一个搜索引擎的实现流程大概为:首先获取海量的数据,整理成统一的格式,然后交给索引程序建立索引,当索引建立好后,就可以进行搜索。简而言之就是:数据获取->数据检索->数据搜索
数据获取大概有如下两种:
- 爬虫定期获取:根据网站特征,写爬虫规则,定期获取想要的文章数据
- 网站主动推送:网站拥有者主动向搜索引擎提交文章数据
搜索引擎的初期数据获取一般只能采取爬虫定期获取,当搜索引擎比较普遍使用(如谷歌、百度等),才会有很多网站拥有者主动推送。
0x1.1爬取站点
信息安全文章的站点,可以分为三类
- 安全社区:先知社区、安全客、嘶吼、freebuf、安全脉搏、91ri、看雪论坛、乌云知识库等
- 创作社区:博客园、csdn、简书、知乎、腾讯云社区等
- 个人博客:hexo主题博客、wordpress博客等
0x1.2爬取方式
在爬取之前,先弄清一下爬取的需求,每篇文章需要获取发布日期、作者、标题、正文内容、文章链接、网站域名。接着对文章重复的判断,这里主要是根据文章链接的唯一性来判断是否重复,当然有的文章可能会在多处发表,存在一小部分的重复文章,最后根据每个网站特点,写定制化爬虫。
爬取的方式可以分为两种,一种是根据网站页面特征来爬取,一种是请求数据接口来爬取。本次爬虫使用的 python 的 Scrapy 框架来演示。
0x1.2.1 网页特征
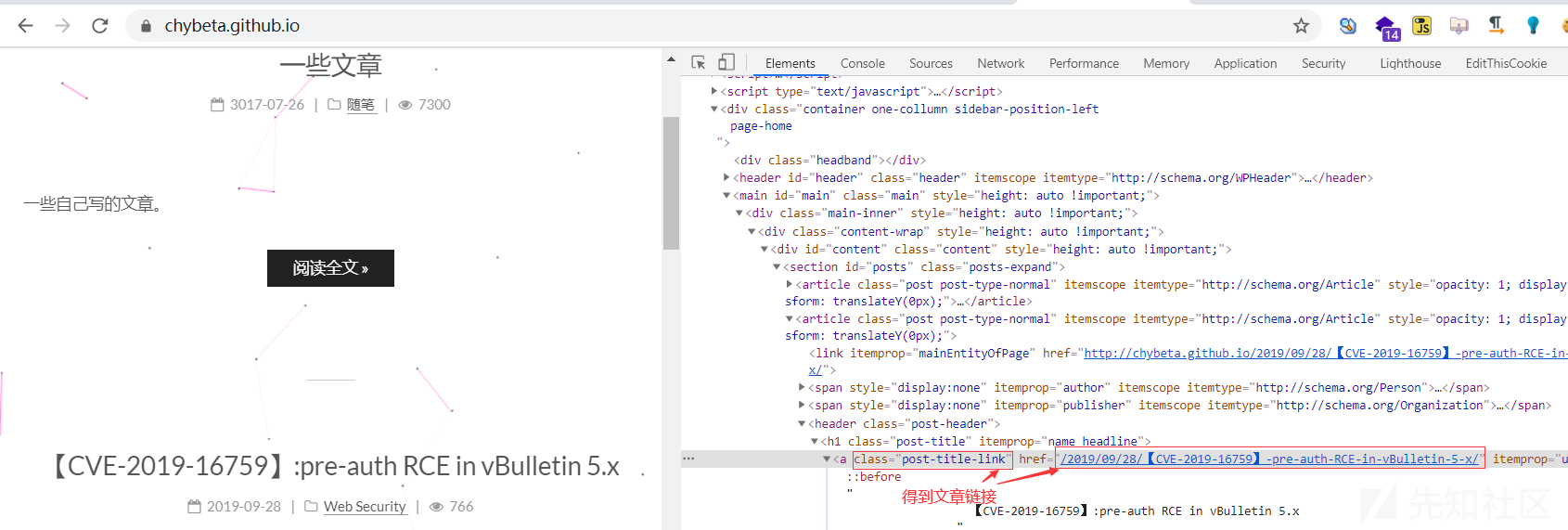
通过观察 HTML 页面,先确定一下要爬取信息所在的位置,然后看一下该位置所处的 DOM 路径、标签元素、属性元素,找到能准确获取该信息的方式。以 hexo 的 next 主题博客为例,这个主题还是挺多师傅使用的。
爬取思路:
(1). 爬取当前页面的所有文章链接
(2). 对页面中的每个文章链接进行爬取,得到文章相关信息
(3). 当前页面爬取完后,获取“下一页”,再从步骤(1)爬取
获取链接

