2024-11-18 06:11:0 Author: reusablesec.blogspot.com(查看原文) 阅读量:6 收藏
This is a follow-up to my previous blog post looking at how to install/run the new John the Ripper Tokenizer attack [Link]. The focus of this post will be on performing a first pass analysis about how the Tokenizer attack actually performs.
Before I dive into the tests, I want to take a moment to describe the goals of this testing. My independent research schedule is largely driven by what brings me joy. Because of that I'm trying to get better at scoping efforts to something I can finish in a couple of days. It's easy to be interested in something for a couple of days! Therefore, my current plan is to run a couple of tests to get a high level view of how the Tokenizer attack performs and then see where things go.
To that end, this particular blog post will focus on three main "tests" to answer a couple of targeted questions.
Test 1: Analyze how sensitive Tokenizer is to the size of the training data
- Question: How sensitive is the Tokenizer attack to being trained on 1mil, or 30+ mil passwords?
- Impact: Knowing this is important since it determines if the Tokenizer attack can be effective when trained on smaller datasets. This could be a community or language specific target, or a dataset targeting a specific password creation policy.
- Secondary Reason: Identifying early on how sensitive Tokenizer is to the training size it will help inform other testing options I have available to me. For example can I train it on a subset of RockYou passwords, and then test it against a different subset from that same breach? Also, full disclosure, I made a mistake somewhere along the line of training the Tokenizer in my previous blog post that led me to think it was more sensitive to the training data size then it actually was.
Test 2: Compare a very basic Tokenizer attack against Incremental and OMEN.
- Question: How does the Tokenizer attack compare to other Markov based attacks?
- Impact: This will provide a quick gut check on if there is value in the tokenizer as-is or if this is more an academic tool to learn from. Aka should I start to incorporate it into my password cracking attacks now, or is it more like the neural network GAN attacks [Link] which were interesting research and a basis to build upon, but are worse than current methods in every way?
- Limits on Scope:
- I'm sticking to OMEN and Incremental since they are very similar attacks to tokenizer.
- There absolutely are other attack types I could run, such as Hashcat's Markov, mask attacks, JtR's --Markov mode, PRINCE, etc. To address this, I'm going to use standard training/test datasets so that way you can compare these other attacks to the Incremental/OMEN results to extrapolate how they would perform compared to Tokenizer.
- There are also a ton of variations of these attacks! For example I could use reduced character sets such as "lowernum" vs. just training on the full set of passwords in the training lists. I'm going to defer that type of experimentation for now and hopefully revisit it when digging into how to optimize cracking sessions.
Test 3: Compare Tokenizer and CutB as Part of a Larger Password Cracking Session
- Question: How does Tokenizer fit in with a larger password cracking session where various wordlist attacks have already been run?
- Impact: "Brute-Force" attacks like Incremental are usually run after wordlist attacks have been exhausted. Therefore it's important to understand how Tokenizer performs after all the "easy" passwords have already been cracked.
- Note 1: I'm going to be comparing Tokenizer against CutB since that is often used in a "throw the kitchen sink" sessions such as those in EvilMog's random ad-hoc methodology described [here].
Note on Testing Tools:
- The primary testing tool suite I'm using to analyze password cracking success is checkpass.py [Link]
- Checkpass works using plaintext passwords and generates statistics about how effective a password cracking session is. I can then paste those statistics into Excel to generate graphs.
- When performing analysis on hashed passwords, this means I need to crack them first. This can be done in a couple of different ways:
- If I've performed a lot of password cracking on the list before and have it at around 96% success rate I can generally use those plains without having to worry too much about the 4% of uncracked passwords
- I can also download wordlists from hashmob [Link] that will often achieve a high success rate since most of the lists I deal with are already on hashmob's public cracking targets.
- Finally, I can simply run the attacks I'm analyzing twice, once as a real password cracking attack, and the second time against the plains using checkpass to make some nice graphs.
Below is an example of how I run checkpass.py and use that to generate these graphs. Note: Checkpass can also create a list of uncracked passwords. This is helpful since it lets me chain together different attacks to simulate more complex cracking sessions.

