
Every vulnerability has two clocks running. One belongs to the defender racing to find it; the 2026-6-17 19:30:0 Author: www.microsoft.com(查看原文) 阅读量:23 收藏
Every vulnerability has two clocks running. One belongs to the defender racing to find it; the other to the cyberattacker hoping to find it first. For as long as software has existed, those clocks have favored the attacker, because modern code is vast, interconnected, and changing every day, while security reviews happen at fixed moments in time. The space between “code shipped” and “code reviewed” is where risk quietly accumulates.
A few months ago, we set out to reshape that timing. We introduced codename MDASH, Microsoft Security’s multi-model agentic scanning system, built to discover, validate, and help remediate software vulnerabilities end-to-end. The goal was straightforward to articulate and hard to execute: take AI-powered vulnerability discovery and remediation capability from a research project and turn them into production-grade defense at enterprise scale. That meant going beyond pattern matching and building a system that could reason through the complexity of proprietary code and platforms like Windows, Hyper-V, Azure, and identity systems.
Rather than rely on any single model, the system orchestrates a panel of specialized AI agents, each with its own role in a structured pipeline, so security teams can surface hard bugs quickly and systematically, expanding the reach of human-led review. Findings flow into Microsoft Defender workflows, where they can be prioritized alongside threat intelligence and runtime signals, and into GitHub and Azure DevOps pipelines, where they can be validated and remediated, a closed loop connecting discovery, validation, proof, and fix across the Microsoft stack.
When we introduced the system, it topped a leading industry benchmark. That was the announcement, and the starting line. In the weeks since, the system has moved from early capability validation into active use by Microsoft engineering teams across Windows, Azure, and identity systems, applied as part of real security workflows rather than isolated testing environments. This post explores what we have built since, the lessons we’ve learned from turning research into a production-quality system, and the opportunities ahead as we focus on delivering real-world security impact.
From the lab into the pipeline
The most meaningful change since launch is where the system is being used. Engineering teams across Windows, Azure, and identity systems are now applying the system as part of their security workflows, running it alongside existing processes and reviews, targeting it at the surfaces that are hardest to audit manually and have historically required the most effort to cover. The goal is to use AI-driven analysis to go deeper, earlier, and across a broader set of targets than traditional approaches allow.
The surfaces in scope are among the most complex Microsoft builds:
- Windows, the kernel, Hyper-V, and the networking stack
- Azure, virtualization and core infrastructure services
- Identity, Active Directory Domain Services
These are not easy targets. They are the deep layers of the platform, components where reasoning about code requires understanding kernel calling conventions, object lifetime invariants, and trust boundaries that no language model encountered in its training data. A single overlooked flaw at this layer can have outsized consequences. The system is not replacing security teams working at this depth. It is giving them meaningful reach into territory they could not cover alone.
Codename MDASH has enabled our security team to perform vulnerability hunting at the scale of Windows with a much higher depth of analysis than was previously possible.”
—Windows security team (kernel, Hyper-V, networking stack)
This is also where the system fits into Microsoft’s existing DevSecOps story. It is not a standalone scanner bolted onto the side of engineering—it plugs into the tools teams already use. Validated findings surface as code scanning alerts in GitHub Advanced Security (GHAS), appearing inline on pull requests and in the repository’s security tab so engineers triage them in the same place they review code. The same findings flow into Azure DevOps, where they can gate pipeline builds and open work items for remediation, and into Microsoft Defender, where they are prioritized alongside threat intelligence and runtime signals. Discovery is only the entry point: because a finding travels the same path as every other code change—with an owner, a pull request, and a fix on the other side—it lands as actionable engineering work rather than stalling in a backlog. The effect is to strengthen the software development lifecycle from the inside, not to add one more tool for teams to tend.
This month’s set of discoveries
The measure of any security system is what it catches. This month’s Patch Tuesday cohort includes a set of vulnerability discoveries across the Windows ecosystem, Hyper-V, the Windows kernel, Active Directory Domain Services, Remote Desktop Client, HTTP.sys, DNS Client, and DHCP Client, spanning exploit classes including remote code execution, elevation of privilege, and information disclosure.
