
Disclaimer 1: This blog post is on a new and still under development toolset in John the Ripper. Results depict the state of the toolset as-is and may not reflect changes made as the toolset evolves.
Disclaimer 2: I really need to run some actual tests and password cracking sessions using this attack, but I’m splitting that analysis up into a separate blog post. Basically I have enough forgotten drafts sitting in my blogger account that I didn’t want to add another one by trying to “finish” this post before hitting publish. So stay tuned for new posts if you want to see how effective this attack really is.


Introduction:
It’s been about 15 years since I last wrote about John the Ripper’s Markov based Incremental mode attacks [Link] [Link 2]. 15 years is a long time! A lot of work has been done applying Markov based attacks to password cracking sessions, ranging from the OMEN approach to Neural Network based password crackers. That’s why I was so excited to see a new proof of concept (PoC) enhancement of JtR’s Incremental mode that was just published by JtR’s original creator SolarDesigner.
The name of this enhancement is likely going to change over time. Originally it was described in an e-mail thread as “Markov phrases”. That’s not a bad descriptor, but doesn’t really get to the heart of the current PoC. Therefore in this blog post I’m going to call this attack after the new script SolarDesigner released (tokenize.pl) and just refer to it as a “Tokenizer Attack”. I think this gets closer to conveying how the underlying enhancement differs from the original Incremental attack which the tokenizer attack is built on.
The next question of course is “What does this new enhancement do?” To take a step back, what make Markov attacks “Markovian” is they represent the conditional probability of tokens appearing together. For example, if you see the letter ‘q‘ in an English word, the next letter is very likely to be a ‘u‘. How far you look ahead to apply this probability is measured by the “order” of the Markov chain. So the above example would describe a first-order Markov process. If we extended this and said that given a ‘q‘ and then a ‘u‘, the next most likely character would be a ‘e‘, now we are talking about a second-order Markov process. Where this starts to play out compared to a first-order process is that ‘qu’ -> ‘e’ with a high probability but the highest probability next character for the substring ‘tu‘ might be ‘r’. Therefore the highest probable letter following a ‘u‘ might change based on the letter before the ‘u‘ Basically the order represents the “memory” of the Markov chain. It can remember X previous tokens of the string it is generating.
The reason I bring this up is that JtR’s Incremental mode works with trigraphs which “roughly” can be represented by second-order Markov processes. I use “roughly” since like most Markov implementations, Incremental mode contains nuances and differences from the abstract/academic definition of Markov based processes. Those nuances aren’t super important for this current investigation/blog-post so I’m going to gloss over them for now.
One interesting area of research is implementing “variable order” Markov processes. Aka some particularly likely substrings might be created by a third/fourth/fifth/sixth order Markov process, but other less likely transitions might be implemented in a lower order (first/second) Markov process. As an example of that, if you were using a second order Markov chain the initial letters ‘or‘ might generate a next letter of ‘k‘ with a high probability, but if you take a larger step back and see the earlier letters are ‘passwor‘ then the next letter will almost certainly be a ‘d‘ instead. Based on this, it’s tempting to “apply the largest memory possible” to your Markov processes. The limiting factor though is if you extend things out too much you run into overtraining issues, not being able to generate substrings not seen in the training data, and general implementation issues (the size of your Markov grammar explodes). So being able to dynamically switch how much memory/state you are keeping track of can be very helpful when generating password guesses. While more research is needed, this is my current theory why the CMU Neural Network Markov based attacks [Link] outperform other Markov implementations. I strongly suspect the Neural Network makes use of a variable order Markov process when generating guesses.
That’s a lot of words/background to say that JtR’s Tokenizer attack can be thought of as a way to incorporate variable length Markov orders into JtR’s current Incremental mode attack. It does this by identifying certain likely substrings (aka “tokens”) and then replacing them in the training set with a “placeholder” character. So for example the likely substring “love” might be replaced with the hex value of x15. This would normally be an unprintable character in ASCII (NAK), but it allows JtR’s normal Incremental mode charset to be trained using these replacements. The resulting Incremental charset will have probability information for generating the character “x15” (NAK) as part of a password guess. Now (NAK) isn’t actually part of a real password (unless the user did something really cool). This means when running a password cracking session, you’ll need to then apply an External mode to translate these guesses back into the full ASCII text outputs. For example the guess “I(x15)MyWife” would be translated by the External mode into “IloveMyWife” which can then be fed into a real password cracking session.
