There aren’t too many professions in IT that makes professionals learn so many differe 2024-10-27 14:0:0 Author: blog.silentsignal.eu(查看原文) 阅读量:15 收藏
There aren’t too many professions in IT that makes professionals learn so many different technologies as pentesting does: one week you are neck-deep in Windows AD, the other you are trying to make sense of some custom thick client protocol in Wireshark, while you are running some webapp scans in the background. On the flipside, time is usually short, resulting in most tools never getting past proof-of-concept quality, causing much headache to practitioners.
In fact one of our recent projects caused so much confusion and cursing, that we decided to do things the right way out of spite. It should be no surprise that some basic software engineering practices can quickly clear their costs, but above certain complexity - like in this project - goals simply can’t be achieved by fast and loose hacks.
In this post we aim to document our efforts to create more robust and maintainable tools for testing WCF-based applications.
Test Environment - Theirs and Ours
To have a sense of the challenges we’re facing here’s a short summary of the project setup we were dealing with (if you are interested in the bits and bytes, feel free to skip this section):
Companies often enforce policies deigned for (external) end-user or developer use-cases on penetration testers. A typical example of this is restricting network access from tester machines to target services and providing access to the target only via ill equipped jump hosts. Our usual phrase for such setups is “repairing the Trabant through the exhaust pipe” - the approach is highly constraining to the applicable testing methods, and reduces test performance significantly.
In an “assumed breach” scenario it could make sense to test system security with constraints similar to those applied to the simulated Patient Zero. Application/product security shouldn’t rely on the limitations on some specific user environment.
Similar restrictions can cause headaches during standard projects, like web application tests, but our target was a thick client, in which case even determining the technology stack we are facing can take considerable effort. In our case application configuration quickly revealed that we’re dealing with a WCF service on the remote end, that only accepts net.tcp:// connections for which the available tooling is very limited (see the next section).
At the same time the test window was also limited that added a countdown to our Trabant-repair exercise.
But just like constraints can contribute to breakthroughs these factors also played as a major motivators to build our own test system instead of refining our tools using the target service. Having a fully controlled test system has several benefits of course:
- Server-side debug information and inspection interfaces are readily available
- Distracting configurations (such as authentication) can be disabled for testing
- Minimal implementations of interesting functionality can be created
- etc.
We used the sample code provided by Microsoft in a standard Windows environment with Visual Studio 2022.
But how much tweaking do we need? Let’s dig into WCF already!
WCF Basics and Prior Work
Windows Communication Foundation (WCF) is a framework that can provide inter-connectivity for .NET services, so a wide range of client applications and network topologies can be supported. From the perspective of technological diversity this single framework can establish connections over different network protocols and message serialization formats. While some WCF-based applications can be tested using off-the-self tools, others need significant research and development to test at scale.
Regular SOAP over HTTP is trivial to handle with any HTTP testing tool such as Burp. Things get more interesting in case of non-delimited, binary serialization formats.
The wcf-deserializer and WCFDSer-ngng Burp Suite plugins cleverly reuse the functionality shipped with the .NET framework to de(serialize) messages embedded inside HTTP messages. These extensions use external .NET executables/services to support the “.NET Binary Format: SOAP Data Structure” (MC-NBFS) serialization.
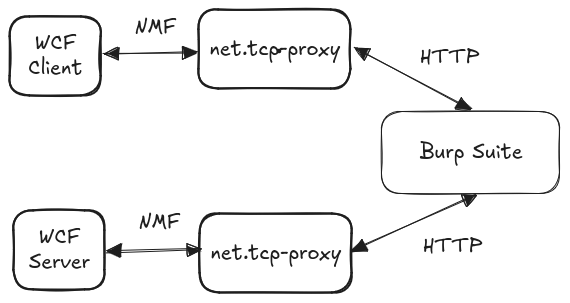
Unfortunately, not all WCF services use HTTP: the net.tcp-proxy tool is capable to proxy raw TCP streams using the MC-NMF, MC-NMFTB and MS-NNS protocols (net.tcp:// schema), supporting authentication over Kerberos. This tool relies on the pure Python python-wcfbin package to implement another payload serialization called “.NET Binary Format: XML Data Structure” (MC-NBFX). Note, that net.tcp-proxy is unmaintained, so we started to maintain our fork some time ago to provide bug fixes and Python 3 compatibility, while a fork of python-wcfbin is now distributed on PyPI by a company that seemingly has very little to do with security (we haven’t looked into the changes they introduced)…
Maintenance and supply-chain risks aside, net.tcp communication is also problematic because of multiple technical reasons:
- TCP itself doesn’t provide a way to split the stream into messages that can be later processed by message-based tools like Burp.