Test 1: Analyze how sensitive Tokenizer is to the size of the training data
Training: RockYou
Note on RockYou Dataset: The RockYou dataset contains duplicate passwords as well as all the encoding weirdness found in the original dump. I randomized the order of the passwords in it to avoid any correlations between passwords present in the original dump, and split it into 32 1-million subsets to allow training/testing against different passwords.
- Tokenize1: Trained on a 1 million subset of RockYou
- Tokenize2: Trained on a different 1 million subset of RockYou
- Tokenize_Full: Trained on the full set of 32 million+ RockYou passwords
Testing: LinkedIn 2012 Data Breach
Notes on LinkedIn 2012 Dataset:
- Origin: There are several different LinkedIn datasets from the 2012 Linkedin data breach [Link]. For this test, I'm going to use the original dump that only included around 6.4 million hashes. This dump also had malformed hashes where the first 5 bytes of the hashes were replaced by 0's. I'm using this dataset vs. some of the later (and larger) datasets since it's been analyzed the most in academic papers.
- Obtaining the List: You can download the list from skullsecurity [Link]. I probably should compare my copy of the list to that one, so there might be some differences, but I figure it's important to point out where other researchers can get a copy.
- Cracking the List: You can crack the list using the default Hashcat raw-sha1 format since by default Hashcat ignores the first five byes of the hash. I wrote about that more [here]. If you are cracking it in John the ripper, you need to use the format "raw-sha1-linkedin"
- Obtaining plains: For this attack I was curious how effective the Hashmob plains list would be. Hashmob is a collaborative password cracking site that has some very skilled members (they won this year's CMIYC competition). So I decided to try it out and promptly fell down a rabbit hole. Before I detour into that research, let me finish up the dataset description.
- Size of Dataset vs. Cracks: 6,458,020 passwords / 5,980,436 cracked. 92% success rate.
Total Side Tangent on LinkedIn List + Hashmob Wordlists:
I'll be up front: Given the age of this dataset and the speed of the underlying hashing algorithm (raw-sha1), I was expecting the hashmob wordlist to crack over 96% of the hashes. So after seeing so many uncracked passwords, I decided to run a standard PCFG attack against the remaining hashes just to perform a sanity check. To my surprise I got a few quick hits almost immediately:

Noticing all the new cracks had non-ASCII characters, I then started up a new attack using the included Russian ruleset:

These aren't complicated passwords. For example, I believe снейка means "snake" in Russian. Wanting to dig into this more, I then ran my cracked list from 2014 when I was investigating this list against the left list.

The actual cracked list was much more, but what's interesting was that almost all of the new (or really old depending on how you look at it) cracks were of e-mail addresses. I talked with a couple other researchers, one of which graciously provided me his cracked list, and I saw similar results. More e-mail addresses and more non-ASCII cracked passwords.
Current Theory: I suspect the Hasmob team strips e-mail addresses from their plain/cracked wordlists they provide to the public. I also suspect they run into issue creating a wordlist with all the weird encoding issues found with passwords in the wild, so their wordlist has gaps in non-ASCII cracks. I want to stress, all of these gaps are 100% totally reasonable, and when it comes to stripping e-mail addresses, commendable! But it's something to keep in mind when using these lists to conduct academic research.
Impact to these tests: While I'd like to have a higher crack percentage, given the fact that so many of the uncracked passwords likely contain non-ASCII characters or are e-mail addresses, this shouldn't have a big impact when analyzing how tokenizer performs. This is because as configured, my tokenizer attacks are unlikely to crack very many of these uncracked passwords. In the future I might run another "real" test of tokenizer against these hashes, but I'm going to put that off until I spend more time validating/improving my testing tools.
Test 1 Results:

Test 1 Analysis:
The two tokenizer attacks trained on 1 million passwords performed very similarly (you almost can't see the second line on the graph). This is a good result since it points to being somewhat resilient to minor differences in the training data. You will notice though that the tokenizer attack trained on the full 32 million RockYou passwords does perform noticeably better.
There's a lot of additional questions that come to mind about this, but I'm going to let these results stand alone for your interpretation and move on to the next set of planned tests.
Bonus Analysis and Correction:
In my previous post I posted the first 25 guesses my training of tokenizer produced, and it looked "weird". SolarDesigner replied with what they were seeing when running their own copy which was very different (and looked more like what I originally expected) [Link]. I reran all my training, and then started getting similar results to Solar. Long story short, somewhere along the way with my troubleshooting and figuring out this attack I made a mistake. Here are the updated results of the first 25 guesses generated by tokenizer with the Rockyou training data above, along with the results Solar provided:

