
2025-1-28 16:37:16 Author: securityboulevard.com(查看原文) 阅读量:1 收藏

Tokens are the fundamental building blocks that power AI language models, serving as the currency of AI interactions. However, managing these tokens effectively requires a deep understanding of how they work, how they interact with context windows, and how they impact both the performance and cost of AI applications.
Think of tokens as the vocabulary units that AI models use to process and generate text. Just as we break down language into words and phrases, AI models break down text into tokens. These can range from single characters to common words or phrases. However, tokens aren't just about text processing – they're intricately connected to how AI models understand context, maintain conversation history, and generate responses.


This comprehensive guide will walk you through everything you need to know about AI tokens, from basic concepts to advanced optimization strategies. We'll explore how tokens work within context windows, examine practical implementations in code generation, and discover methods for cost optimization. Whether you're building an AI coding assistant, implementing chat interfaces, or developing enterprise AI solutions, understanding these concepts is crucial for creating efficient and cost-effective AI applications.
Our journey will take us through several key areas:
- The fundamental nature of tokens and how different AI models handle them
- The crucial role of context windows in managing token usage
- Practical strategies for optimizing token consumption
- Real-world implementations, including a detailed look at AI coding assistants
- Advanced techniques for managing costs while maintaining performance
By understanding these interconnected concepts, you'll be better equipped to make informed decisions about AI implementation and optimization in your projects.
Token Counts Across Major AI Models
Different AI models use different tokenization approaches:
OpenAI GPT Models
- GPT-o1: 200K context window
- GPT-4o: 128K context window
- GPT-4: 8K/32K context window options
- GPT-3.5 Turbo: 16K context window
- Pricing: $0.01-0.03 per 1K tokens (varies by model)
Anthropic Claude
- Claude 3 Opus: 200K context window
- Claude 3 Sonnet: 200K context window
- Claude 3 Haiku: 200K context window
- Pricing: $0.015-0.03 per 1K tokens (varies by model)
Google Gemini
- Gemini 1.5 Flash: 1M context window
- Gemini 1.5 Pro: 2M context window
- Pricing: $0.00025-0.001 per 1K tokens (varies by model)
Mistral
- Mistral Large 24.11: 128K context window
- Mistral Small 24.09: 32K context window
- Pricing: $0.0002-0.001 per 1K tokens (varies by model)
DeepSeek
- DeepSeek-Chat: 64k context window
- DeepSeek-Reasoner: 64k context window
- Pricing: $0.014-0.14 per 1M tokens (varies by model)
Understanding Context Windows
The context window is one of the most crucial concepts in working with AI language models, yet it's often misunderstood. Think of the context window as the AI model's working memory – it's the amount of information the model can "see" and consider at any given time. This window is measured in tokens, and its size directly impacts both the model's capabilities and your token usage costs.
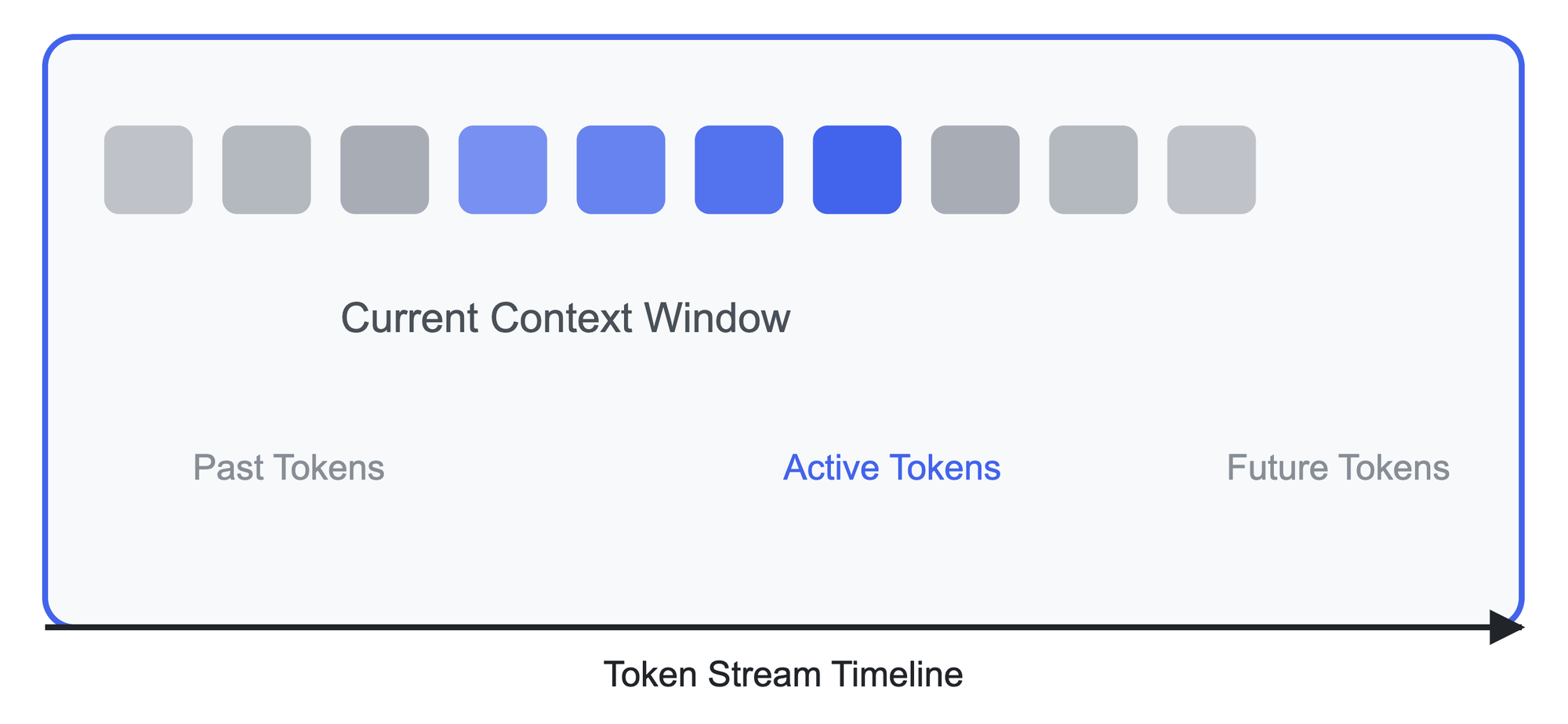
The Mechanics of Context Windows
A context window operates like a sliding glass through which the AI model views information. When you provide input to the model, this window encompasses both your prompt (input) and the space needed for the model's response (output). For instance, if you're using GPT-4 with a 32K context window, this means you have 32,000 tokens to work with in total – divided between your input and the expected output.
