
We’ve just released Llamafile 0.8.14, the latest version of our popular open source AI tool. A Mozilla Builders project, Llamafile turns model weights into fast, convenient executables that run on most computers, making it easy for anyone to get the most out of open LLMs using the hardware they already have.
New chat interface
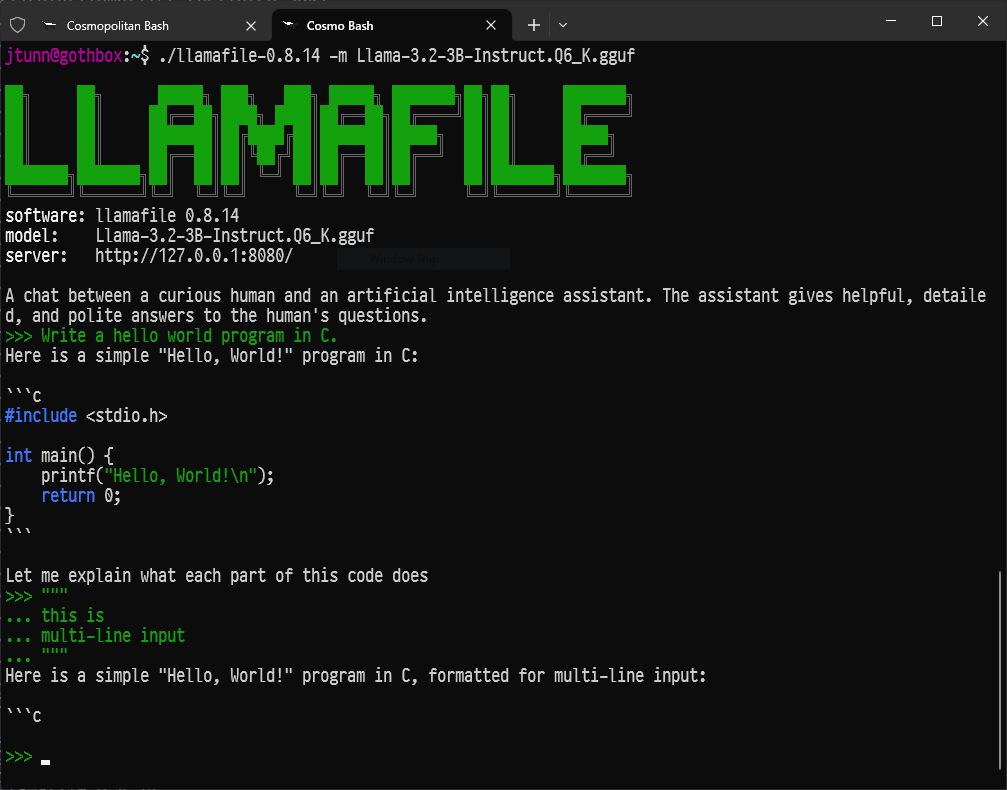
The key feature of this new release is our colorful new command line chat interface. When you launch a Llamafile we now automatically open this new chat UI for you, right there in the terminal. This new interface is fast, easy to use, and an all around simpler experience than the Web-based interface we previously launched by default. (That interface, which our project inherits from the upstream llama.cpp project, is still available and supports a range of features, including image uploads. Simply point your browser at port 8080 on localhost).
Other recent improvements
This new chat UI is just the tip of the iceberg. In the months since our last blog post here, lead developer Justine Tunney has been busy shipping a slew of new releases, each of which have moved the project forward in important ways. Here are just a few of the highlights:
Llamafiler: We’re building our own clean sheet OpenAI-compatible API server, called Llamafiler. This new server will be more reliable, stable, and most of all faster than the one it replaces. We’ve already shipped the embeddings endpoint, which runs three times as fast as the one in llama.cpp. Justine is currently working on the completions endpoint, at which point Llamafiler will become the default API server for Llamafile.
Performance improvements: With the help of open source contributors like k-quant inventor @Kawrakow Llamafile has enjoyed a series of dramatic speed boosts over the last few months. In particular, pre-fill (prompt evaluation) speed has improved dramatically on a variety of architectures:
- Intel Core i9 went from 100 tokens/second to 400 (4x).
- AMD Threadripper went from 300 tokens/second to 2,400 (8x).
- Even the modest Raspberry Pi 5 jumped from 8 tokens/second to 80 (10x!).
When combined with the new high-speed embedding server described above, Llamafile has become one of the fastest ways to run complex local AI applications that use methods like retrieval augmented generation (RAG).
Support for powerful new models: Llamafile continues to keep pace with progress in open LLMs, adding support for dozens of new models and architectures, ranging in size from 405 billion parameters all the way down to 1 billion. Here are just a few of the new Llamafiles available for download on Hugging Face:
- Llama 3.2 1B and 3B: offering extremely impressive performance and quality for their small size. (Here’s a video from our own Mike Heavers showing it in action.)
- Llama 3.1 405B: a true “frontier model” that’s possible to run at home with sufficient system RAM.
- OLMo 7B: from our friends at the Allen Institute, OLMo is one of the first truly open and transparent models available.
- TriLM: a new “1.58 bit” tiny model that is optimized for CPU inference and points to a near future where matrix multiplication might no longer rule the day.
Whisperfile, speech-to-text in a single file: Thanks to contributions from community member @cjpais, we’ve created Whisperfile, which does for whisper.cpp what Llamafile did for llama.cpp: that is, turns it into a multi-platform executable that runs nearly everywhere. Whisperfile thus makes it easy to use OpenAI’s Whisper technology to efficiently convert speech into text, no matter which kind of hardware you have.
Get involved
Our goal is for Llamafile to become a rock-solid foundation for building sophisticated locally-running AI applications. Justine’s work on the new Llamafiler server is a big part of that equation, but so is the ongoing work of supporting new models and optimizing inference performance for as many users as possible. We’re proud and grateful that some of the project’s biggest breakthroughs in these areas, and others, have come from the community, with contributors like @Kawrakow, @cjpais, @mofosyne, and @Djip007 routinely leaving their mark.
We invite you to join them, and us. We welcome issues and PRs in our GitHub repo. And we welcome you to become a member of Mozilla’s AI Discord server, which has a dedicated channel just for Llamafile where you can get direct access to the project team. Hope to see you there!
Stephen leads open source AI projects (including llamafile) in Mozilla's Innovation group. He previously managed social bookmarking pioneer del.icio.us; co-founded Storium, Blockboard, and FairSpin; and worked on Yahoo Search and BEA WebLogic.