The guesses highlighted in green are guesses that were shared with one of the other training runs.
Test 2: Compare a Tokenizer attack against Incremental and OMEN
Training:
All three attack modes were trained on the same 1 million subset of RockYou passwords
- Tokenizer1: Trained on a 1 million subset of RockYou as described previously
- OMEN1: Trained on the same 1 million subset of RockYou passwords. Using the OMEN attack mode build into the PCFG toolset [Link]. While you can specify during training to only generate guesses using OMEN, I took a shortcut and just modified the grammar.txt file of the ruleset to only include "M" (Markov) replacements. This way the PCFG cracker will only generate guesses using OMEN.
- Incremental=Rockyou1: Trained Incremental mode on the same 1 million subset of RockYou passwords. This is roughly equivalent of Incremental=ASCII since I didn't apply a filter which means guesses included upper/lower alpha as well a digits and special characters.
Testing:
- Test 2a: Testing against a different 1 million password subset of the RockYou list. Aka this is a different subset than what the attacks were trained upon
- Test 2b: Testing against the 2012 LinkedIn list (I wasn't planning on running this test, but after looking at the results of Test #1, I was really curious).
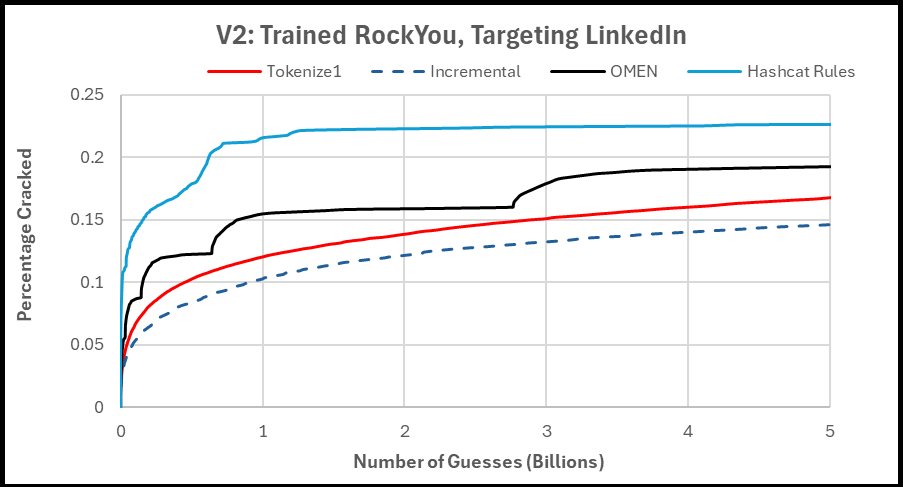
Test 2a Results:

This was interesting, but you really can't see what's going on at the start of the password cracking session. So the next graph is the same test/data, but just zoomed in to the first 20 million guesses.

Test 2b Results:

Test 2(AB) Analysis:
Not a lot of surprises here, which is good! OMEN is a very effective attack mode so that was always a tough one to beat. The challenge with OMEN is the lack of an indexing function (aka being able to tell it "generate password at position 2941932", which leads to complications with pausing/restarting cracking sessions. So I generally use Incremental mode in my real password cracking sessions. It's just easier. Which means that having the Tokenize attack improve upon standard Incremental mode is a big deal.
Side note: I try to point this out whenever talking about OMEN, but you'll notice the sawtooth success rate as it tends to crack more passwords at the start of OMEN "level". This highlights significant room for improvement if any researchers want to look into this. Ideally you'd have a smoother graph to frontload all your effective guesses near the beginning of your cracking session.
Test 3: Compare Tokenizer and CutB as Part of a Larger Password Cracking Session
For this last test I wanted to simulate a larger cracking session. For this I'm loosely going to base my attacks on EvilMog's "Random AD Methodology" describe [Here]. By loosely I mean I'm just going to simulate the first three steps:
- run rockyou with -g 100000 or all the rulesets combined
- (Comparison point) run expander (modified to max at 8 or 10), and then run -a1
- (Comparison point) run cutb with -a1
For the first step, I'm going to use the full RockYou wordlist (only unique words) and the "Hashcat" ruleset in John the Ripper. I figure that gets close the the intention of step #1 without having to resort to making 100k random rules up on the spot.

