By Artem Dinaburg
AI-enabled code assistants (like GitHub’s Copilot, Continue.dev, and Tabby) are making software development faster and more productive. Unfortunately, these tools are often bad at Solidity. So we decided to improve them!
To make it easier to write, edit, and understand Solidity with AI-enabled tools, we have:
- Added support for Solidity into Tabby and Continue.dev, two local, privacy-preserving AI-enabled coding assistants
- Created a custom code completion evaluation harness, CompChomper, to evaluate how well different models perform at Solidity code completion
We also evaluated popular code models at different quantization levels to determine which are best at Solidity (as of August 2024), and compared them to ChatGPT and Claude. Our takeaway: local models compare favorably to the big commercial offerings, and even surpass them on certain completion styles.
However, while these models are useful, especially for prototyping, we’d still like to caution Solidity developers from being too reliant on AI assistants. We have reviewed contracts written using AI assistance that had multiple AI-induced errors: the AI emitted code that worked well for known patterns, but performed poorly on the actual, customized scenario it needed to handle. This is why we recommend thorough unit tests, using automated testing tools like Slither, Echidna, or Medusa—and, of course, a paid security audit from Trail of Bits.
AI assistant improvements
At Trail of Bits, we both audit and write a fair bit of Solidity, and are quick to use any productivity-enhancing tools we can find. Once AI assistants added support for local code models, we immediately wanted to evaluate how well they work. Sadly, Solidity language support was lacking both at the tool and model level—so we made some pull requests.
Trail of Bits added Solidity support to both Continue.dev and Tabby. This work also required an upstream contribution for Solidity support to tree-sitter-wasm, to benefit other development tools that use tree-sitter.
We are open to adding support to other AI-enabled code assistants; please contact us to see what we can do.
Which model is best for Solidity code completion?
What doesn’t get benchmarked doesn’t get attention, which means that Solidity is neglected when it comes to large language code models. Solidity is present in approximately zero code evaluation benchmarks (even MultiPL, which includes 22 languages, is missing Solidity). The available data sets are also often of poor quality; we looked at one open-source training set, and it included more junk with the extension .sol than bona fide Solidity code.
We wanted to improve Solidity support in large language code models. However, before we can improve, we must first measure. So, how do popular code models perform at Solidity completion (at the time we did this work, August 2024)?
To spoil things for those in a hurry: the best commercial model we tested is Anthropic’s Claude 3 Opus, and the best local model is the largest parameter count DeepSeek Coder model you can comfortably run. Local models are also better than the big commercial models for certain kinds of code completion tasks.
We also learned that:
- A larger model quantized to 4-bit quantization is better at code completion than a smaller model of the same variety.
- CodeLlama was almost certainly never trained on Solidity.
- CodeGemma support is subtly broken in Ollama for this particular use-case.
Read on for a more detailed evaluation and our methodology.
Evaluating code completion
Writing a good evaluation is very difficult, and writing a perfect one is impossible. Partly out of necessity and partly to more deeply understand LLM evaluation, we created our own code completion evaluation harness called CompChomper.
CompChomper makes it simple to evaluate LLMs for code completion on tasks you care about. You specify which git repositories to use as a dataset and what kind of completion style you want to measure. CompChomper provides the infrastructure for preprocessing, running multiple LLMs (locally or in the cloud via Modal Labs), and scoring. Although CompChomper has only been tested against Solidity code, it is largely language independent and can be easily repurposed to measure completion accuracy of other programming languages.
More about CompChomper, including technical details of our evaluation, can be found within the CompChomper source code and documentation.