获取文章信息

得到下一页面

在Scrapy 中可以使用 Scrapy shell 调试

Scrapy中的Spider代码如下
import scrapy from urllib import parse from crawlersec.items import CrawlersecItem from crawlersec.util import html_entity class SiHouSpider(scrapy.Spider): name="hexo_next" start_urls = ["https://chybeta.github.io/"] def parse(self, response): urls=response.xpath("//a[@class='post-title-link']/@href").extract()#得到页面的所有文章链接 for i in range(len(urls)): absolute_url=parse.urljoin(response.url,urls[i]) yield scrapy.Request(url=absolute_url, callback=self.parse_text) next_page=response.xpath("//a[@class='extend next']/@href").extract_first() if next_page:#获取下一页页面 absolute_url = parse.urljoin(response.url, next_page) yield scrapy.Request(url=absolute_url, callback=self.parse) def parse_text(self,response):#获取文章的相关信息 item=CrawlersecItem() item['url']=response.url item['title']=html_entity(response.css(".post-title::text").extract_first().strip()) item['author']=get_author_by_url(response.url) item['date']=response.xpath("//time/text()").extract_first().strip() content="" for text in response.xpath("//div[@class='post-body']//text()").extract(): content +="".join(text.split()) content=html_entity(content) item['content']=content item['domain']=list(parse.urlparse(response.url))[1] yield item def get_author_by_url(url): authors = {"chybeta.github.io": "chybeta"} return authors[list(parse.urlparse(url))[1]]
0x1.2.2 数据接口
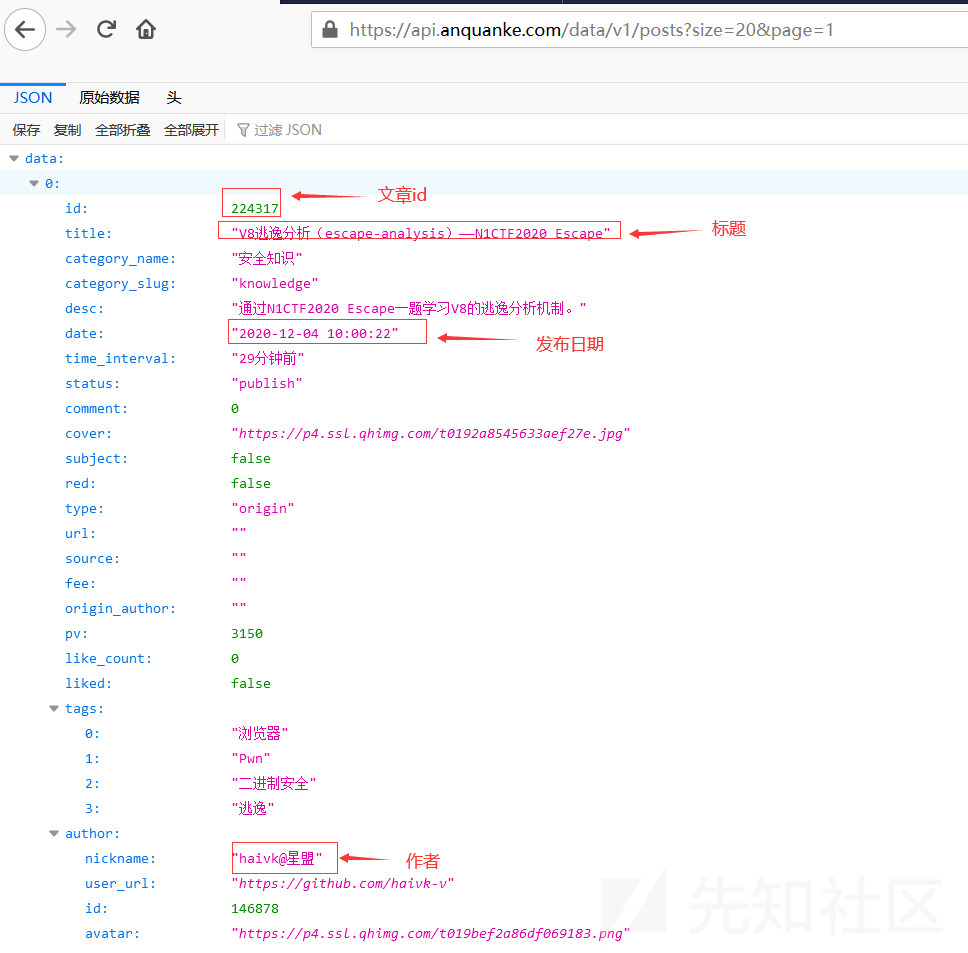
有些站点的文章信息是从数据接口请求而来,刚好可以直接请求数据接口获取文章的信息。例如安全客的文章:
安全客的网站结构是相对比较复杂,但点击加载更多,发现文章信息是通过请求数据接口得来的。
数据接口为
https://api.anquanke.com/data/v1/posts?size=20&page=1
爬取思路为:
(1).首先获取当前数据分页中每条数据文章标题、文章id、发布日期、作者
(2).将获取的文章id,都加上https://www.anquanke.com/post/id/,得到文章链接,请求文章链接获取正文内容
(3).获取下一数据分页,重复步骤(1)

