2020-08-09 09:00:00 Author: arthurchiao.github.io(查看原文) 阅读量:422 收藏
Published at 2020-08-09 | Last Update 2020-08-09
Note: this post also provides a Chinese version, but may update less timely as this one.
- Abstract
- 1 Introduction
- 2 Implementation: Netfilter hooks
- 3 Implementation: Netfilter conntrack
- 3.1 Data structures and functions
- 3.2
struct nf_conntrack_tuple {}: Tuple - 3.3
struct nf_conntrack_l4proto {}: methods trackable protocols need to implement - 3.4
struct nf_conntrack_tuple_hash {}: conntrack entry - 3.5
struct nf_conn {}: connection - 3.6
nf_conntrack_in(): enter conntrack - 3.7
init_conntrack(): create new conntrack entry - 3.8
nf_conntrack_confirm(): confirm a new connection
- 4 Implementation: Netfilter NAT
- 5. Summary
- References
Abstract
This post talks about connection tracking (conntrack, CT), and the design and implementation inside Linux kernel.
Code analysis bases on 4.19. For illustration purposes, only the core
logics are preserved in all pasted code. We have attched the source file names
in kernel source tree for each code piece, refer to them if you need it.
Note that I’m not a kernel developer, so there may be some mistakes in this post. Glad if anyone corrects me.
Connection tracking is the basis of many network services and applications. For example, Kubernetes Service, ServiceMesh sidecar, software layer 4 load balancer (L4LB) LVS/IPVS, Docker network, OpenvSwitch (OVS), OpenStack security group (host firewall), etc, all rely on the functionalities of connection tracking.
1.1 Concepts
Connection tracking (conntrack)
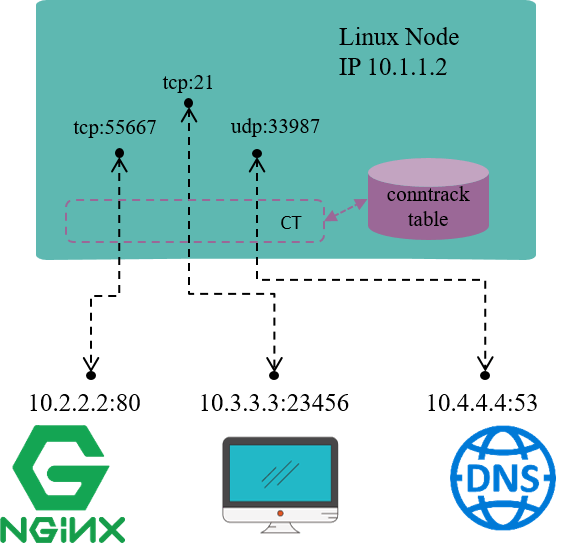
Fig 1.1 Connection tracking example on a Linux node
Connection tracking, as the name illustrates itself, tracks (and maintains) connections’ states.
For example, in Fig 1.1, the Linux node has an IP address 10.1.1.2,
we could see 3 connections on this node:
10.1.1.2:55667 <-> 10.2.2.2.:80: locally originated connection for accessing external HTTP/TCP service10.3.3.3:23456 <-> 10.3.3.2.:21: externally originated connection for accessing FTP/TCP service in this node10.1.1.2:33987 <-> 10.4.4.4.:53: locally originated connection for accessing external DNS/UDP service
Conntrack module’s responsibility is to discover and record these connections and their statuses, which include:
- Extract
tuplefrom packets, distinguishflowand the relatedconnection. - Maintain a “database” (
conntrack table) for all connections, store information such as connection’s created time, packets sent, bytes sent, etc. - Garbage collecting (GC) stale connection info
- Serve for upper layer functionalities, e.g. as the foundation of NAT module
But note that, the term “connection” in “connection tracking” is different from the “connection” concept that we mean in TCP/IP stack. Put it simply,
- In TCP/IP stack, “connection” is a layer 4 (transport layer) concept.
- TCP is a connection-oriented protocol, all packets need to be acknowledged (ACK), and there is retransmission mechanism.
- UDP is a connectionless protocol, acknowledgement (ACK) is not required, no retransmission either.
- In connection tracking, a
tupleuniquely defines aflow, and a flow represents aconnection.- We will see later that UDP, or even ICMP (layer 3 protocol) have connection entries.
- But not all protocols will be connection tracked.
When refering to the term “connection”, we mean the latter one in most cases, namely, the “connection” in “connection tracking” context.
Network address translation (NAT)
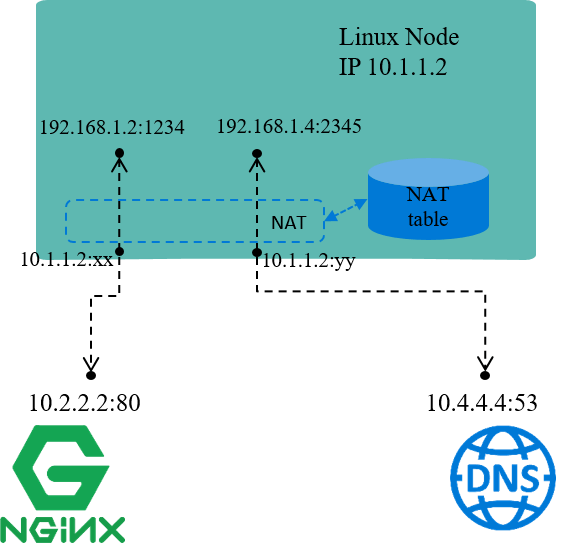
Fig 1.2 NAT for node local IP addresses
As the name illustrates, NAT translates (packets’) network addresses (IP + Port).
For example, in Fig 1.2, assume node IP 10.1.1.2 is reachable from other
nodes, while IP addresses within network 192.168.1.0/24 is not reachable, this
indicates that:
- packets with source IP within network range
192.168.1.0/24could be sent out, as egress routing only relies on destination IP. - but, the reply packets (with destination IP falls into
192.168.1.0/24) could not come back, as192.168.1.0/24is not routable within hosts.
So, one of a solution for this scenario is:
- when packets with source IP belongs to
192.168.1.0/24are going to be sent , the node replaces these source IP (and/or port) with its own IP10.1.1.2then send out. - when reply packets arrive, node does the reverse conversion, then forwards to the original sender.
This is the underlying working mechanism of NAT.
The default network mode of Docker, bridge network mode, uses NAT in the same
way as above [4]. Within the node, each Docker container allocates a
node local IP address. This address enables communications between containers
within the node, but when containers communicate with services outside the node,
the traffic will be NAT-ed.
NAT may replace the source ports as well. It’s easy to understand: each IP address can use the full port range (e.g. 1~65535). So assume we have two connections:
- 192.168.1.2:3333 <–> NAT <–> 10.2.2.2:80
- 192.168.1.3:3333 <–> NAT <–> 10.2.2.2:80
if NAT only replaces source IP addresses to node IP, the above two distinct connections after NAT will be:
- 10.1.1.2:3333 <–> 10.2.2.2:80
- 10.1.1.2:3333 <–> 10.2.2.2:80
which mixed into a same connection that could not be distinguished and the reverse translation will fail. So NAT also replaces source ports if collision happens.
