2024-10-16 23:13:35 Author: hackernoon.com(查看原文) 阅读量:3 收藏
Authors:
(1) Qian Yang, Zhejiang University, Equal contribution. This work was conducted during Qian Yang’s internship at Alibaba Group;
(2) Jin Xu, Alibaba Group, Equal contribution;
(3) Wenrui Liu, Zhejiang University;
(4) Yunfei Chu, Alibaba Group;
(5) Xiaohuan Zhou, Alibaba Group;
(6) Yichong Leng, Alibaba Group;
(7) Yuanjun Lv, Alibaba Group;
(8) Zhou Zhao, Alibaba Group and Corresponding to Zhou Zhao ([email protected]);
(9) Yichong Leng, Zhejiang University
(10) Chang Zhou, Alibaba Group and Corresponding to Chang Zhou ([email protected]);
(11) Jingren Zhou, Alibaba Group.
Table of Links
4 Experiments
4.3 Human Evaluation and 4.4 Ablation Study of Positional Bias
A Detailed Results of Foundation Benchmark
4.3 Human Evaluation
To evaluate the consistency between the evaluations of GPT-4 and human judgements, we design

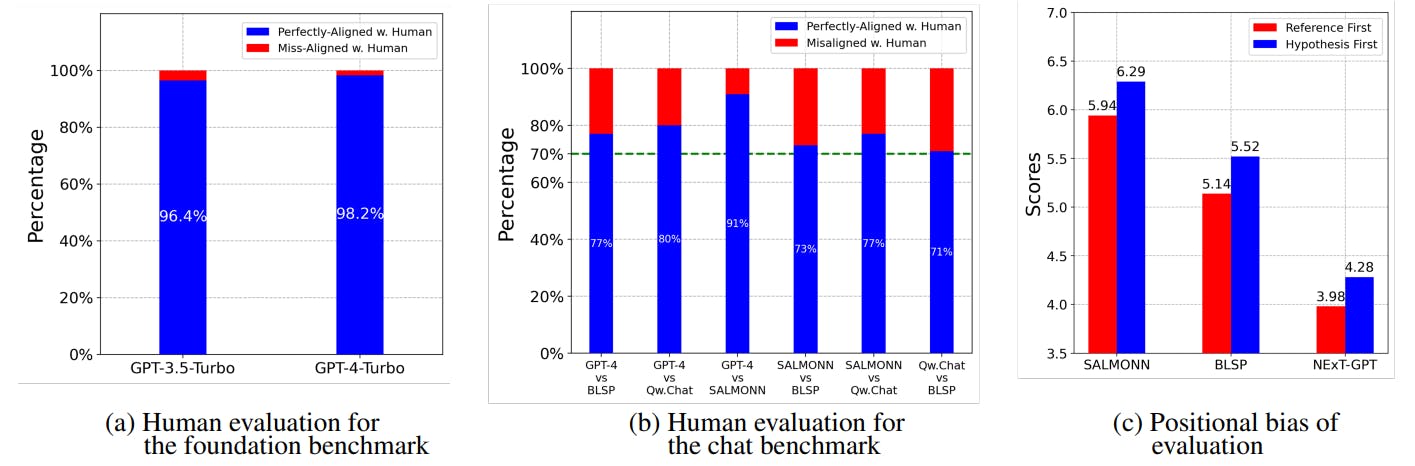
experiments for both the foundation and chat benchmarks. For the foundation benchmark, we instruct the testers to determine which option aligns closest with the hypothesis. We then compare the option selected by human testers with the option chosen by GPT-4 to assess the extent of agreement. For this consistency analysis, we employed Qwen-AudioChat as a representative model and randomly selected 400 questions from the benchmark. These questions were then evaluated by three native English speakers. Additionally, we also compared the performance of GPT-4 with GPT-3.5 Turbo. As depicted in Figure 4 (a), GPT-4 Turbo, serving as the evaluator, exhibited a high level of consistency at 98.2% with human judgements. Comparatively, GPT-3.5 Turbo had a slightly lower consistency rate of 96.4%.
Regarding the chat benchmark, obtaining a numerical score on a scale of 1 to 10 directly from testers poses challenges. Therefore, we resort to a pairwise comparison of the models instead. Testers listen to audio and compare the performance of both models based on their usefulness, relevance, accuracy and comprehensiveness to the given question, indicating their preference as either “A is better”, “B is better”, or “Both are equal”. Subsequently, we convert the GPT-4 scores into the same preference-based rating as the human testers for any two models. We then assess the consistency between the two sets of results. For the chat benchmark, we conduct pairwise comparisons among Qwen-Audio-Chat, SALMONN, BLSP, and GPT4. We randomly select 200 questions and have them evaluated by three native English speakers. As depicted in Figure 4 (b), the pairwise preference consistency scored above 70%, demonstrating a high level of agreement.
4.4 Ablation Study of Positional Bias
In our evaluation framework, we adopt a strategy of scoring twice by interchanging the positions of the hypothesis and reference and calculating the average of the two scores. This approach helps mitigate the bias that may arise from the positional placement. The outcomes of these two evaluations are presented in Figure 4 (c). We observe that the GPT4 evaluator exhibits a clear bias in scoring when the hypothesis is placed before the reference. This highlights the importance of conducting a second scoring to account for addressing this bias.
如有侵权请联系:admin#unsafe.sh