2019-06-11 22:00:32 Author: blog.fox-it.com(查看原文) 阅读量:77 收藏
Applying unsupervised machine learning to find ‘randomly generated domains.
Authors: Ruud van Luijk and Anne Postma
At Fox-IT we perform a variety of research and investigation projects to detect malicious activity to improve the service of our Security Operations Center. One of these areas is applying data science techniques to real world data in real world production environments, such as anomalous SMB sequences, beaconing patterns, and other unexpected patterns. This blog entry will share an application of machine learning to detect random-like patterns, indicating possible malicious activity.
Attackers use domain generation algorithm[1] (DGA) to make a resilient Command and Control[2] (C2) infrastructure. Automatic and large scale malware operations pose a challenge on the C2 infrastructure of malware. If defenders identify key domains of the malware, these can be taken down or sinkholed, weakening the C2. To overcome this challenge, attackers may use a domain generation algorithm.
A DGA is used to dynamically generate a large number of seemingly random domain names and then selecting a small subset of these domains for C2 communication. The generated domains are computed based on a given seed, which can consist of numeric constants, the current date, or even the Twitter trend of the day. Based on this same seed, each infected device will produce the same domain. The rapid change of C2 domains in use allows attackers to create a large network of servers, that is resilient to sinkholing, takedowns, and blacklisting. If you sinkhole one domain, another pops up the next day or the next minute. This technique is commonly used by multiple malware families and actors. For example, Ramnit, Gozi, and Quakbot use generated domains in the malware.
Machine-learning approaches are proven to be effective to detect DGA domains in contrast to static rules. The input of these machine-learning approaches may for example consist of the entropy, frequency of occurrence, top-level domain, number of dictionary words, length of the domain, and n-gram. However, many of these approaches need labelled data. You need to know a lot of ‘good’ domains, and a lot of DGA domains. Good domains can be taken, for example, from the Alexa and Majestic million sets and DGA domains can be generated from known malicious algorithms. While these DGA domains are valid, they are only valid for the remainder of the usage of that specific algorithm. If there is a new type of DGA, chances are your model is not correct anymore and does not detect newly generated domains. Language regions pose a challenge on the ‘good’ domains. Each language has different structures and combinations. Taking the Alexa or Majestic million is a one-size-fits-all approach. Nuances might get lost.
To overcome the challenges of labelled data, unsupervised machine learning might be a solution. These approaches do not need an explicit DGA training set – you only need to know what is normal or expected. A majority of research move to variants of neural networks, which require a lot of computational power to train and predict. With the amount of network data this is not necessarily a deal-breaker if there is ample computing power, but it certainly is a factor to consider.
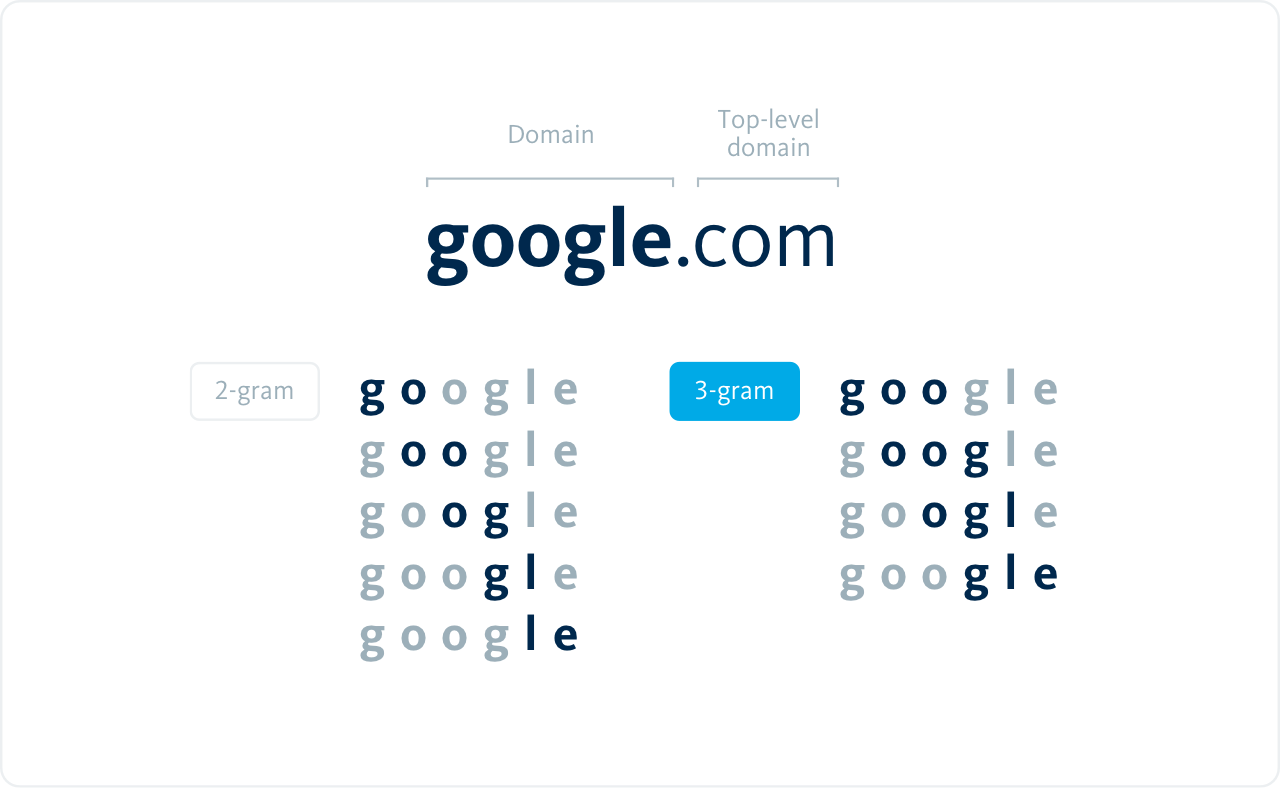
An easier to implement solution is to look solely at the occurrences of n-grams to define what is normal. N-grams are sequences of N consecutive elements such as words or letters, where bi-grams (2-grams) are sequences of two, tri-grams (3-grams) are sequences of three, etc. To illustrate with the domain ‘google.com’:

