Published at 2020-11-04 | Last Update 2020-11-04
This post also provides an English version.
本文是我们的前一篇博客 Trip.com: First Step towards Cloud Native Networking 的后续,介绍自上一篇博客以来我们在基于 Cilium 的云原生网络和云原生安全方面的一些 探索和实践。
从 2013 到 2018 年,我们经历了物理机到虚拟机再到容器的基础设施演进,但网络技 术栈基本都是沿用 Neutron+OVS —— 即使对我们(前期)的 Kubernetes 集群也是 如此。但业务开始往 Kubernetes 迁移之后,这套 Neutron+OVS 的网络方案越来越捉襟见肘, 尤其是在部署密度更高、规模更大的容器面前,这种大二层网络模型的软件和硬件瓶颈暴露无遗 [1]。
为了解决这些问题,更重要地,为了满足云原生业务的各种需求(例如,支持Kubernetes 的 Service 模型),我们调研了很多较新的网络方案,综合评估之后,选择了 Cilium+BGP 的组合 [3]。

Fig 1-1. Networking solutions over the past years [2]
Cilium+BGP 方案 2019 年底正式在我们生产环境落地,我们打通了 Cilium 网络和现有网 络,因此能灰度将容器从 Neutron 迁移到 Cilium。
作为 Cilium 的早起用户之一,我们对 Cilium 的实现和部署做了一些修改或定制化,以使 这套方案能平滑地落地到我们现有的基础设施之中,例如 [2],
-
用
docker-compsoe + salt来部署,而不是采用默认的daemonset+configmap方式。这样每台 node 上的 cilium-agent 都有独立配置,我们能完全控制发布灰度,将 变更风险降到最低。
