2018-02-01 17:20:49 Author: www.msreverseengineering.com(查看原文) 阅读量:57 收藏
This is part two of my three-part series on analyzing and de-virtualizing the FinSpy virtual machine. Part one was a tutorial focused on removing the obfuscation from the x86 implementation of the FinSpy VM to facilitate analysis. This part describes the actual analysis of the FinSpy VM, both the results of it as well as the process of analyzing it. The third part will provide tools to devirtualize FinSpy VM-protected programs.
The same GitHub repository as last time has been updated to contain:
- Commented disassembly for all parts of the FinSpy VM implementation, and some manual decompilation where applicable
- FinSpy VM bytecode disassembler program
- VM bytecode disassembly for this sample
- The compressed and decompressed VM bytecode program
- The referenced IDC and Python scripts
- The referenced notes
I endeavored to write a tutorial-style walkthrough for the entire process of analyzing the FinSpy VM, instead of the more traditional "results-oriented" presentations that are so common in the virtualization deobfuscation literature and security in general. In my opinion, I succeeded at this for the first part, and the third part is also amenable to that style of presentation. The second part, however, proved more difficult to write in that style. Ultimately, the non-linearity of static reverse engineering makes it difficult to present textually. Static reverse engineering involves working with incomplete information, and gradually refining it into complete information. This involves a lot of jumping around and writing notes that are cryptic at first, yet become clear after multiple passes of the same territory. Writing this into a textual document would most likely be incoherent and extremely lengthy (even moreso than currently).
I should have known better: when I teach static reverse engineering, I do so with long hands-on walkthroughs where I start at the beginning of some functionality, and describe in a step-by-step fashion what insights I obtain from the code, and how I translate that into annotations of the IDA database. In lieu of that, a video would probably be the second-best option. (Videos aren't interactive like classroom discussions, but at least they would show the process with mistakes and all.)
I've gone through a few drafts of this document trying to hybridize the standard results-oriented presentations of virtual machine deobfuscation with a hands-on style. After being dissatisfied with my drafts, I've settled on a compromise between the results-oriented and walk-through styles. Namely, I am including both. The first part of the document describes the conclusions I reached after analyzing the FinSpy VM. The second part shows the analysis as best as I can present it, including interstitial and externally-linked notes, assembly language snippets for every part of the VM, and decompilations of the assembly language.
I don't know if I've succeeded in writing something accessible. If you find this document too heady, I hope you will return for part three, which will be once again written like a standard tutorial. And since publishing part one, Filip Kafka has also published an analysis of the FinSpy VM, and two researchers from Microsoft also published an analysis of FinSpy. Hopefully between these sources, anyone interested in reverse engineering the FinSpy VM can follow along.
Virtual machine software protections are interpreters. Namely, a virtual machine software protection translates the original x86 code into its own proprietary bytecode language (a process called "virtualization"). At run-time, whenever the original pre-virtualized x86 code would have run, the virtual machine interpreter instead executes the bytecode into which the pre-virtualized x86 was translated. The benefit of this protection technique is that the analyst can no longer look directly at the original x86 instructions, with which they are presumably familiar. Instead, they must first analyze the interpreter, and then use the knowledge gained to understand the bytecode into which the x86 was translated. This process is usually considerably complicated through a number of anti-analysis techniques:
- Obfuscating the interpreter on the x86 level
- Obfuscating the virtualized program
- Using a different language for each sample, with the goal of requiring manual work for each
- Randomizing the map between opcode bytes and instructions
- Including polymorphic or metamorphic elements into the instructions
FinSpy VM is at the low end of the difficulty spectrum.
3.1 Virtual Machines as Interpreters
Since virtual machine software protections are interpreters, they have a lot in common with ordinary interpreters for more typical programming languages.
- Instruction encoding. Interpreters need their own standardized ways to represent instructions. For bytecode languages, this is a binary encoding of the instruction and its necessary associated data (such as the instruction's operands). In practice, interpreters usually define encoded instructions in terms of data structures or classes.
- VM context. Interpreters always have some state associated with them, also known as the "VM context structure". For example, interpreted programs might have access to registers specific to the language, and/or perhaps a stack or data area. (These are common examples; in practice, the state may contain only some of these elements, and/or other elements specific to the language.) The interpreter state is usually packaged up into a structure or object to allow multiple copies of the interpreter to exist throughout the program's execution (e.g., allowing multiple threads to run VM instances).
- Interpretation. The implementations for the interpreter's instructions, then:
- Take as input a pointer to the interpreter's context structure;
- Query the structure to obtain whatever information it needs to execute (e.g. if the instruction makes use of a value of a register, and the registers are held in the context structure, the instruction must retrieve the register's value from the context structure);
- Perform whatever action is specified by the instruction and its operands;
- Update the context structure with the results, for example, storing some value into a register, into the data section, or onto the context's stack.
Putting it all together, then, the skeleton of an interpreter generally looks like this:
void Interpret(VMContext *vmContext)
{
while(!vmContext->bShouldExit)
{
switch(vmContext->pCurrInsn->opcode)
{
// Instruction: add r0, r1, r2 [r0 <- r1+r2]
case VMOpcode_AddRegReg:
// Updates vmContext->pCurrInsn and vmContext->bShouldExit
VMAddRegReg(vmContext);
break;
// Instruction: add r0, r1, imm32 [r0 <- r1+imm32]
case VMOpcode_AddRegImm:
VMAddRegImm(vmContext);
break;
/* ... more instructions ... */
}
}
}An example instruction handler may look something like this:
void VMAddRegReg(VMContext *vmContext)
{
// Fetch register values
DWORD lhsVal = vmContext->regVals[vmContext->pCurrInsn->lhsReg];
DWORD rhsVal = vmContext->regVals[vmContext->pCurrInsn->rhsReg];
// Perform addition, update context
vmContext->regVals[vmContext->pCurrInsn->destReg] = lhsVal + rhsVal;
// Update VMEip to next instruction
vmContext->pCurrInsn += sizeof(VMInstruction);
// Don't signal VM exit
vmContext->bShouldExit = false;
}3.2 Virtualization Obfuscator Architecture Archetype
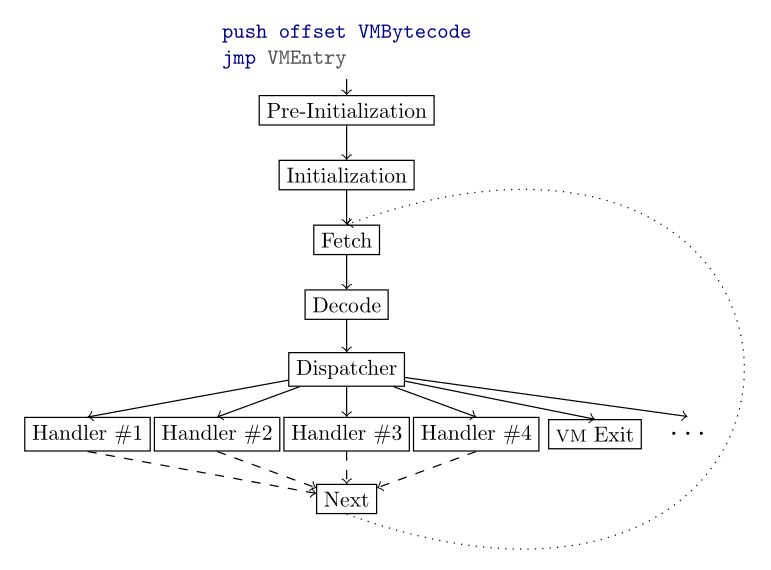
Virtual machines usually stick quite closely to the archtetype just described, though a few variants exist in practice. The following figure shows the basic model for virtual machine execution. Not all VMs follow this schema exactly. For example, some of them have a pre-initialization phase, and some don't; some of them use a "direct-threaded" architecture where each instruction transfers control to the next one, without having a centalized dispatcher invoking function pointers in a loop.
In brief, here are the roles of the phases illustrated in the diagram, and the considerations in analyzing them:
- Save CPU state. Every VM begins by saving the registers and flags before the VM executes. This usually involves pushing them onto the stack, but depending on architecture, may involve copying them to a fixed data area. Analyzing this phase most often provides little information.
