log_syscall_with_id(self, ql: Qiling, address, size, *args, **kwargs) -> None:
# Get the mips syscall table for translating ids into syscall function names
mapper = lin.mips_syscall_table
# Append every instruction address
ins_address = hex(address)
if ins_address not in self.instruction_addresses:
self.instruction_addresses.append(ins_address)
if ql.mem.read(address, size) == b'\x00\x00\x00\x0c':
# In case of system call
syscall_id = ql.arch.regs.read("v0") # stored syscall id
syscall_name = mapper.get(syscall_id)
# Create syscall element and append it for results file
syscall_info = {
"syscall_num": syscall_id,
"syscall_name": syscall_name
}
if syscall_info not in self.syscalls:
self.syscalls.append(syscall_info)
We want to write this collected information into our file. For example, one could format it as JSON:
{
"syscalls": [
{
"syscall_num": 4004,
"syscall_name": "write"
}
],
"instruction_addresses": [
"0x4002a0",
"0x4002a4",
"0x4002a8",
"0x4002ac"
]
}
With this setup, we have a comprehensive overview and collection of all process information. However, we also want to collect data for each process and write it into both an individual file and a summary file. If we implement it just this way, the consequence is that each process will carry the results of the parent process, leading to duplicated entries.
The idea is to clear the arrays of instructions and syscalls for each new process. The simplest way to achieve this is by using our existing fork hook. When the fork creates a new process, we want to clear these arrays in the child process. This can be done by expanding our fork hook as follows:
# In case of childprocesses
if ql.os.child_processes:
# Clear collected information in child cause parent will keep it
self.instruction_addresses.clear()
self.syscalls.clear()
Now, we are creating the result file, locking it, creating the JSON object, and writing it to the result file. The challenging part is that each process needs to write into that file after each emulation.
- First, we need to lock the file to ensure no other process can write to it simultaneously.
- Then, we need to load the data and append the new data to the loaded data.
- Finally, we write the content back to the result file and unlock it.
def generate_result_file(self):
'''
Generate resultfile for current emulation. Each process will write its result into the file.
'''
# Unique path for each emulation
result_path = f"{sys_os.path.dirname(ABSOLUTE_PATH)}/results/{self.timestamp}_{self.binary_name}/"
self.result_path = result_path
result_file_path = f"{result_path}results_{self.mtd_type}_{self.root}.json"
with open(result_file_path, 'r+') as file:
fcntl.flock(file.fileno(), fcntl.LOCK_EX)
try:
# Load content of the result file
existing_data = json.load(file)
except json.JSONDecodeError:
# If content is empty, set basic structure
existing_data = {"syscalls": [], "instruction_addresses": [], "blocks": []}
# Expand instruction address only in case it's not already in the result file
for address in self.instruction_addresses:
if address not in existing_data["instruction_addresses"]:
existing_data["instruction_addresses"].append(address)
# Expand syscall only when it does not exist in result file
for syscall in self.syscalls:
if syscall not in existing_data["syscalls"]:
existing_data["syscalls"].append(syscall)
# Write content back to result file and unlock
file.seek(0)
json.dump(existing_data, file, indent=4)
file.truncate()
fcntl.flock(file.fileno(), fcntl.LOCK_UN)
Additionally, we can easily create separate log files for each process, which you can find in our Qiliot GitHub project.
Custom IDA Script
To work with our result files, we developed a simple IDA script that marks instructions which were executed and prints out some basic statistics. This is primarily to demonstrate what is possible and to give us a closer look at how well the emulations work. To avoid going too deep into details, we will only explain a few interesting aspects. The plugin collects all virtual addresses of instructions from the .text, .init, and .fini segments.
It is important to note that AcidRain is statically linked malware, which means that all the library functions it uses are included in the sample. Through static analysis, we can determine that the core of AcidRain is between 0x00400310 and 0x004017540. So, we are collecting all addresses of instructions within the AcidRain core. This allows us to see how much of the core was emulated.
Using the results file, the script parses all result files located in our AcidRain result folder and collects all addresses from each emulation case.
START_ACIDRAIN_CORE = 0x00400310
END_ACIDRAIN_CORE = 0x00401740
def collect_core_instrutions(self) -> None:
'''
Compares virtual addresses in IDA with the addresses in the results.json file.
If the addresses from the result file are in the segment of the binary file in IDA,
self.emu_main_addresses will be extended with this address.
'''
next_acidrain_address = START_ACIDRAIN_CORE
while next_acidrain_address <= END_ACIDRAIN_CORE:
if next_acidrain_address not in self.main_addresses:
if idaapi.ua_mnem(next_acidrain_address) is not None:
self.main_addresses.add(next_acidrain_address)
next_acidrain_address = idc.next_head(next_acidrain_address)
It sounds really simple, but the results can vary if we don’t pay attention to small details. For example, in the MIPS architecture, disassemblers often simplify code such as address calculations, which is also the case for IDA.

