[This piece is co-authored by Nuno P. Lopes and John Regehr.]
Alive2 is a formal verification framework for LLVM optimizations. It includes multiple tools, including a plugin for `opt’ to verify whether the optimizations just run are correct or not. We gave an introduction to Alive2 in a previous post.
A few years ago we used an old version of Alive to verify small, automatically generated test cases. These test cases had functions with three instructions which were then piped through different optimizations and their outputs verified with Alive for correctness. This approach found several bugs in the then-current version of LLVM.
But we want more — we want to identify and hopefully help fix all miscompilations that can be triggered in practice. To this end, we created Alive2, which can reason about a wide variety of intraprocedural optimizations including those that work with control flow, memory, vectors, and floating point types. We then started running Alive2 regularly on LLVM’s own unit tests. This has already resulted in 39 bug reports.
Working on the unit tests makes a lot of sense:
- The behaviors being tested are clearly important, or at least interesting, or else the LLVM developers wouldn’t have made them part of the unit test suite in the first place.
- The tests are usually small and only involve one or a few optimizations, making it much easier to fix problems than it is when we observe miscompilations in the field.
In this post we describe the process of running Alive2 on LLVM’s unit tests, and give an overview of the remaining problems we’ve found in LLVM that still need to be fixed.
Running Alive2 on LLVM’s unit tests
LLVM’s unit tests are run by a tool called lit, which makes it easy to interpose on calls to opt, the standalone optimizer for LLVM IR. We simply run a subset of the unit tests like this:
$ ~/llvm/build/bin/llvm-lit -vv -Dopt=$HOME/alive2/scripts/opt-alive.sh ~/llvm/llvm/test/Transforms
Our script, then, loads the Alive2 opt plugin and fails the test case if Alive2 can prove that it was optimized improperly. This script has a list of passes that are not supported by Alive2, so it can avoid false positives (tests that look wrong to Alive2, but are actually correct). We take this issue very seriously, to avoid wasting people’s time. Passes that aren’t currently supported are those that do interprocedural optimizations.
In addition to unsupported passes, Alive2 doesn’t support all of LLVM’s IR, including some function attributes and many intrinsics and library functions. If a test case uses an unsupported feature, Alive2 still tries to analyze it to find miscompilations involving only supported IR features, while conservatively approximating the remaining parts.
Running the above lit command takes around 15 hours of CPU time, or less than 2 hours on an 8-core machine.
Tracking bugs over time
We built a simple dashboard to track the evolution of bugs found by Alive2 in LLVM’s unit tests over time.
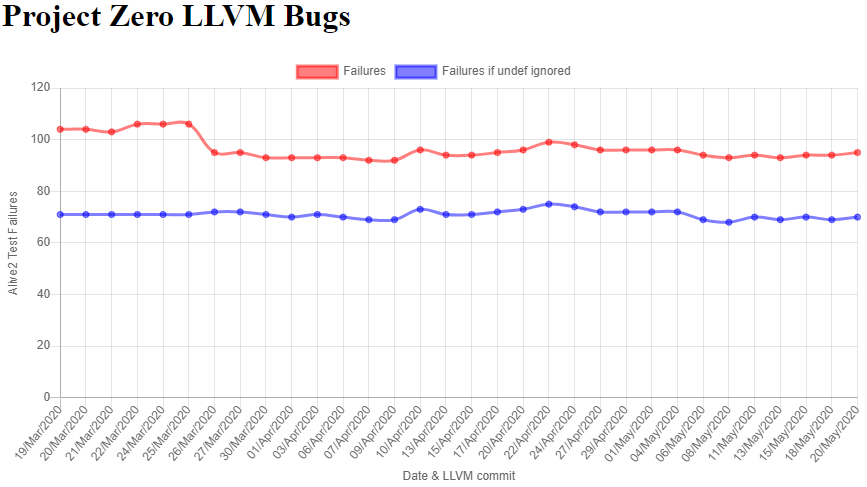
The plot shows two lines: number of failures per day, and number of failures if `undef’ values were to disappear from LLVM. At the time of writing, Alive2 reported a total of 95 bugs in the unit tests, with 25 of those being ok if undef was removed. Since `undef’ values still exist, these optimizations are incorrect. We plot both lines as an incentive to get rid of `undef’ values: over a quarter of the reports would disappear.
