
This is a blog post by Erik Szinai, who worked with us as an intern during the last co 2024-12-6 16:0:0 Author: blog.silentsignal.eu(查看原文) 阅读量:19 收藏
This is a blog post by Erik Szinai, who worked with us as an intern during the last couple of months. We hope our readers will find his contribution to the Burp Suite ecosystem useful!
Burp usually excels in automatically detecting arbitrarily nested structures, encodings and datatypes found in HTTP requests and responses, however, during one of our security assessments we came across a strange phenomenon. It was an API testing scenario, where the body of a POST request contained a Base64-encoded XML. At first, we thought no biggie, Burp will handle this like it usually does, but to our surprise it couldn’t detect the underlying structure, which obviously meant that running an Active Scan on that specific request resulted in nothing useful. At that point, we thought that the problem arose because of the nested structure or the length of the XML, however, those assumptions couldn’t have been further from the truth, as it turned out that the actual issue was rather absurd: the XML body contained the string “Olá mundo”, and when the XML was Base64-encoded, the Spanish “á” completely blindfolded Burp’s detection logic.

After we debugged that issue, Dnet quickly wrote a PoC Insertion Point Provider extension using the old Wiener API to tackle this exact problem, however, we thought it’d be cool to have a more general and refined solution to handle nested data structures, just in case we come across a similar problem in the future. Since the way how Burp detects these structures and encodings is essentially a black box, if shit hits the fan, it’s really tough to discover what went off the rails (and that’s assuming that we do realize that something is off). Also, it’s important to note that our goal wasn’t simply about solving the charset problem, but to have a proper extension that can detect nested, even unknown serializable objects over which we have total control. That’s why we decided to create an easily customizable extension that can detect and automatically encode / decode even the most messed up encodings and nested structures with a reasonable one-time setup cost.
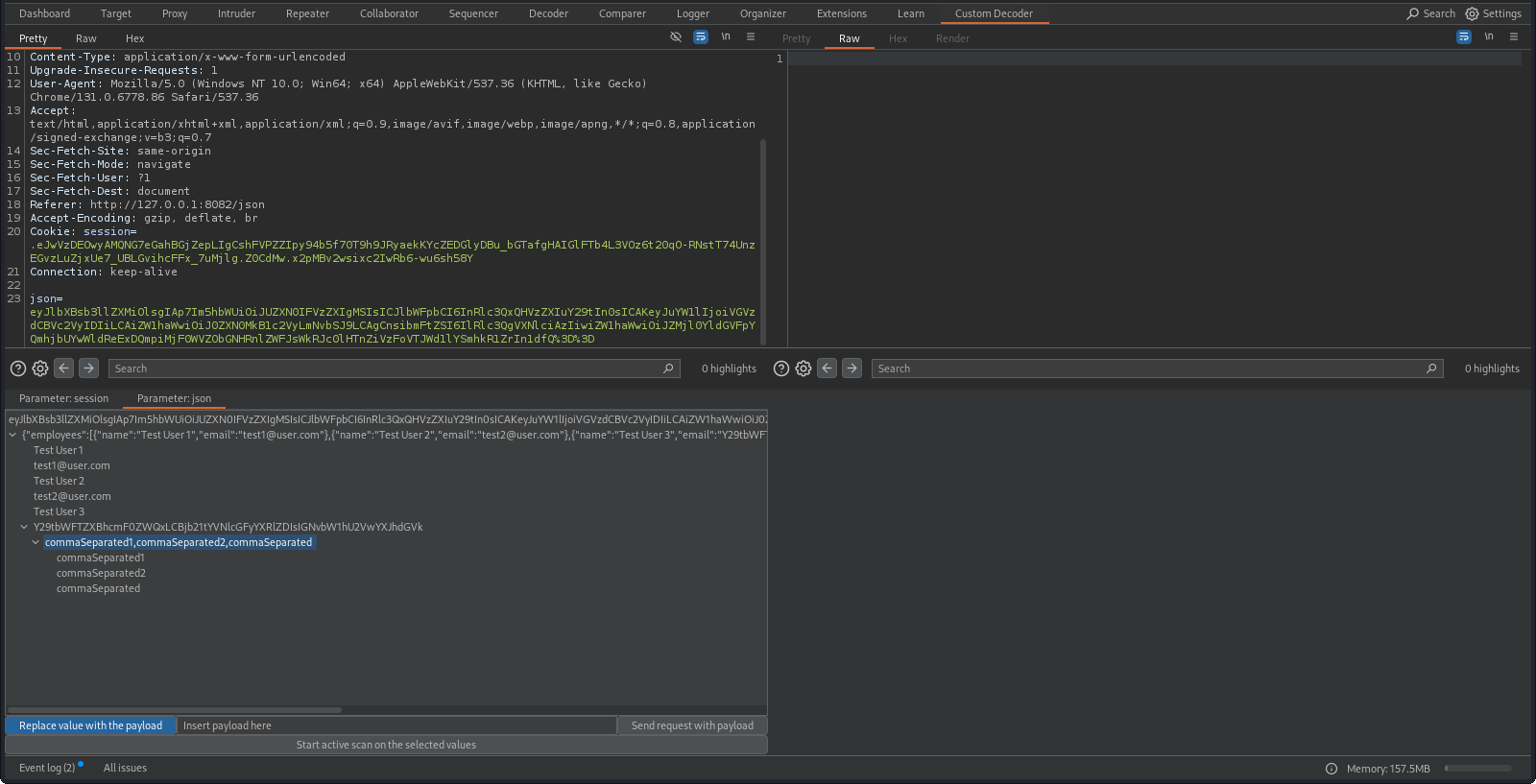
Our extension basically serves as an Insertion Point Provider, but unlike most implementations, this one has a GUI. A request can be sent to the extension using the context menu, where each parameter of the original request is decoded and shown in a tree-like view. From there, we can do two things:
- Modify one of the values and send a single request with the newly crafted parameter. We don’t have to deal with manually encoding the whole thing, which would be a really tedious, time-consuming and nailbiting task, as the extension takes care of it: it keeps track of the parent-child hierarchy with the corresponding encodings, so it automatically constructs the new parameter in the right type of encoding.
