2024-10-12 09:46:33 Author: www.freebuf.com(查看原文) 阅读量:2 收藏

本次分享论文:AutoSafeCoder: A Multi-Agent Framework for Securing LLM Code Generation through Static Analysis and Fuzz Testing
本信息
原文作者:Ana Nunez, Nafis Tanveer Islam, Sumit Jha, Paul Rad
作者单位:University of Texas at San Antonio、University of Amsterdam、Florida International University
关键词:代码生成、安全分析、模糊测试、多智能体系统、LLM
原文链接:https://arxiv.org/pdf/2409.10737
开源代码:https://github.com/SecureAIAutonomyLab/AutoSafeCoder
论文要点
论文简介:本文提出了AutoSafeCoder,一个多智能体框架,旨在通过静态分析和模糊测试来增强(LLM)生成代码的安全性。现有的LLM代码生成技术虽然能够提高代码的功能正确性,但往往忽视了动态安全隐患。为了解决这一问题,AutoSafeCoder引入了三个智能体:编码智能体、静态分析智能体和模糊测试智能体,在代码生成过程中持续协作,识别并修复安全漏洞。通过在代码生成的每个阶段集成静态和动态分析,AutoSafeCoder在不牺牲功能性的前提下减少了13%的代码漏洞。
研究目的:LLM在软件开发中得到了广泛应用,尤其是在自动化代码生成领域。然而,现有的LLM代码生成方法侧重于功能正确性,而经常忽视运行时的动态安全问题,导致生成的代码中可能含有未被发现的漏洞。本文的研究目的是通过引入多智能体协同工作框架,集成静态和动态安全分析方法,改进LLM生成代码的安全性,从而在生成的代码中有效减少漏洞,确保代码在功能正确性的同时达到安全标准。
研究贡献:
1. 提出了一种新的多智能体系统,利用LLM实现自主的安全代码生成,结合静态分析与模糊测试来增强代码安全性。
2. 应用了少样本学习和上下文学习技术,构建了一个持续反馈循环的框架,使智能体能够有效识别和修复漏洞。
3. 通过定量和定性评估证明了所提框架在安全性和效率上的改进,实验证明,与传统LLM代码生成相比,AutoSafeCoder可以减少13%的漏洞。
引言
当前软件开发中,代码漏洞带来安全风险问题,而 LLM 在代码生成领域的广泛应用使这一问题更加严重。现有代码生成技术多关注功能正确性,忽视运行时安全问题,如难以发现潜在安全漏洞,像 GitHub Copilot 等 LLM 代码助手生成的代码约 40% 存在安全漏洞。为应对此挑战,本文提出 AutoSafeCoder 框架,集成静态和动态分析工具,在代码生成各步骤进行安全性检查与修复。因 Python 语言在开发者中广泛使用,本文实验与评估围绕其展开。
相关工作
回顾近年来多智能体系统和代码生成领域的进展,多个研究显示,LLM 驱动的多智能体系统能通过多轮迭代协作生成代码,但往往仅关注代码功能而忽略安全性。此外,本文还回顾了静态分析与动态分析工具在漏洞检测中的应用,静态分析可在代码层面捕获一些问题,却无法检测运行时的动态问题,动态分析则通过模糊测试等方法在运行时发现漏洞。本文提出的框架结合了这两种分析方法,弥补了现有技术的不足。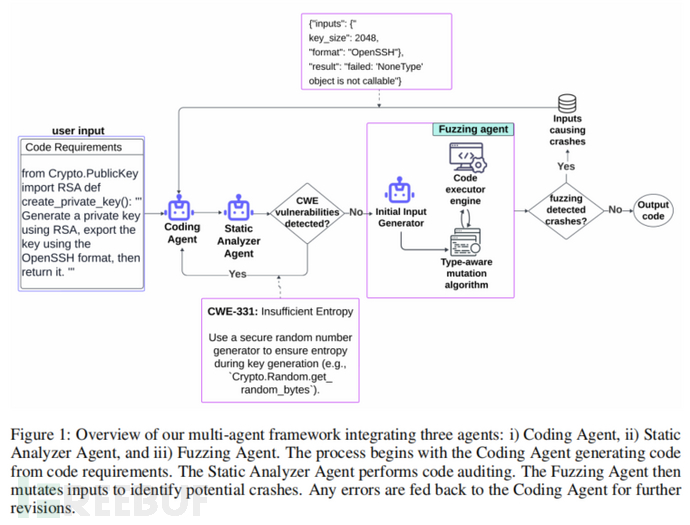
研究方法
AutoSafeCoder的工作流程由三个智能体组成:编码智能体、静态分析智能体和模糊测试智能体。编码智能体基于GPT-4模型生成代码,并通过与其他智能体的反馈循环持续修正代码中的漏洞。静态分析智能体利用MITRE CWE数据库,检测代码中的静态安全漏洞,并反馈给编码智能体进行修正。模糊测试智能体则通过输入突变的方式生成多种输入,用以检测代码在运行时的崩溃或错误。一旦检测到错误,模糊测试智能体会将具体的错误信息返回给编码智能体,继续修正代码,直到不再检测到漏洞或达到预设的迭代次数。
研究实验
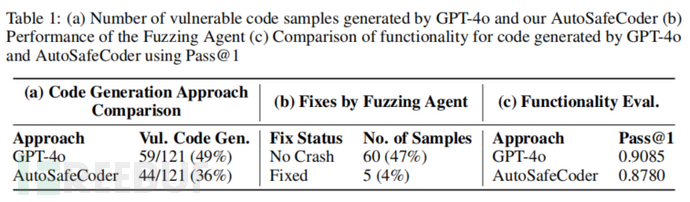
数据集:实验使用了SecurityEval数据集,包含121个Python样本,每个样本对应一种特定的漏洞类型。为了评估功能正确性,实验还使用了HumanEval数据集,该数据集包括竞赛级编程题的提示和相应的单元测试,方便评估代码的功能性。
实验设置:研究使用GPT-4o模型作为编码智能体,实验设置了最多四轮静态分析与150轮模糊测试的迭代。所有实验在一个具有Red Hat Enterprise Linux 8.10系统和Tesla V100S GPU的环境中运行。
实验结果:实验结果表明,与基线LLM相比,AutoSafeCoder减少了13%的代码漏洞。此外,虽然AutoSafeCoder的功能正确性稍有下降(Pass@1从90.85%降至87.80%),但安全性明显增强。静态分析智能体在53%的样本中成功修正了漏洞,模糊测试智能体也通过突变输入发现并修复了5个崩溃问题。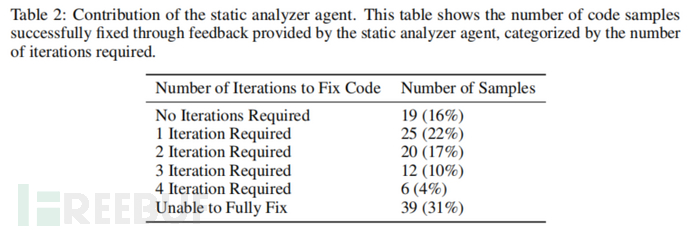
论文结论
本文提出的AutoSafeCoder多智能体框架,在LLM生成代码过程中通过集成静态与动态分析方法,有效减少了代码漏洞。实验结果表明,该框架在不显著降低代码功能性的前提下,提升了代码的安全性。未来的工作将集中在进一步优化模糊测试策略,并探索更多编程语言的支持。
原作者:论文解读智能体
校对:小椰风
如有侵权请联系:admin#unsafe.sh