The John the Ripper "Hashcat" ruleset is actually a collection of rules from the Hashcat repo modified to work with JtR:
[List.Rules:hashcat]
.include [List.Rules:best64]
.include [List.Rules:d3ad0ne]
.include [List.Rules:dive]
.include [List.Rules:InsidePro]
.include [List.Rules:T0XlC]
.include [List.Rules:rockyou-30000]
.include [List.Rules:specific]
The challenge from an analysis perspective these attacks generate an absolute ton of guesses! Partly this is because they aren't optimized. None of these attacks have "reject" functions built into them so every mangling rule is applied to every input word regardless if the mangling rule would actually change that word. This is also because there is significant overlap in the individual mangling rules across these different rulesets.
What I'm trying to say is if I ran this attack with the Rockyou wordlist on my research laptop and piped it into checkpass.py (which itself can be a bit slow), the attack would take me around two weeks to complete. To that end, I ran a "quick" attack of just 5 billion guesses which gets through the best64 ruleset and into d3ad0ne ruleset using checkpass.py simply because I wanted to compare that to my previous graphs. I then launched all these attacks for real on a different computer to create a potfile of all the passwords cracked using these attacks.
(Future Improvement): Hashcat supports the ability to record "guess position" in the outfiles (potfiles) it generates. I've never really used that, but I plan on looking into that feature in a future "improve my testing process" research sprint. For now though, it's just easier to launch JtR and let it run while I do other things.

