2024-10-18 23:51:1 Author: hackernoon.com(查看原文) 阅读量:0 收藏
Table of Links
2 Architectural details and 2.1 Sparse Mixture of Experts
3.1 Multilingual benchmarks, 3.2 Long range performance, and 3.3 Bias Benchmarks
6 Conclusion, Acknowledgements, and References
5 Routing analysis
In this section, we perform a small analysis on the expert selection by the router. In particular, we are interested to see if during training some experts specialized to some specific domains (e.g. mathematics, biology, philosophy, etc.).
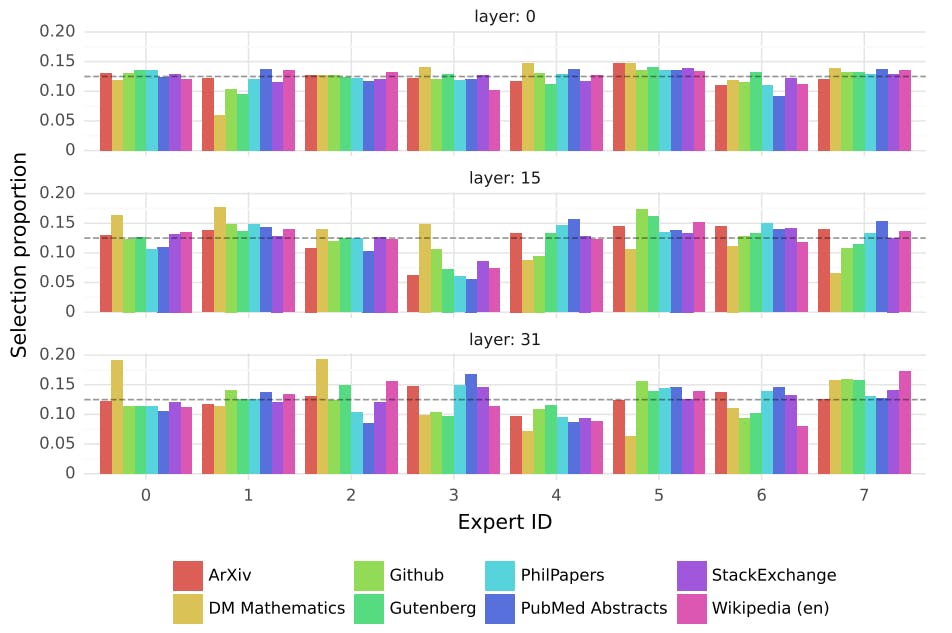
To investigate this, we measure the distribution of selected experts on different subsets of The Pile validation dataset [14]. Results are presented in Figure 7, for layers 0, 15, and 31 (layers 0 and 31 respectively being the first and the last layers of the model). Surprisingly, we do not observe obvious patterns in the assignment of experts based on the topic. For instance, at all layers, the distribution of expert assignment is very similar for ArXiv papers (written in Latex), for biology (PubMed Abstracts), and for Philosophy (PhilPapers) documents.
Only for DM Mathematics we note a marginally different distribution of experts. This divergence is likely a consequence of the dataset’s synthetic nature and its limited coverage of the natural language spectrum, and is particularly noticeable at the first and last layers, where the hidden states are very correlated to the input and output embeddings respectively.
This suggests that the router does exhibit some structured syntactic behavior. Figure 8 shows examples of text from different domains (Python code, mathematics, and English), where each token is highlighted with a background color corresponding to its selected expert. The figure shows that words such as ‘self’ in Python and ‘Question’ in English often get routed through the same expert even though they involve multiple tokens. Similarly, in code, the indentation tokens are always assigned to the same experts, particularly at the first and last layers where the hidden states are more correlated to the input and output of the model.
We also note from Figure 8 that consecutive tokens are often assigned the same experts. In fact, we observe some degree of positional locality in The Pile datasets. Table 5 shows the proportion of consecutive tokens that get the same expert assignments per domain and layer. The proportion of repeated


consecutive assignments is significantly higher than random for higher layers. This has implications in how one might optimize the model for fast training and inference. For example, cases with high locality are more likely to cause over-subscription of certain experts when doing Expert Parallelism. Conversely, this locality can be leveraged for caching, as is done in [11]. A more complete view of these same expert frequency is provided for all layers and across datasets in Figure 10 in the Appendix.
Authors:
(1) Albert Q. Jiang;
(2) Alexandre Sablayrolles;
(3) Antoine Roux;
(4) Arthur Mensch;
(5) Blanche Savary;
(6) Chris Bamford;
(7) Devendra Singh Chaplot;
(8) Diego de las Casas;
(9) Emma Bou Hanna;
(10) Florian Bressand;
(11) Gianna Lengyel;
(12) Guillaume Bour;
(13) Guillaume Lample;
(14) Lélio Renard Lavaud;
(15) Lucile Saulnier;
(16) Marie-Anne Lachaux;
(17) Pierre Stock;
(18) Sandeep Subramanian;
(19) Sophia Yang;
(20) Szymon Antoniak;
(21) Teven Le Scao;
(22) Théophile Gervet;
(23) Thibaut Lavril;
(24) Thomas Wang;
(25) Timothée Lacroix;
(26) William El Sayed.
如有侵权请联系:admin#unsafe.sh