This means that for the calculation, there might be two instructions, but the compiler condenses it into one.

In IDA, you can turn this setting on or off when you load the sample:

The consequence is that in the emulation, two instructions are counted, but in IDA, we only see one. This can and will affect your coverage results. With the code idaapi.ua_mnem(next_acidrain_address), you can retrieve the mnemonic of the instruction. For the second address in this case, the function will return None. Thus, we can disregard this virtual address in the further calculations.
Coverage File
Qiling also provides a plugin to collect code coverage information and save it in the DRCOV format, making the results suitable for further processing or manual viewing. It offers both a command-line interface and an API, making it easy to integrate with your Python scripts.

The idea is to create the coverage file using a with statement and collect all necessary information while ql.run() executes the emulation.
with cov_utils.collect_coverage(ql, 'drcov', "my_coverage_file.cov"):
ql.run()
However, the result is an incomplete coverage file. Why? As mentioned earlier, AcidRain initiates multiple processes. The coverage functionality does not update the coverage file properly, the outcome: the basic blocks in the DRCOV file are not completed.
To address this, we need to make adjustments for our emulation.
Initializing the Coverage File
The idea is to create our own coverage file generator, which is available in our Qiliot GitHub project.
But first things first. We started by generating a coverage file and opening it in a hex editor to analyze its structure and the information it contains. With that understanding, we proceeded to write our own Qiling coverage Python script. To achieve this, we created a class that initializes the coverage file:
class QiliotCov(QlDrCoverage):
'''
Qiliot coverage built on Qiling coverage.
This enables to have a coverage file that includes every created process
'''
def __init__(self, ql, filename):
'''
Initialize Qiliot coverage with extanded attributes.
'''
super().__init__(ql)
self.filename = filename
self._init_file()
def _init_file(self) -> None:
'''
Internal function to initalize the coverage file.
'''
with open(self.filename, "wb"):
pass
We reversed the coverage file and could see how the header was defined:
DRCOV VERSION: XXX
DRCOV FLAVOR: XXX
Module Table: version XXX, count XXX
Columns: id, base, end, entry, checksum, timestamp, path
XXX, XXX, XXX, XXX, XXX, XXX, XXX
BB Table: 00000000 bbs
Note: XXX is a placeholder for the values.
We are writing exactly this header into our coverage file. The necessary values are obtained from the Qiling class QlDrCoverage.
def write_header(self, cov) -> None:
'''
Writes the header for the coverage file.
Args:
cov: Coverage file which need to be updated.
'''
cov.write(f"DRCOV VERSION: {self.drcov_version}\n".encode())
cov.write(f"DRCOV FLAVOR: {self.drcov_flavor}\n".encode())
cov.write(f"Module Table: version {self.drcov_version}, count {len(self.ql.loader.images)}\n".encode())
cov.write("Columns: id, base, end, entry, checksum, timestamp, path\n".encode())
for mod_id, mod in enumerate(self. ql.loader.images):
cov.write(f"{mod_id}, {mod.base}, {mod.end}, 0, 0, 0, {mod.path}\n".encode())
cov.write("BB Table: 000000000 bbs\n".encode())
Writing the Basic Blocks
So, in fact, it’s the same as with our logging files; Each process needs to append its information, and our Qiling coverage needs to write it to a file and clear the basic blocks for the new process.
# Open coverage file
with open(self.filename, "rb+") as cov:
fcntl.flock(cov.fileno(), fcntl.LOCK_EX)