To better understand this concept, consider this analogy: Imagine you're reading a long document through a magnifying glass that can only show a certain number of words at once. The size of this magnifying glass is your context window. Just as you can't see words outside the magnifying glass's view, the AI model can't reference information that falls outside its context window.
Advanced Context Window Techniques
Several sophisticated techniques can help you maximize the effectiveness of your context window:
- Sliding Window Approach
The sliding window technique is particularly useful for processing long documents or conversations. Instead of trying to fit everything into one context window, you slide the window along the content, maintaining overlap for continuity:
def process_with_sliding_window(document, window_size=4000, overlap=1000):
tokens = tokenize_document(document)
results = []
for i in range(0, len(tokens), window_size - overlap):
window = tokens[i:i + window_size]
context = process_window(window)
results.append(context)
return merge_results(results)
- Hierarchical Summarization
For very long contexts, implement a hierarchical summarization approach:
class HierarchicalContext:
def manage_long_context(self, full_context):
if count_tokens(full_context) > self.max_tokens:
# Level 1: Create detailed summaries of chunks
chunks = self.split_into_chunks(full_context)
detailed_summaries = [self.summarize(chunk, 'detailed') for chunk in chunks]
# Level 2: Create high-level summary of summaries
if count_tokens(' '.join(detailed_summaries)) > self.max_tokens:
return self.summarize(' '.join(detailed_summaries), 'high_level')
return ' '.join(detailed_summaries)
return full_context
Best Practices for Context Window Usage
When working with context windows, consider these essential practices:
- Content Prioritization
Not all content deserves equal space in your context window. Implement a priority system that considers:- Recency of information
- Relevance to the current task
- Importance of maintaining context continuity
- Dynamic Token Allocation
Allocate your token budget based on the specific requirements of your task:- Reserve more tokens for complex reasoning tasks
- Use fewer tokens for straightforward generation tasks
- Maintain a buffer for unexpected context needs
- Context Refreshing
Regularly refresh your context window to maintain relevance:
def refresh_context(self, current_context):
# Remove outdated information
refreshed_context = remove_outdated_info(current_context)
# Compress remaining context if needed
if count_tokens(refreshed_context) > self.max_tokens * 0.8:
return self.compress_context(refreshed_context)
return refreshed_context
Impact on Token Usage and Costs
Understanding the relationship between context windows and token usage is crucial for cost optimization. Here's how different context window sizes affect token usage and costs:
- Larger windows provide more context but increase token usage and costs
- Smaller windows are more cost-effective but may require more API calls
- Finding the optimal window size depends on your specific use case
Optimizing Token Usage
For Code Generation
Optimizing token usage for code generation requires a careful balance between providing sufficient context and maintaining efficiency. When working with AI models for code generation, the approach should focus on three key areas: prompt engineering, request structuring, and response management.
