During exploitation of ELF binaries, it is quite common that one needs to find a writable memory region: a writable “cave”. In this post I’ll present two generic techniques to find such caves, without the need to reverse engineer the target binary.
Introducation
Searching for a Writable “cave”
When developing an exploit, one will often try to write his shellcode / ROP stack to a writable vacant place in the program’s address space. Such writable places, writable “caves”, could be used when one has a Write-What-Where attack primitive. The attacker will use this attack primitive in order to prepare his full exploit in memory before using it.
Memory Pages 101
CPUs manage their memory in pages: chunks of 4KB (we will ignore large pages for now). This means that the loader will load only page-sized chunks into the program’s address space. In addition, permissions (R, W, X) can only be set to pages, causing some special edge cases we will soon discuss.
ELF binaries 101
ELF, Executable and Linkable Format, is a binary format that describes an executable program (or library). ELFs are used in Unix-based operating systems, and are also very popular in various firmware structures of network and embedded devices.
Traditionally, a program will contain several logical sections, including:
- .text section – the code, has RX permissions
- .data section – the data variables (Example: global variables), has RW permissions
- .rodata section – read-only data variables (Example: strings), has R permissions
Diving deeper
Naive Server
In the following examples I will use a little program, “naive server”, that receives basic commands and reads/writes from/to it’s memory accordingly. This program is quite handy when testing an exploitation method, before trying it on a real vulnerable programs.
Studying our target
Using IDA Pro, we can look at our program’s data section:

While bigger targets will most probably contain bigger .data sections, all programs will have some common property: it is very unlikely that the data section’s size will be aligned to page size.
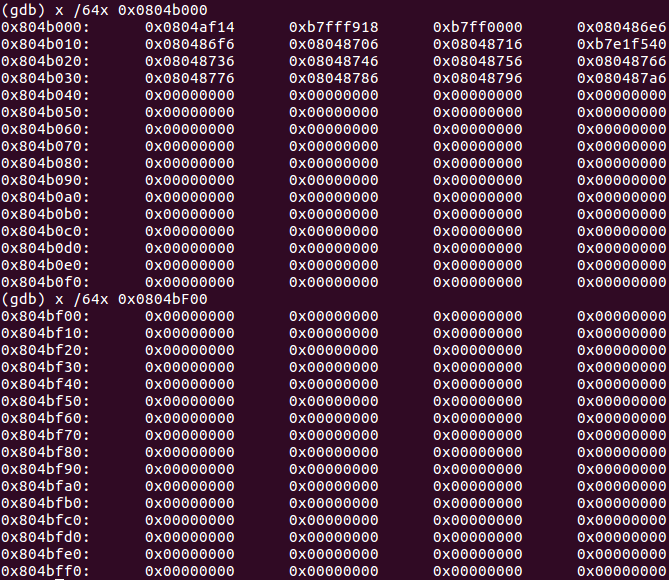
So, if our program does not contain enough data, what will be mapped to the page? Let’s look in GDB and find out:

Answer: the loader will pad our data with 0’s to the end of the page.
As an additional example, let’s send some read commands to the naive server, and check what do we get back:

Cave Scenario #1 – the page’s corner
Most programs won’t have their .data section fully aligned to page-size. This means that the last page in the .data section will contain a padding of 0s. This vacant corner is an excellent writable “cave” as we know that the program will never access this memory. And we don’t even need to reverse engineer the program, as the ELF header itself is enough to find the cave and know that it is empty.
Cave Scenario #2 – the ELF’s backyard
It is quite common in firmwares that the program will be compiled so that the .data section will start right after the .text section. A good example can be found in this excellent paper:

Since we can’t map the W data to the same page as the RX code, we will need to split them to 2 separate pages. However, since the program expects it’s .data segment to start at a given offset (0xF00 in this example), the loader will maintain this property by padding 0’s to the start of the 1st .data page.
This means that firmwares that were compiled this way will most probably have a vacant writable “cave” at the start of the .data section. And once again, we can find and use this cave using the ELF header, without worrying that the program might access our cave.
Conclusion
By leveraging the fact that memory is mapped using pages, while programs are compiled to a more fine grained size granularity, we can generically find writable “caves” for our exploits. These 2 types of “cave”s depend only on the layout of the program, without the need to actually reverse-engineer the program when making sure the program won’t access our “cave”.