Scrapy中的Spider代码如下
import scrapy from urllib import parse import simplejson from crawlersec.items import CrawlersecItem from crawlersec.util import html_entity class AnquankeSpider(scrapy.Spider): name="anquanke" allowed_domains=["anquanke.com"] base_url="https://www.anquanke.com/" start_urls=["https://api.anquanke.com/data/v1/posts?size=20"] def parse(self,response): prefix_url="https://www.anquanke.com/post/id/" res=simplejson.loads(response.text) posts=res['data'] for post in posts: item=CrawlersecItem() item['author']=post['author']['nickname'] item['date']=post['date'] item['title'] = post['title'] url=prefix_url+str(post['id']) item['url']=url item['domain']=list(parse.urlparse(self.base_url))[1] yield scrapy.Request(url=url,meta={'article_item':item},callback=self.parse_text) next_url=res['next'] if next_url: yield scrapy.Request(url=next_url,callback=self.parse) def parse_text(self,response): item=response.meta.get('article_item','') content="" for text in response.xpath("//text()").extract(): content +="".join(text.split()) content=html_entity(content)#HTML entity encoding item['content']=content print(item['content']) yield item
0x1.3 反爬策略绕过
0x1.3.1 User-Agent
反爬策略:网站在处理反爬的过程中,很常见的一种方式就是通过检测 User-agent 来拒绝非浏览器的访问。
绕过方式:可以维护一个 User-agent 组合列表,在发送请求时随机从列表中抽取一个,放入 Headers 请求头部里。
可以在 Scrapy 的 middlewares.py 中自定义 RandomUserAgentMiddleware 类,并作为Download Middleware 启用。Download Middware 是引擎和下载器的中间件,每个 Request 在爬取之前都会调用其中开启的类,从而对 Request 进行一定的处理,在这里对每个请求加上随机的User-Agent
class RandomUserAgentMiddleware(object): def process_request(self, request, spider): rand_use = random.choice(USER_AGENT_LIST) if rand_use: request.headers.setdefault('User-Agent', rand_use)
在 Scrapy 的 setting.py 中定义 USER_AGENT_LIST
USER_AGENT_LIST=[ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" ]
在 setting.py 的 Download Middware 参数配置中添加定义的类
DOWNLOADER_MIDDLEWARES = { 'crawlersec.middlewares.CrawlersecDownloaderMiddleware': 543, 'crawlersec.middlewares.RandomUserAgentMiddleware': 400, }
0x1.3.2 IP限制
反爬策略:同一 IP 访问网站过于频繁,就会对该 IP 进行限制,短时间内无法访问。
绕过方式:
1.维护一个 IP 代理池,每次请求随机使用 一个 IP 代理
2.调小爬虫的线程并发数,或每次请求后,设置一个短时间暂停
这里就从一些免费的站点中获取一些 IP,并保存在 proxies.py 文件中
如 www.xiladaili.com 站点
import scrapy import requests class SeeBugSpider(scrapy.Spider): name="proxy" allowed_domains=["www.xiladaili.com"] base_url="http://www.xiladaili.com/" def start_requests(self): tmp_url="http://www.xiladaili.com/gaoni/{}/" f = open('proxies.txt', "r+") f.truncate() for i in range(2,200):#数字可查看官网链接 yield scrapy.Request(url=tmp_url.format(i),callback=self.parse) def parse(self,response): proxy_list=response.xpath("//tbody//tr/td/text()").extract() for i in range(0,len(proxy_list),8): self.verify_one_proxy(proxy_list[i+1],proxy_list[i]) def verify_one_proxy(self,protocol,url): schema = 'https' if 'https' in protocol else 'http' proxies = {schema: url} print(proxies) try: if requests.get('https://www.baidu.com/', proxies=proxies, timeout=2).status_code == 200: with open('./proxies.txt', 'a+',encoding='utf-8') as f: f.write(schema+"://"+url+"\n") except: pass
在 Scrapy 的 middlewares.py 中定义一个 ProxyMiddleWare 类
class ProxyMiddleWare(object): """docstring for ProxyMiddleWare""" def process_request(self, request, spider): '''对request对象加上proxy''' proxy = self.get_random_proxy() print("this is request ip:" + proxy) request.meta['proxy'] = proxy def process_response(self, request, response, spider): '''对返回的response处理''' # 如果返回的response状态不是200,重新生成当前request对象 if response.status != 200: proxy = self.get_random_proxy() print("this is response ip:" + proxy) # 对当前request加上代理 request.meta['proxy'] = proxy return request return response def get_random_proxy(self): '''随机从文件中读取proxy''' while 1: with open('./proxies.txt', 'r') as f: proxies = f.readlines() if proxies: break else: pass #time.sleep(1) proxy = random.choice(proxies).strip() return proxy
在 setting.py 的 Download Middware 参数中添加配置的类
DOWNLOADER_MIDDLEWARES = { 'crawlersec.middlewares.CrawlersecDownloaderMiddleware': 543, 'crawlersec.middlewares.ProxyMiddleWare': 540, }
0x1.3.3 Cookie
反爬策略:文章需要登录后才能访问
绕过方法:
1.手动登录获取 Cookie,将 Cookie 添加到爬虫脚本中
2.模拟登录
0x1.3.4 Header
反爬策略:网站的文章需要带特定的头部请求才能允许访问,如Referer等
绕过方法: 每次请求中添加需要的头部
例如:
headers={ "X-Requested-With":"XMLHttpRequest", "Referer": "https://www.kanxue.com/" } yield scrapy.FormRequest(url=url,formdata=data,headers=headers,callback=self.parse)
当数据爬取后,对数据建立倒排索引,方便我们快速搜索
0x2.1 倒排索引
倒排索引也称全文索引,检索程序对文章的每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
例如有两篇文章:
文章1内容:it is sunny today
文章2内容:today is rainy
1.首先取得关键字
文章1关键字:[it] [is] [sunny] [today]
文章2关键字:[today] [is] [rainy]
2.建立倒排索引
有了关键词后,就可以建立倒排索引了。上面的对应关系是:“文章号”对“文章中所有关键词”。倒排索引把这个关系倒过来,变成: “关键词”对“拥有该关键词的所有文章号”。
| 关键词 | 文章号 |
|---|---|
| it | 1 |
| is | 1,2 |
| sunny | 1 |
| today | 1,2 |
| rainy | 2 |
通常仅知道关键词在哪些文章中出现还不够,我们还需要知道关键词在文章中出现次数和出现的位置
| 关键词 | 文章号[出现频率] | 出现位置 |
|---|---|---|
| it | 1[1] | 1 |
| is | 1[1] | 2 |
| is | 2[1] | 2 |
| sunny | 1[1] | 3 |
| today | 1[1] | 4 |
| today | 2[1] | 1 |
| rainy | 2[1] | 3 |
实现时,将上面三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)、位置文件 (positions)保存。其中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息。
0x2.2 Elasticsearch
数据检索这里借助了 Elasticsearch。Elasticsearch的 Mapping 提供了对 Elasticsearch 中索引字段名及其数据类型的定义,还可以对某些字段添加特殊属性:该字段是否分词,是否存储,使用什么样的分词器等。
常用的数据类型(type)有:string、text、date等
Elaticsearch 的 mapping 样例如下,对文章链接、标题、作者、发布日期、正文内容、网站域名这六个字段指定检索方式
mappings = { "mappings": { "properties": { "url": { "type": "keyword" }, "title": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "author": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "date": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" }, "content": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "domain": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } }
对数据检索完后,就可以搜索,然而如果搜索结果有一千个,甚至成千上万个呢?哪个又是您最想要的文章?
打开 google ,搜索 "web安全",返回 518000000 条结果,好大的一个数字,在众多的搜索结果中,如何将最相关的放在最前面?