The range of attack vectors is significant. Several findings involve high-severity remote code execution vulnerabilities in core infrastructure layers that are difficult to scrutinize using manual approaches alone. Others surface more subtle issues, such as privilege escalation through DNS components and information disclosure through DHCP client behavior, that reflect the power of code-centric reasoning applied across many targets simultaneously. Each was identified before exploitation, in areas of the codebase that would traditionally demand significant manual effort to review.
| CVE ID | Component | Type | Exploit Class | CVSS (Common Vulnerability Scoring System) |
|---|---|---|---|---|
| CVE-2026-45607 | Windows Hyper-V | Out-of-bounds Read | Remote Code Execution | 8.4 |
| CVE-2026-45641 | Windows Hyper-V | Type Confusion | Remote Code Execution | 8.4 |
| CVE-2026-47652 | Windows Hyper-V | Heap-based Buffer Overflow | Remote Code Execution | 8.2 |
| CVE-2026-41108 | Windows DNS Client | Heap-based Buffer Overflow | Elevation of Privilege | 7.0 |
| CVE-2026-45608 | Windows DHCP Client | Out-of-bounds Read | Information Disclosure | 6.8 |
| CVE-2026-45634 | Windows DHCP Client | Out-of-bounds Read | Information Disclosure | 5.5 |
| CVE-2026-45648 | Windows Active Directory Domain Services | Stack-based Buffer Overflow | Remote Code Execution | 8.8 |
| CVE-2026-47289 | Remote Desktop Client | Heap-based Buffer Overflow | Remote Code Execution | 8.8 |
| CVE-2026-45657 | Windows Kernel | Use-after-free | Remote Code Execution | 9.8 |
| CVE-2026-47291 | HTTP.sys | Integer Overflow | Remote Code Execution | 9.8 |
Beyond the headline: What the engineering work taught us
How the system improved
To improve a system, you have to measure it. CyberGym, an industry benchmark built on 1,507 real-world vulnerabilities, gave us a way to iterate quickly and see exactly where we were getting better.
Since the initial announcement, we evolved the system significantly: new capabilities added, and the entire pipeline rebuilt based on customer feedback, CyberGym evaluation results, and extensive internal testing. The latest version has achieved 96.5% (any crash) on CyberGym, including both target and non-target vulnerabilities.
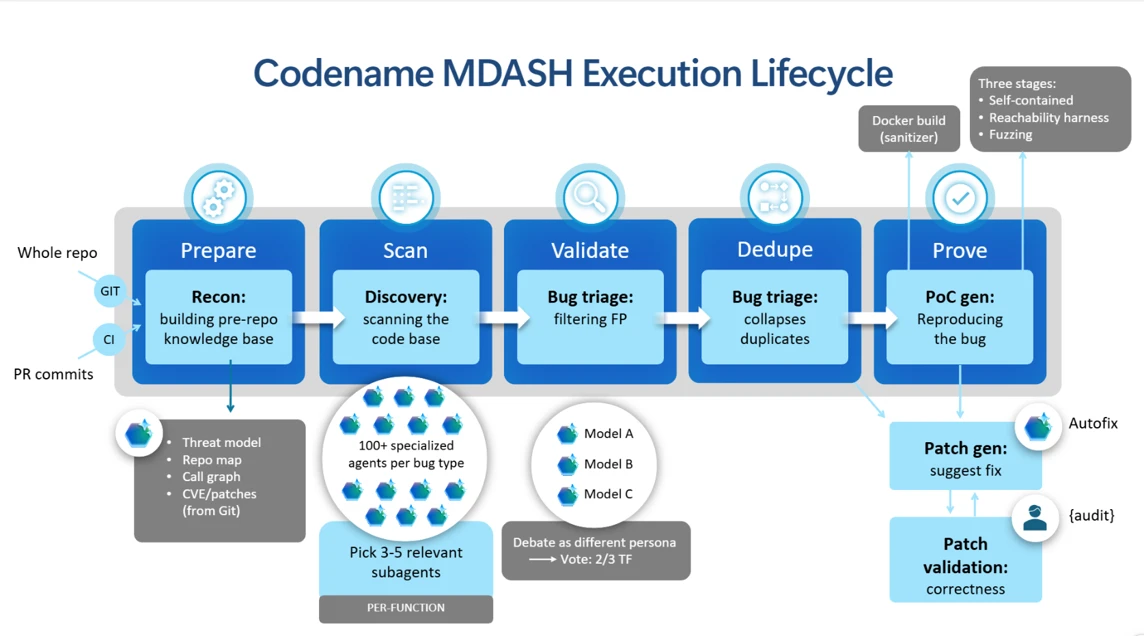
The gains were concentrated in the earliest stages of the pipeline: prepare and scan. These are foundational. Improvements there directly raise the quality of everything downstream, such as validation and proof generation, where precise understanding of the codebase and accurate exploration are critical. Specifically:
- Sharper scoping. The system now more clearly distinguishes the code under audit from contextual code, defining dependencies based on their role rather than their origin. Later stages can focus on what matters, improving both efficiency and signal quality.
- More comprehensive threat modeling. The system has a fuller view of a target repository’s attack surface, particularly in identifying entry points for untrusted input. This includes improved recognition of maintainer-defined entry points, such as fuzz harnesses, that may reside outside the primary codebase but are critical for assessing reachability. The system is better positioned to determine which findings are genuinely exploitable.