- Pre-initialization. Before executing for the first time, the VM might have to allocate data structures (either globally and/or on a per-thread basis), or fix up pointers specified as relative virtual addresses (RVAs) by adding the process' image base address. This phase is usually guarded by a check against a static data item, such as a pointer to allocated memory that is initially set to NULL, or a boolean initialized to false, before pre-initialization has executed for the first time. After pre-initialization, the static pointer/boolean is set to a non-zero value. Analyzing this phase can provide insight into the data structures used by the VM, as well as where within the binary specific parts of the VM interpreter's code and data are located.
- Initialization. After pre-initialization, the VM must prepare its context structure to begin executing the VM instructions specified by the pointer-type value passed to the VM entrypoint. The details of this phase are highly dependent upon low-level implementation choices for the VM. Analyzing this phase usually provides insight into how the VM passes the registers and flags from the host CPU to the virtual CPU, and how the VM interpreter translates the VM bytecode pseudo-pointers into actual pointers to VM instructions (if applicable). It may also provide a wealth of insight into the VM context structure.
- Fetch. After preparing the context to execute, the VM must load the details of its first instruction. Analyzing this phase provides insight into how the instructions are stored, and how the VM locates them.
- Decode. After locating the first instruction, the VM might have to perform special processing to obtain real instructions. The most common example is when the instructions are stored in an encrypted format, and must be decrypted prior to execution. Other examples include modifications to constant operand values encoded within an instruction. The constants may be encrypted as just discussed, or there may be other mechanisms for transforming constants (e.g. converting RVAs into virtual addresses, converting "keys" into values, etc). Analyzing this phase provides crucial, yet usually incomplete, information into how instructions are decoded, which is necessary to understand before writing a disassembler for the VM bytecode.
- Dispatch. Finally, the VM must determine which bytecode operation is specified by the current instruction, and transfer control to x86 code responsible for performing the specified operation. This is most often accomplished by extracting a one-byte opcode from the instruction and using it as an index into a function pointer table. Analyzing this phase provides insight as to which part of the instruction specifies the operation, as well as illuminating how the VM translates that information into a pointer to code to execute (i.e., we learn where the function pointer table for the VM opcode implementations is held). More heavily-obfuscated VMs such as VMProtect may not store raw pointers in a table; those pointers may be encrypted somehow, and must be decrypted prior to dispatch.
- Instruction execution. Once the VM has transferred control to x86 code that implements a given VM instruction, that x86 code then must perform all necessary operations to query and update the state so as to affect the execution of the virtual instruction. Analyzing this phase is when the details finally all come together. Quite often we will observe modifications to the VM state throughout the initialization phase that we are unable to decipher because we don't know how the instructions will use and modify those parts of the VM state. Analyzing the instructions will comprehensively test and extend our understanding of the VM architecture. This is also the most crucial phase for understanding what functionality is actually offered by the VM -- without this information, we can't write a disassembler, as we won't know what any of the instructions actually do.
- VM continuation and/or exit. After an instruction has executed, it might be necessary to execute the next instruction sequentially within the VM bytecode stream. Or, it might be necessary to branch to another location within the VM due to a conditional or unconditional jump (which may be relatively addressed, or absolutely addressed). Or, if the VM implements function calls, we might have to save a return address (or something else that enables continuation of execution) somewhere before branching. Finally, all VMs have the ability to stop executing them and switch back to normal x86 execution. Analysis of this phases stresses understanding of the VM instruction pointer and addressing mode, as well as providing insight into how the VM communicates with x86 code outside of the VM. Re-entry after a VM exit is usually particularly interesting.
The FinSpy VM follows the archetype just presented fairly closely. The entire VM Context structure can be seen here.
- The FinSpy VM context structure contains only one dedicated register, used to virtualize 32-bit memory operands within certain x86 instructions.
- The FinSpy VM does not copy the x86 state -- the registers and flags at the time of VM entry -- into the VM context structure. Instead, it saves these onto the host x86 stack, saves the value of the ESP register into the context structure, and when it needs to use or modify a register, it indexes the saved ESP value to read or write the register value.
- The FinSpy VM has a stack area, and it points the host ESP value to this stack area upon entering the VM. I.e. any x86 instruction such as "push eax" executed as part of one of the VM instruction handlers will modify the stack data area within the VM, as opposed to the x86 stack as it exists outside the VM.
- The FinSpy VM also has a specialized stack that it uses for dynamic code generation. About 50% of the instructions in the VM bytecode program for this sample result in x86 machine code being generated on the fly and executed. This is unusual as far as virtualization obfuscators go, and will be discussed more subsequently.
4.1 Pre-Initialization and Initialization
The FinSpy VM is designed to allow multiple threads to utilize the VM at the same time. In fact, the FinSpy VM maintains a global array of pointers, one per thread ID, each one pointing to a VM Context structure for that particular thread. Upon entering the VM, FinSpy checks to see whether a VM Context structure has already been allocated for that thread. If not, it allocates a new one and initializes it.
Namely, if a thread did not already have a VM Context structure allocated within the global array, the pre-initialization phase allocates one, and the two initialization phases fill in values within the VM Context structure:
- Stores the module's image base into the VM Context structure.
- Initializes the x86 stack area-pointer to point to the last DWORD within the x86 stack area.
- Copies the host ESP value into the VM Context structure. Since the initialization phase pushes the flags and the registers onto the stack, VM instructions can access the values of saved registers and flags by indexing off of this saved ESP value.
- Sets the x86 ESP register to point to the current bottom of the VM x86 stack region.
- Initializes the dynamic code stack pointer to point to the beginning of that region. (The dynamic code stack grows upwards, unlike the x86 general stack, which grows downward.)
- Installs five function pointers within the context structure that the VM instructions use to transfer control to other VM instructions. Some of these function pointers just continue executing the next instruction; some of them implement conditional and unconditional jumps; and one of them is used to return after a VM function that was called has finished executing. The use of so many function pointers for VM continuation is another unusual feature of FinSpy.
- Checks to see whether the VM bytecode program stored in the binary is compressed, and if so, whether it has already been decompressed. If not, it decompresses the VM bytecode program and caches the results.
- Uses the DWORD pushed before entering the VM to locate the VM instruction within the decompressed VM bytecode program that should execute first, and stores the pointer to the instruction as the VM EIP.
4.2 VM Instruction Encoding
The VM bytecode program is stored as a blob at the end of the program's .text section. The blob may be compressed with the APLib compression library, in which case the instructions are decompressed during pre-initialization. The VM instruction structure has a fixed size: namely, 0x18 bytes. This makes it easy to calculate the subsequent VM instruction, in case the instruction does not involve a control flow transfer: just add 0x18 to the VM instruction pointer.
After decompression, the VM bytecode instructions are still encrypted. There is a fixed XOR key within the .text section, which can change on a per-sample basis. Upon executing an instruction, the FinSpy VM instruction fetch portion copies an 0x18-byte instruction from VM EIP into the VM Context structure, and then XORs each DWORD with the fixed key. (The first DWORD is skipped by this XOR process, as it contains the instruction's key.)
The first 8 bytes of each instruction type has the same layout, while the last 0x10 bytes contains the VM instruction operands, and the format differs depending upon which category the instruction falls into.
struct VMInstruction
{
DWORD Key;
BYTE Opcode;
BYTE DataLength;
BYTE RVAPosition1;
BYTE RVAPosition2;
BYTE Data[16];
};
The fields serve the following purposes:
- DWORD Key: Each instruction is associated with a 32-bit "key". The VM can look up instructions by key, as it does to locate the first instruction before the VM begins executing (the caller pushes a key on the stack before jumping to the VM entrypoint). The VM instruction set includes function calls, and function call targets can be specified by key.
- BYTE Opcode: This byte is in the range of 0x00 to 0x21, and specifies one of the 34 VM instruction opcode types.
- BYTE DataLength: Some instructions hold variable-length data in their operand region; this field describes the length of that data.