NAT can be further categorized as:
- SNAT: do translation on source address
- DNAT: do translation on destination address
- Full NAT:do translation on both source and destination addresses
Our above examples falls into SNAT case.
NAT relies on the results of connection tracking, and, NAT the most important users of connection tracking.
Layer 4 load balancing (L4 LB)
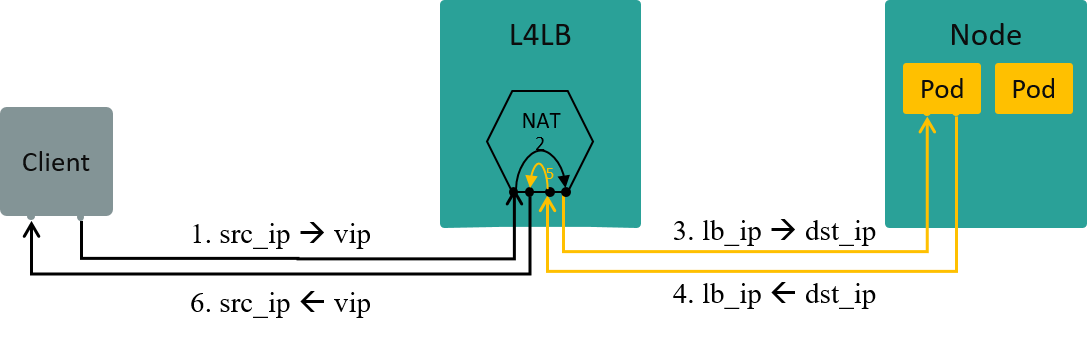
Fig 1.3 L4LB: traffic path in NAT mode [3]
Let’s enlarge our discussing scope slightly, to the topic of layer 4 load balancing (L4LB) under NAT mode.
L4 LB distributes traffic acorrding to packets’ L3+L4 info, e.g. src/dst ip, src/dst port, proto.
VIP (Virtual IP) is an mechanism/design to implement L4LB:
- Multiple backend nodes with distinct Real IPs registered to the same virtual IP (VIP)
- Traffic from clients will first arrive at VIP, then be load balanced to specific backend IPs
If L4LB uses NAT mode (between VIP and Real IPs), then L4LB will perform full NAT between client-server traffic, the data flow depicted as Fig 1.3.
1.2 Thoery
With the above concepts in mind, let’s reasons about the underlying theory of connction tracking.
To track the states of all connections on a node, we need to,
- Hook (or filter) every packet passes through this node, and analyze the packet.
- Setup a “database” for recoding the status of those connections (conntrack table).
- Update connection status timely to database based on the extracted information from hooked packets.
For example,
- When hooked a TCP
SYNCpacket, we could confirm that a new connection attempt is under the way, so we need to create a new conntrack entry to record this connection. - When got a packet that belongs to an existing connection, we need to update the connctrack entry statistics, e.g. bytes sent, packets sent, timeout value, e.g.
- When no packets has matches a conntrack entry for more than 30 minutes, we need to consider deleting this entry from connection database.
Besides the above functional requirements, performance requirements also need to concern, as conntrack module needs filter and analyze every single packet. Performance considerations are fairly important, but it is beyond the scope of this post. We will refer to performance issues again when walking through the kernel conntrack implementation later.
Further, it’s better to have some management tools for faciliating the using of conntrack module.
1.3 Design: Netfilter
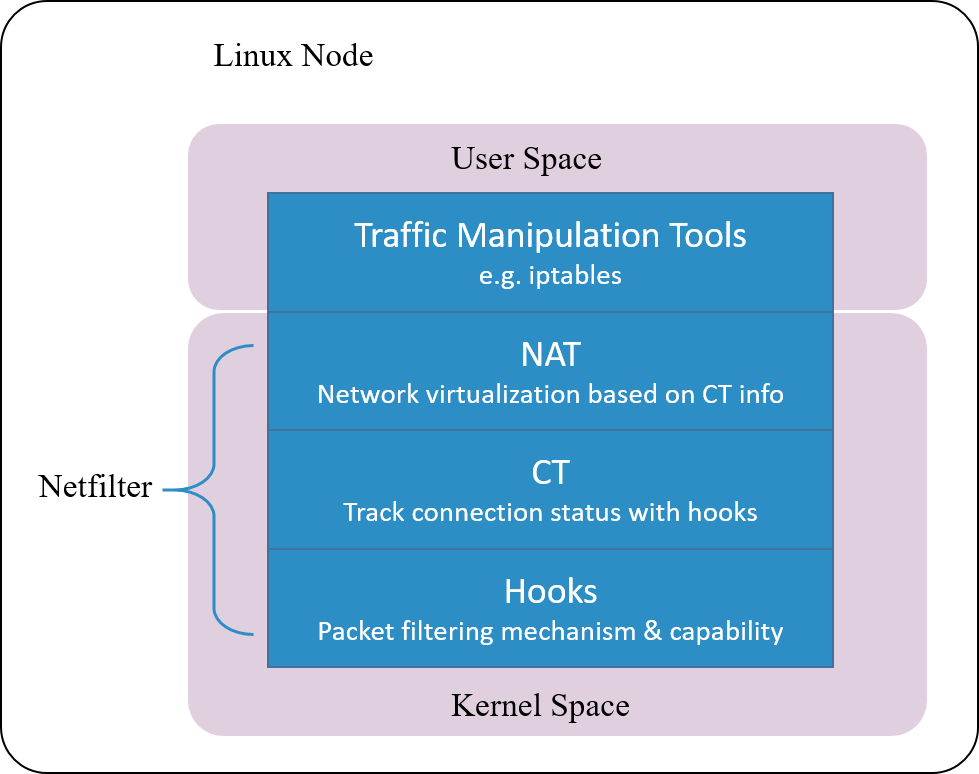
Fig 1.4 Netfilter architecture inside Linux kernel
Linux’s connction tracking is implemented as a module in Netfilter framework.
Netfilter is a packet manipulating and filtering framework inside Linux kernel. It provides several hooking positions inside kernel, so packet hooking, filtering and many other processings could be done.
Put it more clearly, hook is a mechanism that places several checking points in the travesal path of packets. When a packet arrives a hooking point, it first get checked, the checking result could be one of:
- let it go: no modifications to the packet, push it back to the original travesal path and let it go
- modify it: e.g. replace network address (NAT), then push back to the original travesal path and let it go
- drop it: e.g. by security firewall rules configured at this checking (hooking) point
Note that conntrack module only extracts connection information and maintains its database, it does not modify or drop a packet. Modification and dropping are done by other modules, e.g. NAT.
Netfilter is one of the earliest networking frameworks inside Linux kernel, it
initially got developed in 1998, and merged into 2.4.x kernel mainline in
2000.