- A more reliable call graph. The correctness and robustness of the call graph, a core structure used across multiple pipeline stages, has been strengthened, improving the system’s ability to reason about code interactions, especially for reachability analysis during validation.
- Smarter routing to specialized agents. A new routing mechanism filters out clearly irrelevant agents while preserving strong candidates, reducing unnecessary computation while maintaining coverage and allowing the system to scale across diverse targets.
The principle behind all of it is the same: the model is one input, the system around it is the product. Better understanding in the early stages produces more accurate conclusions later, regardless of which model is doing the reasoning.
Understanding the remaining 3.5%
While the 96.55% score previously announced, represents a significant step forward, the system missed 3.5% of cases, 52 tasks in total.
We analyzed which pipeline stage contributed to each miss:
- Scan stage: 8 cases (15.4%), failed to identify the intended finding.
- Validate stage: 10 cases (19.2%), incorrectly flagged intended findings as false positives.
- Prove stage: 34 cases (65.4%), failed to generate a working proof-of-concept.
The following highlights the main failure reasons at each stage.
Scan stage failures
Incorrect scope from ambiguous descriptions. In some cases, the scope generated during the prepare stage did not include the files or functions containing the intended vulnerability. This occurs when bug descriptions are too general, especially in repositories with multiple modules, making precise localization difficult. In arvo:53536, the target bug description reads:
“A stack-buffer-overflow occurs in the code when a tag is found and the output size is not checked to ensure it is within the bounds of the buffer.”
It identifies the vulnerability type but gives little guidance on where to look in a large codebase.
Missed prioritization of vulnerable components. The system prioritizes which files and functions to analyze first and can sometimes de-emphasize less obvious components. In arvo:23547, the vulnerability resides in a lexer/parser component, but the system prioritized other C code paths instead.
Validate stage failures
Hypothetical descriptions and code misinterpretation. Scan results sometimes include hypothetical descriptions of vulnerabilities rather than concrete execution paths. When the validate stage cannot confirm a concrete path in code, it may reject the finding.
In the CyberGym benchmark case “arvo:3569,” the scan stage correctly identified a use-after-free vulnerability, but the validate stage concluded there was no feasible path to free the pointer, and rejected it. The scan-stage finding included a description like: “risk if any destructor or cleanup code attempts to free…” That framing left the validate stage without enough evidence to confirm reachability.
Prove stage failures
Highly structured input requirements. Some targets require complex, structured binary inputs, IVF/AV1, WPG, fonts, PDFs, where crafting inputs that both satisfy format validation and reach the vulnerable code path is inherently difficult, making reliable proof-of-concept generation challenging.
Fuzzing until timeout. For targets requiring highly structured inputs, the system sometimes attempted fuzzing-based approaches that found crashes but failed to generate inputs accepted as valid by the target within time constraints.
Environment mismatch. In some cases, the system reproduced crashes locally but those did not transfer to the evaluation harness, due to mismatches in build configuration, incorrect target selection, or execution paths that differed from the intended setup.
Build complexity and time constraints. In several cases, the build process failed, ran too long, or exceeded the agent’s execution budget, preventing proof-of-concept generation.
Paths to improvement
Integrating fuzzing pipelines. The prove stage is the primary bottleneck in both benchmark and real-world settings. We will integrate the system with existing fuzzing ecosystems such as OSS-Fuzz, allowing us to reuse build pipelines rather than reconstruct them and to draw on existing seed corpora for more effective proof generation. This approach was not applied during CyberGym evaluation, as it may implicitly reuse known proofs-of-concept, but will be adopted for real-world targets.
Extending analysis beyond source code. Some POC generation failures were due to limited support for non-traditional code artifacts. While the system handles conventional languages such as C/C++ well, it does not yet fully support artifacts generated by tools like lex/yacc. We are extending our analysis to cover these cases and broaden our overall coverage.
Improving agent reasoning and output quality. Failures in scan and validate stages often stem from speculative or incomplete reasoning. We will refine agent instructions, enforce structured outputs, and add validation checks to reduce ambiguity and improve reliability.
What newer models add
To isolate the impact of system-level improvements, our primary evaluation (Exp-0, baseline) intentionally used the same model configuration as the previous CyberGym benchmark, attributing gains directly to pipeline improvements rather than model advances. Modern foundation models continue to evolve, however, and we ran additional experiments on the 52 previously failed cases to understand what stronger models contribute.

Experiment 1: Newer OpenAI models for bug discovery, Claude Opus 4.6 for prove
- Configuration: Prepare / Scan / Validate: GPT-5.4, GPT-5.5, GPT-5.4-mini, GPT-5.3-codex. Prove: Claude Opus 4.6.
- Result: 19 of 52 cases solved (36.5%, any crash). Assuming no regressions on previously solved cases in Exp-0, projected success rate: 97.8% (any crash).