- BYTE RVAPosition1 and BYTE RVAPosition2: Some instructions specify locations within the x86 binary. Since the binary's base address may change when loaded as a module by the operating system, these locations may need to be recomputed to reflect the new base address. FinSpy VM side-steps this issue by specifying the locations within the binary as relative virtual addresses (RVAs), and then adding the base address to the RVA to obtain the actual virtual addresses within the executing module. If either of these bytes is not zero, the FinSpy VM treats it as an index into the instruction's data area at which 32-bit RVAs are stored, and fixes the RVA up by adding the base address to the RVA.
- BYTE Data[16]: The instruction's operands, if it has any, are stored here. Each instruction may interpret the contents of this array differently.
4.3 VM Instruction Set
The 34 instructions fall into three groups.
4.3.1 Group #1: Conditional and Unconditional Jumps.
FinSpy virtualizes all of the standard conditional jump instructions from X86, i.e. JZ, JNZ, JB, JO, JNP, etc. There are 17 of these VM opcodes in total, including the unconditional jump. These VM instructions are implementing by checking the respective conditions in the EFLAGS DWORD saved at the bottom of the host stack. I.e., ZF is stored in bit 0x40 within EFLAGS; the JZ VM instruction's implementation checks this bit within the saved EFLAGS, and either falls through to the next VM instruction if ZF is not set, or branches to a different instruction if it is set.
Technically, the implementations for the conditional branch instructions allow the branch target to be specified two different ways. The first is as a displacement off of VM EIP, in which case the next VM EIP is calculated by VMEIP + Displacement (with the displacement stored at &Data[1]). The second method, if the displacement at &Data[1] was 0, is to use the DWORD at &Data[5] as a raw X86 location specified as an RVA (i.e., something other than a VM instruction, causing a VM exit). However, in practice, no VM bytecode instructions within this sample used the latter method.
The VM's unconditional jump instruction is implemented in a slightly more obscure fashion involving dynamic code generation. It technically also allows the branch target to be specified as either a relative displacement against VM EIP or an x86 RVA, and in practice, only the former method was used.
4.3.2 Group #2: Operations on the Dedicated Register
As mentioned previously, the VM has one dedicated register, which we shall call "scratch". The second group of VM instructions involves this register. None of these instructions have unusual control flow; they all transfer control to the physically next instruction after the current VM EIP. Here are those instructions and their operands:
- mov scratch, 0
- mov scratch, imm32 [Operand: imm32 at &Data[0]]
- shl scratch, imm32 [Operand: imm32 at &Data[0]]
- add scratch, imm32 [Operand: imm32 at &Data[0]]
- mov scratch, savedReg32 [Operand: index of savedReg32 at &Data[0]]
- add scratch, savedReg32 [Operand: index of savedReg32 at &Data[0]]
- mov savedReg32, scratch [Operand: index of savedReg32 at &Data[0]]
- mov dword ptr [scratch], savedReg32 [Operand: index of savedReg32 at &Data[0]]
- mov scratch, dword ptr [scratch]
- mov dword ptr [scratch], imm32 [Operand: imm32 at &Data[0]]
- mov dword ptr [imm32], scratch [Operand: imm32 at &Data[0]]
- push scratch
As mentioned, the scratch register is used to virtualize 32-bit x86 memory operands. Here is an example (from the VM bytecode disassembly) of how the instruction "lea eax, dword ptr [ebp+eax*2+0FFFFFDE4h]" is translated into VM instructions:
0x035d78: MOV SCRATCH, 0 0x035d90: MOV SCRATCH, EAX ; scratch := EAX 0x035da8: SHL SCRATCH, 0x000001 ; scratch := EAX*2 0x035dc0: ADD SCRATCH, EBP ; scratch := EBP+EAX*2 0x035dd8: ADD SCRATCH, 0xfffffde4 ; scratch := EBP+EAX*2+0FFFFFDE4h 0x035df0: MOV EAX, SCRATCH ; EAX := EBP+EAX*2+0FFFFFDE4h
4.3.3 Group #3: X86-Related Instructions
Perhaps the only interesting feature of the FinSpy VM is how it handles non-virtualized x86 instructions. Every x86-virtualizing software protection needs a mechanism to execute non-virtualized instructions. Quite often this is implemented by exiting the VM, executing the non-virtualized x86 instruction stored somewhere in one of the program's executable sections, and then transferring control back into the VM. The FinSpy VM takes the approach of including instructions within its instruction set that contain raw machine code for X86 instructions, which are copied into RWX memory and executed on demand as the VM executes. This is somewhat more stealthy than the approach just described, since in that approach, the unencrypted x86 instructions must appear literally somewhere within the binary. For the FinSpy VM, since the VM instructions are encrypted, this allows the non-virtualized x86 instructions to remain encrypted most of the time.
There are four instructions in this group, although two of them are instruction-for-instruction identical to one another. Also, this is the only group of instructions to make use of the "pDynamicCodeStack" member of the VMContext structure. This point emphasizes how the VM context structure and VM instructions are intertwined and cannot be understood in isolation from one another.
Raw X86
The simplest of these instructions simply executes one non-control-flow x86 instruction. It generates the following sequence of code on the dynamic code stack, and then executes it:
9D popf 61 popa ?? ... ?? [raw X86 machine code copied from VM instruction's data at &Data[0]] 68 ?? ?? ?? ?? push offset fpVMReEntryStateInRegs C3 ret
I.e., this sequence restores the saved flags and registers, then executes a single x86 instruction copied out of the VM instruction's data area, and then re-enters the VM at the initialization sequence.
X86 Callout, Direct Address
This instruction is used to virtualize call instructions to fixed targets. I.e., "call sub_1234" will be implemented via this VM instruction, where "call eax" will not. It generates a sequence of code on the dynamic code generation stack, adds 0x30 to the dynamic code generation stack pointer, and then executes the code it generated:
9D popf 61 popa 68 ?? ?? ?? ?? push offset @RESUME 68 ?? ?? ?? ?? push (Data[4]+ImageBase) C3 ret @RESUME: 68 ?? ?? ?? ?? push offset NextVMInstruction 60 pusha 9C pushf 68 ?? ?? ?? ?? push offset VMContext 5B pop ebx 68 ?? ?? ?? ?? push offset fpVMReEntryReturn C3 ret
This sequence begins as before by restoring the saved flags and registers. Next, it pushes the address of some subsequently-generated code, which is used as the return address for the function. Next, it pushes an address within the .text section, fixed up from an RVA into a VA by adding the base address, and then returns. These three instructions together simulate a direct call instruction.
The location labeled @RESUME -- the return location for the called function -- begins by pushing the address of the following VM instruction. (This is computed by adding 0x18 -- sizeof(VMInstruction) -- to the current VM instruction pointer from within the VM Context structure). Next it saves the registers and the flags, sets EBX to the pointer to the VM Context structure for this thread, and then re-enters the VM at a special entrypoint. This special entrypoint sets VM EIP to the value just pushed on the stack before entering the ordinary initialization phase, and subtracts 0x30 from the dynamic code generation stack pointer.
Note that I have been referring to the "dynamic code generation stack", with emphasis on the "stack" aspect. The first X86-type VM instruction did not need to make use of the "stack" aspect, since it was only used to virtualize instructions without control flow. The VM instruction that we are currently discussing does need to utilize the stack features, because if a VM instruction executed by the called function made use of the dynamic code generation feature, and generated code at the same location as the code we've just generated, it would overwrite the sequence of code used for the function's return. Hence, after writing the dynamic code just discussed onto the dynamic code generation stack, it must also increase the stack so as to prevent these kinds of overwrites. In concert, the special VM re-entry location for returns must decrement the dynamic code generation stack pointer.
X86 Callout, Indirect Address
The final X86-related VM instruction is rather similar to the one we just discussed, except it is used to virtualize indirect call instructions, i.e., calls where the destination is not known at the time of virtualization. I.e., an instruction like "call eax" would be virtualized by this VM instruction. It generates the following code on the dynamic code generation stack, increments the dynamic code generation stack pointer, and executes it:
9D popf 61 popa 68 ?? ?? ?? ?? push offset @RESUME ?? ... ?? [raw X86 machine code copied from VM instruction's data at &Data[4]] @RESUME: 68 ?? ?? ?? ?? push offset NextVMInstruction 60 pusha 9C pushf 68 ?? ?? ?? ?? push offset VMContext 5B pop ebx 68 ?? ?? ?? ?? push offset fpVMReEntryReturn C3 ret
The generated code is nearly identical to the one from the previous instruction, and so not much commentary is needed. The only difference lies in what happens after pushing the return address for the call. The previous VM instruction type pushed an address in the .text section onto the stack, and returned to it; this VM instruction, in contrast, executes a raw x86 instruction copied out of the VM bytecode instruction's data region.