While I could be more scientific about it, given the 16 million word wordlist (Rockyou-Unique) and the Best64 ruleset (which has slightly more than 64 rules), the Best64 ruleset finishes up somewhere around 1 billion guesses, which is pretty evident from the graph above. The other Hashcat rulesets are not nearly as optimized. This does highlight though that starting a password cracking session off with a "smart" dictionary attack is still one of the best ways to crack passwords quickly.
Success Ratio for Full Hashcat Rules vs. LinkedIn:
- 3,140,344 of 6,458,020 password cracked. (48.64% success rate)
- As comparison: with all my attacks and the wordlists downloaded from Hashmob, I have 5,980,436 passwords cracked. So this attack is respectable, but there's certainly room to crack more passwords.
Introduction to Hashcat Utils:
For this test, steps #2 and #3 involve using expander and cutb. If you are not familiar with these tools, they are part of Hashcat Utilities [Link].
While you can build the tools in Hashcat Utilities from source [Link], the latest release binaries are available [Here].
As to what Hashcat Utilities are, you can get more detailed information from the first link above, but at a high level they are a set of tools that each perform one specific task Many of them can be chained together (or used stand-alone) to create targeted wordlists which is how we'll be using them in this experiment.
Expander: This tool basically mangles and creates new combinations of words from individual characters found in each word in the input dictionary. The actual operation is a bit weird, but imagine you wrote the input word on a piece of paper and then folded the paper into a circle so the word is like a bracelet. Expander then creates new words by taking cuts out of that bracelet. So "password123" can generate the guess "3pas" as it wraps around. By default it will generate all 1-4 letter combinations from the input wordlist that is piped to it. You can increase this by changing a macro variable in the source and recompiling it. Some people will have multiple versions of expander built with the length of guesses they generate appended to the filename. For example "expander8.bin". Another approach to make longer guesses without having to recompile the code is to combine multiple runs of "length 4" expander using Hashcat's combinator mode to generate longer password guesses. Here is an example of me running expander with one input "word".
- echo password123 | ./expander.bin
Expander will then return the following output (only showing a sample as the full output is 40 unique words):
- p
- a
- <Cut>
- 3
- pa
- ss
- wo
- <Cut>
- ssw
- ord
- 123
- ass
- <Cut>
- pass
- word
- assw
- <Cut>
- ord1
Side note: I was really surprised by guesses Expander didn't make. For example "23pa" was not generated. So it's not an exhaustive list and there are some exceptions in the substrings it generates.
Expander is the basis of what's been called a "Fingerprint" attack. This was first described by pure_hate in the following blogpost where they used it as part of the 2010 CMIYC competition [Link]. A more modern take and example of using a Fingerprint attack can be found [Here].
Now, you generally need to be selective in the input wordlists you feed to Expander since this attack can very quickly get to the point where it's almost equivalent to a full dumb brute-force attack. You also need to make sure you "sort -u" the outputs of Expander since it often generates a ton of duplicate guesses. Because of this, I generally wouldn't recommend using Expander on normal password cracking wordlists. Instead, people will often use Expander on previously cracked passwords to get new cracks. For example:
- Remove the hashes from a standard hashcat potfile and save the results in plains.txt. Note: Unlike John the Ripper's "--show" command, this will output everything in the potfile vs. generating individual lines for each target hash.
- cat hashcat.potfile | cut -d: -f2- | sort -u | plains.txt
- Pipe the plains into expander to create the "base" wordlist.
- cat plains.txt | expander | sort -u > plains_expanded.txt
- Run a basic hashcat combinator attack (-a 1) using the plains_expanded.txt wordlists
- hashcat -m HASH_MODE -a 1 TARGET_HASHES.hash plains_expanded.txt plains_expanded.txt
To continue to build this out and target passwords greater than 8 characters long you can re-run variations of the above commands like as follows:
- Generate a wordlist of all 8 character long Expander generated words:
- hashcat --stdout -a1 plains_expanded.txt plains_expanded.txt | sed -n '/.\{8\}/p' | sort -u > plains_expanded_8.txt
- Generate guesses 9-12 characters long in Hashcat
- hashcat -m HASH_MODE -a 1 TARGET_HASHES.hash plains_expanded_8.txt plains_expanded.txt
You can keep building this process out for longer guesses. Now you know how to run a fingerprint attack!
CutB: This tool allows you to "cut" substrings from an input wordlist for use in hashcat combinator and hybrid (rule-based) attacks. It's a lot easier than piping your wordlists into sed, awk, or other linux tools to retrieve substrings. I'd recommend checking out the Hashcat wiki for info on how to use it, but at a high level you can give it two numbers on the command line to specify which substrings you want to extract. Aka:
- echo password123 | ./cutb.bin 0 4
- Result: pass
- echo password123 | ./cutb.bin 4
- Result: word123
- echo password123 | ./cutb.bin -4
- Result: d123
Often CutB will be run in a script to generate many, many, different subsections of a password guess. You may notice that CutB is pretty similar in operation to Expander, but it allows you much more flexibility to be somewhat targeted about how you apply your cuts.
Side note: CutB's code is weird, and it won't always perform like you'd expect. For example:
- echo password123 |./cutb.bin -5
- Result: rd123
- echo password123 |./cutb.bin -6
- Result: ord12
- echo password123 |./cutb.bin -7
- Result: word
I really don't know what's going on with those two last guesses.....
Description of Test 3 Attacks:
Tokenizer_RockyouFull:
- I'm going to use the version of Tokenizer trained on the full list of 32 million+ Rockyou Passwords
Tokenizer_LinkedinPot:
- This version of Tokenizer is going to be trained on the LinkedIn passwords cracked during the Hashcat rules wordlist attack using the Rockyou_Unique wordlist.
- I'm including duplicated guesses in the training set by generating a list using "./john --show --format=raw-sha1-linkedin --pot=TESING_POTFILE"
- The goal of this attack is to try and make a direct comparison of Tokenizer to CutB and Expander
Expander:
- This attack will use Hashcat Utils: Expander to create a wordlist based on uniquely cracked passwords from the Hashcat rules wordlist attack against Linkedin.
- The resulting wordlist (after sort -u is run on it) has 1,854,331 lines.
- Pow(96 character, 4) = 85 million(ish), and this wordlist included non-ASCII characters as well, so this still represents a significant reduction from a true brute force attack.
- This will be run using Hashcat's combinator attack "-a 1" as described above.
- I'm only doing this first run of expander that will create guesses 2-8 characters long since this attack won't complete in the first 5 billion guesses.
CutB:
- This is going to use CutB trained on uniquely cracked passwords from the Hashcat rules wordlist attack against Linkedin.
- Following the cutb.sh script [Link] in Evilmog's Hashcat scripts, cutb will create two lists. that take cuts from both the front and back of the input words. Pseudocode below:
- for x in range(1,8): cutb 0 x
- for x in range(1,8): cutb -x
- The lists will then be combined and run through "sort -u" to remove duplicates.
- The resulting wordlist contains 7,476,636 lines. These lines range from 1 to 8 characters long. So this is a bigger wordlist than Expander, but it also can generate longer guesses.
- The actual attack will be run using the default PRINCE settings in John the Ripper. For more information about PRINCE, see my blogpost [Here].
Description of Test 3 Target:
All attacks will be run against the remaining uncracked passwords from the 2012 LinkedIn password list after the JtR Hashcat rules with Rockyou-Unique wordlist have been run against it. Each attack will be run for 5 billion password guesses. This is a very short runtime for these attacks. Normally these attacks will generate trillions of password guesses. Future testing might include Hashcat's outfile debugging formats or running the attacks for a set time, but I figure 5 billion guesses can start to indicate how these attacks will compare to each other.
Test 3 Results:
Quick summary of results:
- Tokenize RockyouFull: 8,423 cracked
- Tokenize LinkedInPot: 14,984 cracked
- Expander: 141 cracked!!!
- CutB: 7,344 cracked
I didn't expect Expander to do very well given the short number of guesses, but this low number really shocked me. I'm pretty sure just creating random wordlist rules using "hashcat -g 100000" would be more effective.