-
用
BIRD作为 BGP agent,而不是采用默认的kube-router。kube-router开箱即用,但缺少对 ECMP、BFD 等高级功能的支持,不符合我们生产环境的要求。 -
为了保证某些业务的平滑迁移,我们开发了 StatefulSet/AdvancedStatefulSet 固定 IP 的支持(需要 sticky 调度配合)。
-
定制化了监控和告警。
-
其他一些自定义配置。
我们之前的一篇文章 [2] 对此有较详细的介绍,有兴趣可以移步。 下面讨论几个之前介绍较少或者没有覆盖到的主题。
2.1 BGP 建连模型
Cilium+BIRD 方案中,以宿主机为界,网络可以大致分为两部分,如图 2-1 所示,
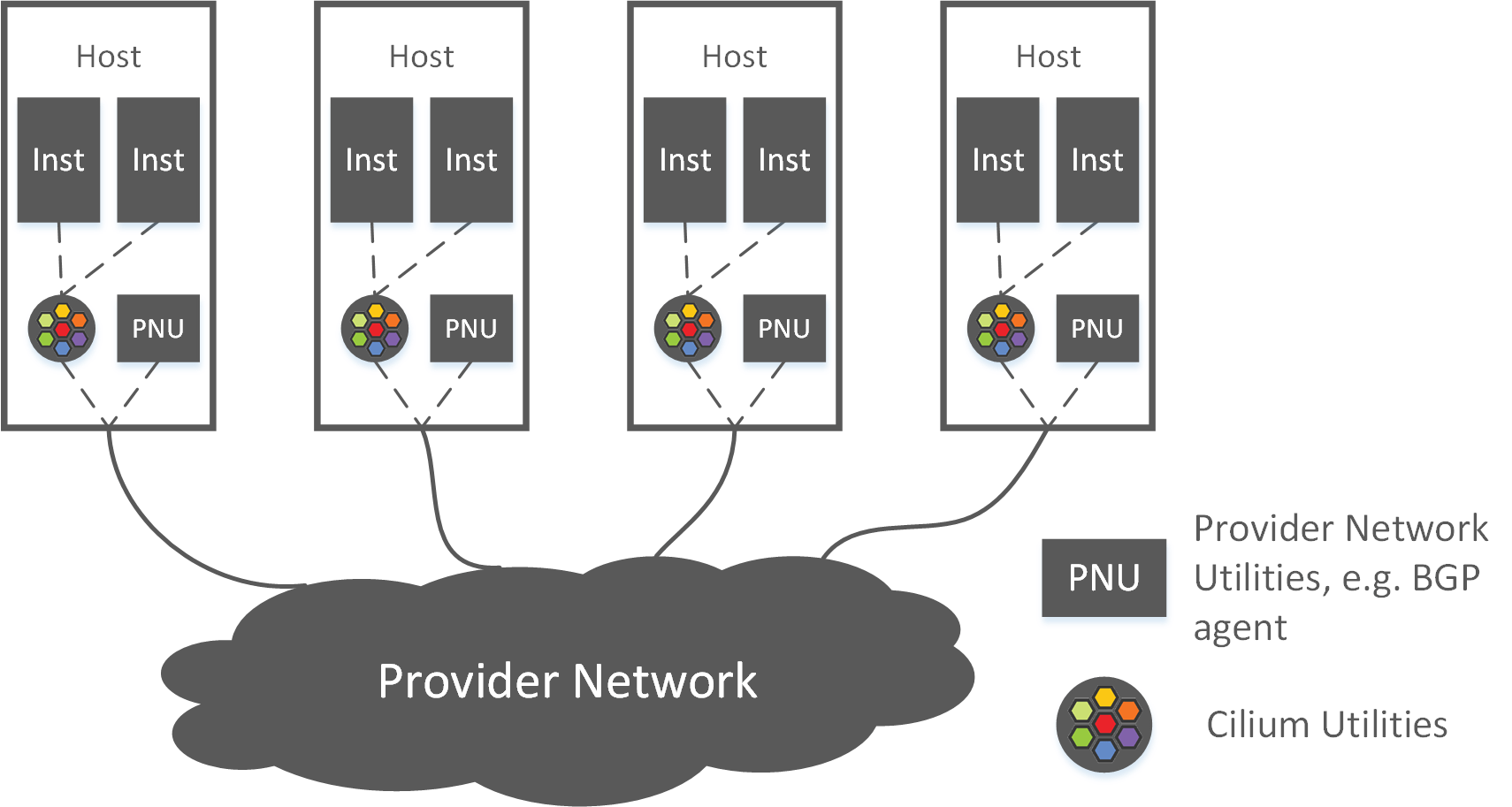
Fig 2-1. High level topology of the Cilium+BGP solution [2]
- 宿主机内部网络:由 Cilium(及内核协议栈)负责,职责包括,
- 为容器创建和删除虚拟网络。
- 为容器生成、编译和加载 eBPF。
- 处理同宿主机内容器之间的网络通信。
- 跨宿主机网络:由 BGP(及内核路由模块)负责,职责包括,
- 与数据中心网络交换路由(PodCIDRs)。
- 对出宿主机的流量进行路由。
对于跨宿主机部分,需要确定要采用哪种 BGP peering 模型,这个模型解决的问题包括 :
- BGP agent 的职责,是作为一个全功能路由控制服务,还是仅用作 BGP speaker?
- 宿主机和数据中心的哪些设备建立 BGP 邻居?
- 使用哪种 BGP 协议,iBGP 还是 eBGP?
- 如何划分自治域(AS),使用哪种 ASN(自治域系统编号)方案?