Now we have everything we need to write a disassembler for this sample. We know what each VM instruction does, and how each encodes its operands -- and this information is not necessarily specific to this particular sample; it can potentially be used across many samples.
There are a number of elements that might easily vary between samples; we know them for this particular sample, at least.
- We have obtained the raw contents of the VM bytecode program for this sample.
- We know the XOR key used to decrypt the instructions.
- We know which opcode corresponds to which VM instruction for this sample.
Since I only had one sample to work with, I chose to hard-code all of these elements in my disassembler. I.e., for any other samples, you will need to determine the three pieces of information just described. This is how I generally approach deobfuscation projects: I start with one sample and write code to break it. Then, I obtain another sample, and determine what needs to change to adapt my previous code to the new sample. If this reveals any sample-specific information, then I need to devise a procedure for extracting the information from a given sample. I repeat this process until my tool can break any sample from the given family.
5.1 Disassembler Architecture
I decided to write my FinSpy VM disassembler in Python, since I figured I might need to make use of my x86 library (the most maintained version of which is also written in Python). You can find the FinSpy VM disassembler here. At several points along the way I wished I'd chosen OCaml, since OCaml is very well-suited to writing programs that manipulate other programs, and has strong type-checking to prevent common errors. In fact I even originally wrote functions to output the disassembled instructions as OCaml datatypes, but I abandoned this idea after I contemplated interoperating between Python and OCaml.
First, I wrote a function to read VM instructions, i.e. 0x18-byte chunks, from the user-specified VM bytecode program binary, and to XOR them with the sample-specific XOR value.
Next, I designed a class hierarchy to represent VM instructions. Since each instruction has a fixed-length encoding of 0x18 bytes, and the first 8 bytes are treated the same by each, it made sense to make a GenericInsn class to handle the common functionality. That class implements a function called Init which takes the decrypted byte array and the position of the instruction within the file, and decodes the common elements in the first 8 bytes.
From there, I derived a few other abstract classes from GenericInsn, to handle families of instructions whose operands were encoded identically. Those classes contain common functions invoked by the constructor to decode the instruction operands, as well as some common functions to assist in printing. These classes are:
- ConditionalBranch, for the 17 branching instructions
- StackDisp32, for some of the dedicated register instructions
- StackDisp8, for other dedicated register instructions
- Imm32, for other dedicated register instructions
Finally, I derived classes for each of the VM instruction types from the classes just mentioned. Those classes invoke the decoding routines from their base classes in their constructors, and provide support for printing the instructions as strings. Not much is noteworthy about printing the instructions, except that when the dedicated register instructions reference x86 registers by numeric index, I emit the name of the register instead of the index. Also for instruction types with embedded x86 machine code, I invoke my disassembler library to print the machine code as human-readable x86 assembly language.
The last piece was to devise a mechanism for creating the correct Python object for a given decrypted instruction encoded as an 0x18-byte array. For this, I created a dictionary mapping the opcode byte to an enumeration element specifying which VM instruction it represented. Then, I created a dictionary mapping those enumeration elements to lambda functions that constructed the correct object type.
Finally I combined the Python object-creation mechanism just described with the raw instruction reading mechanism from the beginning, resulting in a generator that yielded Python instructions. From there, disassembling the program is simply a matter of printing the instruction objects:
for x in insn_objects_from_file("Tmp/dec.bin"):
print xYou can see the complete disassembly for this sample's VM bytecode program here.
Here is a link to the assembly language for the pre-initialization phase, as well as a rough decompilation of that code. We will reproduce snippets of code from the decompilation in explaining how it operates. Feel free to open up the binary and follow along at the instructions shown in the first link showing the assembly language.
6.1 Saving the Host Registers and Flags
The first thing that any VM does upon entry is to save the contents of the registers and the flags. FinSpy VM is no different:
.text:00401BF6 push eax ; PUSHFD sequence, in order .text:00401D5C push ecx .text:004019D2 push edx .text:004020A4 push ebx .text:00401CEC push ebx ; EBX in place of ESP .text:00401DA7 push ebp .text:00401F41 push esi .text:00401EFF push edi .text:00401E9D pushf
6.2 A Word on Position-Independent Code (PIC)
Like many obfuscated programs (and some non-obfuscated ones), the x86 implementation of the FinSpy VM uses position-independent code (PIC). PIC is employed in non-obfuscated contexts to reduce the number of pointers within the program that require relocation should the imagebase change. PIC is employed in obfuscated contexts for the same reason, as well as to obscure which addresses are actually being accessed by a particular memory operation. The next two instructions establish EBP as a PIC base:
.text:00401F60 call $+5 ; Establish position-independent code (PIC) base .text:00401F65 pop ebp ; EBP = 00401F65
Any subsequent memory reference involving EBP (before EBP is subsequently modified) will be computed relative to the address shown. For example:
.text:004020D7 mov eax, [ebp+0D75h] ; == [401F65h+0D75h] == [402CDAh] .text:00402CDA dd 0C4CDh ; <- this is the referenced address and its contents
6.3 Allocating the Global Per-Thread VM Context Structure Array
The FinSpy VM is architected in such a way where multiple threads can execute VM code at the same time. As a result, each thread must have its own VM context structure, and not much of the VM state can be held in global data items. FinSpy handles this by allocating a global array that holds pointers to each thread's VM context structure, where each pointer is initially NULL.
The first thing the pre-initialization function does is to check a global pointer to see whether we have already allocated the thread-specific array, and if not, allocate it. The following code snippets from the decompilation illustrate:
DWORD * gp_VMContext_Thread_Array = NULL;
DWORD **gpp_VMContext_Thread_Array = &gp_VMContext_Thread_Array;
DWORD *GetVMContextThreadArray()
{
return *gpp_VMContext_Thread_Array;
}
void SetVMContextThreadArray(DWORD *pNew)
{
*gpp_VMContext_Thread_Array = pNew;
}
void VMPreInitialize(DWORD encodedVMEip)
{
if(GetVMContextThreadArray() == NULL)
SetVMContextThreadArray(Allocate(0x100000));6.4 Allocating Thread-Specific VM Context Structures
After the previous step, FinSpy knows the global array of VM Context structure pointers has been allocated, so it queries whether a VM Context structure has been allocated for the thread in which it is currently executing. It uses the current thread ID, shifted right by 2 to mask off the low 2 bits, as an index into the array. If not already allocated, it must then allocate a context structure for the current thread.
DWORD GetThreadIdx()
{
// If we're executing in user-mode...
if(g_Mode != X86_KERNELMODE)
return GetCurrentThreadId() >> 2;
// Kernel-mode code has not been decompiled here: it relies upon an RVA
// that has been set to 0 in my sample, so can't be analyzed
}
// ... Continuing inside of void VMPreInitialize(DWORD encodedVMEip) ...
DWORD *dwGlobal = GetVMContextThreadArray();
DWORD dwThreadIdx = GetThreadIdx();
VMContext *thContext = dwGlobal[dwThreadIdx];
if(thContext == NULL)
{
thContext = Allocate(0x10000);
dwGlobal[dwThreadIdx] = thContext;6.5 Pre-Initializing Thread-Specific VM Context Structures
If the VM Context structure for the current thread was not already allocated in the previous step, FinSpy performs some preliminary initialization of the VM context structure. This is the first point in the code that we begin to understand the layout of the VM Context structure, whose full layout is shown here.
