Immagine in evidenza: l’attivista quechua Hilaria Supa Huamán, fonte Wikimedia 2024-11-13 17:16:20 Author: www.guerredirete.it(查看原文) 阅读量:24 收藏
Immagine in evidenza: l’attivista quechua Hilaria Supa Huamán, fonte Wikimedia
{kind=link}
In un anno elettorale come il 2024, la questione della libertà di espressione su internet è stata centrale nei dibattiti pubblici di molte democrazie. Come controllare l’hate speech e la proliferazione della disinformazione? Come far sì che internet resti un luogo aperto e accessibile a tutti gli individui – inclusi coloro che vivono sotto occupazione o in contesti di guerra?
La censura online e la libertà di espressione sono quesiti centrali del nostro tempo, alimentati da altri dilemmi connessi: il potere delle piattaforme, la mancanza di trasparenza degli algoritmi, il ruolo degli Stati e delle regolazioni pubbliche nella governance della rete. Un aspetto resta però sotto analizzato quando si parla di diritti digitali: quello della lingua.
Non è una questione secondaria. Una inchiesta del Guardian (pubblicata in agosto e basata su documenti interni condivisi da un whistleblower anonimo) ha analizzato il ruolo di Meta nel conflitto nei Territori Occupati Palestinesi e nella Striscia di Gaza. L’inchiesta ha confermato che Meta alloca risorse molto diverse per la moderazione dei contenuti in arabo e in ebraico. L’effetto di questa disparità, secondo l’analisi del Guardian, è che l’azienda esamini i contenuti nella lingua ufficiale di Israele in modo meno sistematico rispetto a quelli in arabo. Le policy di moderazione sono più severe in arabo che in ebraico, portando quindi a biases, pregiudizi, che penalizzano i contenuti palestinesi. Tali biases sono stati denunciato ampiamente da ricercatori e attivisti di lingua araba.
Al Guardian si sono aggiunti, a fine ottobre, una serie di organizzazioni della società civile, tra cui ARTICLE 19, che hanno scritto una lettera aperta a Meta accusandola di una serie di mancanze in materia di moderazione dei contenuti, tra cui un eccesso di moderazioni dei contenuti relativi alla Palestina.
I diritti digitali e quelli linguistici sono quindi interconnessi. Ma il problema ha radici ben più profonde dei conflitti recenti.
Internet e i social media nel Sud Globale: un po’ di dati
Occorre partire da alcuni dati. Il primo: il 75% degli utenti di Internet proviene da paesi in cui l’inglese non è la lingua ufficiale, e sono basati nel cosiddetto Sud Globale – le regioni del mondo che non sono né Europa né Stati Uniti. Uno dei rapporti più completi sull’uso delle lingue su internet è lo State of the Internet’s Languages report, pubblicato nel 2022. Si tratta di uno sforzo collaborativo di tre organizzazioni, Whose Knowledge?, l’ Oxford Internet Institute, e il Centre for Internet and Society (basato in India). Il rapporto offre una prospettiva statistica e dà una panoramica dell’utilizzo delle lingue online, con un focus sulle lingue cosiddette minoritarie. Questo termine è utilizzato non perché le comunità parlanti siano composte da un numero limitato di persone (almeno non in tutti i casi), ma perché negli ecosistemi digitali le loro lingue sono sotto-rappresentate. E’ il caso, ad esempio, di alcune lingue sud-asiatiche, come l’hindi o il bengalese. Scrivono Martin Dittus e Mark Graham, due ricercatori dell’Oxford Internet Institute:“Molte app e siti web non sono disponibili nelle migliaia di lingue che le persone di tutto il mondo parlano quotidianamente (…). Le interfacce utente di molte piattaforme digitali sono tipicamente disponibili solo in un numero limitato di lingue.(…) La stragrande maggioranza delle lingue africane non è supportata come lingua di interfaccia da nessuna delle piattaforme che abbiamo analizzato, e di conseguenza più del 90% degli africani deve passare a una seconda lingua per poter utilizzare la piattaforma. (…) Nell’Asia meridionale, quasi la metà delle piattaforme che abbiamo analizzato non offre il supporto dell’interfaccia per nessuna lingua regionale e le principali lingue dell’Asia meridionale, come l’hindi e il bengalese, parlate da centinaia di milioni di persone, non sono così ampiamente supportate come ci si potrebbe aspettare”.