After more than 20 years evolvement, it gets so complicated that could result to degraded performance in certain scenarios, we will talk a little more about this later.
1.4 Design: further considerations
From our discussion in section 1.2, we know that connection tracking concept is independent from Netfilter, the latter is only one of the implementations for connection tracking.
In other words, as long as we have the hooking capability - the ability to hook every single packet that goes through the system - we could implement our own connection trakcing mechanism.
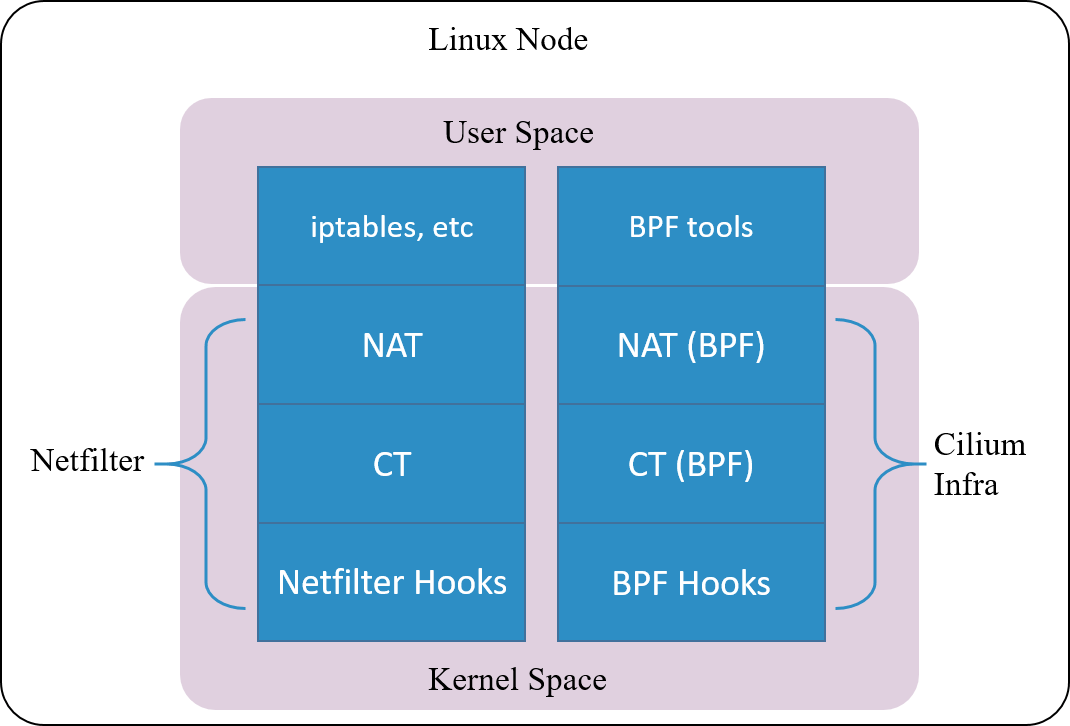
Fig 1.5. Cilium's conntrack and NAT architectrue
Cilium, a cloud native networking solution for Kubernetes, implements such a conntrack and NAT mechanism. The underlyings of the impelentation:
- Hook packets based on BPF hook points (BPF’s equivalent part of the Netfilter hooks)
- Implement completely new conntrack and NAT modules based on BPF hooks (relies on kernel
4.19+to be fully functionaly on itself)
So, you could even remove the entire Netfilter module , and Cilium will still work properly for Kubernetes functionalities such as ClusterIP, NodePort, ExternalIPs and LoadBalancer [2].
As this connction tracking mechanism is independent from Netfilter, its
conntrack and NAT entries are not stored in system’s (namely, Netfilter’s)
conntrack table and NAT table. So frequently used network tools
conntrack/netstats/ss/lsof could not list them, you must use Cilium’s commands, e.g:
$ cilium bpf nat list
$ cilium bpf ct list global
Also, the configurations are also independent, you need to specify Cilium’s
configuration parameters, such as command line argument --bpf-ct-tcp-max.
We say that conntrack module is independent from NAT module, but for performance considerations, their code may have certain couplings. For example, when performing GC for conntrack table, it will efficiently remove related entries in NAT table, rather than maintaining a separate GC loop for NAT table.
This ends our discussion on the theory of connection tracking, and in the following, we will dig into the kernel implementation.
Netfilter consists of several modules:
- conntrack: kernel module
- NAT: kernel module
- iptables: userspace tools
2.1 Netfilter framework
The 5 hooking points
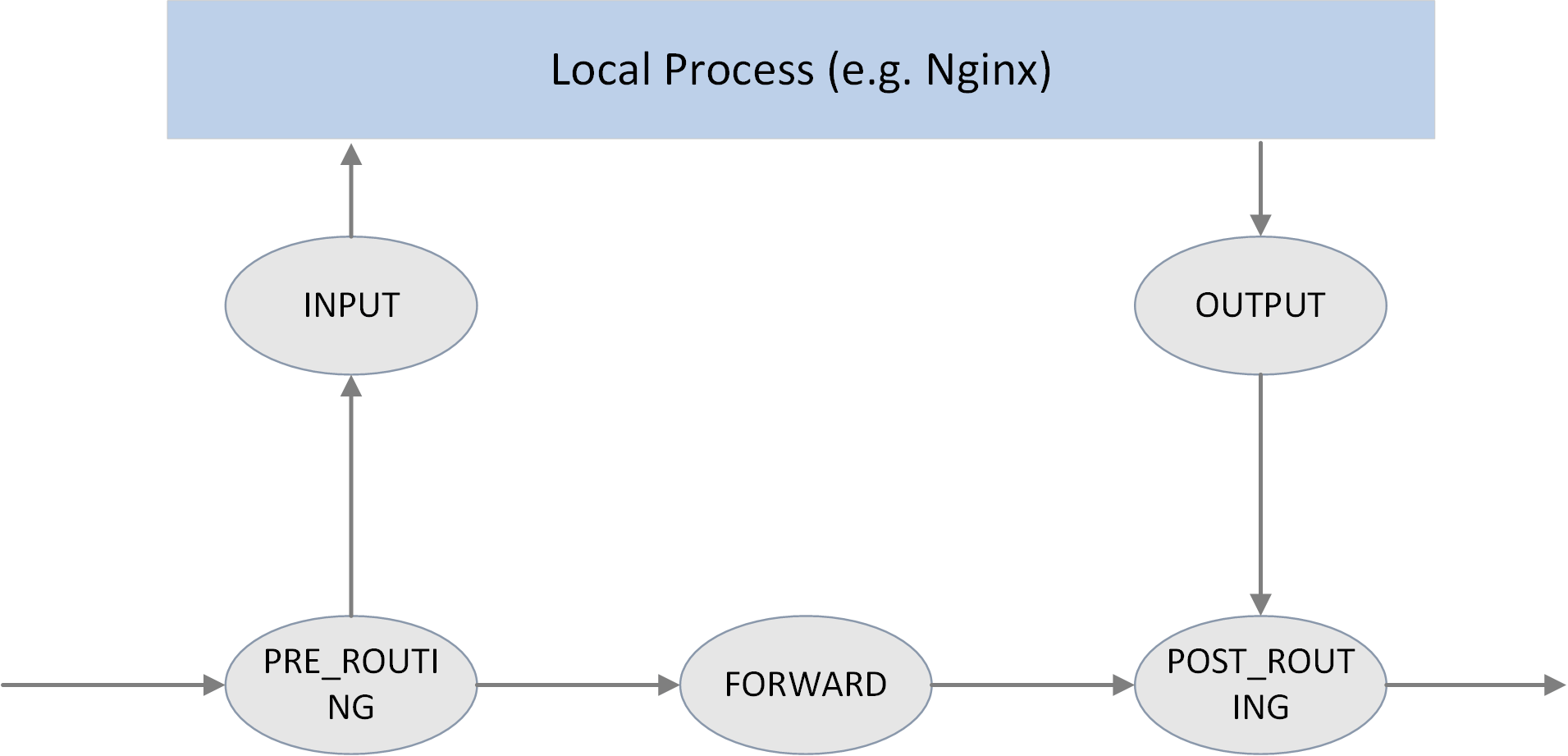
Fig 2.1 The 5 hook points in netfilter framework
As shown in the above picture, Netfilter provides 5 hooking points in the packet travesing path inside Linux kernel:
// include/uapi/linux/netfilter_ipv4.h
#define NF_IP_PRE_ROUTING 0 /* After promisc drops, checksum checks. */
#define NF_IP_LOCAL_IN 1 /* If the packet is destined for this box. */
#define NF_IP_FORWARD 2 /* If the packet is destined for another interface. */
#define NF_IP_LOCAL_OUT 3 /* Packets coming from a local process. */
#define NF_IP_POST_ROUTING 4 /* Packets about to hit the wire. */
#define NF_IP_NUMHOOKS 5
Users could register callback functions (handlers) at these points. When a packet arrives at the hook point, it will triger the related handlers being called.
There is another definition for these
NF_INET_*variables, ininclude/uapi/linux/netfilter.h. These two definitions are equivalent, from the comments in the code,NF_IP_*are probably used for backward compatibility.enum nf_inet_hooks { NF_INET_PRE_ROUTING, NF_INET_LOCAL_IN, NF_INET_FORWARD, NF_INET_LOCAL_OUT, NF_INET_POST_ROUTING, NF_INET_NUMHOOKS };
Hook handler return values
hook handlers return a verdict result after checking against a given packet, and this verdict will guide next processings on this packet. Possible verdict results include:
// include/uapi/linux/netfilter.h
#define NF_DROP 0 // the packet has been dropped this packet in handler
#define NF_ACCEPT 1 // the packet is no dropped, continue following processing
#define NF_STOLEN 2 // the packet has been consumed by the handler, no further processing is needed
#define NF_QUEUE 3 // the packet should be pushed into queue