What we tested
At first we started evaluating popular small code models, but as new models kept appearing we couldn’t resist adding DeepSeek Coder V2 Light and Mistrals’ Codestral. The full list of tested models is:
- CodeGemma 2B, 7B (from Google)
- CodeLlama 7B (from Meta)
- Codestral 22B (form Mistral)
- CodeQwen1.5 7B (from Qwen Team, Alibaba Group)
- DeepSeek Coder V1.5 1.3B, 6.7B (from DeepSeek AI)
- DeepSeek Coder V2 Light (from DeepSeek AI)
- Starcoder2 3B, 7B (from BigCode Project)
We further evaluated multiple varieties of each model. Full weight models (16-bit floats) were served locally via HuggingFace Transformers to evaluate raw model capability. GGUF-formatted 8-bit quantized (Q8) and 4-bit quantized (Q4_K_M) quantizations were served by Ollama. These models are what developers are likely to actually use, and measuring different quantizations helps us understand the impact of model weight quantization.
To form a good baseline, we also evaluated GPT-4o and GPT 3.5 Turbo (from OpenAI) along with Claude 3 Opus, Claude 3 Sonnet, and Claude 3.5 Sonnet (from Anthropic).
Partial line completion results
The partial line completion benchmark measures how accurately a model completes a partial line of code. A scenario where you’d use this is when typing a function invocation and would like the model to automatically populate correct arguments. Below is a visual representation of partial line completion: imagine you had just finished typing require(. Which model would insert the right code?
function transferOwnership(address newOwnerAddress) external {
require(
_ownerAddress = newOwnerAddress
}
Figure 1: Blue is the prefix given to the model, green is the unknown text the model should write, and orange is the suffix given to the model. In this case, the correct completion is msg.sender == _ownerAddress);.
The most interesting takeaway from partial line completion results is that many local code models are better at this task than the large commercial models. This could, potentially, be changed with better prompting (we’re leaving the task of discovering a better prompt to the reader).

Figure 2: Partial line completion results from popular coding LLMs. In this test, local models perform substantially better than large commercial offerings, with the top spots being dominated by DeepSeek Coder derivatives. The local models we tested are specifically trained for code completion, while the large commercial models are trained for instruction following. (Max score = 98.)
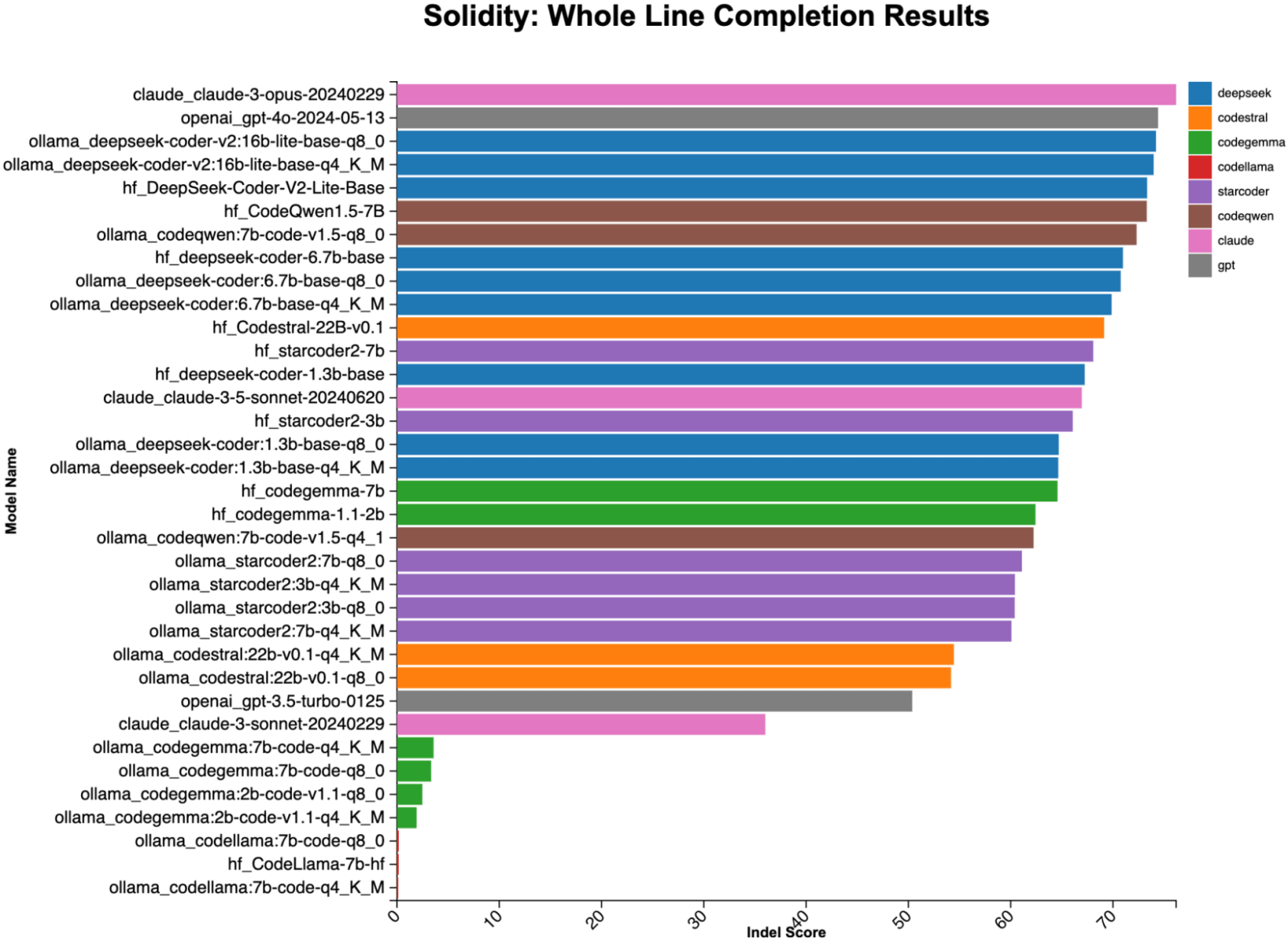
Whole line completion
