2024-10-22 21:57:39 Author: hackernoon.com(查看原文) 阅读量:2 收藏
As a new type of architecture, the integration of data storage and computation is expected to break through the bottleneck of arithmetic power and power consumption.computing in memorycan be divided into two categories: analog and digital. In the next section, we will focus on digitalcomputing in memoryand analogcomputing in memoryand their advantages and disadvantages.
I. Digital in-deposit calculations
Digital computing in memory utilizes all-digital circuits to perform computations, which refers to the integration of digital logic into in-store computing, and is capable of integrating bit-by-bit digital product-accumulation operations directly into memory arrays. Since digitalcomputing in memoryis structurally well supported for multiply-accumulate computation, it has great potential for application in computing scenarios where neural networks are in demand, such as speech processing in smartwatches and Bluetooth headsets, neural network computing acceleration in smartphones, and model training acceleration cards.
The main advantages of digitalcomputing in memoryare replaceable weights in the memory, high bandwidth, and high robustness, but the area and power consumption overheads are relatively large, which is suitable for application scenarios with high precision and low requirements on power consumption.
![Figure. 1 Structure of computational cores in digital memory [1]](https://hackernoon.imgix.net/images/ADfj3NaPm4bQ3JyoNfgwc7OKRvc2-vl03227.png?auto=format&fit=max&w=1920)
As an example, the overall structure of digital in-store computation demonstrated in the literature [1] in ISSCC 2022 is used to explain the operation of digital in-store computation, the structure of which is shown in Fig. 1.
The arithmetic core structure consists of 64 MAC arrays as shown at the top of the figure. In each MAC array, the memory stores the weight data (12T bitcell array section on the left in Fig. 1), the multiplier calculates the result of the elemental product of the input data and the weight data, the adder tree calculates the sum of the results of the elemental product (4b×1b multiplier & 6 stages adder tree section in Fig. 1), and the shift accumulator shifts and accumulates the result obtained from the adder tree calculation (Bit shifter & accumulator section in the figure).
The operation kernel computes the result of the inner product of the 64×1 4bit input vector XIN[63:0][3:0] and the 64×64 4bit weight matrix, which results in a column of 64×1 14bit vectors NOUT[63:0][13:0]. The computational process is as follows: the weight information of the weight matrix is split into 64 64×1 4bit weight vectors stored in the memory of each layer of MAC array, and the writing process is controlled by the WA[7:0] signals, and the 4bit information of one element of the vector, D[4:0], is written each time, for a total of 64 MAC arrays, and it is necessary to write D[255:0] at one time. Input vectors are controlled by XINSEL[3:0] in order from high to low by bit, each clock cycle calculates the product of one input bit 64 XINLBs and the elements of the weight vector 256 RBLBs and sums them up, and the shifted accumulation of the results of the four cycles yields the inner product of the weight vector of the MAC array and the input vector, and composes the results of each layer of the MAC array into a vector, i.e., NOUT[63:0][13:0].
Products based on digitalcomputing in memoryare already known to have been produced. Houmo launched Hongtou™ H30 in May 2023, which is based on SRAM storage media. According to its official website, the product has extremely low access power consumption and ultra-high computational density, and its AI core IPU energy efficiency ratio is as high as 15 Tops/W under Int8 data precision conditions, which is more than 7 times that of the traditional architectural chip, and has not yet landed on the market application of the actual test performance.
II. Analog in-store calculations [2]
Unlike the aforementioned digital in-store computation, analog in-store computation is primarily based on the laws of physics (Ohm's law and Kirchhoff's law), and implements product-accumulation operations on the in-store arrays. For analog in-store computing, the computational mode of thecomputing in memorycircuits is implemented through custom analog computing circuit modules, and energy-efficientcomputing in memoryis achieved through the combination of these analog computing circuits and memory cells, typically using RRAM (Resistive Random Memory, aka Amnesia) and Flash (Flash Memory).
Analogcomputing in memoryarea, power consumption and other overheads are small, energy efficiency, but lack of accuracy, suitable for application scenarios that require low power consumption and do not require high accuracy.
The following is an example of RRAM to describe the principle of analog in-store computation.
Memristor circuits can be made into an array structure, as shown in Fig. 2 below, similar to matrices, and can be widely used in AI reasoning scenarios by utilizing their matrix operation capability. In the inference process, the inference results can be obtained by completing the multiply-add operation with the input vector and the parameter (i.e., weight) matrix of the model.