Effective prompt engineering begins with clarity and precision. Rather than providing lengthy explanations, developers should focus on crafting prompts that clearly define the desired outcome while minimizing token usage. This includes:
- Specifying the exact programming language and version requirements
- Defining the scope and functionality in clear, concise terms
- Including only relevant technical constraints and dependencies
Here's an example of an efficient request structure:
# Efficient request structure that minimizes tokens while maximizing clarity
{
"task": "Create login function",
"requirements": ["JWT", "password hashing"],
"language": "Python"
}
Response handling is equally crucial for optimal token usage. Modern applications should implement streaming responses for larger code generations, which allows for progressive rendering and better user experience while managing token consumption. Additionally, implementing a robust caching system for commonly requested code patterns can significantly reduce token usage over time.
Best Practices for AI Code Generation
When implementing an AI coding assistant, consider these best practices:
- Context Relevance
Always prioritize the most relevant code context. This might include:- Direct dependencies of the code being generated
- Similar implementations in the codebase
- Related configuration and utility functions
- Token Efficiency
Implement efficient token usage strategies:- Use code embeddings to quickly identify relevant sections
- Maintain a cache of commonly used code patterns
- Implement intelligent context pruning for large codebases
- Quality Assurance
Ensure generated code maintains high quality:- Validate against project-specific style guides
- Check compatibility with existing code
- Verify security best practices are followed
This implementation demonstrates how to build an AI coding assistant that balances token efficiency with code quality, providing developers with helpful and contextually aware code generation capabilities.
For Internal Applications
When developing internal applications that leverage AI capabilities, document processing and conversation management become central concerns for token optimization. The approach to handling these aspects requires careful consideration of both technical implementation and practical usage patterns.
Document processing in AI-powered internal applications requires sophisticated chunking strategies. Rather than processing entire documents at once, which can quickly consume token quotas, developers should implement intelligent chunking mechanisms that break documents into meaningful segments while maintaining context. This can be achieved through:
- Semantic chunking that preserves the logical flow of information
- Overlapping windows that maintain context between chunks
- Embedding-based retrieval systems for efficient information access
Consider this example of efficient conversation management:
def manage_context(conversation_history):
# Implement intelligent context retention
return truncate_to_token_limit(
filter_relevant_messages(conversation_history),
max_tokens=4000
)
For AI Agents
AI agents present unique challenges in token optimization due to their need to maintain context over extended interactions while remaining responsive and cost-effective. The key to successful token optimization in AI agents lies in sophisticated context management and efficient tool integration.
Context management for AI agents requires a hierarchical approach to memory and context retention. This involves implementing multiple layers of memory:
- Short-term memory for immediate context
- Medium-term memory for relevant recent interactions
- Long-term memory stored in vector databases for historical context
Here's an implementation example that demonstrates context compression:
class AIAgent:
def compress_context(self):
# Implement intelligent context summarization
return generate_summary(
self.conversation_history,
max_tokens=500
)
Best Practices for Cost Optimization
Cost optimization in AI applications requires a comprehensive approach that combines technical implementation with strategic decision-making. The foundation of effective cost optimization begins with accurate token counting and usage monitoring.