Le piattaforme più multilingue
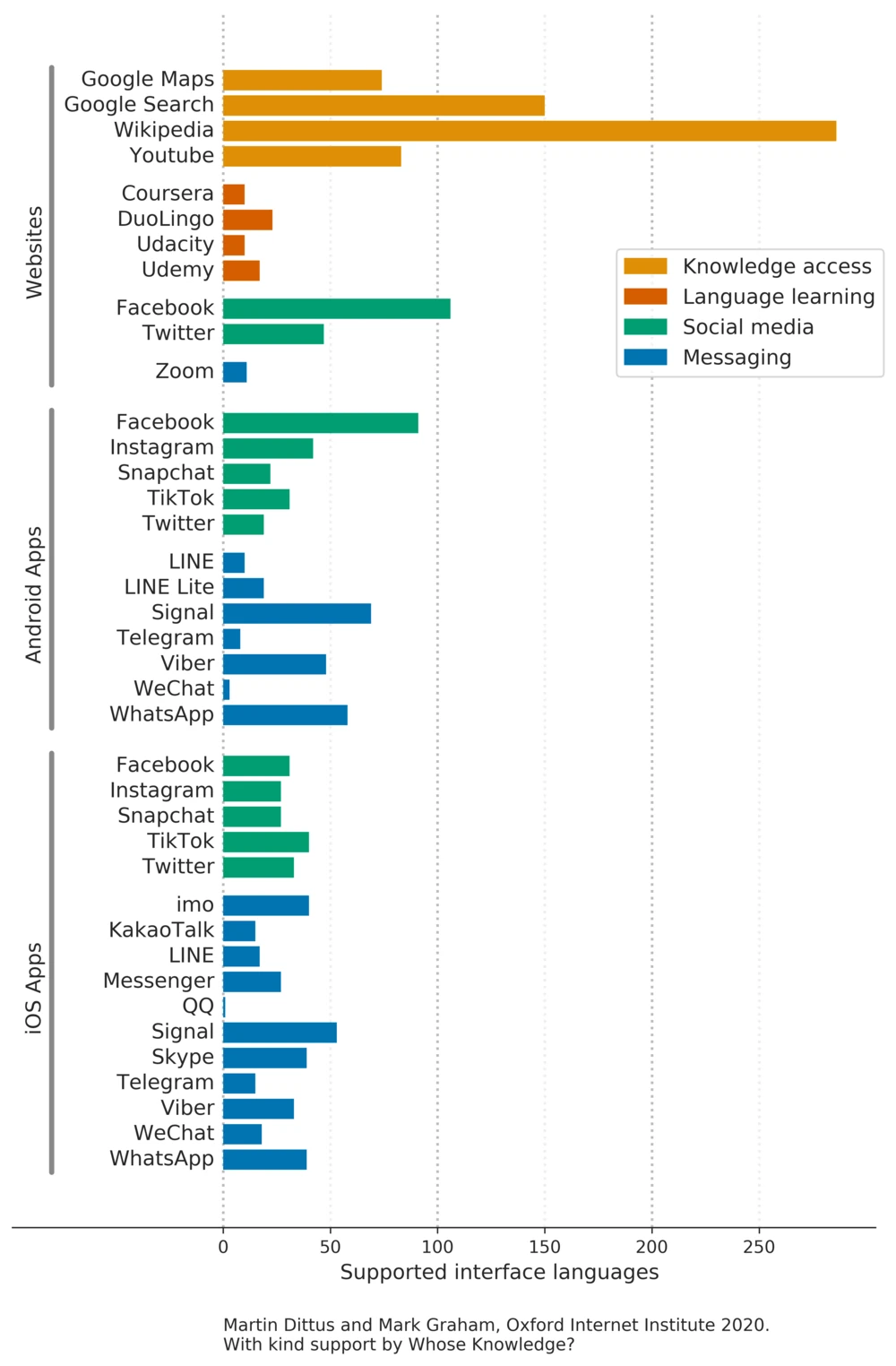
Dai dati analizzati dai ricercatori (relativi al 2020) emerge che le interfacce più tradotte sono quelle di Wikipedia, Google Search, Google Maps e Youtube, disponibili ciascuna in più di cento lingue. È interessante notare che, nonostante aziende come Google o Facebook abbiano notevoli risorse finanziarie a disposizione, il sito disponibile in più lingue sia l’enciclopedia non-profit Wikipedia.