取决于具体的网络需求,这套 BGP 方案可能很复杂。基于我们数据中心网络能提供的能力 及实际的需求,我们采用的是一种相对比较简单的模型,
- 每台 node 运行 BIRD,仅作为 BGP speaker,
- Node 在上线时会自动分配一个
/25或/24的 PodCIDR。 - BIRD 和数据中心网络中的两个邻居建立 BGP 连接。
- BIRD 将 PodCIDR 通告给邻居,但 不从邻居接受任何路由。
- Node 在上线时会自动分配一个
- 数据中心网络只从 node 接受
/25或/24路由宣告,但不向 node 宣告任何路由。 - 整张网络是一张三层纯路由网络(pure L3 routing network)。
这种模型的简单之处在于,
- 数据中心网络从各 node 学习到 PodCIDR 路由,了解整张网络的拓扑,因此 Pod 流量在数据中心可路由。
- Node 不从数据中心学习任何路由,所有出宿主机的流量直接走宿主机默认路由(到数据 中心网络),因此宿主机内部的路由表不随 node 规模膨胀,没有路由条目数量导致的性能瓶颈。

Fig 2-2. BGP peering model in 3-tier network topology
在路由协议方面,
- 老数据中心基于“接入-汇聚-核心”三级网络架构,如图 2-2 所示,
- 节点和核心交换机建立 BGP 连接。
- 使用 iBGP 协议交换路由。
- 新数据中心基于 Spine-Leaf 架构,
- 节点和直连的 Leaf 交换机(置顶交换机)建立 BGP 连接。
- 使用 eBGP 协议交换路由。
我们已经将这方面的实践整理成文档,见 Using BIRD to run BGP [3]。
2.2 典型流量转发路径:从 Pod 访问 Service
来看一下在这套方案中,典型的流量转发路径。
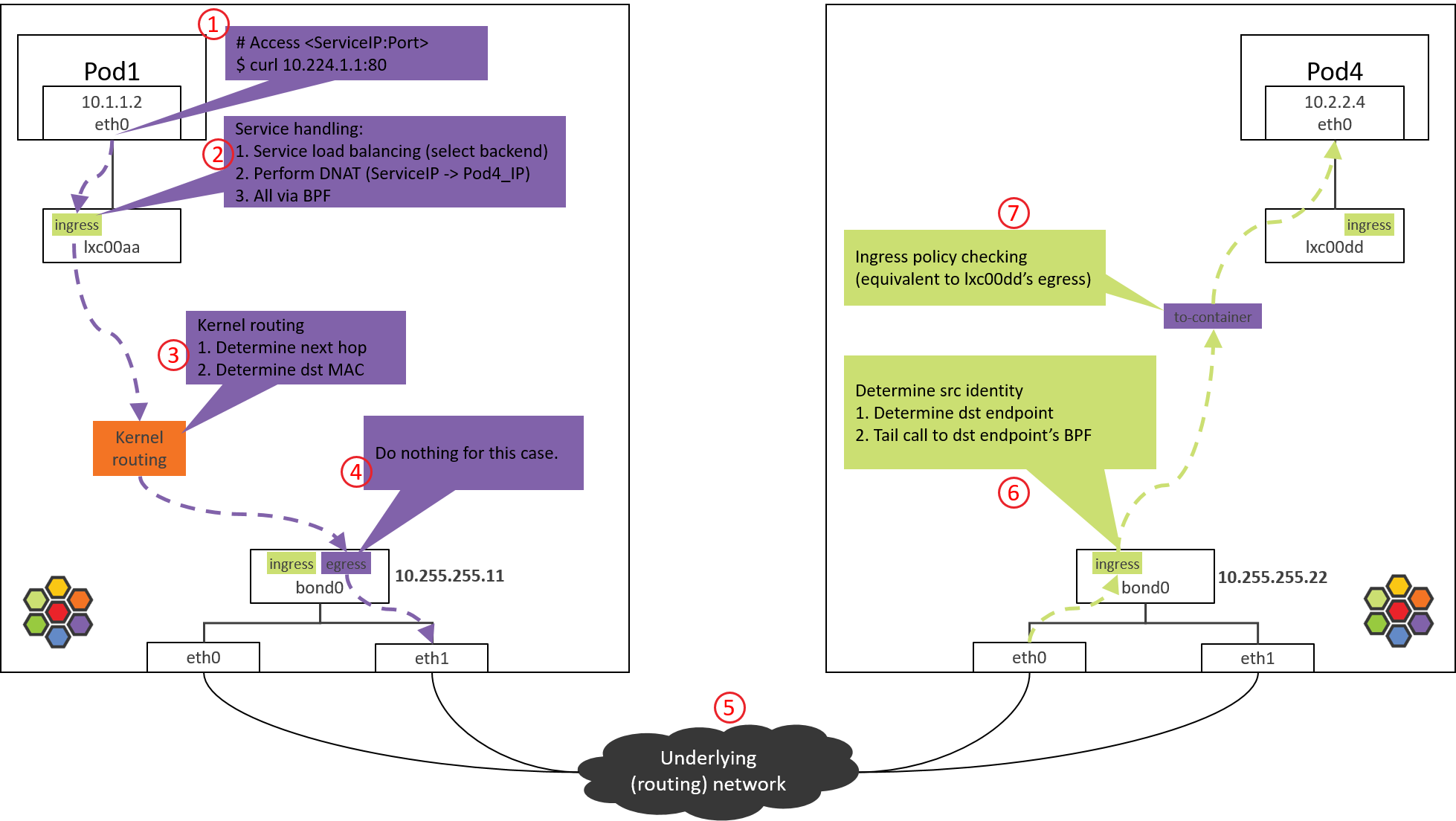
假设从一个 Pod 内访问某个 Service,这个 Service 的后端位于另一台 Node,如下图所示,

Fig 2-3. Traffic path: accessing Service from a Pod [4]
主要步骤:
- 在 Node1 上的 Pod1 里面访问某个 Service (
curl <ServiceIP>:<port>)。 - eBPF 处理 Service 抽象,做客户端负载均衡:选择某个后端,然将包的目的 IP 地址从 ServiceIP 换成后端 PodIP(即执行 DNAT)。