// Base address for currently-running executable thContext->dwBaseAddress = g_BaseAddress; // Last DWORD in VM Context structure thContext->dwEnd = (DWORD)thContext + 0xFFFC; // Initialize pointer to data section thContext->pData = &thContext->Data[1];
While analyzing this and subsequent code, the assembly language contained many structure references such as the following:
.text:00401B19 mov ecx, [ebp+0D79h] ; ecx = .text:00402CDE BASE_ADDRESS dd 400000h .text:00401FA9 mov [ebx+28h], ecx ; <- structure reference: field_28 .text:00401A2F mov eax, ebx .text:00401BCC add eax, 0FFFCh .text:00401AAD mov [ebx+4], eax ; <- structure reference: field_4 .text:00401EC2 lea eax, [ebx+50h] ; <- structure reference: field_50 .text:00401C56 add eax, 4 .text:00401998 mov [ebx+50h], eax ; <- structure reference: field_50
I knew that I would later need to know where and how these structure fields had been initialized, so I opened up a new window in my text editor and took notes on each structure field access. Later I turned those notes into an actual structure in IDA. The full notes can be found here. Here were there notes I took for the fields referenced in the assembly snippet above:
- field_4: 00401AAD: pointer to last DWORD in this structure (0xFFFC offset)
- field_28: 00401FA9: dwBaseAddress
- field_50: 00401998: initialized to address of field_54
6.6 Results of Analyzing the Decompression Code
FinSpy keeps its VM instructions in a large array of VMInstruction structures. This array may be compressed, in which case, the first time the next phase of pre-initialization executes, the instructions will be decompressed. Subsequent thread-specific pre-initializations of VM Context structures need not decompress the instructions after they have been decompressed for the first time.
// If dwInstructionsDecompressedSize was 0, then the instructions aren't
// compressed, so just copy the raw pointer to the instructions to the
// pointer to the decompressed instructions
if(dwInstructionsDecompressedSize == 0)
*dwInstructionsDecompressed = *dwInstructionsCompressed;
// If the decompressed size is not zero, this signifies that the
// instructions are compressed. Allocate that much memory, decompress the
// instruction data there, and then cache the decompression result
else
{
// If we've already decompressed the instructions, don't do it again
if(*dwInstructionsDecompressed == NULL)
{
// Allocate RWX memory for the obfuscated, encrypted APLib decompression
// code
void *pDecompressionStub = Allocate(dwDecompressionStubSize);
memcpy(pDecompressionStub, dwDecompressionStubSize, &x86DecompressionStub);
// Decrypt the decompression code (which is still obfuscated)
XorDecrypt(pDecompressionStub, dwDecompressionStubSize, dwXorKey);
// Allocate memory for decompressed instructions; decompress
VMInstructions *pDecInsns = Allocate(dwInstructionsDecompressedSize);
fpDecompress Decompress = (fpDecompress)pDecompressionStub;
Decompress(*dwInstructionsCompressed, pDecInsns);
// Update global pointer to hold decompressed instructions
*dwInstructionsDecompressed = pDecInsns;
}
}
// Store the pointer to decompressed instructions in the context structure
thContext->pInstructions = *dwInstructionsDecompressed;
// Locate the first instruction by encoded VM EIP
thContext->pCurrInsn = FindInstructionByKey(thContext, encodedVMEip);6.7 Process of Analyzing the Decompression Code
This section describes how the results in the previous section were obtained. After the previous phases of pre-initialization, I observed FinSpy decrypting some obfuscated code stored within its .text section, and then executing it. Seeing it for the first time, I didn't know what the decrypted code did; it turned out to be responsible responsible for decompressing the VM bytecode program. Here's how I figured that out.
For extra stealth, the decompression code is itself encrypted via XOR, and is also obfuscated using the same conditional jump-pair technique seen in the previous entry. When analyzing this part of pre-initialization for the first time, I first noticed it allocating a small amount of RWX memory, copying data from the .text section, and decrypting it:
.text:004020D7 mov eax, [ebp+0D75h] ; eax = .text:00402CDA dd 0C4CDh .text:00401E1A add eax, [ebp+0D79h] ; eax = 0C4CDh + .text:00402CDE BASE_ADDRESS dd 400000h ; i.e. eax contains 0x40C4CD, an address in .text .text:00401A1F push eax ; eax = 0x40C4CD .text:00401CDE push ecx ; ecx = .text:00402CD6 dd 60798h .text:00401E8A mov eax, [ebp+0D6Dh] ; eax = .text:00402CD2 dd 67Dh .text:00401B94 push eax .text:00401B95 call ALLOCATE_MEMORY ; Allocate 0x67D bytes of RWX memory .text:00401B9A mov edi, eax .text:00401C18 push edi ; Save address of allocated memory .text:00401D45 mov esi, [ebp+0D61h] ; esi = .text:00402CC6 dd offset dword_40BE50 .text:00401CA5 cld ; Clear direction flag for rep movsb below .text:00401FF9 mov ecx, [ebp+0D6Dh] ; .text:00402CD2 dd 67Dh .text:00401E54 push ecx .text:00402064 rep movsb ; Copy 0x67D bytes from dword_40BE50 to allocated RWX memory .text:00401E41 pop ecx ; Restore ecx = 60798h .text:00401A86 pop edi ; Restore edi = address of allocated region .text:00401C2C mov eax, [ebp+0D7Dh] ; .text:00402CE2 XOR_VALUE dd 2AAD591Dh .text:00401D7C push eax ; eax = value to XOR against allocated memory .text:00401D7D push ecx ; ecx = size of allocated region .text:00401D7E push edi ; edi = beginning of allocated region .text:00401D7F call loc_40250B ; XOR_DWORD_ARRAY: XOR DWORDs starting at edi+4, to edi+(ecx>>2)
Seeing the code being decrypted, I wrote a small IDC script that replicated the action of the function at loc_40250B, a/k/a XOR_DWORD_ARRAY. It can be found here and is reproduced here for ease of presentation.
static DecryptXOR(encAddr, encLen, xorVal)
{
auto encNum;
auto cursor;
auto i;
// Skip first DWORD
cursor = encAddr + 4;
encNum = (encLen - 4) >> 2;
for(i = 0; i < encNum; i = i + 1)
{
PatchDword(cursor,Dword(cursor)^xorVal);
cursor = cursor + 4;
}
}And then I invoked it to decrypt the region of code being referenced in the snippet above: DecryptXor(0x40BE50, 0x67D, 0x2AAD591D).
Continuing to follow the assembly code where the last snippet left off, we see:
.text:00401CB9 pop ecx ; Restore ecx = .text:00402CD6 dd 60798h .text:00402046 pop eax ; Restore eax = 0x40C4CD .text:00401F79 mov esi, eax ; esi = 0x40C4CD .text:00401FBE push ecx ; Allocate 60798h bytes of memory .text:00401FBF call ALLOCATE_MEMORY .text:00401FC4 mov edx, edi ; edx = 0x67D-byte region of RWX memory, decrypted previously .text:00401AD6 mov edi, eax ; edi = 60798h bytes of memory just allocated .text:00401A4C push edi ; Second argument = edi (60798h-byte region) .text:00401A4D push esi ; First argument = 0x40C4CD .text:00401A4E call edx ; Execute decrypted code in smaller region
Now I knew the decrypted region contained code copied from 0x40C4CD, so I began to analyze it. It was obfuscated with the same conditional jump-pairs as we saw in part one. As somebody who has been reverse engineering malware for 15 years, though is somewhat rusty due to different focuses lately, I immediately experienced a sense of deja vu. I knew I'd seen the following function a million times before:
.text:0040C320 add dl, dl .text:0040C1E6 jnz short @@RETURN .text:0040BF24 mov dl, [esi] .text:0040C01F inc esi .text:0040C100 adc dl, dl @@RETURN: .text:0040BFE8 retn
Specifically, the "adc dl, dl" instruction jumped out at me. Were I more regularly engaged in malware analysis, I would have immediately recognized this as part of the APLib decompression code. Instead, I wound up searching Google with queries like 'x86 decompression "adc dl, dl"'. Eventually my queries led me to other malware analysis write-ups which identified APLib as the culprit decompression library.
Once I recognized that the code I'd decrypted probably implemented APLib, I decided to try to unpack it and see what happened. If I'd gotten gibberish as a result, I may have needed to dive deeper into the code to see whether it had implemented any custom modifications. Such is a bane of static reverse engineering -- had I been dynamically analyzing this code, I could have merely dumped it out of memory.
