2024-10-18 00:0:22 Author: hackernoon.com(查看原文) 阅读量:1 收藏
Authors:
(1) Divyanshu Kumar, Enkrypt AI;
(2) Anurakt Kumar, Enkrypt AI;
(3) Sahil Agarwa, Enkrypt AI;
(4) Prashanth Harshangi, Enkrypt AI.
Table of Links
2 Problem Formulation and Experiments
A APPENDIX
A.1 EXPERIMENT UTILS
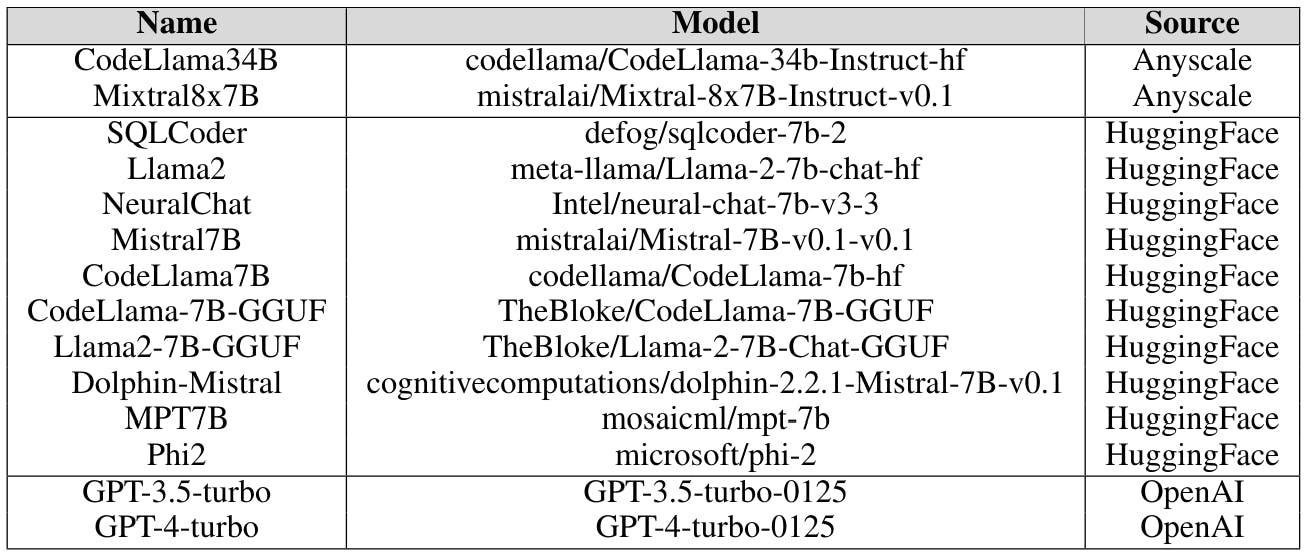
We utilize various platforms for our target model, including Anyscale’s endpoint, OpenAI’s API, and our local system, Azure’s NC12sv3, equipped with a 32GB V100 GPU, along with Hugging Face, to conduct inference tasks effectively. We import models from Hugging Face to operate on our local system.

A.2 EXPERIMENT RESULTS IN DETAILS
In our experimentation, we explore various foundational models, including the latest iterations from OpenAI’s GPT series, as well as models derived from previous fine-tuned versions. We conduct tests on these models both with and without the integration of guardrails. Additionally, we examine models that have been quantized, further expanding the scope of our investigation. This comprehensive approach allows us to assess the performance and effectiveness of guardrails across a range of model architectures and configurations. By analyzing these diverse scenarios, we aim to gain insights into the impact of guardrails on model stability and security, contributing to the advancement of responsible AI deployment practices. Figure 3 showcases the impact of Guardrails.

We monitor the number of queries needed to jailbreak the model. Figure 4 examines the sustainability of Guardrails in resisting jailbreak attempts (the data includes only instances when the models were jailbroken). It’s quite evident that having guardrails does offer additional resistance to jailbreak attempts, even if the model has been compromised.

如有侵权请联系:admin#unsafe.sh