#define NF_REPEAT 4 // current handler should be called again against the packet
Hook handler priorities
Multiple handlers could be registered to the same hooking point.
When register a handler, a priority parameter must be provided. So that when a packet arrives at this point, the system could call these handlers in order with their priorities.
2.2 Filtering rules management
iptables is the userspace tool for configuring Netfilter hooking capabilities.
To faciliate management, it splits rules into several tables by functionalities:
- raw
- filter
- nat
- mangle
This is not the focus of this post, more information on this, refer to A Deep Dive into iptables and Netfilter Architecture.
conntrack module traces the connection status of trackable protocols [1]. That is, connection tracking targets at specific protocols, not all protocols. We will see later what protocols it supports.
3.1 Data structures and functions
Key data structures:
struct nf_conntrack_tuple {}: defines atuple.struct nf_conntrack_man {}: the manipulatable part of a tuplestruct nf_conntrack_man_proto {}: the protocol specific part in tuple’s manipulatable part
struct nf_conntrack_l4proto {}: a collection of methods a trackable protocol needs to implement (and other fields).struct nf_conntrack_tuple_hash {}: defines a conntrack entry (value) stored in hash table (conntrack table), hash key is auint32integer computed from tuple info.struct nf_conn {}: defines a flow.
Key functions:
hash_conntrack_raw(): calculates a 32bit hash key from tuple info.nf_conntrack_in():core of the conntrack module, the entrypoint of connection tracking.resolve_normal_ct() -> init_conntrack() -> l4proto->new(): creates a new conntrack entry.nf_conntrack_confirm(): confirms the new connection that previously created vianf_conntrack_in().
3.2 struct nf_conntrack_tuple {}: Tuple
Tuple is one of the most important concepts in connection tracking.
A tuple uniquely defines a unidirectional flow, this is clearly explained in kernel code comments:
//include/net/netfilter/nf_conntrack_tuple.h
A
tupleis a structure containing the information to uniquely identify a connection. ie. if two packets have the same tuple, they are in the same connection; if not, they are not.
Data structure definitions
To facilite NAT module’s implementation, kernel splits the tuple structure into “manipulatable” and “non-manipulatable” parts.
In the following code,
_manis short formanipulatable, which is a bad naming/abbreviating from today’s point of view.
// include/net/netfilter/nf_conntrack_tuple.h
// ude/uapi/linux/netfilter.h
union nf_inet_addr {
__u32 all[4];
__be32 ip;
__be32 ip6[4];
struct in_addr in;
struct in6_addr in6;
/* manipulatable part of the tuple */ / };
struct nf_conntrack_man { /
union nf_inet_addr u3; -->--/
union nf_conntrack_man_proto u; -->--\
\ // include/uapi/linux/netfilter/nf_conntrack_tuple_common.h
u_int16_t l3num; // L3 proto \ // protocol specific part
}; union nf_conntrack_man_proto {
__be16 all;/* Add other protocols here. */
struct { __be16 port; } tcp;
struct { __be16 port; } udp;
struct { __be16 id; } icmp;
struct { __be16 port; } dccp;
struct { __be16 port; } sctp;
struct { __be16 key; } gre;
};
struct nf_conntrack_tuple { /* This contains the information to distinguish a connection. */
struct nf_conntrack_man src; // source address info,manipulatable part
struct {
union nf_inet_addr u3;
union {
__be16 all; // Add other protocols here
struct { __be16 port; } tcp;
struct { __be16 port; } udp;
struct { u_int8_t type, code; } icmp;
struct { __be16 port; } dccp;
struct { __be16 port; } sctp;
struct { __be16 key; } gre;
} u;
u_int8_t protonum; // The protocol
u_int8_t dir; // The direction (for tuplehash)
} dst; // destination address info
};
There are only 2 fields (src and dst) inside struct nf_conntrack_tuple {}, each stores
source and destination address information.
But src and dst are themselves also structs, storing protocol specific data.
