2024-10-29 22:20:1 Author: hackernoon.com(查看原文) 阅读量:3 收藏
Artificial intelligence is taking a significant leap forward in its ability to learn and improve through natural conversations. A groundbreaking study from Cornell University researchers demonstrates how large language models (LLMs) can enhance their performance on complex tasks simply by analyzing the implicit feedback contained in their interactions with humans. This novel approach, dubbed RESPECT (Retrospective Learning from Interactions), shows promise for creating AI systems that can continually learn and adapt without the need for extensive external annotations or feedback.
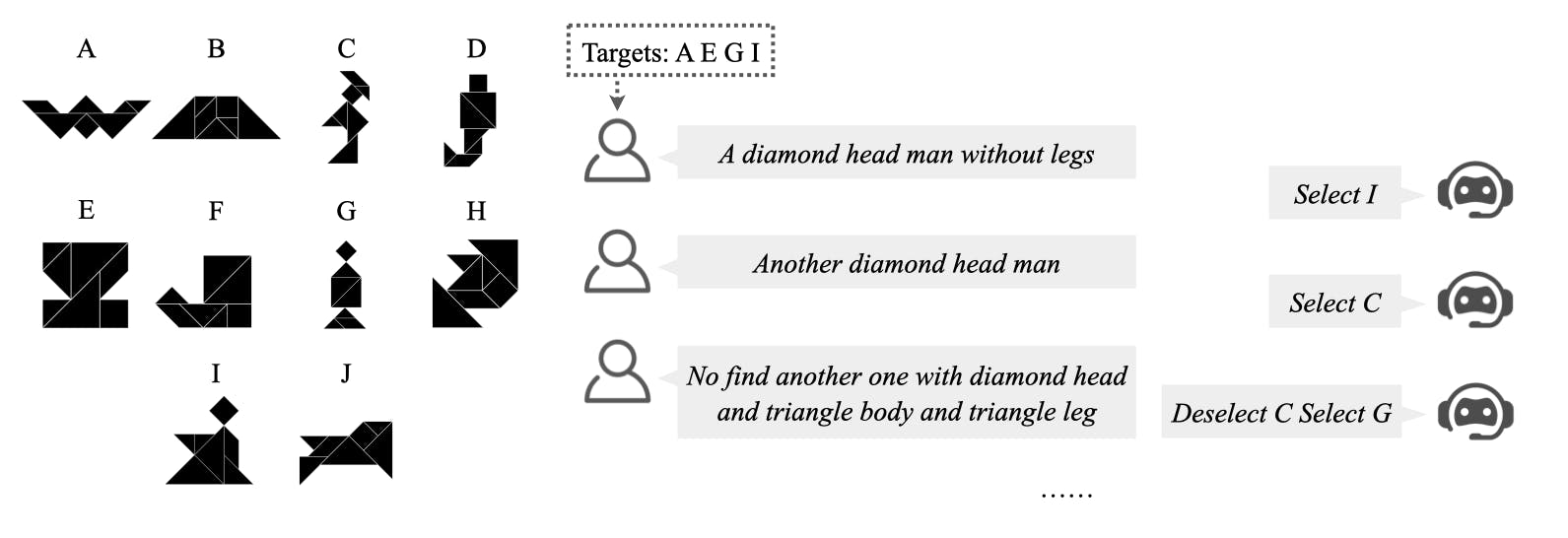
The research team, led by Zizhao Chen and Yoav Artzi, deployed their RESPECT method in a new multimodal interaction scenario called MULTIREF. In this setup, humans instruct an AI to solve abstract reasoning tasks with a vast number of possible solutions. Through thousands of interactions with human users, the AI system was able to dramatically improve its task completion rate from an initial 31% to an impressive 82% - all without any explicit feedback or additional training data.
At the heart of RESPECT is the insight that human-AI conversations naturally contain subtle cues about the AI's performance. When an AI responds inappropriately, users often rephrase their request, express frustration, or change direction. Conversely, approval or smooth progression to the next task can signal success. These implicit feedback signals occupy a relatively constrained subspace of language, making it possible for AI systems to identify and learn from them even when struggling with the primary task.
"The key insight underlying RESPECT is that conversational implicit feedback signals occupy a relatively constrained subspace of natural language," explains lead author Zizhao Chen. "Such signals can include direct approvals or signs of frustration, and also more subtle cues, such as when the user rephrases their request."
The RESPECT process works in rounds, alternating between interaction and training:
- Deployment: The AI model interacts with human users to complete tasks.
- Retrospection: After each interaction, the model analyzes its own responses and the subsequent user reactions to decode implicit feedback.
- Learning: The model is retrained using the aggregated data and decoded feedback.
- Improvement: The process repeats, with the model becoming more capable in each round.
This cycle allows the AI to bootstrap its own learning, gradually improving its performance without the need for resource-intensive manual annotation or explicit feedback collection.
The researchers conducted their experiments using IDEFICS2-8B, an 8-billion parameter language model, as their base AI system. They explored multiple learning methods, including supervised learning, reinforcement learning techniques, and a novel approach called KTO (Kahneman-Tversky Optimization).
The MULTIREF scenario used in the study is particularly noteworthy for its complexity. Unlike simple reference games where an AI might need to identify a single image, MULTIREF requires the selection of multiple abstract shapes (called tangrams) from a set. This creates an exponentially large solution space, making the task challenging even for advanced AI systems.

"MULTIREF is not designed to increase complexity in arbitrary ways, but to provide an environment for humans to naturally expose core aspects of human communication," says co-author Yoav Artzi. "At the same time, the scenario is both controlled and scoped, allowing for easy measurement of task completion and progress, as well as making learning feasible with relatively limited data."
The abstract nature of the tangram shapes used in MULTIREF also encourages rich and diverse language use by human participants. Descriptions of these shapes can be ambiguous and open to interpretation, requiring complex pragmatic reasoning from the AI. This setup closely mimics real-world scenarios where humans and AI must collaborate to solve problems through natural language communication.
One of the most striking aspects of the RESPECT method is its ability to improve AI performance without relying on stronger models for critique or using interactions created by other AI systems. The same model that struggles with a task can effectively analyze its own performance by focusing on the constrained space of implicit feedback signals.
The implications of this research are far-reaching. As AI systems become more integrated into our daily lives, the ability to learn and improve through natural interactions could lead to more adaptive and capable assistants. This approach could be particularly valuable in scenarios where collecting explicit feedback is impractical or where the AI needs to quickly adapt to new users or tasks.
However, the researchers caution that their work is still in its early stages. While the results are promising, further study is needed to understand how well this approach generalizes to different types of tasks and interaction scenarios. Additionally, ethical considerations around AI systems that continually learn from user interactions will need to be carefully addressed.
As the field of AI continues to evolve, approaches like RESPECT offer a glimpse into a future where our digital assistants become increasingly adept at understanding and meeting our needs. By harnessing the wealth of information contained in everyday conversations, we may be on the cusp of creating truly adaptive AI systems that grow and improve alongside their human users.
The code, data, and models used in this study are available at https://lil-lab.github.io/respect, allowing other researchers to build upon and extend this work. As we move forward, it's clear that the ability of AI to learn from natural interactions will play a crucial role in shaping the next generation of intelligent systems.
如有侵权请联系:admin#unsafe.sh