当今,扩散模型在图像生成方面取得了令人瞩目的成果,能够根据文本描述创造出逼真且多样的图像。然而,图像编辑技术却相对落后,难以满足人们对于生成内容可控性的需求。
技术能力展示:https://team.doubao.com/seededit
11 月 11 日,豆包大模型团队正式公布通用图像编辑模型 SeedEdit。让一句话轻松 P 图成为现实。
用户只需输入简单的自然语言,便可对图像进行多样化编辑操作,包括修图、换装、美化、风格转化以及在指定区域添加或删除元素等。
1. 一句话轻松 P 图,精准可控,实现高美感编辑
SeedEdit 能够广泛适应不同用户的多样化编辑需求,可控性强、编辑效果佳且无贴图感,主要体现在三个方面:
高精度指令理解,对中英文、专有名词“来者不拒”
SeedEdit 依托豆包文生图大模型,具备出色的指令理解能力。无论是中文还是英文输入,都能精准响应,对于成语、专有名词等复杂词汇也毫不逊色。
例如,当输入 “街道上车水马龙” 这样富有场景描述的指令时,SeedEdit 能够迅速捕捉关键信息,将原图巧妙地转换为一幅展现交通繁忙景象的街道画面。
prompt:街道上车水马龙
再如,输入“驴打滚换成拿破仑”这一指令,SeedEdit 准确识别出 “驴打滚” 和 “拿破仑” 的特殊含义,迅速完成美食的替换操作,完美地实现用户的编辑意图。
高质量编辑效果,聚焦目标,不“误伤”原图
与传统涂抹选中修改目标的方式相比,SeedEdit 直接通过文字指令编辑图像,在处理如裂纹、发丝等精细涂抹区域时展现出独特优势。
它能够更加灵活、精准且快速地选择目标,在编辑过程中最大限度地保持原图的完整性。
如图所示,SeedEdit 仅处理文字指令涉及区域(玻璃裂纹),图像其余部分画面结构、像素质量,均不受影响。
值得一提的是,SeedEdit 支持多轮编辑。它借助隐空间编辑技术,能维持图片像素的清晰度和画面结构的稳定性,进而支持用户长时序、复杂编辑任务。
一个茶杯经多轮编辑,华丽变身成带有“WOW”字样的大理石花纹咖啡杯。SeedEdit 不仅能变材质、加杯盖、添文字,还能换背景、增光线,轻松支持用户的创意编辑。
高效率创新模型,可实现多元风格,美观自然
相较于通过优化单一专家任务、配置专有工作流等传统方式,SeedEdit 充分发挥了通用图像编辑模型的优势。
用户只需通过简单的指令调优,即可轻松完成诸如换背景、变换风格、物体增删、替换等丰富多样的编辑任务,极大地提高了编辑效率。
让小狗手拿报纸,经过 SeedEdit 编辑后的图片整体风格自然流畅,毫无贴图感。
prompt:腊肠狗在充满泡泡的浴缸中看报纸
2. SeedEdit:从图像再生成到图像编辑
现今的扩散模型可以仅凭文本描述生成真实且多样的图像。然而,这些生成的图像通常是不可控的,在某种程度上,生成过程单凭文本难以控制。
目前,业界扩散模型图像编辑方法大致分为两类:无需训练方法、数据驱动方法,二者均有劣势。训练自由方法的重建和再生过程不稳定,容易因误差累积,造成编辑图像与输入或目标描述不一致;数据驱动方法的数据集收集困难,主要依赖工具创建数据集,性能受限于数据创建工具。
为了解决以上问题,豆包大模型团队提出 SeedEdit 框架,不引入新的参数将图像生成扩散模型转换为图像编辑模型。
团队在论文中提及:图像编辑本质上是图像重建和再生成之间的平衡,因此开发了一个 Pipeline,首先生成散布在这两个方向上的多样化成对数据,然后逐渐将一个图像条件扩散模型对齐,以在这两项任务之间达到最佳平衡。
SeedEdit: Align Image Re-Generation to Image Editing arXiv 链接:https://arxiv.org/pdf/2411.06686
SeedEdit 官网:https://team.doubao.com/seededit
具体而言,首先将文本到图像(T2I)模型视为一个弱编辑模型,改造它通过生成带有新提示的新图像来实现“编辑”。随后,将这种弱编辑模型反复进行蒸馏和对齐,以最大程度地继承再生成能力,同时提高图像一致性,如下图所示。