È importante analizzare quello che i dati mostrano, ma anche quello che non mostrano, avvertono Dittus e Graham. Un’altra importante domanda è infatti quante persone restano escluse dall’utilizzo di siti e applicazioni per motivi di accessibilità linguistica? Per rispondere, i ricercatori hanno incrociato i dati sulle traduzioni dei siti / applicazioni con un elenco delle 40 lingue più parlate al mondo.

L’asse orizzontale mostra le lingue più parlate al mondo, secondo la classificazione di Etnologue. I quadrati bianchi indicano quando un sito o un’applicazione non supporta una lingua, il grigio quando la supporta parzialmente, e il verde quando la supporta totalmente. Vediamo che, anche tra le lingue più comuni, vi sono importanti lacune. L’hindi, il bengalese, lo swahili, l’urdu e il marathi sono tra le venti lingue più comuni, eppure sono significativamente meno fruibili online rispetto alle lingue europee.
C’è quindi un problema: Internet non è accessibile a tutte le persone allo stesso modo. Se l’inglese lo spagnolo, il francese e altre lingue europee sono supportate dalla maggior parte delle applicazioni, lingue come l’Urdu, il Tamil, e il Bengali non sono altrettanto utilizzate nello sviluppo delle interfacce, in particolare, possiamo dedurre dai dati, nel caso delle applicazioni mobili.
La scarsa usabilità di applicazioni in lingue cosiddette minoritarie minaccia anche la sopravvivenza di queste lingue. Ha scritto la ricercatrice italiana Claudia Soria: “E’ molto probabile che un’esperienza costantemente difficile e faticosa nell’uso quotidiano di una lingua induca un utente medio ad abbandonare una lingua a favore di un’altra che abbia un migliore supporto o che dia accesso a più servizi e opportunità, soprattutto se quest’altra scelta è una lingua che è già tra quelle che compongono la competenza multilingue del parlante”.
Combattere la disinformazione e l’hate speech? Sì, ma solo in inglese
Un ulteriore aspetto da analizzare è la sicurezza dei contenuti e l’investimento nella loro moderazione. Le grandi piattaforme impiegano personale in varie lingue per identificare post, immagini e video potenzialmente pericolosi, disinformatori, di incitamento all’odio e alla violenza. Anche in questo caso vediamo uno squilibrio a favore delle lingue europee, e in particolare dell’inglese.