![Figure 2 Analog-type memristor with 3×3 crossed array [3]](https://hackernoon.imgix.net/images/ADfj3NaPm4bQ3JyoNfgwc7OKRvc2-60132ng.png?auto=format&fit=max&w=828)
![Figure 3 Schematic diagram of matrix multiply-add operation with crossed arrays [4]](https://hackernoon.imgix.net/images/ADfj3NaPm4bQ3JyoNfgwc7OKRvc2-kf232vh.png?auto=format&fit=max&w=1080)
Regarding the matrix multiply-add operation, as shown in Fig. 3 above, the input data of the model is set as matrix [V], the parameters of the model are set as matrix [G], and the output data after the operation is set as matrix [I]. Before operation, the model parameter matrix is stored into the memristor (i.e., [G]) in row and column positions, and the input vector (i.e., [V]) is represented by a given voltage at the input terminal, and the corresponding current vector can be obtained at the output terminal according to Ohm's law, and then the currents are summed up according to Kirchhoff's law, which yields the output result (i.e., [I]). In addition, multiple matrix multiplication and addition calculations can be accomplished with multiple arrays of memory arrays in parallel.
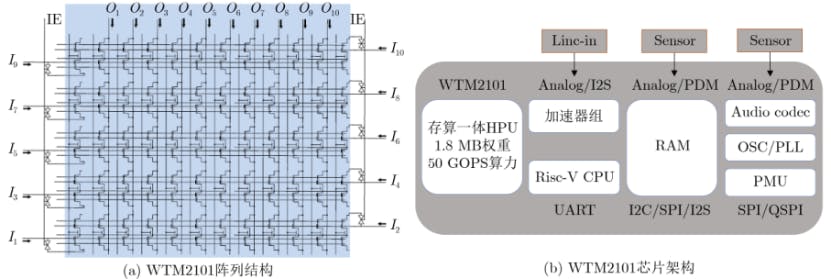
There have been many achievements in analogcomputing in memoryresearch. For example, in October 2023, Tsinghua's Qian He and Wu Huaqiang led a team to innovate and design a new generalized algorithm and architecture (STELLAR) for efficient on-chip learning of RRAM memory-computing integration, and developed the world's first fully integrated RRAM memory-computing integration chip supporting efficient on-chip learning, which has been published in Science. In addition, Flash-based analogcomputing in memoryis also a research focus. 2022, China's ZhiCun Technology took the lead in mass production of commercial WTM2101 chip, which combines the RISC-V instruction set and NOR Flashcomputing in memoryarrays, and uses a special circuit design to suppress the impact of threshold voltage drift on the computational accuracy, which can realize low-power computation and low-power control, and the structure of its array and chip architecture are shown in Figure 4, which includes 1.0 and 1.0 V. The chip architecture is shown in Figure 4. Its array structure and chip architecture are shown in Figure 4, including a 1.8 MB NOR Flashcomputing in memoryarray, a RISC-V core, a digital computing gas pedal group, 320 kB RAM, and a variety of peripheral interfaces[5] . The WTM2101 chip is suited for low-power AIoT applications, and it can complete large-scale deep learning operations using micro- to milliwatt-level power consumption, and can be applied to smart voice, smart health, and other market areas. It can be applied to intelligent voice, intelligent health and other market areas, and has already completed mass production and market application. In addition, WTM-8 series chips, a high-performance and low-power storage-calculation integrated AI processing chip for video enhancement processing, adopts the second-generation 3Dcomputing in memoryarchitecture, and is the world's first end-side large-calculation power storage-calculation integrated chip, which will soon be mass-produced, and possesses the core advantages of high-calculation power, low-power consumption, high-energy-efficiency, and low-cost, and can be applied to the real-time processing and spatial computation of 1080P-4K video. Real-time processing and spatial computation for 1080P-4K video[6] . The main product performance of WTM2101 and WTM-8 is shown in Table 1 below, and the unpublished data is denoted by "-", so please take it with a grain of salt.
Table 1 WTM2101 and WTM-8 product performance
|
WTM2101 |
WTM-8 | |
|---|---|---|
|
in-store computing model |
(computing) simulate in-store calculations |
(computing) simulate in-store calculations |
|
storage medium |
Flash |
Flash |
|
arithmetic power |
50Gops |
>24Tops |
|
automatic cleaning |
40nm |
- |
|
area (of a floor, piece of land etc) |
2.6✖3.2mm2 |
- |
|
power wastage |
5uA-3mA |
- |
|
Maximum model parameters |
1.8M |
64M |
|
calculation accuracy |
8bit |
12bit |
|
note |
High-computing power low-power localization for smart wearable devices, mainly for smart voice and smart health applications |
Positioned as a computing vision chip for mobile devices, with 4-core high-precision in-store computing, support for linux, support for AI super-scoring, frame interpolation, HDR, recognition and detection, applied to 1080P-4K video real-time processing and spatial computing |
![Figure 4 WTM2101 chip array and architecture [7]](https://hackernoon.imgix.net/images/ADfj3NaPm4bQ3JyoNfgwc7OKRvc2-g6332kt.png?auto=format&fit=max&w=1920)
III. Comparative analysis of the advantages and disadvantages of the two
Digitalcomputing in memoryand analogcomputing in memoryare both key development paths in the development process of integrated storage and computing, and they have different advantages and disadvantages and application scenarios.