The whole line completion benchmark measures how accurately a model completes a whole line of code, given the prior line and the next line. A scenario where you’d use this is when you type the name of a function and would like the LLM to fill in the function body. This style of benchmark is often used to test code models’ fill-in-the-middle capability, because complete prior-line and next-line context mitigates whitespace issues that make evaluating code completion difficult. Below is a visual representation of this task.
function transferOwnership(address newOwnerAddress) external {
_ownerAddress = newOwnerAddress;
}
Figure 3: Blue is the prefix given to the model, green is the unknown text the model should write, and orange is the suffix given to the model. In this case, the correct completion is:
require(msg.sender == _ownerAddress);.
The large models take the lead in this task, with Claude3 Opus narrowly beating out ChatGPT 4o. The best local models are quite close to the best hosted commercial offerings, however. Local models’ capability varies widely; among them, DeepSeek derivatives occupy the top spots.

Figure 4: Full line completion results from popular coding LLMs. While commercial models just barely outclass local models, the results are extremely close. (Max score = 98.)
What we learned
Overall, the best local models and hosted models are pretty good at Solidity code completion, and not all models are created equal. We also learned that for this task, model size matters more than quantization level, with larger but more quantized models almost always beating smaller but less quantized alternatives.
The best performers are variants of DeepSeek coder; the worst are variants of CodeLlama, which has clearly not been trained on Solidity at all, and CodeGemma via Ollama, which looks to have some kind of catastrophic failure when run that way.
It may be tempting to look at our results and conclude that LLMs can generate good Solidity. Please do not do that! Code generation is a different task from code completion. In our view, using AI assistance for anything except intelligent autocomplete is still an egregious risk. As mentioned earlier, Solidity support in LLMs is often an afterthought and there is a dearth of training data (as compared to, say, Python). Patterns or constructs that haven’t been created before can’t yet be reliably generated by an LLM. This isn’t a hypothetical issue; we have encountered bugs in AI-generated code during audits.
As always, even for human-written code, there is no substitute for rigorous testing, validation, and third-party audits.
What’s next
Now that we have both a set of proper evaluations and a performance baseline, we are going to fine-tune all of these models to be better at Solidity! This process is already in progress; we’ll update everyone with Solidity language fine-tuned models as soon as they are done cooking.