“This is an intuitive way to dissect language. Because, what are the odds you see a ‘kzp’ in a domain? And what are the odds you see ‘oog’ in a domain?”
We calculate the domain probability by multiplying the probability of each of the tri-grams and normalise by dividing it by the length of the domain. We chose an unconditional probability, meaning we ignore the dependency between n-grams as this speeds up training and calculation times. We also ignored the top level domain (e.g. “.co.uk”, “.org”) as these are common in both normal as in DGA domains and will focus our model to the parts of the domain that is distinctive. If the domain probability is below a predefined threshold, the domain is deviant from the baseline and likely a DGA domain.
To evaluate this technique we trained on roughly 8 million non-unique common names of a network, thereby creating a baseline of what is normal for this network. We evaluated the model by scoring one million non-unique common names and roughly 125.000 DGA domains over multiple algorithms, provided by Johannes Bader[3]. We excluded some domains that are known to use random generated (sub)-domains from both the training- and evaluation set, such as content delivery networks.
Figure below illustrates the log probability distributions of the blue baseline domains, i.e. the domains you would expect to see, and the red DGA domains. Although a clear distinction between the two distributions can be seen there is also a small overlap between the -10 and -7.5 visible. This is because some DGA domains are much alike to regular domains, some baseline domain are random-like, and for some domains our model wasn’t able to correctly distinguish it from DGA domains.

For our detection to be practically useful in large operations, such as Security Operation Centers, we need a very low false positive rate. We also assumed that every baseline has a small contamination ratio. We chose for a ratio of 0.001%. We also use this as the cut-off value between predicting a domain as DGA or not. During hunting this threshold may be increased or completely ignored.
| True DGA | True Normal | |
| Predicted DGA | 94.67% | ~0 |
| Predicted Normal | 6.33% | ~100% |
| Total | 100% | 100% |
If we take the cut-off value at this point we get an accuracy (the percentage correct) of 99.35% and an F1-score of 97.26.
DGA domains are a tactic used by various malware families. Machine learning approaches are proven to be useful in the detection of this tactic, but lack to generalize in a simple and strong solution for production. By relaxing some restrictions on the math and compensating this with a lot of baseline data, a simple and effective solution can be found. This simple and effective solution does not rely on labelled data, is on par with scientific research and has the benefit to take into account the common language of regular domains used in the network.
We demonstrated this solution with hostnames in common names, but it is also applicable for HTTP and DNS. Moreover, a wide range of applications is possible since it detects deviations from the expected. For example random generated file names, deviating hostnames, unexpected sequences of connections, etc.
- This technique is recently added to the MITTRE ATT&CK tactics. https://attack.mitre.org/techniques/T1483/
- For more information about C2, see: https://attack.mitre.org/tactics/TA0011/
- https://github.com/baderj/domain_generation_algorithms
Published
如有侵权请联系:admin#unsafe.sh