- Payload serialization formats tend to be “non-delimited”. This means that if we manipulate a piece of data, we’ll likely need to adjust other parts of the Payload too (e.g. the Length field of a TLV structure). To do this reliably, we need robust implementations for data serialization and deserialization that is not available in off-the-shelf tools.
Design
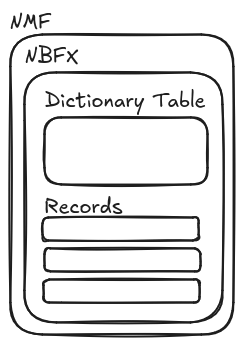
Fortunately net.tcp:// uses .NET Message Framing (NMF) that is fundamentally a message-oriented protocol, and ERNW’s net.tcp-proxy even provides a stable implementation for it. Our first problem seems to be easy to solve. Original versions of python-wcfbin also seemed to handle NBFX correctly (note our careful wording!), so our initial plan was rather simple:
- Split the net.tcp stream to messages
- Embed the messages in HTTP so they can be handled by Burp Suite
- Provide the capability to edit messages in Burp so scans and ad-hoc manual tests can be efficiently executed
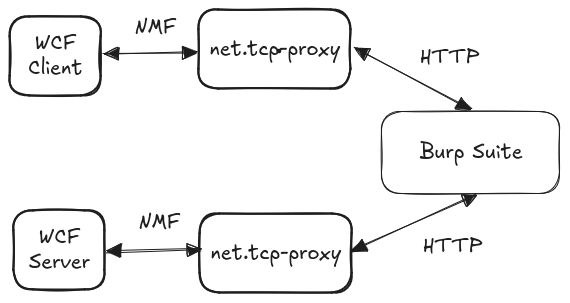
To do this, we need two “translator” proxies:
- One standing between the WCF client and Burp, transforming the TCP stream to HTTP messages and serializing data to some text-based, delimited format that can be easily manipulated by simple string replacement
- One standing between Burp and the WCF server, stripping of the HTTP wrapping and deserializing the delimited format to NBFX
This looked simple enough at first: implement a HTTP client and a HTTP server in net.tcp-proxy, use the python-wcfbin package to (de)serialize data between NBFX binary protocol and Python object. For delimited serialization we could use jsonpickle, that can serialize arbitrary Python objects to JSON that can be easily handled by Burp.
There were only a few teeny-tiny problems with this approach: the most significant one was that while the serializer function (parse()) of python-wcfbin worked flawlessly, the deserializer (dump_records(), obviously) produced a radically different format from the original input. This may be (in part) the result of the 2to3 conversion that we had to perform on the original Python 2 code to ensure future compatibility. While fixing Python compatibility issues is doable, the last (or first?) nail in the coffin of python-wcfbin was the fact that it is a “handcrafted” parser where a seemingly trivial change at one place can cause cascading failures across the whole program - there was no way we could tackle this problem in such code on time.
We needed a proper parser generator. And even with that, we needed a way to make sure that our new serializer works at least as good as the original implementation.
Robust Protocol Parsing
Kaitai Struct has proved itself incredibly useful in several of our previous projects (e.g.: XCOFF, AS/400 PGMs) so it was an obvious choice for this one. Structure definitions to support every feature of the sample application we used in our test environment was written during an afternoon. The vast majority of structures follow a basic TLV pattern for which the official documentation includes plenty of guidance.
The most challenging part was the implementation of MultiByteInt31, that is a variable-length integer encoding that stores 7-bits of numeric data in every byte. This type is used extensively in NBFX, and while implementing a coder would be a typical programming exercise in any imperative language, expressing the algorithm declaratively for Kaitai isn’t obvious. Fortunately, The Kaitai Format Gallery includes the vlq_base128_be format, that provides the secret sauce:
seq:
- id: groups
type: group
repeat: until
repeat-until: not _.has_next
types:
group:
seq:
- id: has_next
type: b1
doc: If true, then we have more bytes to read
- id: value
type: b7
doc: The 7-bit (base128) numeric value chunk of this group
instances:
last:
value: groups.size - 1
value:
value: |
(groups[last].value
+ (last >= 1 ? (groups[last - 1].value << 7) : 0)
# ...
+ (last >= 7 ? (groups[last - 7].value << 49) : 0)).as<u8>
doc: Resulting value as normal integer
The solution consists of multiple clever tricks:
- It relies on Bit-Sized Integer Support to encode the semantics of the bytes representing the value.
