
Reverse engineering tools tend to be developed against fundamental assumptions, for example, that binaries will more or less conform to the standard patterns generated by compilers; that instructions will not jump into other instructions; perhaps that symbols are available, etc. As any reverse engineer knows, your day can get worse if the assumptions are violated. Your tools may work worse than usual, or even stop working entirely. This blog post is about one such minor irritation, and the cheap workaround that I used to fix it.
In particular, the binary I was analyzing -- one function in particular -- made an uncommon use of an ordinary malware subterfuge technique, which wound up violating ordinary assumptions about the sizes of functions. In particular, malware authors quite often build data that they need -- strings, most commonly -- in a dynamic fashion, so as to obscure the data from analysts using tools such as "strings" or a hex editor. (Malware also commonly enciphers its strings somehow, though that is not the feature that I'll focus on in this entry.) As such, we see a lot of the following in the function in question.
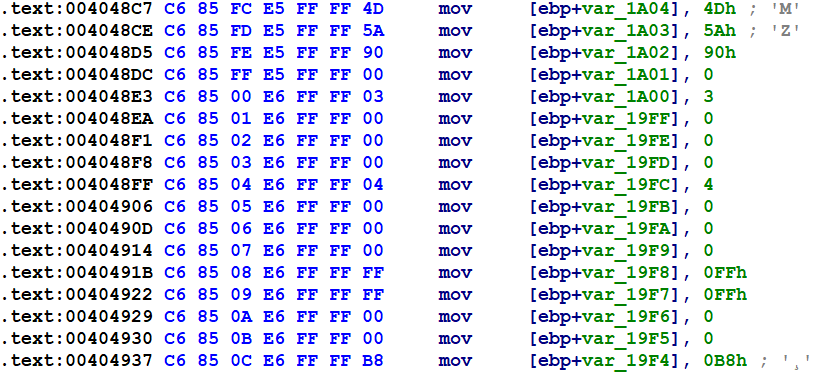
What made this binary's use of the technique unusual was the scale at which it was applied. Typically the technique is used to obscure strings, usually no more than a few tens of bytes apiece. This binary, on the other hand, used the technique to build two embedded executables, totaling about 16kb in data -- hence, there are about 16,000 writes like the one in the previous figure, each implemented by a 7-byte instruction. The function pictured above comprises about 118KB of code -- over 25% of the total size of the binary. The function would have been large even without this extra subterfuge, as it has about 7kb of compiled code apart from the instructions above.
The Hex-Rays decompilation for this function is about 32,500 lines. The bulk of this comes from two sources: first, the declaration of one stack local variable per written stack byte:

Second, one assignment statement per write to a stack variable:
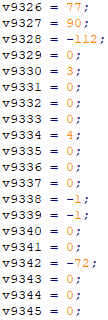
To IDA's credit, it handles this function just fine; there is no noticeable slowdown in using IDA to analyze this function. Hex-Rays, however, has a harder time with it. (I don't necessarily blame Hex-Rays for this; the function is 118KB, after all, and Hex-Rays has much more work to do than IDA does in dealing with it.) First, I had to alter the Hex-Rays decompiler options in order to even decompile the function at all:

After making this change, Hex-Rays was very slow in processing the function, maxing out one of my CPU cores for about five minutes every time I wound up decompiling it. This is suboptimal for several reasons:
I often use the File->Produce file->Create .c file... menu command more than once while reverse engineering a particular binary. This function turns every such command into a cigarette break.
Some plugins, such as Referee, are best used in conjunction with the command just mentioned.
When using the decompiler on this function in an interactive fashion (such as by renaming variables or adding comments), the UI becomes slow and unresponsive.
Randomly looking at the cross-references to or from a given function becomes a game of Russian Roulette instead of a normally snappy and breezy part of my reverse engineering processes. Decompile the wrong function and you end up having to wait for the decompiler to finish.
Thus, it was clear that it was worth 15 minutes of my time to solve this problem. Clearly, the slowdowns all resulted from the presence of these 16,000 write instructions. I decided to simply get rid of them, with the following high-level plan:
Extract the two .bin files written onto the stack by the corresponding 112KB of compiled code
Patch those .bin files into the database
Replace the 112KB worth of instructions with one patched call to memcpy()
Patch the function's code to branch over the 112KB worth of stack writes
The first thing I did was copy and paste the Hex-Rays decompilation of the stack writes into its own text file. After a few quick sanity checks to make sure all the writes took place in order, I used a few regular expression search-and-replace operations and a tiny bit of manual editing to clean the data up into a format that I could use in Python.

Next, a few more lines of Python to save the data as a binary file:

From there, I used IDA's Edit->Patch program->Assemble... command to write a small patch into the corresponding function:
After a bit of fiddling and manual hex-editing the results, my patch was installed:
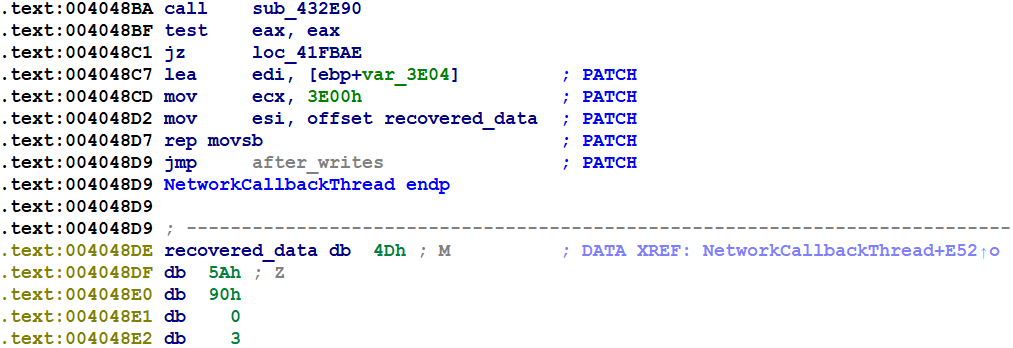
And then I used a two-line IDC script to load the binary files as data in the proper location:

Afterwards, the navigation bar showed that about 31% of the text section had been converted into data:

And now the problem is fixed. The function takes approximately two seconds to decompile, more in line with what we'd expect for a 7kb function. Hooray; no more endless waiting, all for the time cost of about three accidental decompilations of this function.
This example shows that, if you know your tools well enough to know what causes them problems, that sometimes you can work your way around them. Always stay curious, experiment, and don't simply settle for a suboptimal reverse engineering experience without exploring whether there might be an easier solution.