- The second option is to select multiple nodes, which will then act as insertion points and start an Active Scan on these. Here we also have the option to decide how we want the payload to be “processed”: we can either choose to replace the whole value with the payload generated by Burp, or we can choose so the payload only gets appended to our selected value(s), which could come in handy when we are dealing with injection-type vulnerabilities for example.
One drawback we have experienced with our extension is connected to the payloads generated by Burp.
We did some research on this topic and we also experimented with it, and found out that Burp dynamically tries to guess what kind of payloads it should insert based on the characteristics of previous responses and some other factors. However, its success is a bit of a hit-and-miss when dealing with custom insertion points.
We have tried to set the correct insertion point types for the custom IPs (e.g.,
we set PARAM_XML_ATTR enum constant for an XML attribute), but Burp seemingly ignored this and didn’t put more focus on XML-related payloads for the given insertion point (in fact, it didn’t even send one).
This could be solved by manually editing the audit’s configuration, though.
If you want to get involved in the more technical details, how we implemented the extension, and if (for some weird reason) you are missing some recursive methods from your life, feel free to read the next section.
Otherwise, you can just grab the extension from GitHub right away!
Technical Details
Since we wanted our extension to be easily customizable, we opted to create an interface that defines all of the methods one encoding type should implement, which we named HandleEncoding.
These methods for example include the logic to decide whether a given string can be considered one specific encoding.
For instance, detecting a Base64-encoded strings can be done using regexes, however, this approach might produce some false positives, and to mitigate this, we introduced a threshold limit regarding the minimum length of the string.
For JSON, we did a pre-check: first, we examined whether the first non-whitespace character is either ‘[’ or ‘{‘ (we did similarly with the closing brackets), and only tried to parse the string if the previous check has passed - with this approach the detection process can become more resource-efficient.
The decoding / parsing aspect is an interesting one as well.
Let’s assume that we successfully detected that we’re dealing with a Base64-encoded value - decoding a Base64-encoded string is nothing extraordinary, we just have to use the Base64 utilities offered by the Montoya API.
However, with serializable objects, like JSON, it became a tad more challenging.
One of the main issue here is the fact that we know absolutely nothing about the structure or scheme of the incoming object, which means we can’t use the well-known parsers, like GSON or Jackson in the traditional way.
Serializing them into POJOs is also out of the equation (well, not quite, it could definitely be doable, but still) due to the above-mentioned issue, and besides that, it wouldn’t even get us any further: we have no intention of actually treating them like objects, we just want to extract every key-pair value out of them.
