
Botnets are one of the biggest current threats for devices connected to the internet. Their methods to evade security actions are frequently improved. Most of the modern botnets use Domain Generation Algorithms (DGA) to generate and register many different domains for their Command-and-Control (C&C) server with the purpose to defend it from takeovers and blacklisting attempts.
To improve the automated analysis of DGA-based malware, we have developed an analysis system for detection and classification of DGA’s. In this blog post we will discuss and present several techniques of our developed DGA classifier.
The DGA detection can be useful to detect DGA-based malware. With the DGA classification it is also possible to see links between different malware samples of the same family. Such a classification is expressed with a description of the DGA as a regex.
Moreover, our analysis methods are based on the network traffic of single samples and not of a whole system or network, which is a difference to most of the related work.
DGA-based Botnets
A Domain Generation Algorithm (DGA) generates periodically a high number of pseudo-random domains that resolve to a C&C server of a botnet [H. 16]. The main reason of its usage by a botnet owner is that it highly complicates the process of a takeover by authorities (Sinkholing). In a typical infrastructure of a botnet that uses a static domain for the C&C server, authorities could take over the botnet with cooperation of the corresponding domain registrar by changing the settings of the static C&C domain (e.g. changing the DNS records).
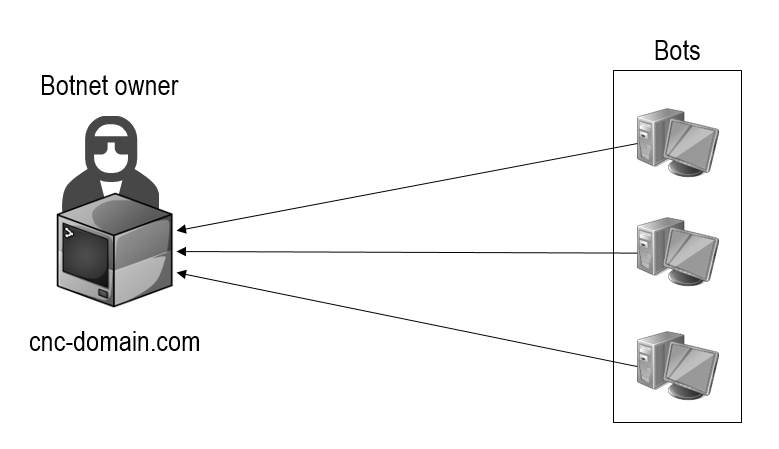
With the usage of a DGA that is generating domains dynamically which resolve to the C&C server there is no effective sinkholing possible anymore. Since the bots use a new generated domain after every period to connect to the C&C server, it would be senseless to take control of a domain that is not used anymore by the bots to build up a connection to the C&C server.
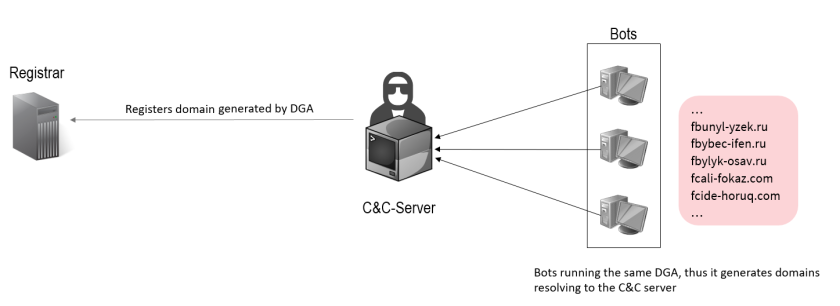
The C&C server and the bots use the same DGA with the same seed, so that they are able to generate the same set of domains. DGA’s use mostly the date as a seed to initialize the algorithm for domain generation. Hence the DGA creates a different set of domains everyday its run. To initialize a connection to the C&C server the bot needs to run first the DGA to generate a domain, that could be possibly also generated on the side of the C&C server, since both are using the same algorithm and seed [R. 13]. After every domain generation, the bot attempts to resolve the generated domain. These steps are repeated until the domain resolution succeeds, so that the bot figures out the current IP address of the corresponding C&C server. Through that DGA domain the bot can set up a connection to the C&C server.