Take IPv4 UDP as example, information of the 5-tuple stores in the following
fields:
dst.protonum: protocol type (IPPROTO_UDP)src.u3.ip: source IP addressdst.u3.ip: destination IP addresssrc.u.udp.port: source UDP port numberdst.u.udp.port: destination UDP port number
Connection-trackable protocols
From the above code, we could see that only 6 protocols support connection tracking currently: TCP, UDP, ICMP, DCCP, SCTP, GRE.
Pay attention to the ICMP protocol. People may think that connction tracking is
done by hashing over L3+L4 headers of packets, while ICMP is a L3 protocol, so it
could not be conntrack-ed. But actually it could be, from the above code, we see
that the type and code fields in ICMP header are used for defining a
tuple and performing subsequent hashing.
3.3 struct nf_conntrack_l4proto {}: methods trackable protocols need to implement
Protocols that support connection tracking need to implement the methods defined
in struct nf_conntrack_l4proto {}, for example pkt_to_tuple(), which
extracts tuple information from given packet’s L3/L4 header.
// include/net/netfilter/nf_conntrack_l4proto.h
struct nf_conntrack_l4proto {
u_int16_t l3proto; /* L3 Protocol number. */
u_int8_t l4proto; /* L4 Protocol number. */
// extract tuple info from given packet (skb)
bool (*pkt_to_tuple)(struct sk_buff *skb, ... struct nf_conntrack_tuple *tuple);
// returns verdict for packet
int (*packet)(struct nf_conn *ct, const struct sk_buff *skb ...);
// create a new conntrack, return TRUE if succeeds.
// if returns TRUE, packet() method will be called against this skb later
bool (*new)(struct nf_conn *ct, const struct sk_buff *skb, unsigned int dataoff);
// determin if this packet could be conntrack-ed.
// if could, packet() method will be called against this skb later
int (*error)(struct net *net, struct nf_conn *tmpl, struct sk_buff *skb, ...);
...
};
3.4 struct nf_conntrack_tuple_hash {}: conntrack entry
conntrack modules stores active connections in a hash table:
- key: 32bit value calculated from tuple info
- value: conntrack entry (
struct nf_conntrack_tuple_hash {})
Method hash_conntrack_raw() calculates a 32bit hash key from tuple info:
// net/netfilter/nf_conntrack_core.c
static u32 hash_conntrack_raw(struct nf_conntrack_tuple *tuple, struct net *net)
{
get_random_once(&nf_conntrack_hash_rnd, sizeof(nf_conntrack_hash_rnd));
/* The direction must be ignored, so we hash everything up to the
* destination ports (which is a multiple of 4) and treat the last three bytes manually. */
u32 seed = nf_conntrack_hash_rnd ^ net_hash_mix(net);
unsigned int n = (sizeof(tuple->src) + sizeof(tuple->dst.u3)) / sizeof(u32);
return jhash2((u32 *)tuple, n, seed ^ ((tuple->dst.u.all << 16) | tuple->dst.protonum));
}
Pay attention to the calculating logic, and how source and destination address fields are used for the final hash value.
Conntrack entry is defined as struct nf_conntrack_tuple_hash {}:
// include/net/netfilter/nf_conntrack_tuple.h
// Connections have two entries in the hash table: one for each way
struct nf_conntrack_tuple_hash {
struct hlist_nulls_node hnnode; // point to the related connection `struct nf_conn`,
// list for fixing hash collisions
struct nf_conntrack_tuple tuple;
};
3.5 struct nf_conn {}: connection
Each flow in Netfilter is called a connection, even for those connectionless
protocols (e.g. UDP). A connection is defined as struct nf_conn {}, with
important fields as follows:
// include/net/netfilter/nf_conntrack.h
// include/linux/skbuff.h
------> struct nf_conntrack {
| atomic_t use; // refcount?
| };
struct nf_conn { |
struct nf_conntrack ct_general;
struct nf_conntrack_tuple_hash tuplehash[IP_CT_DIR_MAX]; // conntrack entry, array for ingress/egress flows
unsigned long status; // connection status, see below for detailed status list
u32 timeout; // timer for connection status
possible_net_t ct_net;
struct hlist_node nat_bysource;
// per conntrack: protocol private data
struct nf_conn *master; union nf_conntrack_proto {
/* insert conntrack proto private data here */
u_int32_t mark; /* mark skb */ struct nf_ct_dccp dccp;
u_int32_t secmark; struct ip_ct_sctp sctp;
struct ip_ct_tcp tcp;
union nf_conntrack_proto proto; ---------->-----> struct nf_ct_gre gre;
}; unsigned int tmpl_padto;
};
All possible status of a connection, enum ip_conntrack_status:
// include/uapi/linux/netfilter/nf_conntrack_common.h
enum ip_conntrack_status {
IPS_EXPECTED = (1 << IPS_EXPECTED_BIT),
IPS_SEEN_REPLY = (1 << IPS_SEEN_REPLY_BIT),
IPS_ASSURED = (1 << IPS_ASSURED_BIT),
IPS_CONFIRMED = (1 << IPS_CONFIRMED_BIT),
IPS_SRC_NAT = (1 << IPS_SRC_NAT_BIT),
IPS_DST_NAT = (1 << IPS_DST_NAT_BIT),
IPS_NAT_MASK = (IPS_DST_NAT | IPS_SRC_NAT),
IPS_SEQ_ADJUST = (1 << IPS_SEQ_ADJUST_BIT),
IPS_SRC_NAT_DONE = (1 << IPS_SRC_NAT_DONE_BIT),
IPS_DST_NAT_DONE = (1 << IPS_DST_NAT_DONE_BIT),
IPS_NAT_DONE_MASK = (IPS_DST_NAT_DONE | IPS_SRC_NAT_DONE),
IPS_DYING = (1 << IPS_DYING_BIT),
IPS_FIXED_TIMEOUT = (1 << IPS_FIXED_TIMEOUT_BIT),
IPS_TEMPLATE = (1 << IPS_TEMPLATE_BIT),
IPS_UNTRACKED = (1 << IPS_UNTRACKED_BIT),
IPS_HELPER = (1 << IPS_HELPER_BIT),
IPS_OFFLOAD = (1 << IPS_OFFLOAD_BIT),
IPS_UNCHANGEABLE_MASK = (IPS_NAT_DONE_MASK | IPS_NAT_MASK |
IPS_EXPECTED | IPS_CONFIRMED | IPS_DYING |
IPS_SEQ_ADJUST | IPS_TEMPLATE | IPS_OFFLOAD),
};
3.6 nf_conntrack_in(): enter conntrack
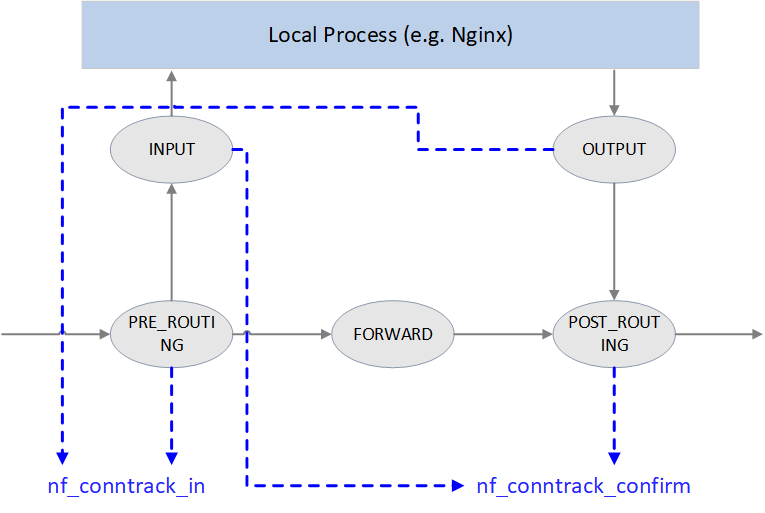
Fig 3.1 Conntrack points in Netfilter framework
As illustrated in Fig 3.1, Netfilter performs connection tracking at 4 hooking positions:
-
PRE_ROUTINGandLOCAL_OUTStart connection tracking by calling
nf_conntrack_in(), normally this will create a new conntrack entry, then insert it into unconfirmed list.Why starting at these two places? Because both of them are the earliest points that the initial packet of a new connection arrives Netfilter framework.