And the answer to this problem is recursion, what else.
We created a JsonElement using the GSON from the given string, and then we recursively traversed the whole object extracting every single key-value pair.
Inserting a payload into a JSON object went down in a pretty much similar fashion, where we took advantage of the fact the keys should be unique in a JSON object.
Data Representation
One of the most crucial and critical question during the design phase was which datatype to use to represent nested encodings. In the beginning, we experimented with list-like datatypes, however, managing the complex parent-child hierarchy within the list quickly became a headache. After some head-scratching, we realized that the answer is relatively simple, and should have been obvious from the beginning: trees, more specifically an n-ary tree. A tree is a nearly perfect fit for our problem: we have an initial value (we could say a root value), which, when decoded, might have a lot of children representing decoded values, which, in turn, might also have some children, and so on:
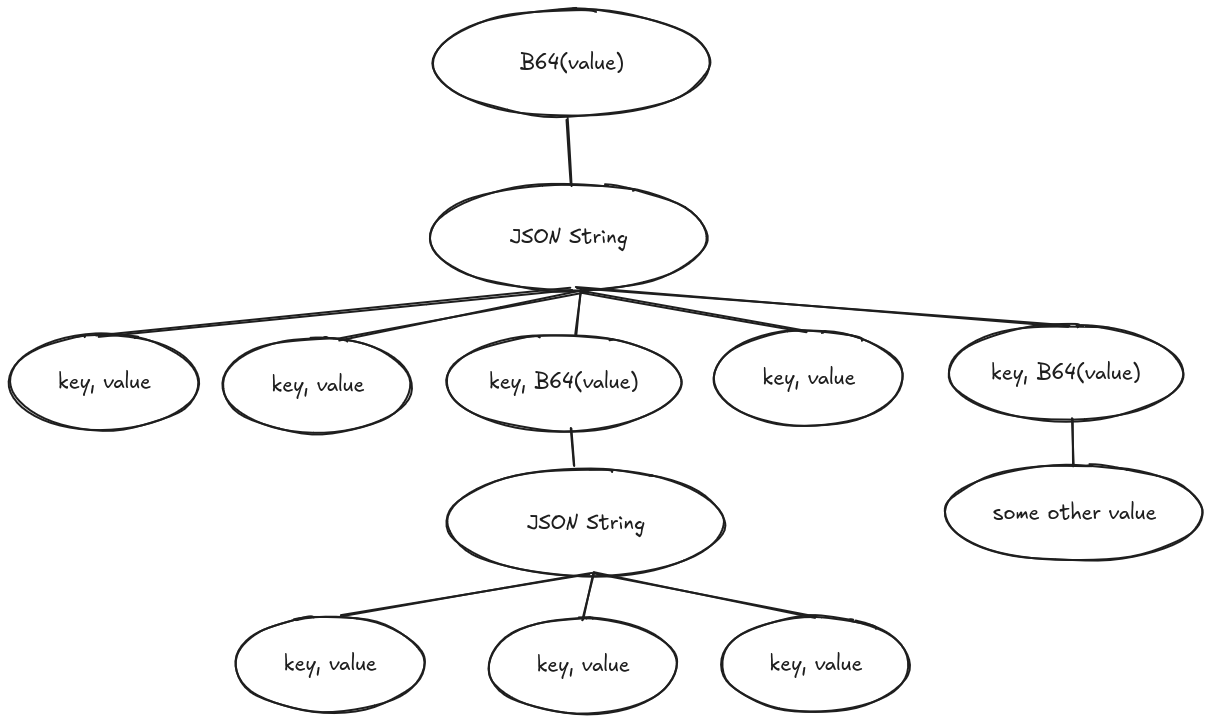
Of course, a Base64-encoded JSON containing another Base64-encoded JSON can rarely be spotted in the wild, we just wanted to demonstrate the chosen datatype and the capability of our extension. Oh, and trees are also cool because they bring more recursion to the table, yay!