- 内核路由决策:查询系统路由表,根据包的目的 IP 地址确定下一跳;对于这个例 子匹配到的是默认路由,应该通过宿主机网卡(或 bond)发送出去。
- 包到达宿主机网卡(bond),通过默认路由发送到宿主机的默认网关(配置在数据中心 网络设备上)。
- 数据中心网络对包进行路由转发。由于此前数据中心网络已经从各 Node 学习到了 它们的 PodCIDR 路由,因此能根据目的 IP 地址判断应该将包送到哪个 Node。
- 包达到 Node 2 的网卡(bond):一段 eBPF 代码负责提取包头,根据 IP 信息找到 另一段和目的 Pod 一一对应的 eBPF 代码,然后将包交给它。
- 后一段 eBPF 代码对包执行 入向策略检查,如果允许通过,就将包交给 Pod4。
- 包到达 Pod4 的虚拟网卡,然后被收起。
我们有一篇专门的文章详细介绍整个过程,见 [4]。
2.3 集群边界 L4/L7 入口解决方案
在 Kubernetes 的设计中,ServiceIP 只能在集群内访问,如果要从集群外访问 Service 怎么办?例如,从 baremetal 集群、OpenStack 集群,或者其他 Kubernetes 集群访问?这属于集群边界问题。
K8s 为这些场景提供了两种模型:
- L7 模型:称为 Ingress,支持以 7 层的方式从集群外访问 Service,例如通过 HTTP API 访问。
- L4 模型: 包括 externalIPs Service、LoadBalancer Service,支持以 4 层的方 式访问 Service,例如通过 VIP+Port。
但是,K8s 只提供了模型,没提供实现,具体的实现是留给各厂商的。例如,假如你使 用的是 AWS,它提供的 ALB 和 ELB 就分别对应上面的 L7 和 L4 模型。在私有云,就需要 我们自己解决。
我们基于 Cilium+BGP+ECMP 设计了一套四层入口方案。本质上这是一套四层负载均衡器( L4LB),它提供一组 VIP,可以将这些 VIP 配置到 externalIPs 类型或 LoadBalancer 类 型的 Service,然后就可以从集群外访问了。
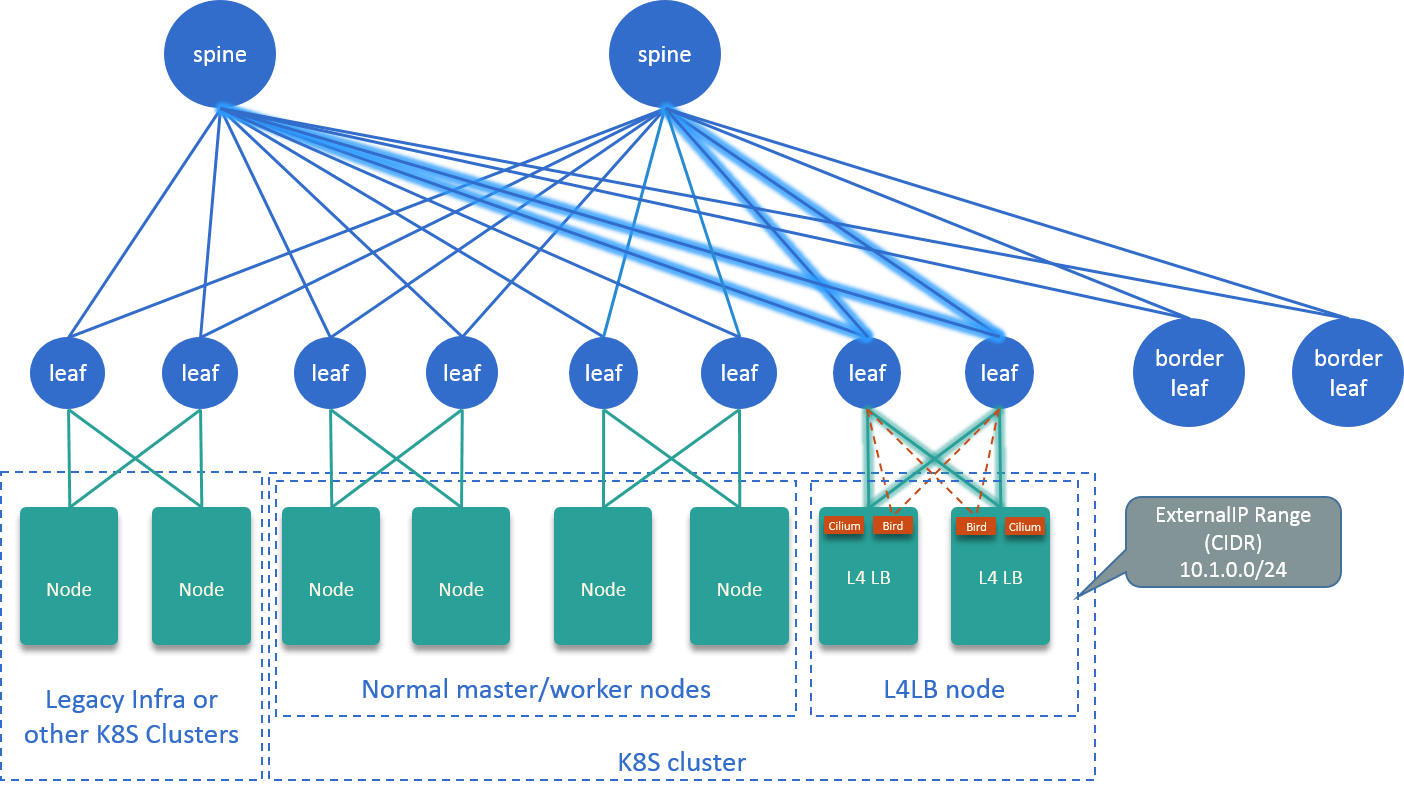
Fig 2-4. L4LB solution with Cilium+BGP+ECMP [5]
基于这套四层入口方案部署 istio ingress-gateway,就解决了七层入口问题。从集群外访 问时,典型的数据转发路由如下:
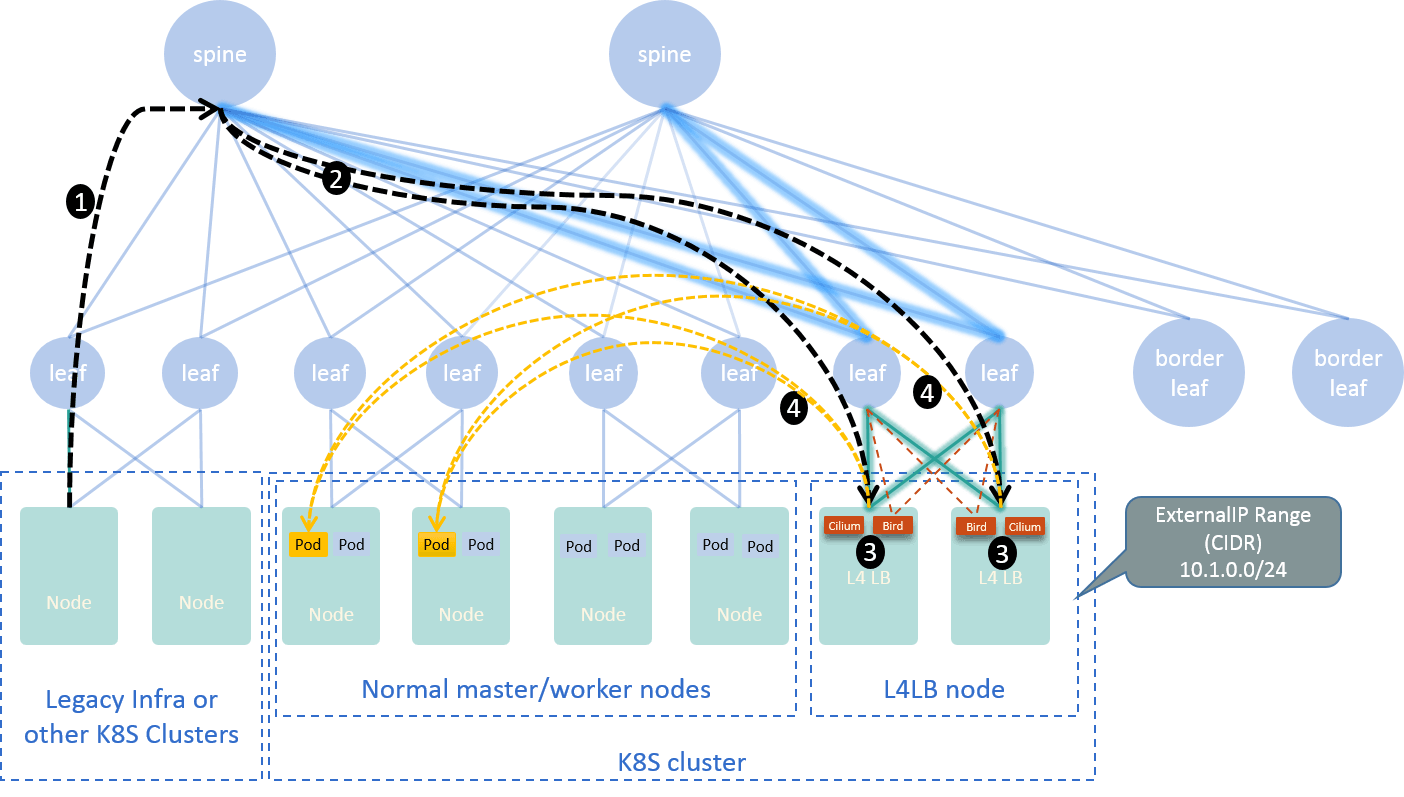
Fig 2-5. Traffic path when accesing Service from outside the Kubernetes cluster [5]
我们之前有篇博客详细介绍这个主题,见 [5]。
Cilium 提供的两大核心能力:
- 基于 eBPF 的灵活、动态、高性能网络。
- L3-L7 安全策略:CiliumNetworkPolicy 是对 K8s 的 NetworkPolicy 的扩展。
在落地了网络功能后,针对安全需求,我们在尝试落地基于 Cilium 的安全。
3.1 Cilium 安全策略
首先来看一个简单的例子,看看 CiliumNetworkPolicy (CNP) 长什么样 [6]:
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "clustermesh-ingress-l4-policy"
description: "demo: allow only employee to access protected-db"
spec:
endpointSelector:
matchLabels:
app: protected-db
ingress:
- toPorts:
- ports:
- port: "6379"
protocol: TCP
fromEndpoints:
- matchLabels:
app: employee
上面的 yaml:
- 创建一个 CNP,可以指定
name和description等描述字段。 - 对带
app=protected-db标签(labels)的 endpoints(pods)执行这个 CNP。 - 在执行 CNP 的时候,只对入向(
ingress)流量做控制,并且限制如下流量来源:- 协议是
TCP,并且端口是6379. - 流量来自带
app:employeelabels 的 endpoints(pods)。
- 协议是
可以看到,CNP 非常灵活,使用起来也很方便。但真实世界要远比想象中复杂,要真正落地 Cilium 安全策略,还存在很多挑战。
3.2 落地挑战
下面举两个例子,相信这些问题在很多公司都需要面对,并不是我们独有的。
多集群问题
如果你所有的应用都运行在 Cilium 集群中,并且客户端和服务端都收敛到一个集群(大部 分公有云厂商都推荐一个 region 只部署一套 K8s 集群,所有访问都收敛到这套集群),那落 地起来会简单很多。