I began by using an IDC one-liner to dump the compressed blob out of memory: savefile(fopen("e:\\work\\Malware\\blah.bin", "wb"), 0, 0x40C4CD, 0x60798); If you want the compressed blob, you can find it here.
Now that I knew I had an APLib-compressed blob, I needed to decrypt it. First I went to the APLib website and downloaded the APLib package. Next I simply tried to invoke the stand-alone decompression tool on my blob, but it failed with a non-descriptive error message. I began reading the source code and tracing the decompression tool in a debugger, and realized that the failure arose from APLib expecting a header before the encrypted blob. Fair enough. I set about re-creating a header for my data, but failing to do so within 20 minutes and becoming impatient, I started looking for another way.
I came across the open-source Kabopan project which purported to offer "a python library of various encryption and compression algorithms, cleanly re-implemented from scratch." After a few minutes reading the examples, I wrote a small script which did the trick:
from kbp.comp.aplib import decompress
with open("compressed.bin", "rb") as g:
dec,decSize = decompress(g.read()).do()
print decSize
with open("decompressed.bin", "wb") as f:
f.write(dec)Kabopan didn't complain, and my script printed the expected decompressed size, so for all I knew, it had worked. The decompressed result can be found here. I loaded the decompressed binary into IDA, not knowing what to expect. The data had some regularly-recurring patterns in it, but its format was still unknown to me at this point. I would later analyze it more fully.
This section resumes immediately after the pre-initialization phase from the last section. The assembly language for the initialization phase is shown here; feel free to follow along. For clarity of exposition, most of the following shall use the decompilation, shown in full here. To summarize the last section, FinSpy VM's pre-initialization phase is clearly denoted by two attempts to access previously-allocated structures. If the structures aren't present, it performs the allocation and pre-initialization phases as described in the previous section. If they are present, it skips those phases and branches directly to the initialization phase, mocked up in pseudocode as such:
//
// From pre-initialization phase, shown previously
//
// Try to get the global VM Context * array
if(GetVMContextThreadArray() == NULL)
SetVMContextThreadArray(Allocate(0x100000));
// Once allocated, retrieve the global pointer
DWORD *dwGlobal = GetVMContextThreadArray();
// Try to get the per-thread VMContext *
DWORD dwThreadIdx = GetThreadIdx();
VMContext *thContext = dwGlobal[dwThreadIdx];
if(thContext == NULL)
{
// We detailed this phase in the previous section:
// Allocate and pre-initialize the VMContext * if not present
}
//
// Beginning of initialization phase
//
// Once allocated, retrieve the thread-specific pointer
DWORD *dwGlobal = GetVMContextThreadArray();
DWORD dwThreadIdx = GetThreadIdx();
VMContext *thContext = dwGlobal[dwThreadIdx];
// ... execution resumes here after both pointers are allocated ...7.1 Initializing VM Function Pointers
Most of the initialization phase computes the value of function pointers using a position-independent code idiom. Subsequent analysis clarified the purpose of these function pointers, which were somewhat difficult to understand in isolation. They will be explained in a subsequent section, in a more natural context (section 9).
Like the the pre-initialization code, this section contains many structure references. I continued to update my document describing what I knew about each structure reference. Again, those notes can be found here.
vm_initialize: thContext->pPICBase = (void *)0x00402131; // Points to the vm_initialize label above thContext->fpFastReEntry = (fpReEntryNoState)0x0040247C; thContext->fpLookupInstruction = &FindInstructionByKey; if(g_Mode != X86_KERNELMODE) thContext->fpEnterFunctionPointer = (fpReEntryHasState)0x00402B92; else thContext->fpEnterFunctionPointer = (fpReEntryHasState)0x00402BC6; thContext->fpExecuteVMInstruction = (fpReEnterToInstruction)0x00402C39; thContext->fpRelativeJump = (fpReEntryHasState)0x00402B74; thContext->fpNext = (fpReEntryHasState)0x00402B68;
One thing I did notice quickly was that the "fpFastReEntry" function pointer pointed to the VM initialization code. Recalling the diagram from section 3.2 showing generic VM organization, note that VM instructions need to locate the instruction fetch/decode code within the VM entrypoint. I guessed that the code at that location might serve that purpose; that was mostly correct (actually some initialization is performed before instruction fetch, namely the initialization shown in the pseudocode above).
7.2 Host <=> VM State Transfer
After installing the function pointers as per the previous section, the VM then saved the host's ESP into the VM context structure, twice, and then set the host's ESP to a point near the end of the VM context structure. Hence it was clear that the VM state included a stack, physically located at the end of the context structure.
thContext->pSavedEsp1 = ESP; thContext->pSavedEsp2 = ESP; ESP = thContext->pDataEnd;
At this point in the analysis, I was still hazy about many of the VM Context structure entries, though fortunately the notes I'd taken allowed me to efficiently piece things together. The subsequent code dealt with loading instructions from the decompressed memory region, optionally transforming them, and then transferring control to the relevant x86 code responsible for implementing them.
8.1 FinSpy VM Instruction Fetch
The pseudocode decompilation for the instruction fetch phase can be found here, and the commented assembly listing can be found here.
After initializing the context structure, the FinSpy VM then makes use of some fields we've already analyzed. Thanks to the ongoing notes I'd taken, it was easy to understand what was happening. Recall these two statements from the pre-initialization phase when decompressing the instructions:
thContext->pInstructions = *dwInstructionsDecompressed; thContext->pCurrInsn = FindInstructionByKey(thContext, encodedVMEip);
I.e. the pCurrInsn member of the VM Context structure already contains a pointer somewhere within the pInstructions data blob. Returning to the present, the next part of the FinSpy VM entrypoint makes use of these fields:
VMInstruction *Fetch(VMContext *thContext)
{
memcpy(&thContext->Instruction,thContext->pCurrInsn, sizeof(VMInstruction));
XorDecrypt(&thContext->Instruction, sizeof(VMInstruction), dwXorKey);
return &thContext->Instruction;
}From here we learn the size of each entry in the Instruction structure member -- namely, 0x18 -- and we also see that the instructions are decrypted using the same function we saw previously to decrypt the decompression code. We will return to talk more about these points in Section 8.4.
Note again the following line from pre-initialization:
thContext->pCurrInsn = FindInstructionByKey(thContext, encodedVMEip);
To refresh your memory from part one, each VM entrypoint pushed a value onto the stack before transferring control to the VM entrypoint. An example is reproduced from part one:
.text:004065A4 push 5A403Dh ; <- encodedVMEip .text:004065A9 push ecx ; .text:004065AA sub ecx, ecx ; .text:004065AC pop ecx ; .text:004065AD jz loc_401950 ; VM entrypoint
This "encodedVMEip" parameter is used to look up the first VM instruction that should be executed beginning at that VM entrypoint. Namely, the FindInstructionByKey function takes the encodedVMEip parameter, iterates through the decompressed instructions, and tries to find one whose first DWORD matches that value:
VMInstruction *FindInstructionByKey(VMContext *vmc, DWORD Key)
{
VMInstruction *insns = vmc->pInstructions;
while(insns->Key != Key)
insns++;
return insns;
}So we have learned that:
- Each VM instruction is associated with a key.
- The key is the first element in the VM instruction structure.
- The VM may look up instructions by their keys.
8.2 FinSpy VM Instruction Decode
The pseudocode decompilation for the instruction decode phase can be found here, and the commented assembly listing can be found here.
After copying an instruction out of the global instructions array and decrypting it, the VM entrypoint then calls a function that will optionally fix-up DWORDs within the instructions by adding the current module's imagebase to them. This functionality allows the instructions to reference addresses within the module's image without having to care where the module is loaded. This functionality effectively performs the same job as the operating system's loader.
void Decode(VMContext *thContext)
{
VMInstruction *ins = &thContext->Instruction;
if(ins->Fixup1)
*(DWORD *)&ins->Data[ins->Fixup1 & 0x7F] += thContext->dwImageBase;
if(ins->Fixup2)
*(DWORD *)&ins->Data[ins->Fixup2 & 0x7F] += thContext->dwImageBase;
}8.3 FinSpy VM Instruction Dispatch
The pseudocode decompilation for the instruction dispatch phase can be found here, and the commented assembly listing can be found here.