Le rivelazioni della whistleblower Frances Hagen nel 2021 hanno mostrato che l’87% del budget dell’allora Facebook per combattere la disinformazione era dedicato a contenuti in inglese, quando solo il 9% degli utilizzatori della piattaforma al tempo era madrelingua inglese. Il basso investimento in moderazione di contenuti in lingue diverse dall’inglese ha avuto costi umani elevatissimi, anche di recente. In Etiopia, ad esempio, durante il conflitto civile nel Tigray alla fine del 2021, l’uso di Facebook come catalizzatore della violenza online e offline è stato ben documentato. Alla fine del 2022 Meta è stata anche oggetto di una causa legale per incitamento alla violenza etnica. Ha scritto Amnesty International: “L’azione legale sostiene che Meta ha promosso discorsi che hanno portato alla violenza etnica e alle uccisioni in Etiopia, utilizzando un algoritmo che dà priorità e raccomanda contenuti violenti e di odio su Facebook. I firmatari chiedono di impedire agli algoritmi di Facebook di raccomandare tali contenuti agli utenti di Facebook e di obbligare Meta a creare un fondo per le vittime di 200 miliardi di dollari (1,6 miliardi di dollari).”
Le vittime sono rappresentate dalla non-profit Foxglove, che si occupa di cause legali legate al mondo tech. La mancanza di moderatori di contenuti umani che conoscessero la lingua e il contesto locale ha notevolmente aggravato la situazione. Secondo quanto riporta DigWatch, Facebook ha tradotto i suoi standard di sicurezza della community nelle lingue locali etiopi, Amharic e Oromo, solo alla fine del 2021.
“Le lingue vengono aggiunte solo quando una situazione diventa apertamente ed evidentemente insostenibile, come nel caso dell’Etiopia. Di solito Facebook impiega almeno un anno per introdurre gli strumenti automatizzati di base. Intorno al 2022, in seguito alla richiesta di una moderazione più efficace in Etiopia, Facebook ha stretto una partnership con le società di moderazione locali PesaCheck e AFP Fact Check e ha iniziato a moderare i contenuti nelle due lingue. Tuttavia, sono state impiegate solo cinque persone per analizzare i contenuti pubblicati dai 7 milioni di utenti etiopi. Facebook utilizza principalmente strumenti automatici per analizzare i contenuti in Etiopia”.
Se si guarda alla condizione della moderazione per le lingue europee la situazione non appare migliore. A partire dai report di trasparenza della grandi piattaforme (che devono essere obbligatoriamente pubblicati secondo quanto stabilito dal Digital Services Act), i ricercatori di Global Witness hanno estratto i dati sul numero di moderatori nelle lingue europee per ciascuna delle grandi piattaforme: anche in questo caso, i numeri sono dominati dall’inglese.
I dati sono basi su quanto fornito dalle piattaforme, che, avvertono i ricercatori, non è sempre perfettamente trasparente. Tuttavia, alcune conclusioni possono essere tratte anche rispetto allo spazio europeo. Sia su X che su Pinterest, solo l’8% dei moderatori di contenuti conosce bene una lingua ufficiale dell’Unione che non sia l’inglese. Su YouTube, solo l’11% dei moderatori di contenuti che lavorano in lingue europee ha esaminato contenuti non in inglese. Né X né Snapchat hanno moderatori che sappiano parlare estone, greco, ungherese, irlandese, lituano, maltese, slovacco, sloveno. Per X non lavora nessun moderatore che sappia parlare ceco, danese, finlandese, rumeno o svedese.
Ricercatori e sviluppatori in lingue minoritarie
Ci sono alcuni casi in cui, a fronte di una mancanza strutturale da parte delle piattaforme, ricercatori e sviluppatori si sono organizzati in modo indipendente per creare strumenti utilizzabili nelle cosiddette lingue minoritarie. Anche nello sviluppo di applicazioni automatiche, infatti, le lingue minoritarie sono svantaggiate. Secondo una già citata del Center for Democracy and technology: “La nostra indagine rivela una tendenza preoccupante: le aziende tecnologiche stanno nascondendo ai ricercatori dati cruciali, ostacolando lo sviluppo di tecnologie di moderazione automatica dei contenuti per le lingue a bassa densità di risorse”.