但大部分有基础设施演进的公司恐怕都不满足这个假设,实际的情况很可能是:业务分散在多 个集群。
混合基础设施
多集群还不是最大的问题,因为业界多少还有一些多集群解决方案。
更严重的一个问题是:业务不仅分散在不同集群,而且在不同平台。例如对我们来说,现在 有:
- Bare metal 集群
- OpenStack 集群
- 基于 Neutron+OVS 的 Kubernetes 集群
- 基于 Cilium+BGP 的 Kubernetes 集群
虽然我们计划将所有容器从 Neutron 网络迁移到 Cilium 网络,但另外两种,bare metal 和 OpenStack 集群,还是会长期存在的,虽然规模可能会逐渐减小。
3.3 整体方案设计
我们目前的一个整体方案:在服务端容器做入向安全策略,客户端可以来自任何平台、任何集群:
- 这将范围框定到了已经在 Cilium 网络的服务端容器,是一个不错的起点。
- 传统网络里的服务端容器,会逐渐迁移到 Cilium 网络。
- BM 和 VM 的服务端实例,第一阶段先不考虑安全控制。
那接下来的问题就是:服务端如何具备对所有类型、所有集群的客户端进行限制的能力? 我们的解决方案是:
- 首先,用 Cilium 提供 ClusterMesh 将已有 Cilium 集群连接起来;
- 然后,“扩展” ClusterMesh,让它能感知到 mesh 之外的 endpoints,即 BM、BM 和 Neutron Pods。
下面分别解释这两点。
3.3.1 用 ClusterMesh 做 Cilium 集群互连

Fig 3-1. Vanilla Cilium ClusterMesh [6]
ClusterMesh [7] 是 Cilium 自带的一个多集群解决方案。如果所有应用都在 Cilium 集群 里,那这种方式可以解决跨集群的安全策略问题,即,application 实例可以分布在不同的集群。
这样说来,使用 ClusterMesh 似乎是理所当然的,但其实它并不是我们当初的第一选择。 因为多集群还有其他方案,本质上做的事情就是如何在多个集群之间同步元数据,并且做到 集群变动的实时感知。
- 出于多个内部需求,当时有考虑自己做这样一套元数据同步方案,它能解决包括 Cilium 在内的多个需求。
- 并未看到业界大规模使用 ClusterMesh 的案例,所以对它的可用性还存疑。
但后来综合对比了几种选项之后,觉得 ClusterMesh 还是值得尝试的。
关于 ClusterMesh 的实地(功能)测试,可以参考我们之前的一篇博客 [6]。
