- 原文地址:Zenbleed
- 原文作者:Tavis Ormandy
如果你从字符串 “hello, world” 中移除第一个单词会导致什么结果?这是我们发现答案可能是你的 root 密码的故事!
介绍
所有 x86-64 CPU 都有一组 128 位向量寄存器,它们被称作 XMM 寄存器。位永远不够,因此最新的 CPU 将这些寄存器的宽度扩展至 256 位甚至 512 位。
256 位扩展寄存器称为 YMM,512 位扩展寄存器称为 ZMM。
这些大寄存器在很多情况下都很有用,而不仅仅是在数学运算中!它们甚至被标准 C 库函数使用,例如 strcmp、memcpy、strlen 等。
让我们看一个例子。下面是 glibc 通过 AVX2 优化的 strlen 的前几条指令:
(gdb) x/20i __strlen_avx2
...
<__strlen_avx2+9>: vpxor xmm0,xmm0,xmm0
...
<__strlen_avx2+29>: vpcmpeqb ymm1,ymm0,YMMWORD PTR [rdi]
<__strlen_avx2+33>: vpmovmskb eax,ymm1
...
<__strlen_avx2+41>: tzcnt eax,eax
<__strlen_avx2+45>: vzeroupper
<__strlen_avx2+48>: ret
完整的例子很复杂并且会处理很多情况,但让我们逐步完成这个简单的情况。请耐心听我说,我保证这是有道理的!
第一步是将 ymm0 初始化为零,只需将 xmm0 与其自身1进行异或即可完成。

> vpxor xmm0, xmm0, xmm0
vpcmpeqb ymm1, ymm0, [rdi]
vpmovmskb eax, ymm1
tzcnt eax, eax
vzeroupper
这里 rdi 包含指向我们的字符串的指针,因此 vpcmpeqb 将检查 ymm0 中的哪些字节与我们的字符串匹配,并将结果存储在 ymm1 中。
由于我们已经将 ymm0 设置为全零字节,因此只有 nul 字节会匹配。

vpxor xmm0, xmm0, xmm0
> vpcmpeqb ymm1, ymm0, [rdi]
vpmovmskb eax, ymm1
tzcnt eax, eax
vzeroupper
现在只需计算尾部零位的个数,就能找到第一个零字节。
这是一个非常常见的操作,因此有一个指令——tzcnt(尾随零计数)。

vpxor xmm0, xmm0, xmm0
vpcmpeqb ymm1, ymm0, [rdi]
vpmovmskb eax, ymm1
> tzcnt eax, eax
vzeroupper
现在我们只用了四个机器指令就知道了第一个 nul 字节的位置!
你也许能想象到 strlen 现在在你的系统上运行的频率有多高,但这足以说明,位和字节不断地从整个系统流入这些向量寄存器。
寄存器清零
你可能已经注意到我错过了一条指令,vzeroupper 指令。

vpxor xmm0, xmm0, xmm0
vpcmpeqb ymm1, ymm0, [rdi]
vpmovmskb eax, ymm1
tzcnt eax, eax
> vzeroupper
你猜对了,vzeroupper 会将向量寄存器的高位清零。
我们这样做的原因是,如果混用 XMM 和 YMM 寄存器,XMM 寄存器会自动提升为全宽(256 位)。这有点像 C 语言中的整数符号扩展。
这样做效果很好,但超标量处理器需要跟踪依赖关系,以便知道哪些操作可以并行化。这种升级方式增加了对这些高位的依赖性,在处理器等待它并不真正需要的结果时,会造成不必要的停滞。
这些停滞正是 glibc 通过 vzeroupper 想要避免的。现在,任何未来的结果都不会取决于这些位的内容,因此我们可以安全地避免这一瓶颈!
向量寄存器堆
既然我们知道了 vzeroupper 的作用,那么它是如何做到的呢?