Constructing the tree from the root value was relatively straightforward once we figured out the proper datatype, and was done using, yes, you wouldn’t believe it, recursion! Here’s a relatively high-level overview and yet another clumsy visualization of what’s going on under the hood:
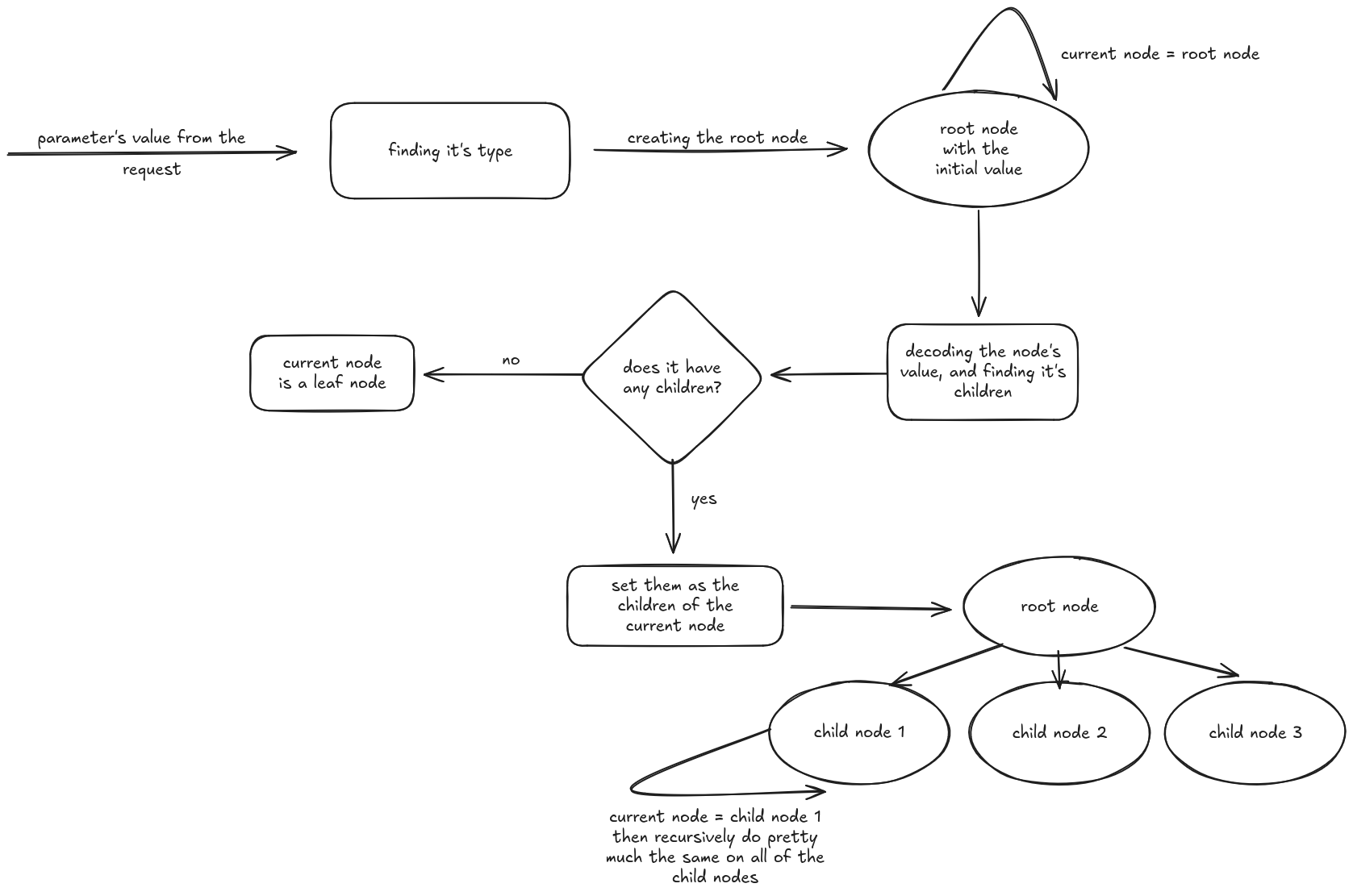
Now that we have our little tree constructed from the parameter’s initial value, let’s see how we can insert a payload into one of the nodes (insertion points), because that’s what this is all about after all. Since each node keeps track of its parent and children, and they also know their encoding algorithm, the process isn’t rocket science: we set the new value for the specified node, which then notifies its parent saying “howdy, I’ve been modified, here’s my old and my brand new value, please update yourself accordingly”, then the parent notifies its own parent, then that parent notifies its own parent, and so on until we reach the root node.