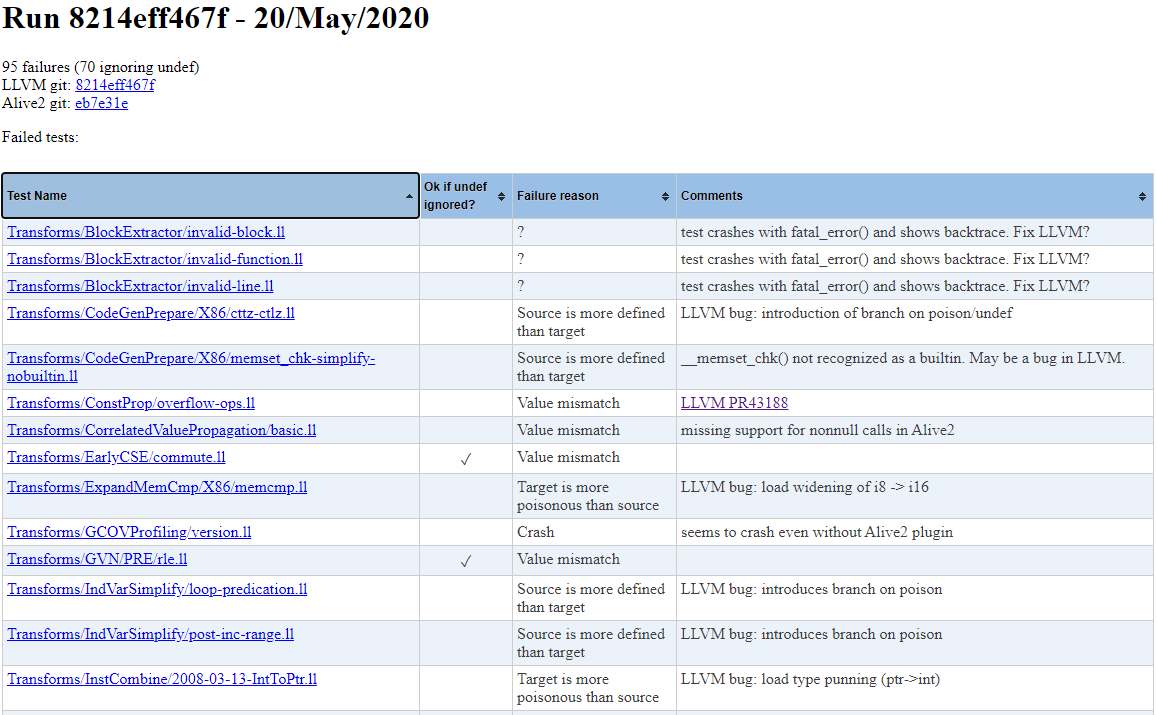
The page has further information for the last five runs, including the reports that were fixed and which are new in each run. Clicking on a run gives the list of all failed tests, as well as a short manually written description of the failure cause.
We use a timeout in Alive2 for the work done by the theorem prover underneath. Unfortunately, some reports are only triggered very close to the timeout and therefore sometimes there is churn, with a test failing only in some runs.
Current issues in LLVM
Many of the bugs we’ve found and reported have been fixed already. Most of these were some Instcombine pattern that was incorrect for some inputs. Other issues are trickier to solve, for example some bugs are hard to fix without performance regressions, as they may need further changes in other optimizations or even in SelectionDAG to recognize a different IR canonicalization. In some cases, there is not yet an agreement on the right semantics for the IR: these can’t be fixed straight away without considering pros and cons of different semantics and getting the community to reach a consensus about them. We now give a few examples of open issues in LLVM.