if cov.seek(0, os.SEEK_END) == 0:
# Initalize header in empty file
self.write_header(cov)
# Write basic block into file
for bb in self.basic_blocks:
cov.write(bytes(bb))
cov.seek(0, os.SEEK_SET)
Additionally, the header contains the length of the basic blocks, which needs to be updated by adding the collected basic block length to the value that is already present. To do this, we search for the line that starts with BB Table: in the coverage file. After finding it, we get the old length by parsing the value with line[10:19] and the current length with len(self.basic_blocks) and add them together.
With cov.seek(-len(line) + 10, os.SEEK_CUR) we move the file pointer to the correct position and update the length:
while True:
# Read the file to get needed information in header
line = cov.readline()
if not line:
raise Exception("Coverage file seems to be corrupted.")
if line.startswith(b"BB Table:"):
# Get the BasicBlock header, update length and write basic blocks into the file.
new_len = int(line[10:19]) + len(self.basic_blocks)
print(f"filename: {self.filename} Update length from {line[10:19]} to {new_len}", flush=True)
cov.seek(-len(line) + 10, os.SEEK_CUR)
cov.write(f"{new_len:09d}".encode())
break
fcntl.flock(cov.fileno(), fcntl.LOCK_UN)
Admittedly this is quite the hack, but it’s the best you can do in a concurrent scenario such as this.
Now, the output is that we have a coverage file for each emulation case. Okay, but now what? Where are the numbers? Hold on a second — first, let’s explain which plugins you can use.
Results
With the generated coverage file (DRCOV), we can load it into our disassembler of choice. We are working with IDA Pro, but don’t panic—this is also possible in Ghidra. In both cases, we will explain how to load the file into your disassembler, and afterward, we’ll discuss the resulting numbers.
IDA Pro with Lighthouse
To load the coverage file (DROV), the plugin you need is Lighthouse. It is a powerful code coverage explorer for IDA Pro and Binary Ninja. Simply download the files from the repository and place them in your IDA \plugins folder, and you’re good to go.
In IDA, under File -> Load File -> Code coverage file ..., you can load one or more coverage files at once.
With Lighthouse, you have the ability to see instructions highlighted in both the assembler view, disassembler view, and the Path View. You can also see the number of times each basic block was executed within a function, as well as the percentage of instructions executed.
Additionally, you can view the average of all coverage files or compare two coverage files with each other.
Ghidra with Cartographer
For Ghidra, you can use Cartographer — the Code Coverage plugin. The installation requires a few steps, as described in the README:
- Launch Ghidra.
- Navigate to the Install Extensions window with
File -> Install Extensions... - Click the green “+” icon at the top-right corner.
- Select the downloaded ZIP file to load the plugin into Ghidra.
- Click the “OK” button to exit the Install Extensions window.
- Restart Ghidra when prompted.
After installation, you can load the Code Coverage file from the Tools Menu under Tools -> Code Coverage -> Load Code Coverage File(s) .... The functionality is similar to Lighthouse.
Finally the Numbers
All the data in this section will be visualized in IDA Pro using the Lighthouse plugin and our custom plugin.
Results of the Entire Sample
Despite using different parameters in each emulation, the differences in coverage between the scenarios were minimal. For example, whether AcidRain was running with root privileges or not had no significant effect; only the order of execution varied.