Finally, after the instructions have been decrypted and optionally fixed up, the VM then transfers control to the x86 code that implements the instruction. In decompilation:
// Locate the handler table in the .text section fpInstruction *handlers = (fpInstruction *)vmc->pPICBase + 0x9AF; // Invoke the relevant function in the handler table handlers[i->Opcode](vmc);
In x86:
.text:00402311 movzx ecx, byte ptr [ebx+3Ch] ; Fetch the opcode byte .text:0040248D mov eax, [ebx+24h] ; Grab the PIC base .text:004023FC add eax, 9AFh ; Locate the VM handler table .text:0040218C jmp dword ptr [eax+ecx*4] ; Transfer control to the opcode handler
8.4 A Cursory Look at the VM Bytecode
In this chapter on instruction fetch / decode / dispatch, we learned that the instructions are 0x18-bytes apiece, and that each instruction is encrypted via a DWORD-level XOR. Since I'd previously decompressed the instruction blob, I could now decrypt it and take a look. I used the same script I had previously written during my analysis of the pre-initialization decompression code, linked again for convenience. I just wrote a script to call that function in a loop, and executed it within the IDB for the decompressed blob:
auto i; for(i = 0; i < 0x00060797; i = i + 0x18) DecryptXOR(i, 0x18, 0x2AAD591D);
After running that script, the data format was still mostly unknown. The data was mostly zeroes, but clearly very structured. Since I have written an x86 disassembler before, some of the non-zero data jumped out at me as looking plausibly like x86 machine code. I turned a few of them into code and IDA confirmed:
seg000:00000078 dd 5A1461h seg000:0000007C db 1Bh ; VM opcode: 0x1B seg000:0000007D db 6 ; x86 instruction length seg000:0000007E db 0 ; fixup1 location seg000:0000007F db 0 ; fixup2 location seg000:00000080 ; --------------------------------------------------------------------------- seg000:00000080 mov dword ptr [eax], 1D7h seg000:00000080 ; --------------------------------------------------------------------------- seg000:00000086 db 0Ah dup(0) seg000:00000090 dd 5A1468h seg000:00000094 db 1Bh ; VM opcode: 0x1B seg000:00000095 db 5 ; x86 instruction length seg000:00000096 db 1 ; fixup1 location seg000:00000097 db 0 ; fixup2 location seg000:00000098 ; --------------------------------------------------------------------------- seg000:00000098 mov eax, offset unk_1F000 seg000:00000098 ; --------------------------------------------------------------------------- seg000:0000009D db 0Bh dup(0) seg000:000000A8 dd 5A146Ch seg000:000000AC db 1Bh ; VM opcode: 0x1B seg000:000000AD db 1 ; x86 instruction length seg000:000000AE db 0 ; fixup1 location seg000:000000AF db 0 ; fixup2 location seg000:000000B0 ; --------------------------------------------------------------------------- seg000:000000B0 leave seg000:000000B0 ; --------------------------------------------------------------------------- seg000:000000B1 db 0Fh dup(0) seg000:000000C0 dd 5A146Dh seg000:000000C4 db 1Bh ; VM opcode: 0x1B seg000:000000C5 db 3 ; x86 instruction length seg000:000000C6 db 0 ; fixup1 location seg000:000000C7 db 0 ; fixup2 location seg000:000000C8 ; --------------------------------------------------------------------------- seg000:000000C8 retn 4 seg000:000000C8 ; --------------------------------------------------------------------------- seg000:000000CB db 0Dh dup(0)
This was curious to say the least. Why were there single, isolated x86 instructions contained in data blobs? Does the VM really contain raw x86 instructions? Though not all of the instructions are like this, it turns out that, yes, indeed, about half of the VM instructions contain literal x86 machine code within them. I figured that if I could convert the remaining non-raw-x86 VM instructions into x86, it would probably be easy to revert the entire VM bytecode program back into x86.
Anyway, talk about recovering the x86 program is premature at the moment. Now that we have decrypted the VM bytecode program, it will be easier for us to reverse engineer the VM instruction set. If we are ever confused about how an x86 instruction handler for a VM opcode is using parts of the VM instruction structure, we can simply look up real examples of those instructions for clarification without having to guess.
Before we discuss the VM instruction set, let's return to the five function pointers found within the VM context structure pertaining to VM exit and re-entry. All of these disassembly listings can be found here, though they are reproduced herein.
9.1 Re-Enter VM, State in Registers
The first function pointer for returning to the VM, called fpFastReEntry in the VM Context structure, simply contains the address of the initialization phase within the VM entrypoint. It assumes that the registers and flags contain meaningful values, and that they have not already been placed on the stack.
9.2 Re-Enter VM, State on Stack
The next return sequence assumes that EAX contains the address of the function pointer from the previous section, and that the flags and registers are saved on the stack. It simply pops the flags and registers off the stack, and transfers control to the function pointer in EAX.
.text:00402BB2 mov [esp-4], eax ; Save VM initialization location from EAX onto stack .text:00402BAB popf ; Restore flags .text:00402BBD popa ; Restore registers .text:00402B9C jmp dword ptr [esp-28h] ; Branch to VM initialization location
9.3 Branch Taken, State on Stack
This return sequence is used by the VM's conditional and unconditional branch instructions when the branch should be taken. It has the capability to add a displacement to VM EIP -- very similar to how processors like x86 implement relative branches. It also has the capability to branch to an x86 location specified as an RVA, but this code was never used in the sample that I inspected.
.text:00402B74 VM__RelativeJump__Execute: .text:00402B74 mov eax, [ecx+1] ; Instruction data at DWORD +1 contains .text:00402B74 ; a displacement for the VM EIP .text:00402B77 test eax, eax ; Was it non-zero? .text:00402B79 jz short jump_to_x86 ; No -- branch to x86 code at [ecx+5] .text:00402B7B add [ebx+VMContext.pCurrInsn], eax ; Add the displacement to VM EIP .text:00402B7D mov eax, [ebx+VMContext.fpVMEntry] ; eax := state-in-registers VM entry .text:00402B80 mov esp, [ebx+VMContext.SavedESP1] ; esp := restore host ESP .text:00402B83 jmp [ebx+VMContext.fpVMReEntryToFuncPtr] ; branch to state-on-stack re-entry .text:00402B86 ; --------------------------------------------------------------------------- .text:00402B86 .text:00402B86 jump_to_x86: ; CODE XREF: ... .text:00402B86 mov eax, [ecx+5] ; Otherwise, use [ecx+5] as x86 RVA .text:00402B89 add eax, [ebx+VMContext.dwBaseAddress] ; Convert RVA to VA .text:00402B8C mov esp, [ebx+VMContext.SavedESP1] ; esp := restore host ESP .text:00402B8F jmp [ebx+VMContext.fpVMReEntryToFuncPtr] ; branch to state-on-stack re-entry
9.4 Branch Not Taken, State on Stack
This return sequence is used by the VM's conditional and unconditional branch instructions when the branch is not taken. It simply adds 0x18, the size of a VM instruction, to the current VM instruction pointer, and re-enters the VM via the "state on stack" handler.
.text:00402B68 VM__NextInsn__Execute: .text:00402B68 add [ebx+VMContext.pCurrInsn], size VMInstruction ; Point VM EIP to next instruction .text:00402B6B mov eax, [ebx+VMContext.fpVMEntry] ; EAX := ordinary VM re-entry location .text:00402B6E mov esp, [ebx+VMContext.SavedESP1] ; Restore host ESP .text:00402B71 jmp [ebx+VMContext.fpVMReEntryToFuncPtr] ; branch to state-on-stack re-entry
9.5 Function Return, State on Stack
Finally, this VM re-entry function pointer is invoked by dynamically-generated code after a function call returns. The code must pop the last frame off of the dynamically-generated code stack, and update the VMContext->pCurrInsn entry to the VM instruction after the one that issued the function call. Since the VM instruction pointer is saved on the stack above the registers and flags, this code shifts the registers and flags up by one DWORD, and adds 4 to the stack pointer. Finally, it re-enters the VM using the state-on-stack function pointer.