Introduction of branch on poison/undef
Branching on a poison or undef value is immediate UB, like dividing by zero. Optimizations that hoist branches and/or combine multiple branches can introduce branches on values that were not observed in the original program. This issue is prevalent across multiple optimizations like SimplifyCFG, loop unswitch, simple loop unswitch, and induction variable simplification. A simple example:
if (x) {
if (y) {
S1
}
}
=>
if (x & y) {
S1
}
The original program would not branch on y if x was false. The optimized code, however, always branches on x and y. Therefore, when x=false and y=poison, the source program is well defined, but the optimized program is UB. This is a failure of refinement and the transformation is wrong.
One possible solution is to stop performing these transformations, but in general this is not considered acceptable because it loses performance. A different solution is to add freeze instructions that we introduced in a paper, and that have been supported in LLVM since version 10.0. Freezing a regular value has no effect, and freezing undef or poison results in an arbitrary value being chosen.
A correct version of the wrong optimization above is:
if (x & freeze(y)) {
S1
}
We know where freeze instructions need to be introduced — this is not too difficult. However, adding too many freezes can (and has) led to performance regressions. These are usually not because freeze is inherently expensive, but rather because freezes can inhibit optimizations, particularly those involving loops. Fixing the regressions is a matter of putting in the engineering effort to do things like hoisting freeze out of loops, eliminating unnecessary freezes, and teaching optimizations not to be blocked by freezes. Work is underway, but several parts of the compiler need to be touched and it will take some time.
Introduction of undef uses
Generally speaking, it is not legal to add a new use of an undef value in LLVM. This is a problem in practice because it is easy for compiler developers to forget that almost any value is potentially undef. For example, shl %x, 1 and add %x, %x are not equivalent if %x might be undef. The former always returns an even number, while the latter could also yield an odd number if %x is undef. In other words, different uses of an undef value can resolve to different concrete values. Alive2 reports 25 test cases that are incorrect if we consider some of the variables to be undef, but are correct otherwise.
Some cases are easy to fix. For the example above, we can simply choose to canonicalize the IR to the shift instruction. We could also freeze %x, since all uses of the frozen value will resolve to the same concrete value.
This canonicalization has no obvious alternative solution other than using freeze or removing undef entirely from LLVM:
sext(x < 0 ? 0 : x) => zext(x < 0 ? 0 : x)
If x is undef, the expression x < 0 ? 0 : x may yield a negative number. Therefore, replacing the sign-extension with a zero-extension is not correct. Freezing x or eliminating undef values would both work.
Pointer comparison semantics
LLVM pointers track object provenance. That is, a pointer derived from a malloc() call can only point within the buffer allocated by that call, even if the underlying machine value of the pointer happens to point to another buffer. For example:
int *p = malloc(4); int *q = malloc(4); p[x] = 2; // this implies x = 0; cannot write to q, for example
The reason for this semantics is that it enables cheap, local alias analysis. If provenance tracking didn't exist, alias analysis would often need to do whole program analysis where today it can get away with easy, local reasoning. This is nice; we all love fast compilation times and good object code!
The goal of provenance tracking is to prevent the program from learning the layout of objects in memory. If the program could learn that q is placed right after p in memory for the example above, the program could potentially change their contents without the compiler realizing it. A way the memory layout can leak is through pointer comparison. For example, what should p < q return? If it's a well defined operation, it leaks memory layout information. An alternative is to return a non-deterministic value to prevent layout leaks. There are pros and cons of both semantics for the comparison of pointers of different objects:
| Comparison yields a deterministic value |
Comparison yields a non-deterministic result |
|
| p = obj1 + x; q = obj2 + y; x,y unknown |
Cannot simplify the comparison; depends on the values of x & y |
Can fold p < q to false |
| Equivalence between pointer and integer comparison? |
Yes; can simplify (ptrtoint p) < (ptrtoint q) to p < q |
No |
| Assume all pointers are > null | Yes; can simplify (p <= q) or (p == null) to: (p <= q) |
Maybe (can special case?) |
| inttoptr simplification | Harder; pointer comparisons leak memory layout |
Simpler |
Unfortunately LLVM currently wants the best of both worlds, with different optimizations assuming different semantics, which can lead to miscompilations. We need to settle on one semantics and stick to it throughout the compiler.