3.3.2 扩展 ClusterMesh,感知 mesh 外实例
这里的外部实例(external endpoints)包括 Neutron Pod、VM、BM。
基于对 Cilium 的理解,我们判断只要将外部实例信息以 Cilium 能感知的方式(格式)同 步到 Cilium 集群,那在入向(inbound),Cilium 对这些实例的控制能力,与对原生 Cilium 实例的控制能力并无区别。换句话说,我们“骗一下” Cilium,让它认为这些实例都是 Cilium endpoints/pods。
为此我们开发了一个组件,使得 OpenStack 平台、Bare metal 平台和Neutron-powered Kubernetes 平台能将它们的实例创建/销毁/更新信息同步更新到 Cilium 集群,如下图所示:

Fig 3-2. Proposed security solution over hybrid infrastructures
结合 3.3.1 & 3.3.2,在这套“扩展之后的” ClusterMesh 中,每个 Cilium agent 都对 全局实例(container/vm/bm)有着完整的、一致的视图,因此能在 Cilium Pod 的入向 对各种类型的客户端做安全控制。目前计划支持的是 L3-L4 安全策略,未来考虑支持 L7。
这套方案已经通过了功能验证,正在进行正式开发和测试,计划年底开始灰度上线。
本文总结了我们自上一篇博客以来,在基于 Cilium 的云原生网络和云原生安全方面的一些 探索和实践。更多技术细节,可参考下面一些链接。
- Ctrip Network Architecture Evolution in the Cloud Computing Era
- Trip.com: First Step towards Cloud Native Networking.
- Cilium Doc: Using BIRD to run BGP
- Life of a Packet in Cilium: Discovering the Pod-to-Service Traffic Path and BPF Processing Logics
- L4LB for Kubernetes: Theory and Practice with Cilium+BGP+ECMP
- Cilium ClusterMesh: A Hands-on Guide
- Cilium Doc: clustermesh
如有侵权请联系:admin#unsafe.sh