I ricercatori intervistati dal CDT lavorano in tre lingue sotto-rappresentate: il Tamil, parlato in Sri Lanka e nel sud dell’India, il Kiswahili, parlato in Africa Orientale, e il Quechua una lingua indigena dell’America del Sud, comune in un territorio che comprende oggi Perù, Ecuador, Bolivia, Argentina e Cile. Uno dei problemi evidenziati è la mancanza di dati accessibili. Per sviluppare strumenti di moderazione, infatti, è necessario avere accesso a una mole significativa di dati linguistici e testuali, provenienti dalle piattaforme. Mancano informazioni che non siano in inglese, e le difficoltà sono state esasperate dai blocchi che Meta e X hanno imposto sugli strumenti di analisi per i ricercatori – come Crowdtangle e ai tool open source.
Sviluppatori e ricercatori provenienti dal Sud Globale molto spesso non hanno accesso a risorse computazionali sofisticate. Facendo di necessità virtù, hanno quindi lavorato per creare soluzioni comunitarie e dal basso. I ricercatori Tamil hanno avviato una campagna di raccolta di dati da parte degli utenti di WhatsApp per studiare la diffusione della disinformazione in India. A causa della mancanza di un numero sufficiente di testi digitali in quechua, gli sviluppatori hanno collaborato con i parlanti madrelingua, che hanno fornito volontariamente i loro dati vocali e hanno contribuito alla trascrizione manuale. Tuttavia: “i ricercatori si sentivano impotenti senza fondi e non potevano compensare equamente i membri della comunità per il loro contributo a sostenere processi di raccolta dati così elaborati”
L’IA e il Natural Language Processing
Di recente la questione linguistica si è complicata, con l’introduzione dei grandi modelli di intelligenza artificiale e di natural language processing (NLP). I grandi modelli linguistici (o LLM, large language model) sono utilizzati in vari settori (dalla traduzione, alla creazione di contenuti, allo sviluppo di chatbot conversazionali, fino ad applicazioni più sofisticate come sentiment analysis o content analysis). L’applicazione più nota, discussa e largamente utilizzata è forse ChatGPT. Ma tutte le grandi piattaforme hanno sviluppato o stanno sviluppando tecnologie linguistiche.
I primi modelli di LLM sono stati creati in inglese. In tempi più recenti gli sviluppatori hanno iniziato a progettare modelli linguistici cosiddetti multilingua, cioè in grado di analizzare e processare dati, e successivamente restituire output, in più lingue. Per sopperire alla mancanza di dati in alcune lingue viene usata una tecnica particolare : “I ricercatori sostengono che i modelli linguistici multilingue deducano connessioni tra gli idiomi, consentendo loro di applicare associazioni di parole e regole grammaticali apprese dalle lingue con più dati testuali disponibili per l’addestramento (in particolare l’inglese)”, si legge in un report del Centre for Technology and Democracy. In pratica è come se i buchi di conoscenza dell’algoritmo in una lingua venissero riempiti dalle regole e dal contesto di un’altra. I LLM multilingua generalmente performano bene, anche meglio, in alcuni casi, dei modelli mono-lingua. Ma non mancano i problemi. Ancora dal report: “I modelli linguistici multilingue sono ancora di solito addestrati in gran parte su testi in lingua inglese e finiscono quindi per trasferire valori e assunti codificati in inglese in altri contesti linguistici a cui potrebbero non appartenere.”
L’impatto delle tecnologie linguistiche nella nostra vita non farà che aumentare. per questo occorre mettere in atto un approccio basato sui diritti linguistici, che tuteli in primis gli appartenenti a comunità parlanti minoritarie. L’unico modo efficace per procedere, secondo gli esperti del CDT è coinvolgere le comunità nello sviluppo di tecnologie e nei processi di ricerca: “I parlanti di lingue locali e gli esperti del contesto dovrebbero partecipare a ogni fase di questo processo, oltre a curare i dati e valutare i modelli linguistici utilizzati dai grandi servizi online globali”. Per rendere infine, Internet uno spazio davvero accessibile.
如有侵权请联系:admin#unsafe.sh