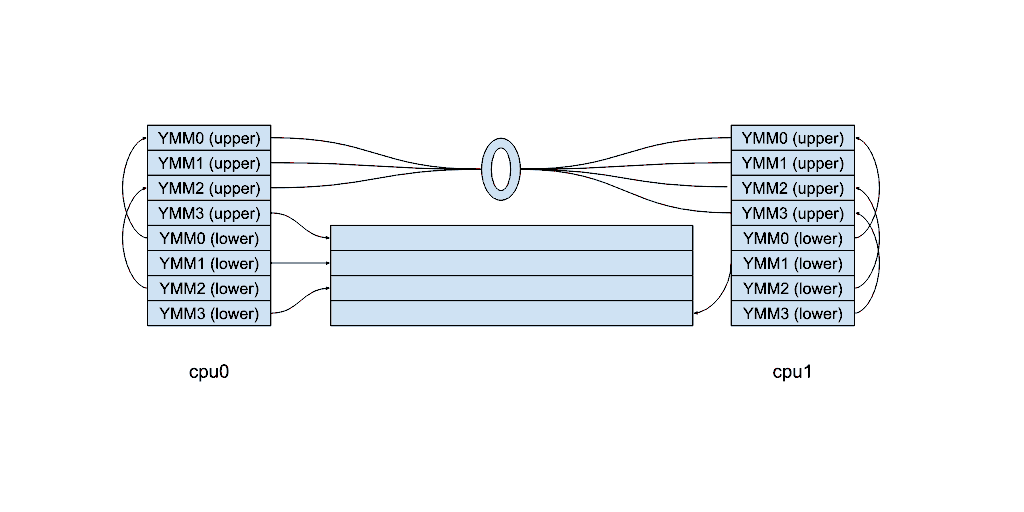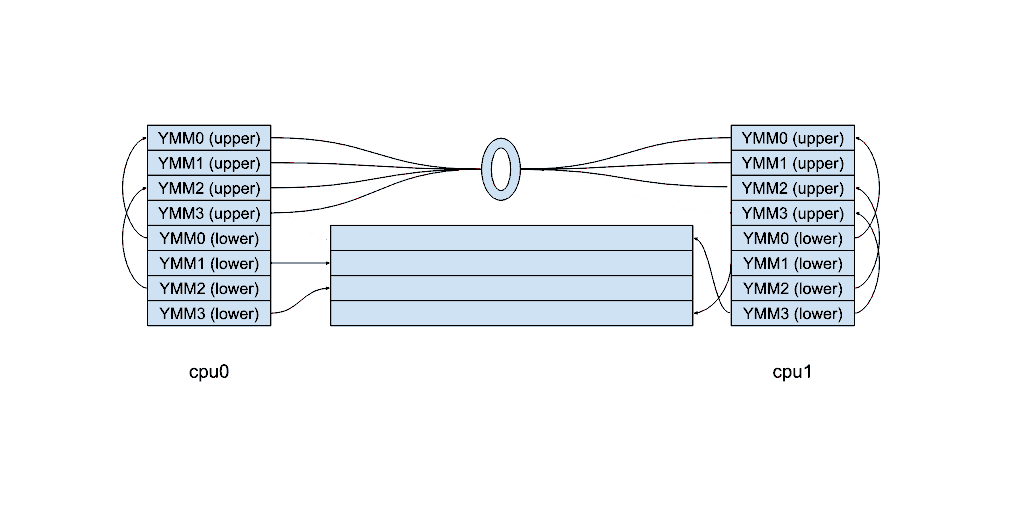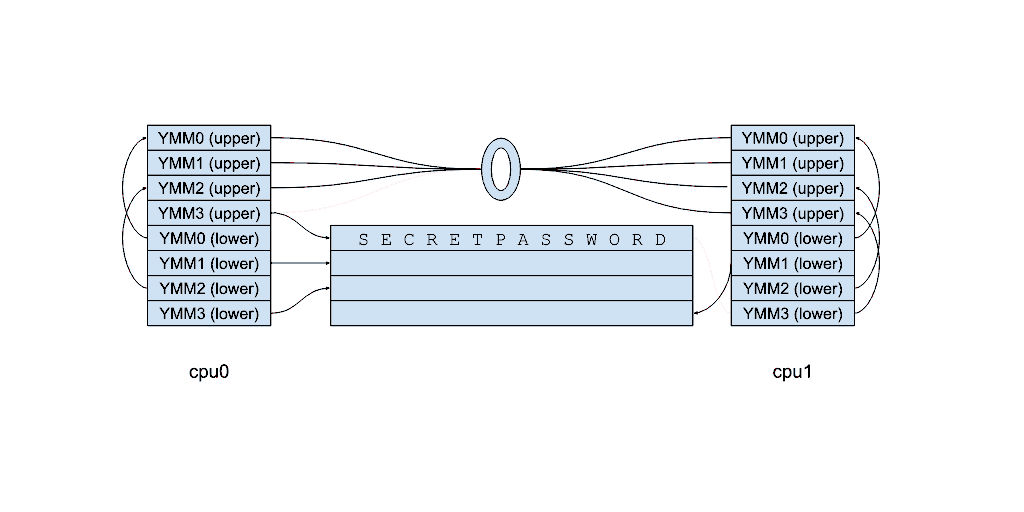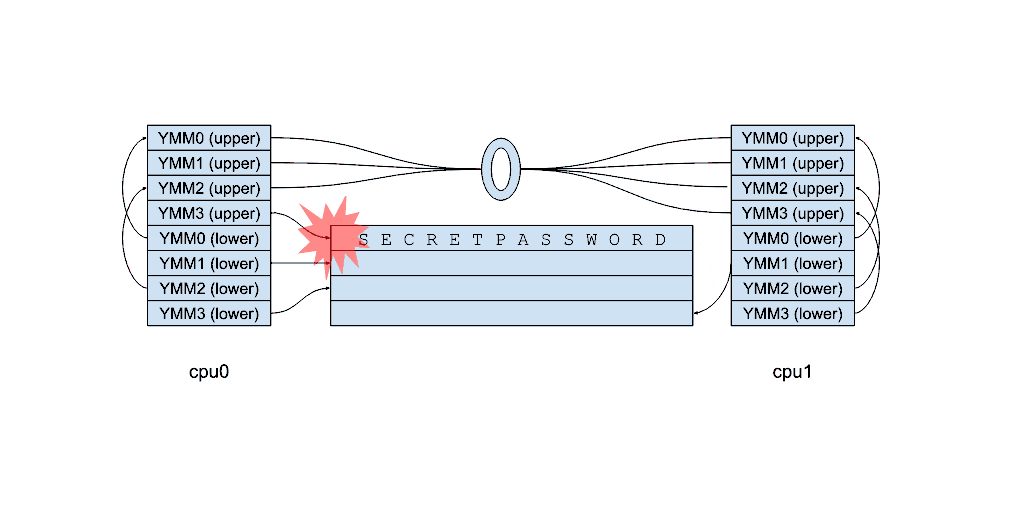
处理器中的每个寄存器并不是存放在一个物理位置,而是存放在所谓的寄存器堆和寄存器分配表(Register Allocation Table, RAT)中。如果把每个寄存器看作一个指针,这就有点像用 malloc 和 free 来管理堆。寄存器分配表会记录寄存器文件中分配给哪个寄存器的空间。
实际上,当你将 XMM 寄存器清零时,处理器根本不会将这些位存储在任何地方 - 它只是在寄存器分配表中设置一个名为 z 位的标志。该标志可以独立应用于 YMM 寄存器的上部和下部,因此 vzeroupper 可以简单地设置 z 位,然后释放寄存器堆中分配给它的任何资源。

寄存器分配表(左)和物理寄存器堆(右)。
推测执行
等等,还有一个麻烦!现代处理器使用推测执行,因此有时必须回滚操作。
如果处理器推测执行 vzeroupper,但随后发现存在分支预测错误,会发生什么情况?好吧,我们必须恢复该操作并将一切恢复原状…也许我们可以取消设置那个 z 位?
如果我们回到 malloc 和 free 的类比,就会发现事情没那么简单——这就好比在指针上调用 free() 后又改变了主意!