Burp Integration
On Burp’s and on the Montoya API’s level the following happens: we’ve created a new class that implements the AuditInsertionPointProvider interface, which basically delegates custom insertion points to the Active Scanner.
Inside this class, the provideInsertionPoints method has to be implemented.
Some nice example code can be found on the official PortSwigger GitHub, which was really helpful at the beginning.
This method gets the base HTTP request-response pair as a parameter, from which we can extract all of the parameters found inside the HTTP request body - we traverse these parameters and try to construct an instance of the above-mentioned tree.
This method returns a list of AuditInsertionPoint objects, so we’ve created a new class that implements this interface.
The constructor of this class requires 5 parameters: the node (our insertion point), the MontoyaApi instance, the request extracted from the base HttpRequestResponse, the current parameter, and a boolean that indicates whether we want to append or replace the payload generated by Burp.
Inside this class we set the insertion point’s base value and its name, and we also have to override the buildHttpRequestWithPayload method - this is the method where we create the new request with the payload given by Burp, this is where we update our tree, and this newly crafted request will be sent during the Active Scan phase.
Now this is cool and all, but you might be wondering: how do we decide which nodes we consider as an insertion point? This leads us to another dilemma we’ve faced while developing this extension.
User Interface
In the beginning, we simply planned to create a traditional insertion point provider extension, which would only delegate those nodes as insertion points to the active scanner which have no children - essentially the leaf nodes, which are plain string values. However, this approach introduced some shortcomings. For instance, it would create a lot of overhead, since we might be sending out requests for insertion points that are totally uninteresting to us, or even sending out duplicates if Burp recognized those insertion points as well. We quickly realized that some finer control over the extension’s behaviour is much desired, and to achieve this control we opted to create a GUI.
GUI elements for Burp can be created using the Montoya API and the Java library called Swing.
In the meantime, we thought it’d be also good to have a Repeater-like functionality where we can select a single node, rewrite its value, and send the new HTTP request without worrying about the different encodings and conversions and such.
For this reason, we needed two HTTP editors: one for the request and one for the response, and luckily the Montoya API provides us with these elements out-of-the-box.
When we send our specified request to the extension using the context menu (an example can be found here), in the background the extension quickly constructs the tree from the request’s parameters, which is then shown in a tree-like view.
For this functionality, we used a Swing element called JTabbedPane, where each parameter gets its own tab at the bottom of the panel.
The following video demonstrates the usage:
However, with the introduction of the GUI our traditional insertion point provider class has lost its relevance (the tree is already constructed when we send the request to the extension), but we still need to delegate our user-selected insertion points to the Active Scanner. For this reason, we’ve created a parameterized insertion point provider class, which works like the following:
- The user selects the desired nodes in the GUI and clicks on the Active Scan button.
- When the button’s action listener is fired, the user-selected nodes are retrieved from the JTree and are placed in a list.
- Then, we register a new instance of the parameterized Insertion Point Provider class, which requires 4 constructor parameters: the API instance, the list of user-selected nodes, the parameter, and a boolean based on the state of the replace-append toggle button.
- Inside the parameterized IPP class, the
provideInsertionPointsmethod does nothing magical: it traverses the list of the user-selected nodes and creates a new custom insertion point instance based on each selected node.
If someone would like to use the extension in the traditional way, i.e. without the GUI and only the insertion point provider functionality, we’ve left the original AuditInsertionPointProvider class in the project, one just has to uncomment and comment the relevant parts in the Main class.
Summary and Future Work
The easily customizable nature of our extension should also be highlighted: while currently, the extension supports 3 basic encodings, adding a new one is a matter of implementing HandleEncoding in a new class. If someone decides to implement a brand new encoding type, they don’t have to worry about low-level parts, like recursive methods and constructing the tree - that job is already done and dusted. This is in line with Silent Signal’s other published tools like Piper or Duncan: instead of trying to solve every problem imaginable, we provide a framework where experts can focus on the specifics of their target, without thinking about the nuts and bolts required for integration. We also hope that the public release will encourage the sharing of encoder implementations, so all can benefit from the work done for individual targets.
We believe we’ve wrapped up the story of our Burp extension, thank you for joining us, and any contribution to our extension is more than welcome! 😎
Check it out on GitHub: https://github.com/silentsignal/BurpNestedEncoder
The header image was taken by Iza Gawrych
如有侵权请联系:admin#unsafe.sh