While I can certainly dive more into the details of the tokenizer attack, this intro is already too long. So lets instead look at how to run it!
References:
- Post by SolarDesigner announcing the release of the tokenize.pl script: [Link]
- John the Ripper Bleeding Edge: [Link]
Configuring The Attack:
1) Update JtR Bleeding Edge:
- The new code, (including tokenize.pl) is available in the newest version of JtR Bleeding Jumbo.
- To make use of it, clone the gihub repository and make sure you are on the “bleeding-jumbo” branch which is the default. [Link]
- (Optional) Rebuild JtR from source.
- This is optional since the new code “should” work with older versions of JtR. But you might want to rebuild JtR to be on the safe side.
2) Create a Custom Incremental .CHR File:
- Run the new tokenize.pl script on your training passwords.
- Notes:
- Save the full output of this tool, as you’ll need to run the Sed command to parse/tokenize your trianing set, and you’ll need to paste the External “Untokenize” script to your john.conf file. Both of these steps will be described later
- Example:
- ./tokenize.pl TRAINING_PASSWORDS.txt
Example output when training on one million passwords from RockYou. You may note that the results are slightly different than when SolarDesigner trained on the full RockYou list:

- Re-run the sed script on the training set to generate a custom training file.
- Example:
- cat TRAINING_PASSWORDS.txt | sed {{REALLY LONG SED COMMAND}} > new_training.txt
- Closer to Real Example:
- cat TRAINING_PASSWORDS.txt | sed ‘s/1234/\x10/; s/love/\x15/; s/2345/\x1b/; s/3456/\x93/; s/ilov/\xe5/; s/123/\x6/; s/234/\x89/; s/ove/\x8c/; s/lov/\x90/; s/345/\x96/; s/456/\xa4/; s/and/\xb2/; s/mar/\xc1/; s/ell/\xd9/; s/199/\xdf/; s/ang/\xe0/; s/200/\xe7/; s/ter/\xe9/; s/198/\xee/; s/man/\xf4/; s/ari/\xfb/; s/an/\x1/; s/er/\x2/; s/12/\x3/; s/ar/\x4/; s/in/\x5/; s/23/\x7/; s/ma/\x8/; s/on/\x9/; s/el/\xb/; s/lo/\xc/; s/ri/\xe/; s/le/\xf/; s/al/\x11/; s/la/\x12/; s/li/\x13/; s/en/\x14/; s/ra/\x16/; s/es/\x17/; s/re/\x18/; s/19/\x19/; s/il/\x1a/; s/na/\x1c/; s/ha/\x1d/; s/am/\x1e/; s/ie/\x1f/; s/11/\x7f/; s/ch/\x80/; s/10/\x81/; s/00/\x82/; s/te/\x83/; s/ve/\x84/; s/as/\x85/; s/ne/\x86/; s/ll/\x87/; s/or/\x88/; s/ta/\x8a/; s/st/\x8b/; s/is/\x8d/; s/01/\x8e/; s/ro/\x8f/; s/20/\x91/; s/ni/\x92/; s/at/\x94/; s/34/\x95/; s/45/\x97/; s/it/\x98/; s/08/\x99/; s/mi/\x9a/; s/ca/\x9b/; s/ic/\x9c/; s/da/\x9d/; s/he/\x9e/; s/21/\x9f/; s/nd/\xa0/; s/me/\xa1/; s/ng/\xa2/; s/mo/