这将是一个释放后使用漏洞,但 CPU 中不存在释放后使用这样的东西……不是吗?
剧透:有的🙂
该动画显示了为什么重置 z 位还不够。
漏洞
事实证明,通过精确调度,可以使一些处理器从错误的 vzeroupper 预测中恢复过来!
该技术为 CVE-2023-20593,适用于所有 Zen 2 级处理器,至少包括以下产品:
- AMD Ryzen 3000 Series Processors
- AMD Ryzen PRO 3000 Series Processors
- AMD Ryzen Threadripper 3000 Series Processors
- AMD Ryzen 4000 Series Processors with Radeon Graphics
- AMD Ryzen PRO 4000 Series Processors
- AMD Ryzen 5000 Series Processors with Radeon Graphics
- AMD Ryzen 7020 Series Processors with Radeon Graphics
- AMD EPYC “Rome” Processors
这个错误的工作原理如下:首先,你需要触发 XMM 寄存器合并优化2这一功能,然后触发寄存器重命名并错误预测 vzeroupper。这一切都必须在一个精确的窗口内发生才能起作用。
我们现在知道像 strlen、memcpy 和 strcmp 这样的基本操作将使用向量寄存器——因此我们可以有效地监视系统上任何地方发生的这些操作!它们是否发生在其他虚拟机、沙箱、容器、进程等中并不重要!
之所以能做到这一点,是因为同一物理内核上的所有程序都共享寄存器堆。事实上,两个超线程甚至可以共享同一个物理寄存器堆。
不相信我?让我们写一个漏洞利用🙂
利用
触发漏洞的方法有很多,让我们来看一个非常简单的例子。
vcvtsi2s{s,d} xmm, xmm, r64
vmovdqa ymm, ymm
jcc overzero
vzeroupper
overzero:
nop
这里的 cvtsi2sd 被用来触发合并优化。cvtsi2sd 的作用并不重要,我使用它只是因为它是手册中使用该优化的指令之一3。
接下来我们需要触发寄存器重命名,让 vmovdqa 起作用。如果执行了条件分支4,但 CPU 预测的是未执行的路径,那么执行到 vzeroupper 时就会预测错误,从而出现错误!
优化
事实证明,故意预测错误很难优化!花了点功夫,我找到了一种变体,每个核心每秒可以泄漏大约 30 kb。
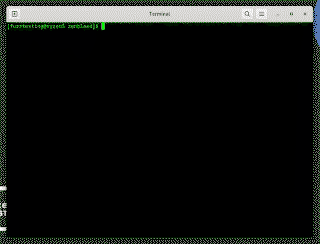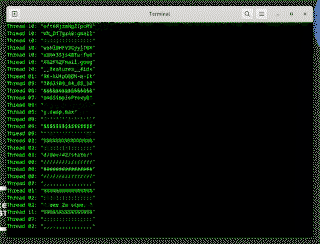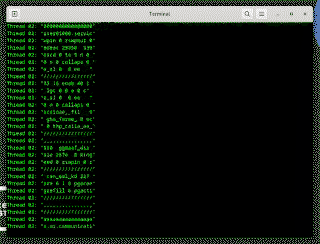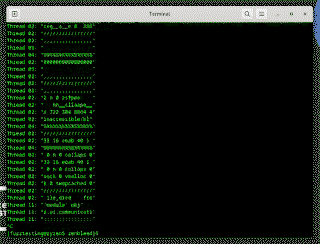
这足以在用户登录时监控加密密钥和密码!
我们今天将发布完整的技术咨询以及所有相关代码。详细信息将发布在我们的安全研究存储库中。
如果您想测试该漏洞,可以在此处获取代码。
请注意,这份代码适用于 Linux,但该漏洞并不依赖于任何特定的操作系统,所有操作系统都会受到影响!
发现
我是通过 fuzzing 发现这个漏洞的,但令人惊讶🙂的是,我并不是第一个应用 fuzzing 发现硬件缺陷的人。事实上,供应商会对自己的产品进行广泛的 fuzzing——业界称之为 “硅后验证”(Post-Silicon Validation)。
那么,为什么没有更早地发现这个错误呢?我想我做了一些不同的事情,也许是因为我没有 EE 背景,所以有了新的视角!