先简单了解一下数据搜索的过程:
1.搜索字符串分词
对输入的 “web安全”进行分词:web 、安全、安、全
2.搜索字符串和文档的相关性计算
首先,一个文档有很多词(Term)组成,如web、安全、安、全、等。
其次对于文档之间的关系,不同的 Term 重要性不同,比如对于本篇文档,“web、安全”就相对重要一些,“的、地、可”可能相对不重要一些。所以如果两篇文档都包含“web、安全”,这两篇文档的相关性好一些,然而就算一篇文档包含“的、地、可”,另一篇文档不包含“的、地、可”,也不能影响两篇文档的相关性。
因而判断文档之间的关系,首先找出哪些词(Term)对文档之间的关系最重要,如“web、安全”,然后判断这些词(Term)之间的关系。
找出词(Term)对文档的重要性的过程称为计算词的权重(Term weight)的过程。
计算词的权重(Term weight)有两个参数,第一个是词(Term),第二个是文档(Document)
判断词(Term)之间的关系从而得到文档相关性的过程应用一种叫做向量空间模型的算法(Vector Space Model)。
(1)计算权重
影响一个词(Term)在一篇文档中的重要性主要有两个因素:
- Term Frequency (tf):即此Term在此文档中出现了多少次。tf 越大说明越重要。
- Document Frequency (df):即有多少文档包含次Term。df 越大说明越不重要。
词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,如“web”这个词,在本文档中出现的次数很多,说明本文档主要就是讲这方面的事的。然而在一篇文档中,“的”出现的次数更多,就说明越重要吗?不是的,这是由第二个因素进行调整,第二个因素说明,有越多的文档包含此词(Term), 说明此词(Term)太普通,不足以区分这些文档,因而重要性越低。
权重计算公式如下:


(2)向量空间模型的算法(VSM)
我们把文档看作一系列词(Term),每一个词(Term)都有一个权重(Term weight),不同的词(Term)根据自己在文档中的权重来影响文档相关性的打分计算。
于是我们把所有此文档中词(term)的权重(term weight) 看作一个向量。
Document = {term1, term2, …… ,term N}
Document Vector = {weight1, weight2, …… ,weight N}
同样我们把查询语句看作一个简单的文档,也用向量来表示。
Query = {term1, term 2, …… , term N}
Query Vector = {weight1, weight2, …… , weight N}
我们把所有搜索出的文档向量及查询向量放到一个N维空间中,每个词(term)是一维。
如图:

我们认为两个向量之间的夹角越小,相关性越大。
所以我们计算夹角的余弦值作为相关性的打分,夹角越小,余弦值越大,打分越高,相关性越大。
相关性打分公式如下:
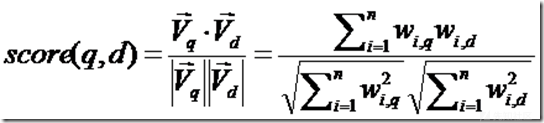
最终项目地址:http://secsea.cfyqy.com/ 。写得有点简洁,莫喷。
1.web界面
显示最近一周的实时文章和相关资讯

显示收录文章数量比较多的站点

2.搜索功能
提供了正文内容搜索、标题搜索、作者搜索、时间搜索、站点数据搜索功能。
默认使用的是正文内容搜索

只想要某个站点的数据,并显示最近一年的

参考文章:
倒排索引原理和实现: https://www.cnblogs.com/binyue/p/3380750.html
全文检索的基本原理:https://www.cnblogs.com/forfuture1978/archive/2009/12/14/1623594.html
如有侵权请联系:admin#unsafe.sh