PRE_ROUTING: earliest point that the first packet of a new externally-initiated connection arrives.LOCAL_OUT: earliest point that the first packet of a new locally-initiated connection arrives.
-
POST_ROUTING和LOCAL_INCall
nf_conntrack_confirm(), move the newly created (in previousnf_conntrack_in()) connection in unconfirmed list to confirmed list.Again, why these two hooking points? It is because if the first packet of a new connection is not dropped during internal processing, it should arrive these places and these are the last place before it leaving Netfilter framework:
- For packet of externally-initiated connection,
LOCAL_INis the last hooking point before it is sent to upper layer application (e.g. a Nginx process). - For packet of locally-initiated connection,
POST_ROUTINGis the last hooking point before this packet is sent out on the wire.
- For packet of externally-initiated connection,
We could see how these handlers get registered into the netfilter framwork:
// net/netfilter/nf_conntrack_proto.c
/* Connection tracking may drop packets, but never alters them, so make it the first hook. */
static const struct nf_hook_ops ipv4_conntrack_ops[] = {
{
.hook = ipv4_conntrack_in, // enter conntrack by calling nf_conntrack_in()
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_PRE_ROUTING, // PRE_ROUTING hook point
.priority = NF_IP_PRI_CONNTRACK,
},
{
.hook = ipv4_conntrack_local, // enter conntrack by calling nf_conntrack_in()
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT, // LOCAL_OUT hook point
.priority = NF_IP_PRI_CONNTRACK,
},
{
.hook = ipv4_confirm, // call nf_conntrack_confirm()
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING, // POST_ROUTING hook point
.priority = NF_IP_PRI_CONNTRACK_CONFIRM,
},
{
.hook = ipv4_confirm, // call nf_conntrack_confirm()
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN, // LOCAL_IN hook point
.priority = NF_IP_PRI_CONNTRACK_CONFIRM,
},
};
Method nf_conntrack_in() is the core of connection tracking module.
// net/netfilter/nf_conntrack_core.c
unsigned int
nf_conntrack_in(struct net *net, u_int8_t pf, unsigned int hooknum, struct sk_buff *skb)
{
struct nf_conn *tmpl = nf_ct_get(skb, &ctinfo); // get related conntrack_info and conntrack entry
if (tmpl || ctinfo == IP_CT_UNTRACKED) { // if conntrack exists, or if is un-trackable protocols
if ((tmpl && !nf_ct_is_template(tmpl)) || ctinfo == IP_CT_UNTRACKED) {
NF_CT_STAT_INC_ATOMIC(net, ignore); // no need to conntrack, inc ignore stats
return NF_ACCEPT; // return NF_ACCEPT, continue normal processing
}
skb->_nfct = 0; // need to conntrack, reset refcount of this packet,
} // prepare for further processing
struct nf_conntrack_l4proto
*l4proto = __nf_ct_l4proto_find(); // extract protocol-specific L4 info
if (l4proto->error(tmpl, skb, pf) <= 0) { // skb validation
NF_CT_STAT_INC_ATOMIC(net, error);
NF_CT_STAT_INC_ATOMIC(net, invalid);
goto out;
}
repeat:
resolve_normal_ct(net, tmpl, skb, ... l4proto); // start conntrack, extract tuple:
// create new conntrack or update existing one
l4proto->packet(ct, skb, ctinfo); // protocol-specific processing, e.g. update UDP timeout
if (ctinfo == IP_CT_ESTABLISHED_REPLY && !test_and_set_bit(IPS_SEEN_REPLY_BIT, &ct->status))
nf_conntrack_event_cache(IPCT_REPLY, ct);
out:
if (tmpl)
nf_ct_put(tmpl); // un-reference tmpl
}
Rough processing steps:
- Get conntrack info of this skb.
- Determine if conntrack is needed for this skb. If not needed, update ignore
counter, return
NF_ACCEPT; if needed, init (reset) this skb’s refcount. - Extract L4 information from skb, init protocol-specific
struct nf_conntrack_l4proto {}variable, which contains the protocol’s callback methods for performing connection tracking. - Call protocol-specific
error()method for data validation, e.g. checksum. - Start conntrack by calling
resolve_normal_ct()method, it will create new tuple, new conntrack entry, or update status of existing conntrack entry. - Call
packet()method for some protocol-specific processing. E.g. for UDP, ifIPS_SEEN_REPLYis set in status, it will updatetimeoutvalue. timeout varies according to different protocols, the smaller it is, the more it will be stronger on anti-DDos attacks (DDos attacks a system by exausting all the system’s connections).
3.7 init_conntrack(): create new conntrack entry
If connection does not exist yet (the first packet of a flow),
resolve_normal_ct() method will call init_conntrack(), and the latter will
further call protocol-specific method new() to create a new conntrack entry.