- Semantic representation allows the declaration of a variable-length sequence depending on the
has_nextproperties of the already consumed bytes. - A Value Instance, arithmetic and branching Expressions are used to calculate the actual value based on the consumed bytes.
Nonetheless, adjusting this sample to the NBFX specification took numerous tries, and since MultiByteInt31 values are typically used in Length fields, miscalculations easily break parsing and thus the (otherwise phenomenal) Web IDE. This stage of development was thus heavily supported by our test suite.
Test Suite
The value of automated tests can’t be overstated. In case of this project, multiple factors made such sanity checks essential for success:
First, both the project input and output data, and the project code is hard to inspect. Data is not only “binary” (non-textual), bit-level packing is also employed. Most of the running code is generated, with abstract naming, and deep, sometimes recursive control flows.
Second, while a test environment is available, testing there takes significant amount of time: code needs to be transferred and installed, services need to be restarted or killed (sockets can be stuck in weird ways). Since integration tests are not automated (yet), there is also a high chance of human error, executing different versions of code at different elements of the proxy chain.
We use the standard pytest package for unit testing. Creating the initial test setup (overall design, implementing fixtures) took about an hour including reading documentation. The ability to catch errors on the development system and debug minimal samples easily saved us a day so far.
Because there were some nasty errors to catch…
Serialization (and Suffering)
Before we move on it’s worth to summarize where we were and where we wanted to go at this point:
- We could parse NMF messages and their NBFX payloads with net.tcp-proxy and our new, shiny Kaitai-based parser
- We made changes to net.tcp-proxy’s
proxy.pyso it could act as NMF->HTTP and HTTP->NMF proxies- We used jsonpickle to serialize NMF messages over HTTP
- At the HTTP->NMF side we could deserialize NMF with jsonpickle and reserialize it to the binary NMF stream that was acceptable by the WCF service.
- What was missing is reserialization of the NBFX payload traveling inside NMF messages, so any changes in the payload would actually occur at server-side. This would be the job our our Kaitai parser.
In the rush of the project one thing slipped our attention though: the current stable release of Kaitai Struct (0.10) doesn’t support serialization - something that we definitely need for this project. Whoops! An escape route could’ve been to use the Construct output format of Kaitai and generate a parser generator with a parser generator (the spirit of Xzibit is with us!), but fortunately the bleeding edge code finally has serialization support, so we went with that.
It should be easy from this point, right? Well, astute readers may have noticed when we first mentioned jsonpickle that while JSON is a delimited format, if the represented object (originally deserialized from an NBFX stream) keeps track of data sizes, we still have to keep this metadata and the corresponding values in sync to produce a valid output stream somehow. A related issue affects Kaitai Struct’s serializer implementation at an even deeper level.
Kaitai works on byte streams, typically referenced by the _io member of structure objects, and the sizes of these streams are fixed. In practice this means that if the size of the payload data (e.g. the length of a string) changes, all referring size values and containing streams must be reinitialized with the right size, otherwise we get nasty exceptions from the depths of generated code, e.g.:
kaitaistruct.ConsistencyError: Check failed: entry, expected: 0, actual: 128
As you can see, Kaitai is pedantic, and expects exactly the right amount of bytes for serialization, so we can’t get away with just allocating “large enough” buffers. Fortunately, pytest immediately caught missing size adjustments and with the --pdb option it dropped us right in the middle of the failing function. This allowed us to walk up the stack and find the substructures that needed adjustment.
Figuring this out took a lot of hair pulling, I hope the above exception message will attract other lost souls to this solution…
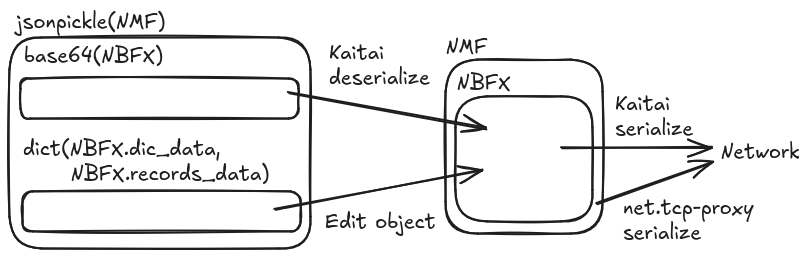
At the HTTP side we partially gave up on pickle-ing the full object because exposing the whole NBFX structure for modification by users (pentesters) could easily lead to invalid object states. Instead, we kept jsonpickle only for serializing NMF, and came up with a custom dictionary structure for NBFX, that only includes data that we can safely reserialize (this is similar to what we did with Oracle Forms).