As for the graph of the results see below. As a disclaimer, due to the small number of cracks vs. the total size of the list, don't read too much into it:

Analysis of Tet 3 Results:
While it's never fun to say that the biggest finding is that your test setup is flawed, that's my main takeaway from these tests. When looking at the results, 5 billion guesses is way too low a number to analyze these attacks after trillions of guesses have been made running wordlist attacks. Going back to Test 2, (and quick disclaimer this is not a direct comparison due to different training sets for Tokenizer), but Tokenizer cracked over 1 million passwords when it was run as the first attack. So when it cracks just 14k unique passwords more than the Hashcat Rules based attacks, that shows a strong overlap in the guesses that these two attacks are making.
This is a long way of saying, after an initial very long run using the Hashcat Rules attack against LinkedIn, I don't expect any non-wordlist based attack to do very well for just 5 billion guesses. So while it's easy for me to make fun of Expander, I really can't make any definitive statement about how these attacks perform in real life unless I run a cracking session that represents several days with a GPU.
Looking at the bright side, I'm glad I ran this test. It forced me to better understand some of the tools in Hashcat Utilities, as well as start to identify what future tests should look like as well as gaps in my testing strategies.
Future Research Ideas:
I'll be up front: The holidays are coming up, and I have a lot of other research items I'm working on that I would like to finish up [Spoiler/Link]. This basically means that while there are a ton of unanswered questions from this blog post, I'm probably not going to get around to investigating them anytime soon. As a note to my future self though, here are a couple of topics that jump out to me:
- Develop a process to track/analyze longer password cracking session.
- My gut feeling is this will require using Hashcat's output options to print guess positions for new cracks. I spent a lot of time looking at JtR's log format but I don't think I saw an equivalent guess position option.
- This is a general problem for academic research. Either the sessions modeled are very short (several billion guesses), or some alternative method such as Monte Carlo estimations are used to predict how effective a longer password cracking session would be. Disclaimer: I'm very skeptical about the accuracy of the Monte Carlo estimations. But I'm willing to be convinced otherwise if someone can run a real session and the results roughly match the estimates.
- Investigate how to optimize the "guessing budget" in OMEN levels to smooth out it's cracking graph and move more effective rule to earlier in the cracking session.
- As I mentioned earlier, that sawtooth graph highly implies that there is a lot of room for optimization within the OMEN attacks.
- Incorporate the Tokenizer approach into OMEN.
- Besides the general OMEN improvements above, I think the Tokenizer approach shows a lot of promise for improving Markov based attacks by adding variable length Markov orders into them.
- There's probably an academic paper that can be written on this. If you are a research student thinking about this and want an advisor or consult, drop me a line as I have a lot of thoughts about this.
- Make Tokenizer Attacks Easier to Run.
- I think the Tokenizer attack is a really cool improvement to John the Ripper's Incremental mode attacks. Using this attack will improve your password cracking success rate.
- The challenge is due to the complications of getting this to run, I'm very doubtful about how many people will take advantage of this improvement.
- Ideally tokenizer attacks should be run exactly like Incremental attacks, and the "external mode" requirement should be hidden from the user.
- I'd also like to make training a new tokenizer attack to be easier
- It would be nice to train Incremental mode attacks from a list of plaintext passwords as well as from a potfile.
- There's a couple of different manual steps required to train a Tokenizer attack. It would be helpful to combine them together so only one command needs to be run, (besides updating your john-local.conf to include the attack).
如有侵权请联系:admin#unsafe.sh