Digitalcomputing in memorymainly uses SRAM as the memory device, adopts advanced logic process, has the advantage of high performance and high precision, and has good noise immunity and reliability, which can avoid inaccuracy due to process changes, data conversion overhead and poor scalability of analog circuits, and therefore is more suitable for large-scale implementation of high-precision computing chips. However, the high power consumption per unit area of digitalcomputing in memoryencounters new problems in terms of power and area, for example, a typical CMOS full adder unit requires 28 transistors, which is a large area and power overhead. In summary, digitalcomputing in memoryis more suitable for high-precision, power-insensitive large-computing computing scenarios, such as cloud-side AI scenarios.
Analog in-store calculations usually use non-volatile media such as RRAM and Flash as memory devices, which have high storage density, high parallelism, low overhead such as area and power consumption, low cost, and high energy efficiency. However, analogcomputing in memoryis very sensitive to environmental noise and temperature, and due to the effects of transistor variations and ADC (analog-to-digital converter), etc., SNR (signal-to-noise ratio) is insufficient, and analogcomputing in memorytends to lack accuracy, and it is more suitable for energy-efficient small-computing power application scenarios with low power consumption, low requirements for functional flexibility, and low requirements for accuracy, such as end-side wearable devices[8] . The advantages and disadvantages of the two in-store computation modes are compared as shown in Table 2 below.
Table 2 Comparison of twocomputing in memorymodels
|
number crunching |
(computing) simulate in-store calculations | |
|---|---|---|
|
precision |
your (honorific) |
relatively low |
|
noise immunity |
unyielding |
(following a decimal or fraction) slightly less than |
|
Versatility, flexibility |
comparatively strong |
weaker |
|
energy efficiency |
high |
your (honorific) |
|
power wastage |
high |
lower (one's head) |
|
storage medium |
Mainly SRAM |
Various non-volatile media |
|
area expenses |
larger |
Smaller area |
|
Adaptation Scenarios |
Big computing power, high precision,Cloud computing, edge computing |
Small computing power, low cost,End-side, long-time standby |
In conclusion, digitalcomputing in memoryand analogcomputing in memoryhave their own advantages and disadvantages, and are both key development paths in the development process of storage-computing integration. Digitalcomputing in memoryis more suitable for application scenarios such as large computing power, cloud computing, edge computing, etc. due to its high-speed, high-precision, strong noise immunity, mature process technology, and high energy efficiency; analogcomputing in memoryis more suitable for application scenarios of small computing power, end-side, and long-time standby, etc. due to its characteristics of non-volatility, high-density, low-cost, and low-power consumption. Analogcomputing in memoryis more suitable for application scenarios such as small computing power, end-side, and long-time standby, due to its non-volatile, high-density, low-cost, and low power consumption. In the context of wearable devices, smart furniture, toy robots and other applications into thousands of households, the analogcomputing in memoryof high energy-efficiency, small area, low-cost and other market advantages are gradually highlighted, such as the aforementioned WTM2101 has taken the lead in entering the market scale applications, in the leading position in the process of commercialization, and higher-computing-power WTM-8 series is about to be mass-produced, in the end of the side AI market has great potential for application. The WTM-8 series with higher computing power will be mass-produced soon, which has great potential for application in the end-side AI market.
Whether it is digitalcomputing in memoryor analog in-store computing, currently facing some of their own challenges, such as the complexity of the programming model, the complexity of the hardware design, the reliability of the hardware system, etc., but with the continuous efforts of the researchers, these challenges will gradually be resolved, the future ofcomputing in memorychips will be promising.
bibliography
[1] Yan B, Hsu J L, Yu P C, et al. A 1.041-Mb/MM 2 27.38-TOPS/W signed-INT8 dynamic-logic-based ADC-less SRAM compute-in-memory macro in 28nm with reconfigurable bitwise operation for AI and embedded applications[C]//2022 IEEE International Solid-State Circuits Conference (ISSCC). IEEE, 2022, 65: 188-190.
[2][4] Deposit and Computing Integration White Paper (2022), Research Institute of China Mobile Communications Ltd.
[3] A study on the working principle and development of amnesia - Know.
[5][7] Xinjie Guo, Guangyao Wang, Shaodi Wang. Research progress and application ofcomputing in memorychips[J]. Journal of Electronics and Information,2023,45(05):1888-1898.
[6] Witintech website (witintech.com).
[8] Chih Y D, Lee P H, Fujiwara H, et al. 16.4 An 89TOPS/W and 16.3 TOPS/mm 2 all-digital SRAM-based full-precision compute-in memory macro in 22nm for machine-learning edge applications[C]//2021 IEEE International Solid-State Circuits Conference (ISSCC). IEEE, 2021, 64: 252-254.
如有侵权请联系:admin#unsafe.sh