反馈
性能最佳的 fuzzer 以覆盖率反馈为指导。问题是,没有什么与 CPU 中的代码覆盖率真正类似的东西……不过,我们有性能计数器!
当各种有趣的架构事件发生时,它们就会通知我们。
将这些数据提供给 fuzzer 可以让我们优雅地引导它探索有趣的特征,而这些特征是我们无法独立偶然发现的!
要掌握正确的细节很有挑战性,但我利用这一点教会了我的 fuzzer 寻找有趣的指令序列。这样,我就能自动发现合并优化等功能,而无需输入任何信息!
预言
当我们对软件进行模糊测试时,我们通常会寻找崩溃。软件不应该崩溃,所以如果软件崩溃了,我们就知道一定是出了什么问题。
我们如何知道 CPU 是否在正确执行随机生成的程序?程序崩溃可能是完全正确的!
针对这一问题,人们提出了一些解决方案。其中一种方法被称为反转法(reversi)。它的总体思路是,每生成一条随机指令,就同时生成一条相反的指令(例如,ADD r1, r2 → SUB r1, r2)。执行结束时,与初始状态的任何偏差都一定是错误,整齐划一!
反转方法很聪明,但对于像 x86 这样的 CISC 架构来说,它使得生成测试用例变得非常复杂。
一个更简单的解决方案是使用预言机(Oracle)。预言机只是另一个 CPU 或模拟器,我们可以用它来检查结果。如果我们将测试 CPU 的结果与预言 CPU 的结果进行比较,任何不匹配都表明出现了问题。
我结合这两种想法开发了一种新方法,我将其称为预言序列化。
预言序列化
作为开发人员,我们监控的是宏观架构状态,也就是寄存器值之类的东西。还有一些我们几乎看不到微体系结构状态,如分支预测器、乱序执行状态和指令流水线等。
序列化通过指示 CPU 重置指令级并行,让我们可以对此进行一些控制。这包括存储/加载屏障、推测栅栏、缓存行刷新等。
序列化预言的思想是生成一个随机程序,然后自动将其转换为序列化形式。
| Ins | Oracle Ins |
|---|---|
movnti [rbp+0x0],ebx | movnti [rbp+0x0],ebx sfence rcr dh,1 lfence sub r10, rax mfence rol rbx, cl nop xor edi,[rbp-0x57] |
随机生成的指令序列,以添加了随机对齐、序列化和推测栅栏的相同序列。
这两个程序可能具有非常不同的性能特征,但它们应该产生相同的输出。序列化的形式现在可以成为我的预言!
如果最终状态不匹配,那么在微体系结构上执行这些状态时肯定出现了错误——这可能表明存在错误。
这正是我们第一次发现这个漏洞的原因,序列化预言的输出不匹配!
解决方案
我们于 2023 年 5 月 15 日向 AMD 报告了此漏洞。
AMD 已针对受影响的处理器发布了微码更新。你的 BIOS 或操作系统供应商可能已经提供了包含它的更新。
变通方案
强烈建议使用微码更新。
如果由于某种原因无法应用更新,有一个软件变通方法:可以设置 chicken bit DE_CFG[9]。
这可能会带来一些性能代价。
Linux
你可以使用 msr-tools 在所有核心上设置 chicken bit:
# wrmsr -a 0xc0011029 $(($(rdmsr -c 0xc0011029) | (1<<9)))
FreeBSD
在 FreeBSD 上,可以使用 cpucontrol(8)。
Others
如果您使用的是其他操作系统,不知道如何设置 MSR,请向供应商寻求帮助。
请注意,仅禁用 SMT 是不够的。
检测方法
我不知道有什么可靠的技术可以检测利用情况。这是因为不需要特殊的系统调用或权限。
绝对不可能静态检测 vzeroupper 的不当使用,请不要尝试!
总结
事实证明,即使在硅片中,内存管理也很困难。