最终,SeedEdit 得以输出高质量、高保持、高精准的编辑图像。
用于编辑数据生成的 T2I 模型
首先,作为弱编辑模型的 T2I 模型生成带有新提示的新图像,实现初步“编辑”。
预训练的 T2I 模型通过类似 InstuctP2P 的文本描述,生成一对作为初始编辑数据的图像。
然而,现有方法如从 Prompt-to-Prompt 、调整注意力控制等,无法涵盖所有图像编辑类型,只能生成有限类型的配对数据。
为解决这一问题,SeedEdit 结合多类型的再生技术和调整参数,生成大规模配对数据集。此外,还增加随机性以确保数据多样性,再通过过滤器筛选优质例子,用于模型训练和对齐。
在 CLIP 指标基础上,SeedEdit 的对齐模型表现明显胜于简单的再生成。
带图像输入的因果扩散模型
通过最大限度继承重新生成能力、提升图像一致性,弱编辑模型 T2I 模型被蒸馏对齐为以输入为条件的编辑模型(强编辑模型)。
与过去为图像条件添加额外输入通道的方法不同,SeedEdit 图像条件扩散模型重用自注意力机制,两个分支(共享参数)分别用于图像输入与输出。
具体来说,SeedEdit 通过引入一个因果自注意力结构,两个网络能够基于中间特征建立通信。如果去掉输入分支,图像条件扩散模型将回到原始的 T2I 模型,从而实现在编辑和 T2I 数据上进行混合训练。
该做法受无需训练的方法启发,实验中在几何变形任务上表现更佳,引入新参数更少。
迭代对齐
由于噪声问题,最初在成对样本上训练的编辑模型,虽然能覆盖多样化编辑任务,但成功率有限,可能不足以应对应用需求。
为进一步确保模型鲁棒性,SeedEdit 增加额外微调轮次,逐步对齐编辑模型。
微调操作为,基于已有编辑模型,遵循上述数据流程,准备一套新数据,对结果再次进行编辑、筛选,重复多轮直至在指标上没有明显改进、模型收敛。
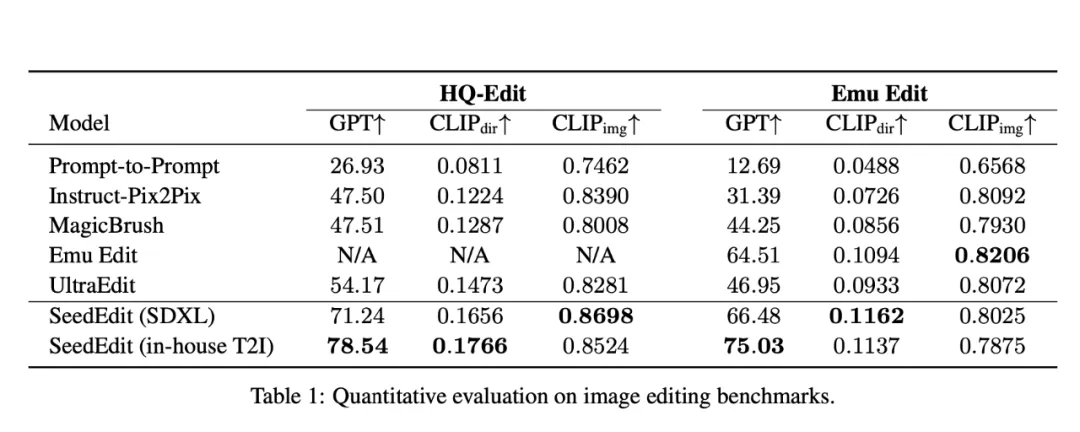
实验结果
实验选择 SDXL、MMDTi 两个基础模型,使用 HQ-Edit 、Emu Edit 数据集,采用两个指标评估编辑性能。
其中,基于 CLIP 的指标用于评估对编辑提示的对齐情况,以 CLIP 图像相似度衡量一致性。以 LLM 作为评估器的指标,GPT 用于替代 CLIP 方向分数,衡量编辑成功与否。
在 HQ-Edit 数据集上,SeedEdit 编辑分数明显高于开源基线,效果优于目前任何开源方案,有更高的 CLIP 图像相似度,原始图像保持更完整。
在 Emu Edit 基准上,SeedEdit 相比原有方法,分数实现提升或持平。
HQ-Edit 基准测试方法和基线的定性示例显示,SeedEdit 可以更好地理解模糊指令,执行细颗粒度编辑时成功率更高。
3. 持续发力图像编辑,拓展多图玩法,提升响应精度
目前,SeedEdit 模型已在豆包 PC 端和即梦网页端开启测试。
相比业内现有研究成果,SeedEdit 首次以产品形态零样本稳定跟随用户需求编辑图片,同时增强了响应能力和保持能力。这也是豆包大模型团队在多模态生图领域的一次重要拓展。
以此为起点,团队将从技术创新与玩法拓展上持续精进,全面提升图像编辑模型的综合实力。
于技术层面而言,团队将聚焦于优化 SeedEdit 在处理真实图片时的鲁棒性,同时针对性提升人体相关、人像美化、素材设计与重设计等高价值专家模型的响应效果。利用大模型能力,未来希望在图片控制上进一步扩展对于用户编辑意图的精准理解,在压缩的隐空间维度实现更精准的响应效果。
在玩法创新维度,现阶段 SeedEdit 主要致力于单图编辑,未来将拓展多图联动玩法,通过构建稳定且连贯的场景、人体与物体组合,以 “讲故事” 的方式赋予图像序列生命力,为用户的创意表达开辟更为广阔的空间,激发无限创作潜能。
如果对 SeedEdit 创新成果感兴趣,欢迎点击“阅读原文”浏览 SeedEdit 官网了解技术详情,或登录豆包 PC 端及即梦网页端体验模型能力。同时,豆包大模型团队希望吸引有志于视觉领域的优秀人才,共同用技术创造更多可能。
点击“阅读原文”,了解 SeedEdit 技术成果
如有侵权请联系:admin#unsafe.sh