Motivation
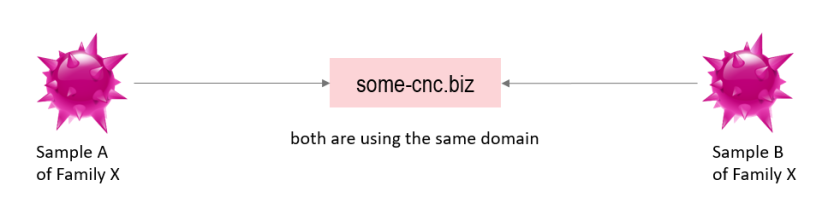
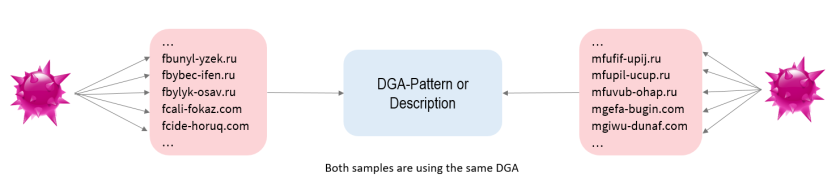
DGA detection can be very helpful to detect malware, because if it is possible to detect the usage of a DGA while analyzing the network traffic of a single sample, then it is very likely that the analyzed sample is malicious, since DGA’s are used commonly by malware but not by benign software. DGA classification is the next step in the analysis after a DGA has been detected. A successful classification returns a proper description of a DGA. With such a unified description, it is possible to group malware using the same DGA. Being able to group malware by correlating characteristics, leads to an improvement to the detection of new malware samples of these families. Therefore, the signatures of recently detected malware samples will be automatically blacklisted. The following figure shows for an non-DGA malware that grouping malware families based on the same domains in their DNS requests traffic will be only possible, if they use all the same and static C&C domain:
If the malware uses a DGA, then the grouping of malware will not be trivial anymore, because generated DGA domains are just used temporarily, thus using those to find links between samples would not be very effective.
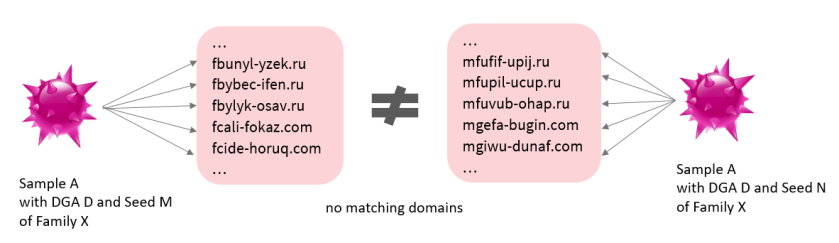
Note also that occurring domains in the network traffic of the recently analyzed malware sample could differ on another day with the same sample analyzed, since many DGA’s use the date as a seed. The solution is to calculate a seed-independent DGA description for every analyzed sample using a DGA. That description can be used then as a bridge between malware samples using the same DGA.
To solve this problem, we have divided it into three smaller tasks. Thus, the DGA classifier is structured into three components. Each component solves a task that contributes to the result of the DGA classification.
In this blog post we concentrate only on approaches for DGA detection and classification that are automatable, since we want to analyze a very high number of samples. Furthermore, we want to avoid as much as possible unnecessary network traffic, therefore we focus only on offline methods.
This approach for DGA detection is based on statistical values calculated over the relevant label attributes of the domains. Since the domains generated by a DGA follow mostly a pattern, it is very useful to calculate the standard deviation of some attribute values [T. 13]. The average value can be also used for some attribute values to measure whether a domain is generated by a DGA or not. Those statistical values are also calculated over a list of domains from the Top 500 Alexa Ranking. These are considered as reference values for non-DGA domains regarding the relevant label attributes.
The domains with multiple levels are split into their labels for further analysis.
E.g. this domain: http://www.developers.google.com is split into:
com – Top-level domain (TLD)
google – Second-level domain
developers – Third-level domain
www – Fourth-level domain
All domains in the domain list resulting from a sample are compared level-wise, such that the labels of every domain are only compared with the same level.
To find proper indicators for DGA usage, we have done a level-wise comparison of statistical values calculated over several lexical properties of DGA domains and non-DGA domains (e.g. from Top 500 Alexa Ranking).

Our experiments have proven that these statistical values over domain levels are very effective for DGA detection:
- Average of the . . .
- number of used hyphens
- maximum number of contiguous consonants
- Standard deviation of the . . .
- string length of the label
- consonant and vowel ratio
- entropy
- Redundancy of substrings or words in case of a wordlist DGA
With all these arguments, we can build a score with a specific threshold. If the score exceeds the threshold, the component will decide that the analyzed domain list was generated by a DGA. Since the arguments are based on statistical values, which lose their significance with smaller sets, it is also important to consider the case with too few domains. In this regard, the score is scaled down.