\xa3/; s/ba/\xa5/; s/sa/\xa6/; s/ti/\xa7/; s/56/\xa8/; s/sh/\xa9/; s/ea/\xaa/; s/ia/\xab/; s/ol/\xac/; s/se/\xad/; s/ov/\xae/; s/be/\xaf/; s/de/\xb0/; s/co/\xb1/; s/ss/\xb3/; s/99/\xb4/; s/to/\xb5/; s/22/\xb6/; s/oo/\xb7/; s/02/\xb8/; s/ke/\xb9/; s/ee/\xba/; s/ho/\xbb/; s/ey/\xbc/; s/ck/\xbd/; s/ab/\xbe/; s/et/\xbf/; s/ad/\xc0/; s/13/\xc2/; s/07/\xc3/; s/pa/\xc4/; s/09/\xc5/; s/06/\xc6/; s/ki/\xc7/; s/98/\xc8/; s/hi/\xc9/; s/th/\xca/; s/05/\xcb/; s/14/\xcc/; s/25/\xcd/; s/ay/\xce/; s/ce/\xcf/; s/89/\xd0/; s/ac/\xd1/; s/os/\xd2/; s/ge/\xd3/; s/03/\xd4/; s/ka/\xd5/; s/ja/\xd6/; s/bo/\xd7/; s/do/\xd8/; s/04/\xda/; s/e1/\xdb/; s/nn/\xdc/; s/em/\xdd/; s/31/\xde/; s/15/\xe1/; s/18/\xe2/; s/ir/\xe3/; s/91/\xe4/; s/om/\xe6/; s/90/\xe8/; s/30/\xea/; s/nt/\xeb/; s/di/\xec/; s/si/\xed/; s/ou/\xef/; s/un/\xf0/; s/24/\xf1/; s/us/\xf2/; s/88/\xf3/; s/ai/\xf5/; s/78/\xf6/; s/y1/\xf7/; s/so/\xf8/; s/pe/\xf9/; s/ot/\xfa/; s/ga/\xfc/; s/ly/\xfd/; s/16/\xfe/; s/ed/\xff/’ > new_training.txt
- Convert the new_training.txt file to a John the Ripper potfile format
- Reason: Currently JtR’s Incremental mode character sets can only be trained from cracked passwords in a potfile. You can’t just give it a set of raw plaintext passwords.
- Enhancement: You can totally combine this step with the previous one by piping the output of the original Sed command into this second one. I’m keeping these steps separate for now since my recommendation is going to be to update the tokenizer.pl script to incorporate this step into the Sed command it generates. Basically I’m hopeful I can just delete this step in the future
- Example:
- cat new_training.txt | sed ‘s/^/:/’ > training.pot
- Run the JtR Incremental mode training program on the new training file.
- Flags:
- –make-charset= : the filename here is the name of the Incremental character file you want to create. Warning: It will overwrite existing files!
- –pot- : In this example, this is the potfile to read in training passwords from. In “normal’ usage this is the file where your cracked passwords will be stored.
- Example:
- john –make-charset=tokenize.chr –pot=training.pot
Example output of running the training session on one million training passwords:

3) Update John the Ripper’s Config File
- Add the following to John the Ripper’s “john.conf” config file
- New Values:
- [Incremental:Tokenize]
- File = $JOHN/tokenize.chr
- Notes:
- If you save your Incremental character file as “custom.chr” you can use the default custom Incremental mode that is already including in John.conf instead