// include/net/netfilter/nf_conntrack_core.c
// Allocate a new conntrack
static noinline struct nf_conntrack_tuple_hash *
init_conntrack(struct net *net, struct nf_conn *tmpl,
const struct nf_conntrack_tuple *tuple,
const struct nf_conntrack_l4proto *l4proto,
struct sk_buff *skb, unsigned int dataoff, u32 hash)
{
struct nf_conn *ct;
ct = __nf_conntrack_alloc(net, zone, tuple, &repl_tuple, GFP_ATOMIC, hash);
l4proto->new(ct, skb, dataoff); // protocol-specific method for creating a conntrack entry
local_bh_disable(); // disable softirq
if (net->ct.expect_count) {
exp = nf_ct_find_expectation(net, zone, tuple);
if (exp) {
__set_bit(IPS_EXPECTED_BIT, &ct->status);
/* exp->master safe, refcnt bumped in nf_ct_find_expectation */
ct->master = exp->master;
ct->mark = exp->master->mark;
ct->secmark = exp->master->secmark;
NF_CT_STAT_INC(net, expect_new);
}
}
/* Now it is inserted into the unconfirmed list, bump refcount */
nf_conntrack_get(&ct->ct_general);
nf_ct_add_to_unconfirmed_list(ct);
local_bh_enable(); // re-enable softirq
if (exp) {
if (exp->expectfn)
exp->expectfn(ct, exp);
nf_ct_expect_put(exp);
}
return &ct->tuplehash[IP_CT_DIR_ORIGINAL];
}
Implementations of protocol-specific new() method, see
net/netfilter/nf_conntrack_proto_*.c.
If current packet will influence the status of subsequent packets,
init_conntrack() will set the master field in struct nf_conn.
Connection oriented protocols (e.g. TCP) uses this feature.
3.8 nf_conntrack_confirm(): confirm a new connection
The new conntrack entry that nf_conntrack_in() creates will be inserted into
an unconfirmed connection list.
If this packet is not dropped during intermediate processing, then when it
arrives POST_ROUTING hook, it will be further processed by
nf_conntrack_confirm() method. We have analyzed why it is further processed
here instead of other hooking points.
After nf_conntrack_confirm() is done, status of the connection will turn to
IPS_CONFIRMED, and the conntrack will be move from unconfirmed list to
confirmed list.
Why bother to split the conntrack creating process into two stages (
newandconfirm)?It is because after the initial packet passes
nf_conntrack_in(), but before it arrivesnf_conntrack_confirm(), it is possible that the packet get dropped by the kernel somewhere in the middle. This may result in large half-connected conntrack entries, and it would be a big concern in terms of both performance and security. Spliting into two steps will significantly accelerate the GC process.
// include/net/netfilter/nf_conntrack_core.h
/* Confirm a connection: returns NF_DROP if packet must be dropped. */
static inline int nf_conntrack_confirm(struct sk_buff *skb)
{
struct nf_conn *ct = (struct nf_conn *)skb_nfct(skb);
int ret = NF_ACCEPT;
if (ct) {
if (!nf_ct_is_confirmed(ct))
ret = __nf_conntrack_confirm(skb);
if (likely(ret == NF_ACCEPT))
nf_ct_deliver_cached_events(ct);
}
return ret;
}
confirm logic, error handling code omitted:
// net/netfilter/nf_conntrack_core.c
/* Confirm a connection given skb; places it in hash table */
int
__nf_conntrack_confirm(struct sk_buff *skb)
{
struct nf_conn *ct;
ct = nf_ct_get(skb, &ctinfo);
local_bh_disable(); // disable softirq
hash = *(unsigned long *)&ct->tuplehash[IP_CT_DIR_REPLY].hnnode.pprev;
reply_hash = hash_conntrack(net, &ct->tuplehash[IP_CT_DIR_REPLY].tuple);
ct->timeout += nfct_time_stamp; // update timer, will be GC-ed after timeout
atomic_inc(&ct->ct_general.use); // update conntrack entry refcount?
ct->status |= IPS_CONFIRMED; // set status as `confirmed`
__nf_conntrack_hash_insert(ct, hash, reply_hash); // insert into conntrack table
local_bh_enable(); // re-enable softirq
nf_conntrack_event_cache(master_ct(ct) ? IPCT_RELATED : IPCT_NEW, ct);
return NF_ACCEPT;
}
One thing needs to be noted here: we could see softirq (soft interrupts) is disabled/re-enabled at many places; besides, there are lots of lock/unlock operations (omitted in the above code). This may be the main reasons of degraded performance in certain scenarios (e.g. massive concurrent short-time connections)?
NAT is a function module built upon conntrack module, it relies on connection tracking’s results to work properly.
Again, not all protocols supports NAT.
4.1 Data structures and functions
Data structures:
Protocols that support NAT needs to implement the methods defined in:
struct nf_nat_l3proto {}struct nf_nat_l4proto {}
Functions:
nf_nat_inet_fn(): core of NAT module, will be called at all hooking points exceptNF_INET_FORWARD.
4.2 NAT module init
// net/netfilter/nf_nat_core.c
static struct nf_nat_hook nat_hook = {
.parse_nat_setup = nfnetlink_parse_nat_setup,
.decode_session = __nf_nat_decode_session,
.manip_pkt = nf_nat_manip_pkt,
};
static int __init nf_nat_init(void)
{
nf_nat_bysource = nf_ct_alloc_hashtable(&nf_nat_htable_size, 0);
nf_ct_helper_expectfn_register(&follow_master_nat);
RCU_INIT_POINTER(nf_nat_hook, &nat_hook);
}
MODULE_LICENSE("GPL");
module_init(nf_nat_init);
4.3 struct nf_nat_l3proto {}: protocol specific methods
// include/net/netfilter/nf_nat_l3proto.h
struct nf_nat_l3proto {
u8 l3proto; // e.g. AF_INET
u32 (*secure_port )(const struct nf_conntrack_tuple *t, __be16);
bool (*manip_pkt )(struct sk_buff *skb, ...);
void (*csum_update )(struct sk_buff *skb, ...);
void (*csum_recalc )(struct sk_buff *skb, u8 proto, ...);
void (*decode_session )(struct sk_buff *skb, ...);
int (*nlattr_to_range)(struct nlattr *tb[], struct nf_nat_range2 *range);
};
4.4 struct nf_nat_l4proto {}: protocol specific methods
manip is the abbraviation of manipulate in the code:
// include/net/netfilter/nf_nat_l4proto.h
struct nf_nat_l4proto {
u8 l4proto; // L4 proto id, e.g. IPPROTO_UDP, IPPROTO_TCP
// Modify L3/L4 header according to the given tuple and NAT type (SNAT/DNAT)
bool (*manip_pkt)(struct sk_buff *skb, *l3proto, *tuple, maniptype);
// Create a unique tuple
// e.g. for UDP, will generate a 16bit dst_port with src_ip, dst_ip, src_port and a rand
void (*unique_tuple)(*l3proto, tuple, struct nf_nat_range2 *range, maniptype, struct nf_conn *ct);
// If the address range is exhausted the NAT modules will begin to drop packets.
int (*nlattr_to_range)(struct nlattr *tb[], struct nf_nat_range2 *range);
};
Implementations of these methods, see net/netfilter/nf_nat_proto_*.c. For
example, the TCP’s implementation:
// net/netfilter/nf_nat_proto_tcp.c
const struct nf_nat_l4proto nf_nat_l4proto_tcp = {
.l4proto = IPPROTO_TCP,
.manip_pkt = tcp_manip_pkt,
.in_range = nf_nat_l4proto_in_range,
.unique_tuple = tcp_unique_tuple,
.nlattr_to_range = nf_nat_l4proto_nlattr_to_range,
};
4.5 nf_nat_inet_fn(): enter NAT
nf_nat_inet_fn() will be called in following hooking points:
NF_INET_PRE_ROUTINGNF_INET_POST_ROUTINGNF_INET_LOCAL_OUTNF_INET_LOCAL_IN
namely, all Netfilter hooking points except NF_INET_FORWARD.