The primary gain comes from higher-quality scan-stage findings. Compared to Exp-0 baseline in this dataset, outputs are less hypothetical and more precise, with concrete execution details that improve both validation accuracy and downstream proof generation.
In the CyberGym benchmark case “arvo:3569,” the baseline produces a vague description, “risk if any destructor or cleanup code attempts to free…”, while GPT-5.5 identifies a specific execution path: “line 210 calls pj_default_destructor (P,…), which frees P->params, Q (= P->opaque).” That grounded description gives validation a clear path to reason about reachability.
GPT-5.5 also shows improved alignment between detected bugs and their corresponding common weakness enumeration (CWE) categories, contributing to more effective proof generation.
Experiment 2: GPT-5.5 / GPT-5.5-cyber for prove, using bug discovery from Experiment 1
- Configuration: Prepare / Scan / Validate: Bug discovery outputs from Experiment 1. Prove: GPT-5.5 / GPT-5.5-cyber.
- Result (GPT-5.5): 21 of 52 cases solved (40.4%, any crash). Assuming no regressions on previously solved cases in Exp-0, projected success rate: 97.9% (any crash).
- Result (GPT-5.5-cyber): 23 of 52 cases solved (44.2%, any crash). Assuming no regressions on previously solved cases in Exp-0, projected success rate: 98.1% (any crash).
Both GPT-5.5 and GPT-5.5-cyber found more crashes than Claude Opus 4.6 in the prove stage. The gain is meaningful but more modest than the improvements observed in scan. This dataset alone is not sufficient to conclude these models are consistently stronger across all proof-of-concept generation tasks.
Three distinct strategies emerged across all models in the prove stage:
- Code-based, reasoning over code paths to craft inputs.
- Fuzzing-based, searching the input space for crashes.
- Custom instrumentation-based, exposing vulnerability-relevant variables and using them as feedback signals to guide input generation.
All three models applied all three strategies across the 52 cases but differed in which targets they applied them to, and that selection drove differences in outcome. In arvo:61902, only GPT-5.5-cyber generated a working proof-of-concept, applying a custom instrumentation-based approach that reframed the task as a hill-climbing problem: reducing “understand the codec well enough to craft adversarial audio” to “search until this value exceeds 128.”
Seeing past the score
CyberGym has been an invaluable platform for rapid iteration, continuous evaluation, and measurable progress. Through this feedback loop, the system has advanced dramatically, reaching 96.5% performance on the benchmark, with newer models already contributing an additional 1%-2% improvement beyond that baseline. Achieving this level of performance in such a short period is a strong indicator of the underlying architecture, research direction, and engineering rigor driving the effort.
At the same time, we are careful to interpret these results appropriately. A 96.5% CyberGym score demonstrates that the system can reason effectively over a broad and challenging set of known vulnerabilities. Equally important, it highlights an opportunity to broaden our evaluation framework. Real-world vulnerability discovery involves ambiguity, incomplete information, and constantly evolving software ecosystems—dimensions that extend beyond any fixed benchmark. This is precisely what makes the next phase of the work so exciting: applying these capabilities to increasingly realistic environments and pushing the frontier from benchmark excellence to real-world impact.
Where we go next
We will chart our course in two directions.
First, we are advancing the system to operate in genuine real-world environments, targeting cost-efficient discovery of previously unknown vulnerabilities, combined with integrated capabilities to triage and fix issues at scale. Finding the bug is half the job. Closing it is the other half.
Second, we see a clear opportunity to advance the benchmark to capture the complexity, ambiguity, and end-to-end workflows of how real-world vulnerability discovery actually happens.
The model variation experiments point toward the same conclusion: the system and the models improve in complementary ways. To prove our pipeline gains were not simply model gains, we held the model configuration constant in the core evaluation, then tested newer models separately. The additional gains were real, especially in the precision of scan-stage findings. That is not a complication in interpreting the results. It is a roadmap.
Defense at AI speed
Come back to the two clocks. The arc of this work is the story of the moment they switched places: from a defender racing to catch up, to a defender with AI-driven analysis reaching deeper into production code, earlier in the process, across a broader surface than any manual program could sustain.
That is what defending at AI speed means. Not faster scanning in isolation, but a posture that keeps pace with the way software is actually built and shipped today, where every improvement to the pipeline makes the next finding more precise, and the system and the models grow stronger together.
Learn more
Codename MDASH is just getting started. We would like you with us for the next chapter.
Sign up to follow codename MDASH and join the private preview. To go deeper on the engineering behind codename MDASH, explore our technical blog series.
To learn more about Microsoft Security solutions, visit our website. Bookmark the Security blog to keep up with our expert coverage on security matters. Also, follow us on LinkedIn (Microsoft Security) and X (@MSFTSecurity) for the latest news and updates on cybersecurity.
如有侵权请联系:admin#unsafe.sh