The only notable difference in outcomes was observed when varying the mtd_type (NANDFLASH), as shown in Figure 04.
A more substantial impact on the results comes from the rootfs, which is obvious. We achieved the best results with the rootfs extracted from the original firmware of the modem where AcidRain runs.
Using the rootfs provided by Qiling itself, we achieved less than 2% coverage. We observed around 10% less coverage with a nearly empty rootfs, which is expected since AcidRain deletes directories, unlinks files, and so on. With a rootfs that triggers all of AcidRain’s functionality, we were able to achieve an overall coverage of 73.09%.
Note: AcidRain is statically linked IoT malware. The library functions can be detected with FLIRT and the appropriate signatures. After applying FLIRT, the results may vary slightly, but not significantly.
We found a suitable signature file here: uclibc-sig on GitHub, which can be loaded into IDA Pro. For Ghidra, we found this project: ApplySig on GitHub, which allows you to apply the signature file.
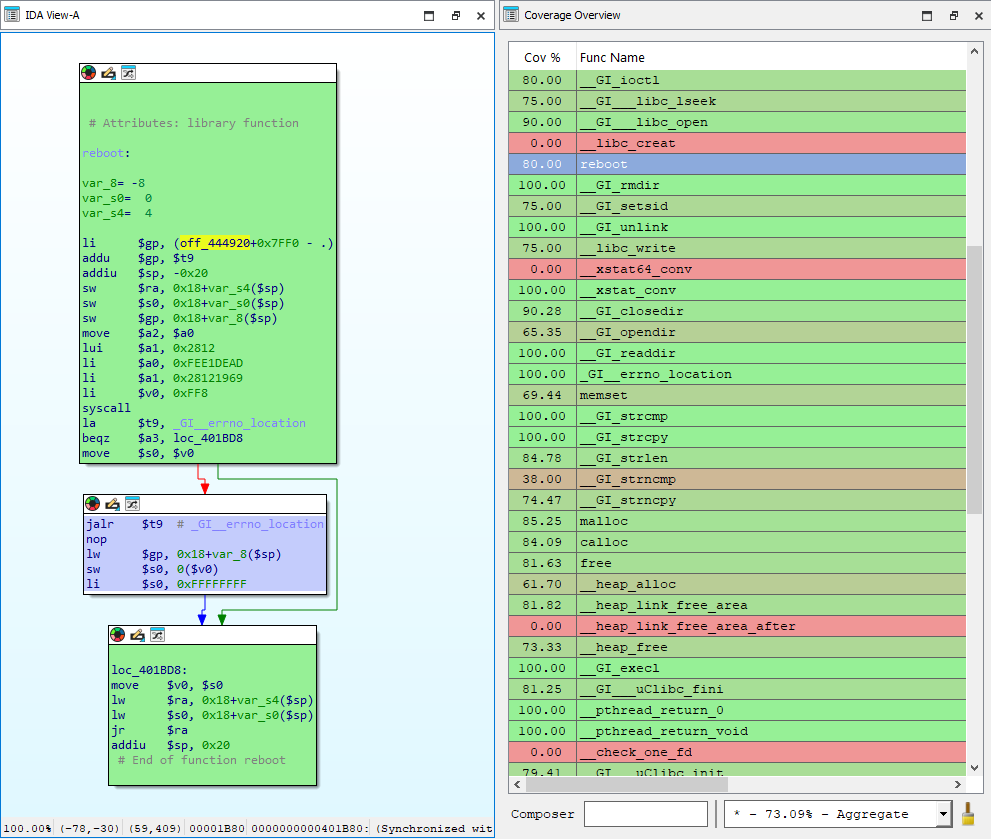
So far, the result is promising but not particularly impressive. What about the remaining 37% of AcidRain? To be fair, not every library function was emulated. For instance, loading and starting the C application weren’t fully covered. Additionally, there is a significant amount of error handling that wasn’t obviously executed, as shown in Figure 05, particularly in the reboot function.

Now, let’s take a closer look at the coverage of AcidRain’s core functions.
Results of the Core Function
The core functions of AcidRain are located between the virtual addresses 0x00400310 and 0x00401744. In Figure 06, you can see that nearly every function prefixed with acidRain_ was covered across the four emulation cases.

Using our results file and the plugin, we can print out how extensively the entire AcidRain malware was emulated, as well as just the core. The following result was obtained:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
It’s quite impressive that the AcidRain core was emulated to 96.95% across all four emulation cases. With library functions included, AcidRain was emulated to 73.09%, which is identical to the coverage result from before. The difference between the coverage of the core and the full sample is quite normal because not all library functions were executed or triggered during the emulation.
And that’s it. We hope you enjoyed the blog series about IoT malware emulation and creating a safe dynamic analysis environment. We hope you found it informative and had fun trying it out. Thanks for reading, and stay tuned for more exciting blogs!