Load type punning
In order to respect pointer provenance semantics, LLVM's memory is typed. We need at least to be able to distinguish whether a byte in memory holds an integer/float or a pointer. However, LLVM sometimes violates this rule and loads a pointer with an integer load operation or vice-versa. This implies that any load instruction could potentially do an implicit inttoptr or ptrtoint operation, thus leaking information about the memory layout. This is not good: as we have seen before, it undermines alias analyses.
Introducing type punning instructions is common in LLVM. Many of these cases arise when converting small memcpy operations to load/store instructions. While memcpy copies memory as-is, load/store instructions are typed. Additionally, LLVM currently has no way of expressing C's char or C++'s std::byte. These types are allowed to store any type of data, including pointers and integers.
A suggestion to fix this issue is to introduce a `byte' type in LLVM IR, a sort of union of all LLVM types. This type couldn't be used in arithmetic operations, but only in memory operations and appropriate casts (yielding poison when casting byte to the wrong type). An alternative solution is to accept that load instructions may do implicit casts and fix alias analyses to take this fact into account (likely paying a performance price).
Select to Arithmetic
LLVM canonicalizes select instructions to arithmetic when it can do so. All of these transformations are wrong because select blocks a poison value from its not-chosen input, but arithmetic does not. The most obvious fix, changing the meaning of select so that it no longer blocks poison, is unacceptable because this renders unsound a different class of transformation that LLVM wants to do: canonicalizing simple conditional expressions to select. This kind of tricky semantic balancing act is found again and again in LLVM IR. Appropriate fixes would be to avoid these transformations (which requires strengthening up support for select in backends, and in fact some work in this direction has been done) or else freezing values before performing arithmetic on them.
Other issues
This post is already long, so we list here a few further open issues and a short description:
- FP bitcast semantics. What's the value of (int)(float)x, where x is an integer? Is it always x? The corner case is when x matches one of the NaN bit-patterns. Can the CPU canonicalize the NaN bit-pattern and thus when converting the float back to integer yield a result different than x?
- Load widening. LLVM combines multiple consecutive loads into a single load by widening the loaded type. This is not correct: if any of the loaded values is poison, all of them become poison. A solution is to use loads with vector types, as poison elements in a vector don't contaminate each other.
- inttoptr(ptrtoint(x)) => x. This is not correct, as there can be two valid pointers with the same integer value (beginning of an object and one past the end of another). The solution is to enable this transformation only when a static analysis determines it's safe to do so. Currently, LLVM performs this optimization unconditionally.
- Shufflevector semantics. When the mask is out of bounds, the current semantics are that the resulting element is undef. If shufflevector is used to remove an element from the input vector, then the instruction cannot be removed, as the input might have been poison. The solution is to switch to give poison instead.
Future
Our short-term goal is to get LLVM to a point where Alive2 detects zero miscompilations in the unit test suite. Then we hope that an Alive2 buildbot can continuously monitor commits to help ensure that no new miscompilation bugs are committed to the code base. This is a powerful baseline, but we believe there are additional miscompilation errors lurking in LLVM that will only be exposed by more thorough testing. We will accomplish this by using Alive2 to monitor LLVM while it optimizes real applications and also randomly generated programs.
We thank everyone involved in fixing LLVM bugs as well as discussing semantics and fixing LangRef!