- Feel free to update the name of this attack (in this example it’s “Tokenize”) to whatever identifier you want to use.
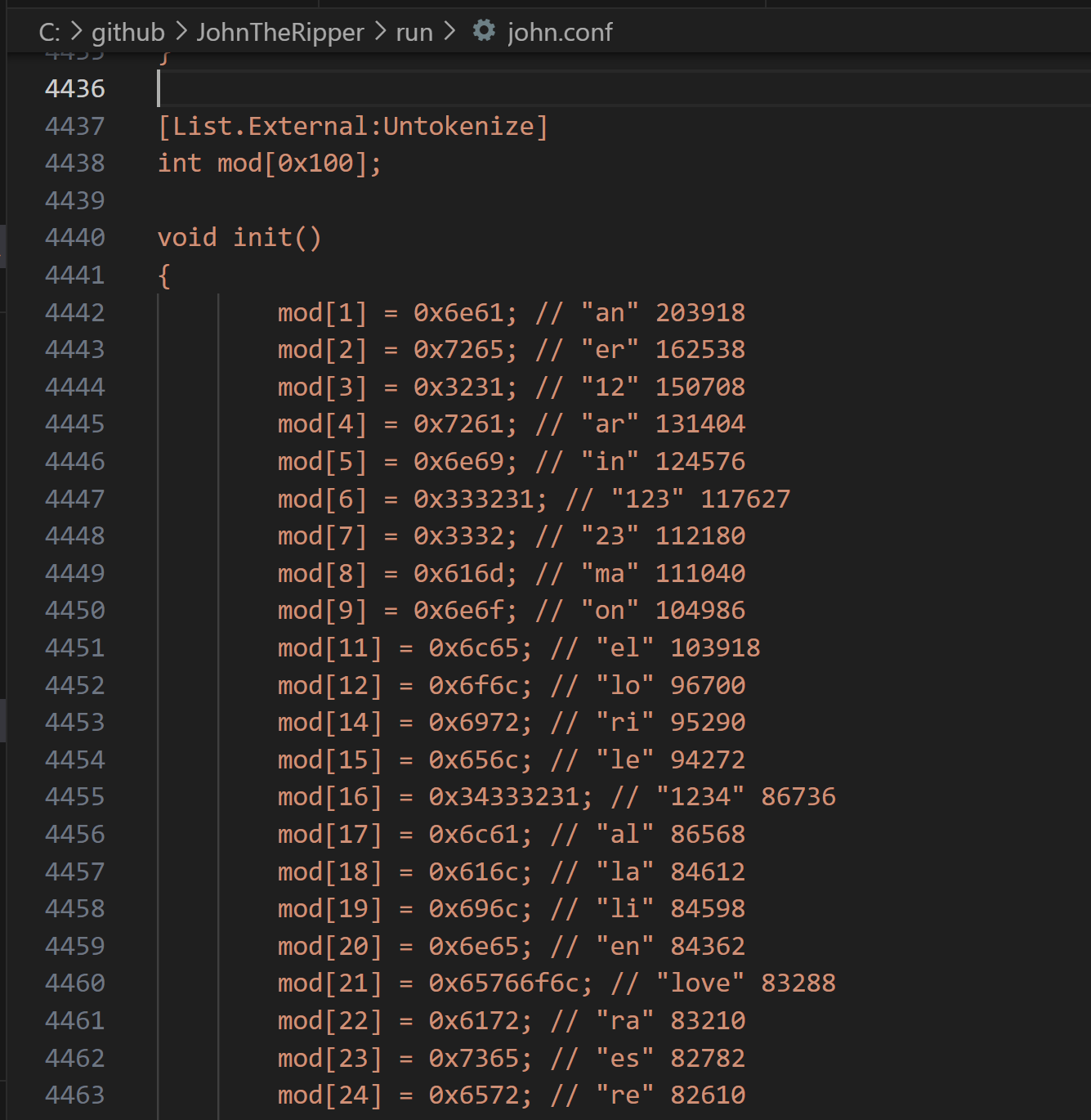
- Add the “Untokenize External Mode” config generated when you ran tokenize.pl to your john.conf
- Notes:
- I don’t think there are many restrictions where you paste this in, as long as it is not in the middle of another configuration item or at the very end.
Below is a screenshot of me running the tokenize.pl script again, with the External mode section highlighted.

Next is a screenshot of me pasting the resulting External mode into my John the Ripper config file.

Running The Attack:
To run the attack, you can use the following commands in addition to your normal attack commands:
- Arguments:
- –incremental=Tokenize : You can set this to be whatever name you specified in your john.conf file to use the .chr file you generated with tokenize.pl
- –external=untokenize : This calls the external mode to convert the tokenized output of the Incremental mode attack into a normal password guess
- Example:
- ./john –incremental=tokenize –external=untokenize –stdout
Here is a screenshot comparing the first 25(ish) guesses generated by both the new Tokenize attack and the default JtR Incremental attack. It’s interesting to note that the default Incremental attack seems to start off stronger with more likely passwords. What’s important though is longer password cracking sessions, which I’ll investigate in future tests.

Conclusion:
The next step will be to run some actual tests. The experiments SolarDesigner ran seemed to imply a significant improvement when running the tokenize attack over the first two billion guesses compared to a standard Incremental attack. This assumes you run these attacks after cracking the “common” passwords first using a more traditional wordlist attack. I’m having to restrain myself from speculating about the results of future tests that I’m planning on running (better to just run them), but hopefully this blog post is helpful for anyone else who also wants to experiment with this new attack. It’s a cool attack and a neat approach so I’m looking forward to seeing how it evolves going forward.
*** This is a Security Bloggers Network syndicated blog from Reusable Security authored by Matt Weir. Read the original post at: https://reusablesec.blogspot.com/2024/10/running-jtrs-tokenizer-attack.html
如有侵权请联系:admin#unsafe.sh