Separation of non-DGA Domains
Malware tries often to connect at first to a benign host (e.g. google.com) to check their connectivity to the internet. So, in case of DGA-based malware, the samples do not only send requests to DGA domains, but also to non-DGA domains. Hence the program for DGA classification needs to expect a domain list containing DGA domains and non-DGA domains. Before the program can classify a DGA, it needs to filter out the non-DGA domains. In this process, we assume that the majority of the domains in the domain list of the sample are DGA domains. Therefore, the non-DGA domains are considered as outliers. We used different outlier methods to identify non-DGA domains:
- Outlying TLD-label
- Outlying www-label
- Find outlier with the method of Nalimov [A. 84] regarding following label attributes:
- String length of the label
- Digit and string length ratio
- Hyphen and string length ratio
- Consonant and vowel ratio
- Outlying label count
- Find outliers by too few occurring values regarding the following label attributes (the more a value occurs, the higher is the probability that it belongs to a DGA domain. We use the opposite case to find non-DGA domains here):
- String length of the label
- Consonant and vowel ratio
- Digit and string length ratio
- Entropy
- Hyphen and string length ratio
- Relative position of the first hyphen in the label
DGA Classification
After the separation process of DGA domains from non-DGA domains, we start with the classification of the DGA. The classifier analyzes the list of DGA domains and creates a, specific as possible, regex that matches all these DGA domains. If the separation is not completely successful, the program will continue with the classification based on DGA domains and non-DGA domains which could lead to a wrong description of the DGA. But not every failing separation process causes a wrong classification. In some cases, if non-DGA domains cannot be differentiated from DGA domains regarding any domain attributes, then the classification will still return the correct DGA description, since it covers only the relevant domain attributes. If the failing separation process causes a wrong DGA description, then the resulting wrong or imprecise DGA description could be interpreted still as a fingerprint calculated over the requested non-DGA domains and the DGA domains. That fingerprint is still useful to group malware of the same family, because it is very common that those requested non-DGA domains occur in other malware samples of the same family, too.
DGA’s do not generate necessarily always the same set of domains, because in most cases the seed of the DGA is changed (usually the date is used as seed).
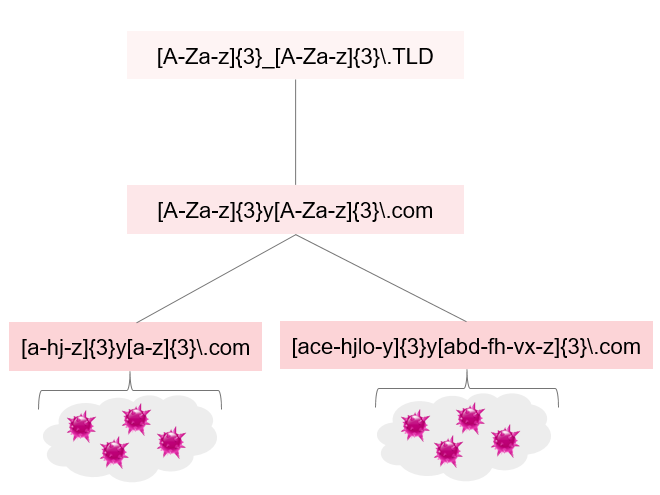
In the following picture, you can see that the calculated DGA regexes are not matching because of the differentiating first letter, which seems to be seed-dependent in that case:

An important requirement to the automatically generated DGA description is that it needs to be independent of the seed. Since it is in our perspective not possible to determine which part of a DGA domain is seed dependent, we use an approach that tries to generalize the seed-dependent part of a domain.
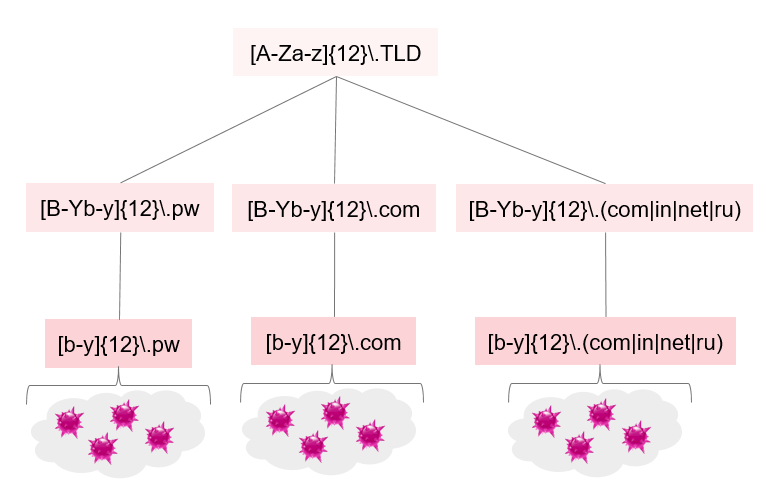
For this task, we use three layers of regexes that are hierarchically arranged:
- Layer: very generalized pseudo-regex
- Layer: generalized regex
- Layer: specific regex
All those regexes can be interpreted as DGA descriptions (calculated with only one sample) of the same DGA with different precision.