Implementing precise token counting mechanisms is essential for managing costs effectively:
from transformers import GPT2Tokenizer
def count_tokens(text):
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
return len(tokenizer.encode(text))
Beyond basic token counting, organizations should implement tiered processing strategies that match computational resources with task requirements. This involves creating a hierarchy of models and processing approaches:
- Using lightweight models for initial text processing and classification
- Reserving more powerful (and expensive) models for complex tasks
- Implementing sophisticated caching mechanisms to avoid redundant processing
Batch processing can significantly reduce costs by optimizing token usage across multiple requests:
def batch_process(items, batch_size=10):
return [
process_batch(items[i:i+batch_size])
for i in range(0, len(items), batch_size)
]
The final piece of cost optimization involves implementing robust monitoring and analytics systems. Organizations should:
- Track token usage patterns across different types of requests
- Analyze cost-per-request metrics to identify optimization opportunities
- Implement dynamic usage quotas based on business value and ROI
Advanced Token Optimization Techniques
1. Dynamic Model Selection
def select_model(task_complexity, input_length):
if task_complexity == 'low' and input_length < 1000:
return 'gpt-3.5-turbo'
return 'gpt-4'
2. Context Window Management
def manage_context_window(history, new_message):
total_tokens = count_tokens(history + new_message)
if total_tokens > MAX_TOKENS:
return truncate_and_summarize(history)
return history + new_message
3. Hybrid Approaches
- Combine embedding searches with direct queries
- Use cached responses for common queries
- Implement progressive enhancement
Conclusion: Mastering Token Usage for Optimal AI Implementation
Understanding and optimizing token usage is more than just a technical requirement – it's a fundamental skill for anyone working with AI language models. Throughout this guide, we've explored how tokens form the foundation of AI interactions and how their effective management can dramatically impact both performance and costs.
The relationship between tokens and context windows proves particularly crucial. As we've seen in our detailed exploration, the context window acts as the AI's working memory, determining how much information it can process at once. This understanding becomes especially valuable when implementing practical applications like AI coding assistants, where managing context effectively can mean the difference between generating precise, contextually aware code and producing disconnected, less useful output.
Understanding Token Fundamentals:
- Tokens serve as the basic units of AI processing, breaking down text into manageable pieces
- Different models handle tokens differently, with varying costs and context window sizes
- Token optimization requires balancing context preservation with cost efficiency
Context Window Management:
- Context windows determine the scope of what AI models can "see" and process
- Effective context window management requires strategic approaches to information organization
- Sliding windows and hierarchical summarization provide powerful tools for handling long contexts
Practical Applications:
- AI coding assistants demonstrate how token management translates into real-world applications
- Strategic context prioritization ensures optimal use of available tokens
- Streaming implementations help manage large-scale generations efficiently
Cost Optimization Strategies:
- Token usage directly impacts costs, making optimization crucial for scalability
- Implementing tiered processing helps balance cost with performance
- Monitoring and analytics provide insights for continuous optimization
Looking ahead, AI continues to evolve, with models becoming more sophisticated and context windows growing larger. However, the fundamental principles of token management and optimization remain crucial. By understanding these concepts and implementing the strategies we've discussed, you can build more efficient, cost-effective AI applications that make the most of available resources.
Remember that effective token management is an ongoing process. Regular monitoring, optimization, and adjustment of your token usage strategies will help ensure your AI applications remain both powerful and cost-effective as your needs evolve and grow.
Whether you're implementing an AI coding assistant, building enterprise applications, or developing new AI-powered tools, the principles and strategies outlined in this guide provide a foundation for successful token management. By applying these concepts thoughtfully and systematically, you can create AI applications that not only perform well but do so efficiently and economically.
*** This is a Security Bloggers Network syndicated blog from Deepak Gupta | AI & Cybersecurity Innovation Leader | Founder's Journey from Code to Scale authored by Deepak Gupta - Tech Entrepreneur, Cybersecurity Author. Read the original post at: https://guptadeepak.com/complete-guide-to-ai-tokens-understanding-optimization-and-cost-management/
如有侵权请联系:admin#unsafe.sh