Welcome, to the Real World (and Legacy Code)
At this point we were at the last day of the testing window. We rushed out the remaining definitions to our new NBFX parser (a nice thing about the declarative definition is that you can write new things with confidence) and moved our tools into the target environment (pip didn’t work as expected there of course, but that’s another story). And our tool…didn’t work :(
There were two obvious differences between our test environment and the target:
- The target used Kerberos authentication, our sample service was unauthenticated
- Our sample client was an application with a single
Main()function, while the target had a GUI, that most likely runs with multiple threads.
Despite the complexity of the protocol itself, tackling Kerberos was relatively simple: the implementation of net.tcp-proxy could already handle this authentication mode, and the implementation only required to wrap the TCP stream to the service in the GSSAPIStream class that handled stream authentication perfectly. We had some bugs in our untested code that we quickly fixed and could already see the NMF messages coming in.
Unfortunately the second issue remained: as a quick-and-dirty solution we initially just used some global variables to handle all HTTP messages received by the HTTP->NMF proxy, and kept open a single TCP stream to the service. This PoC-level implementation now exploded, as it was impossible to determine:
- Which incoming HTTP message belongs to which client
- Which NMF response should be forwarded back to which client
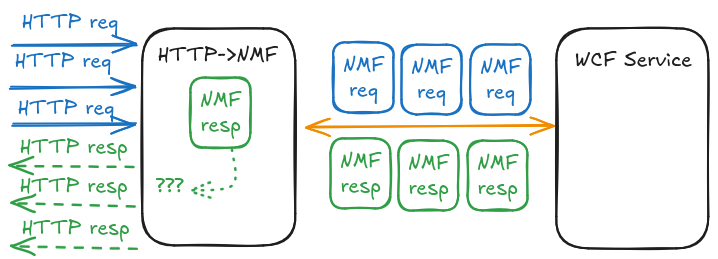
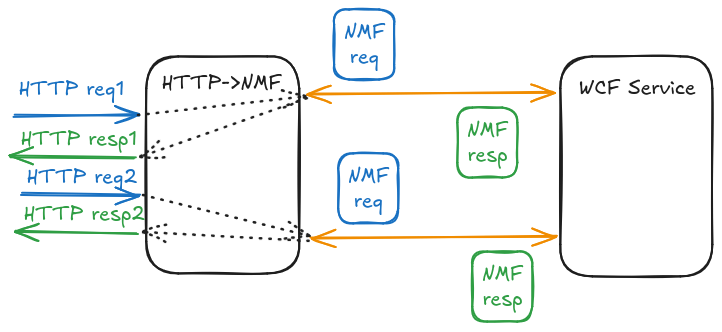
We needed to implement proper connection pooling so stateless HTTP messages can find or create their dedicated NMF streams based on the client address attached as metadata to the serialized NMF messages by the NMF->HTTP proxy. Now the code can safely handle several parallel clients.
That being said, the proxy.py component of the new net.tcp-proxy implementation still suffers from its age:
- Multiple features of different designs are packed into a single Python script
- Variable names are confusing (this resulted in numerous bugs during development), but refactoring is not easy without integration tests
- Much leftover and debug code is present (sadly we contributed to this a lot)
- etc.
As of the writing of this blog post, our most promising plan is to add detailed comments to this existing legacy script to support future refactoring efforts.
Sharing is Caring
Unfortunately, at this point our testing window has expired. But our code is available on GitHub and efficient testing with intercepting HTTP proxies should now be possible, and - more importantly - bugfixes and other contributions should be much easier to make in the refreshed code base:
- https://github.com/silentsignal/net.tcp-proxy
- https://github.com/silentsignal/nbfx
- https://github.com/silentsignal/nbfx-kaitai
The following video shows the basics of testing a WCF application using Burp Suite:
As you can see, script kiddie mode is not available yet. While using this tool you have to:
- keep in mind the stream-like nature of the underlying protocol and setup your tests accordingly,
- handpick payload positions, since you don’t want to corrupt metadata used during protocol translation,
- properly encode payloads for JSON, since breaking jsonpickle in the proxy won’t tell you much about the security of your real target.
Nonetheless we believe this release is a major step forward to uncover vulnerabilities in WCF services, and we are looking forward to hear about your experiences in this area!
Header image: The Soldier of Marathon announcing the Victory by Jean-Pierre Cortot, Wikipedia
{kind=link}
Diagrams made with Excalidraw
如有侵权请联系:admin#unsafe.sh