Such hierarchy could look like this:
Out of 113.993 samples, the DGA classifier detects 782 DGA-based malware samples.
To determine the false positive rate, we have reviewed the results of the analysis system manually. Regarding the DGA detection we have found 38 false positives in our result set. Hence we have a false positive rate that is lower than 0.049% (with the assumption that the DGA-based malware samples queried a relative high number of different domains). A false negative evaluation is hard in this case, because the number of input sample is too high for manual evaluation. For an automatic false negative evaluation, the required ground truth of a large sample set is missing.
The following excerpt shows some specific DGA regexes from the DGA classification, which used 38.380 DGA-based malware samples as input:
| Domain Fingerprint / Regex | Matches | Family name |
| [0-9A-Za-z]{8}\.kuaibu8\.cn | 569 | Razy |
| [a-hj-z]{3}y[a-z]{3}\.com | 2082 | simda |
| [a-z]{11}\.eu | 829 | simda |
| [a-z]{6,12}\.(com|info|net|org|dyndns\.org) | 2047 | Pykspa |
| [b-y]{12}\.(com|in|net|ru) | 8508 | tinba |
| [b-y]{12}\.com | 6296 | tinba |
| [b-y]{12}\.pw | 7714 | tinba |
| [b-y]{12}\.(biz|pw|space|us) | 35 | tinba |
| [b-y]{12}\.(cc|com|info|net) | 17 | tinba |
| [d-km-y]{12}\.(com|in|net|ru) | 172 | tinba |
| [d-y]{12}\.(com|in|net|ru) | 110 | tinba |
| [c-y]{12}\.(com|in|net|ru) | 45 | tinba |
| [df-km-su-x]{12}\.(com|in|net|ru) | 110 | tinba |
| [a-z]{8}\.info | 216 | tinba |
| v[12]{1}\.[a-uw-z]{7}\.ru | 77 | Kryptik |
| v1\.[a-uw-z]{7}\.ru | 579 | |
| [b-np-z]{7,11}\.(com|net) | 113 | |
| [0-9A-Za-z]{8}\.[aiktux]{3}i[abnu]{2}8\.cn | 114 | |
| [a-y]{6,19}\.com | 644 | Ramnit |
| [a-z]{14,16}\.(biz|com|info|net|org) | 173 |
It is conspicuous that the Tiny Banker Trojan (Tinba) has a very high occurrence with different specific regexes in the result set. After generalizing the most regexes of Tinba, as described in section 2.3, it will be possible to group all samples with only one regex. The missing family names are given by the fact that we could not detect automatically to which malware family the samples that used the DGA belongs.
The result shows that DGA detection and DGA classification can be very useful to detect new malware samples by their DGA. Hence it is also possible to find links between old and new malware samples of the same family via their classified DGA.
The DGA detection seems to be very reliable for samples that have queried many different domains. Our implemented concept for DGA classification seems to be in many cases successful. However, there are still cases where the calculated DGA descriptions are not correct, because the created patterns are sometimes overfitted to the given domain lists or rather non-DGA domains were considered in the calculation of the DGA descriptions, too. To confine this problem, we use a multi-layered regex generalization.
Even wrong DGA descriptions can be still considered as fingerprints calculated over the domain list of the sample. That fingerprint could be used to classify the DGA-based malware, so that it makes still a good contribution to automated malware analysis.
[A. 84] A. Zanker. Detection of outliers by means of Nalimov’s test – Chemical Engineering, 1984.
[H. 16] H. Zhang, M. Gharaibeh, S. Thanasoulas, C. Papadopoulos Colorado State University, Fort Collins, CO, USA. BotDigger: Detecting DGA Bots in a Single Network, 2016.
[R. 13] R. Sharifnya and M. Abadi – Tarbiat Modares University Tehran, Iran. A Novel Reputation System to Detect DGA-Based Botnets, 2013.
[T. 13] T. Frosch, M. Kührer, T. Holz – Horst Görtz Institute (HGI), Ruhr-University Bochum, Germany. Predentifier: Detecting Botnet C&C Domains From Passive DNS Data, 2013.