Priorities at these hooking points: Conntrack > NAT > Packet Filtering.
conntrack has a higher priority than NAT, since NAT relies on the results of connection tracking.
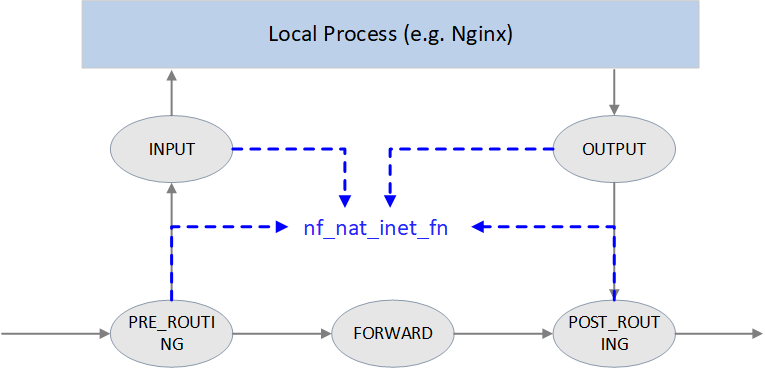
Fig. NAT
unsigned int
nf_nat_inet_fn(void *priv, struct sk_buff *skb, const struct nf_hook_state *state)
{
ct = nf_ct_get(skb, &ctinfo);
if (!ct) // exit NAT if conntrack not exist. This is why we say NAT relies on conntrack's results
return NF_ACCEPT;
nat = nfct_nat(ct);
switch (ctinfo) {
case IP_CT_RELATED:
case IP_CT_RELATED_REPLY: /* Only ICMPs can be IP_CT_IS_REPLY. Fallthrough */
case IP_CT_NEW: /* Seen it before? This can happen for loopback, retrans, or local packets. */
if (!nf_nat_initialized(ct, maniptype)) {
struct nf_hook_entries *e = rcu_dereference(lpriv->entries); // obtain all NAT rules
if (!e)
goto null_bind;
for (i = 0; i < e->num_hook_entries; i++) { // execute NAT rules in order
if (e->hooks[i].hook(e->hooks[i].priv, skb, state) != NF_ACCEPT )
return ret; // return if any rule returns non ACCEPT verdict
if (nf_nat_initialized(ct, maniptype))
goto do_nat;
}
null_bind:
nf_nat_alloc_null_binding(ct, state->hook);
} else { // Already setup manip
if (nf_nat_oif_changed(state->hook, ctinfo, nat, state->out))
goto oif_changed;
}
break;
default: /* ESTABLISHED */
if (nf_nat_oif_changed(state->hook, ctinfo, nat, state->out))
goto oif_changed;
}
do_nat:
return nf_nat_packet(ct, ctinfo, state->hook, skb);
oif_changed:
nf_ct_kill_acct(ct, ctinfo, skb);
return NF_DROP;
}
It first queries conntrack info for this packet, if conntrack info not exists, it means this connection could not be tracked, then we could never perform NAT for it. So just exit NAT in this case.
If conntrack info exists, and the connection is in
IP_CT_RELATED or IP_CT_RELATED_REPLY or
IP_CT_NEW states, then get all NAT rules.
If found, execute nf_nat_packet() method, it will further call
protocol-specific manip_pkt method to modify the packet. If failed, the packet
will be dropped.
Masquerade
NAT module often configured in this fashion: change IP1 to IP2 if matching XXX。
There is also another fashion for SNAT, called masquerade: change IP1 to dev1's IP if
matching XXX.
Masquerade differentiates itself from SNAT in that when device’s IP address changes, the rules still valid. It could be seen as dynamic SNAT (dynamically adapting to the source IP changes in SNAT rules).
The drawback of masquerade is that it has degraded performance compared with SNAT, and this is easy to understand.
4.6 nf_nat_packet(): executing NAT
// net/netfilter/nf_nat_core.c
/* Do packet manipulations according to nf_nat_setup_info. */
unsigned int nf_nat_packet(struct nf_conn *ct, enum ip_conntrack_info ctinfo,
unsigned int hooknum, struct sk_buff *skb)
{
enum nf_nat_manip_type mtype = HOOK2MANIP(hooknum);
enum ip_conntrack_dir dir = CTINFO2DIR(ctinfo);
unsigned int verdict = NF_ACCEPT;
statusbit = (mtype == NF_NAT_MANIP_SRC? IPS_SRC_NAT : IPS_DST_NAT)
if (dir == IP_CT_DIR_REPLY) // Invert if this is reply dir
statusbit ^= IPS_NAT_MASK;
if (ct->status & statusbit) // Non-atomic: these bits don't change. */
verdict = nf_nat_manip_pkt(skb, ct, mtype, dir);
return verdict;
}
static unsigned int nf_nat_manip_pkt(struct sk_buff *skb, struct nf_conn *ct,
enum nf_nat_manip_type mtype, enum ip_conntrack_dir dir)
{
struct nf_conntrack_tuple target;
/* We are aiming to look like inverse of other direction. */
nf_ct_invert_tuplepr(&target, &ct->tuplehash[!dir].tuple);
l3proto = __nf_nat_l3proto_find(target.src.l3num);
l4proto = __nf_nat_l4proto_find(target.src.l3num, target.dst.protonum);
if (!l3proto->manip_pkt(skb, 0, l4proto, &target, mtype)) // 协议相关处理
return NF_DROP;
return NF_ACCEPT;
}
Connection tracking (conntrack) is a fairly fundamental and important network module, but it goes into normal developer or system maintainer’s eyes only when they are stucked in some specific network troubles.
For example, in highly concurrent connection conditions, L4LB node will receive large amounts of short-lived requestions/connections, which may breakout the conntrack table. Phenomenons in this case:
- Clients connect to L4LB failed, the failures may be random, but may also be bulky.
- Client retries may succeed, but may also failed again and again.
- Capturing traffic at L4LB nodes, could see that L4LB nodes received SYNC (take TCP as example) packets, but no ACK is replied, in other words, the packets get siliently dropped.
The reasons here maybe that conntrack table size is not big enough, or GC interval is too large, or even there are bugs in conntrack GC.
- Netfilter connection tracking and NAT implementation. Proc. Seminar on Network Protocols in Operating Systems, Dept. Commun. and Networking, Aalto Univ. 2013.
- Cilium: Kubernetes without kube-proxy
- L4LB for Kubernetes: Theory and Practice with Cilium+BGP+ECMP
- Docker bridge network mode
- Wikipedia: Netfilter
如有侵权请联系:admin#unsafe.sh