.text:00402C6F mov eax, [esp+24h] ; Get saved VMInstruction * from stack .text:00402CB0 lea esi, [esp+20h] ; esi = address of registers begin .text:00402C4E lea edi, [esp+24h] ; edi = address of VMInstruction * .text:00402C40 mov ecx, 9 .text:00402C66 std ; Move saved registers/flags up by .text:00402C93 rep movsd ; one DWORD, erasing the VMInstruction * .text:00402CAA cld .text:00402C79 add esp, 4 ; Adjust stack to remove superfluous DWORD .text:00402C8B mov [ebx+VMContext.pCurrInsn], eax ; Set next instruction .text:00402C58 sub [ebx+VMContext.pScratch], 30h ; Pop function stack .text:00402C83 mov eax, [ebx+VMContext.fpVMEntry] ; Get VM entry pointer .text:00402C9F jmp [ebx+VMContext.fpVMReEntryToFuncPtr] ; Use state-on-stack return
The VM instruction set, 34 opcodes in total, can be divided neatly into three groups.
- Conditional and unconditional jumps
- Operations involving the dedicated register
- X86-related instructions
10.1 Group #1: Conditional and Unconditional Jumps
Annotated disassembly listings for these instructions can be found here.
The conditional jump instructions are all fairly simple, and nearly identical to one another. Note and recall that at the time the VM entrypoint transfers control to any instruction, the host stack contains the saved flags at the bottom, and the saved registers immediately above that. The conditional jump instructions all load the saved flags off of the bottom of the host stack, and then test the desired combination of bits by using the "test" instruction to isolate individual bits from the saved EFLAGS register. To make my job easier, I created an enumeration in IDA to give names to the symbolic constants:
FFFFFFFF ; enum X86Flags, mappedto_291 FFFFFFFF X86Flags_CF = 1 FFFFFFFF X86Flags_PF = 4 FFFFFFFF X86Flags_AF = 10h FFFFFFFF X86Flags_ZF = 40h FFFFFFFF X86Flags_SF = 80h FFFFFFFF X86Flags_OF = 800h
Now we can easily apply this enumeration to the disassembly listing to tell which bits are being tested. Here is the x86 code for the VM "JL" instruction:
.text:00403007 lea ecx, [ebx+VMContext.CurrentInsn.InsnData] .text:00402FD2 mov eax, [ebx+VMContext.SavedESP1] .text:00402FE8 mov eax, [eax] ; Grab saved flags from the host stack .text:0040302D test eax, X86Flags_OF ; 800h .text:00402FFA setnz dl .text:0040303C test eax, X86Flags_SF ; 80h .text:0040304C setnz al .text:00403014 cmp al, dl .text:00403021 jnz short loc_402FDD ; JNZ path .text:00402FDD jmp [ebx+VMContext.fpVMRelativeJump] ; JZ path .text:00402FC9 jmp [ebx+VMContext.fpVMNext]
This sequence tests the overflow flag (OF) and sign flag (SF) within EFLAGS, and performs a relative jump if they are different from one another. (That's the "JNZ path" in the code above.) If they are the same, execution is instead transferred to the physically next VM instruction (the "JZ path" above) -- exactly the same way that a real conditional jump works on a real x86 processor.
You might not have the condition codes for the various conditional jumps memorized. I.e. you might be confused, when encountering the code above, about which x86 conditional jump instruction corresponds to the situation where the branch is taken when OF!=SF. I usually forget them, too; I reference the code from my X86-to-IR translator when I need a reminder. Here's a table so you don't have to look them up.
Branch | Condition JS SF JNS !SF JO OF JNO !OF JZ ZF JNZ !ZF JP PF JNP !PF JB CF JAE !CF JA !CF && !ZF JBE CF || ZF JL SF != OF JGE SF == OF JG SF == OF && !ZF JLE SF != OF || ZF
The unconditional jump instruction uses some trickery involving dynamically-generated x86 code. It seems suitable to delay that instruction until we discuss dynamic code generating-VM instructions in Section 10.3.
10.2 Group #2: "Dedicated Register" Instructions
Annotated disassembly listings for these instructions can be found here.
Analyzing the "dedicated register" instructions confused me at first. As you can see in the code snippet below, each of these contains a memory reference that looks like "[ecx+eax*4+4]", where ECX points to the saved ESP before VM entry, and EAX is computed as 7-Data[0].
.text:00403982 lea ecx, [ebx+VMContext.CurrentInsn.InsnData] ; point ECX to the data region .text:004039B0 movzx ecx, byte ptr [ecx] ; get the first byte .text:00403995 mov eax, 7 .text:0040396C sub eax, ecx ; EAX := 7-data[0] .text:00403947 mov ecx, [ebx+VMContext.SavedESP1] ; ECX := host ESP .text:0040395E mov eax, [ecx+eax*4+4] ; Grab saved register .text:00403951 mov [ebx+VMContext.dwScratch], eax ; Store loaded register into SCRATCH .text:00403978 add [ebx+VMContext.pCurrInsn], size VMInstruction .text:004039B8 mov eax, [ebx+VMContext.fpVMEntry] .text:004039A2 mov esp, [ebx+VMContext.SavedESP1] .text:0040398D jmp [ebx+VMContext.fpVMReEntryToFuncPtr]
I eventually realized that the host stack contains the saved flags followed by the saved registers. Thus, the "+4" part of the memory operand indexes past the saved flags. Then, the value of EAX in "eax*4" is used to select one of the saved registers. If the byte in Data[0] was 0, then this instruction would select the 7th element in the saved register array -- i.e. the first register pushed, which was EAX. If Data[0] was 1, then this instruction would select the 6th saved register -- i.e. the second register pushed, which was ECX.
Since I've written a disassembler before, I realized the connection between Data[0] and the register chosen. x86 machine code assigns a number to its 32-bit registers in the following order: EAX, ECX, EDX, EBX, ESP, EBP, ESI, EDI. Thus, Data[0] selects a register in that order. Therefore, it is a simple matter to figure out which register is accessed by one of these instructions -- just keep an array with the register names in that order.
I was also worred about what happens when Data[0] was not in the range of [0,7]. Negative numbers could result in indexing below the host stack, and numbers 8 or above would result in indexing above the saved registers. I wasn't sure how I would represent and devirtualize these possibilities. I coded limited support for these situations in my disassembler, figuring I would deal with the problem if it ever materialized. Fortunately, it didn't.
10.3 Group #3: X86-Related Instructions
Annotated disassembly listings for these instructions can be found here.
The high-level summary already described the purpose of these instructions: to execute x86 instructions whose machine code are provided within the relevant VM instructions' data regions. The only real difficulty in analyzing them was making sense of which instructions they were writing to the dynamic code region. As you can see in the snippet below, the values written are obfuscated in the disassembly listing:
.text:004040F1 mov edi, [ebx+VMContext.pScratch] .text:004040BF mov eax, [ebx+VMContext.SavedESP1] .text:004040DD and eax, 2Fh .text:00404110 add edi, eax .text:0040412E push edi .text:00404119 mov word ptr [edi], 6ACh ; <- Write 0x6AC .text:0040408F xor word ptr [edi], 6731h ; <- XOR with 0x6731 .text:00404139 add edi, 2 .text:004040B1 lea esi, [ebx+VMContext.CurrentInsn.InsnData] .text:00404086 movzx ecx, byte ptr [ebx+VMContext.CurrentInsn.DataLength] .text:004040A2 rep movsb .text:0040414F mov byte ptr [edi], 0E9h ; <- Write 0xE9 .text:00404165 xor byte ptr [edi], 81h ; <- XOR with 0x81 .text:0040405E mov eax, [ebx+VMContext.fpVMEntry] .text:004040CA mov [edi+1], eax .text:00404068 mov byte ptr [edi+5], 6Ch ; <- Write 0x6C .text:004040D3 xor byte ptr [edi+5], 0AFh ; <- XOR with 0xAF .text:004040E5 add dword ptr [ebx+VMContext.pCurrInsn], size VMInstruction .text:0040415B pop eax .text:004040FD mov esp, [ebx+VMContext.SavedESP1] .text:00404071 jmp eax
For example, these two lines:
.text:00404119 mov word ptr [edi], 6ACh ; <- Write 0x6AC .text:0040408F xor word ptr [edi], 6731h ; <- XOR with 0x6731
Write 0x06AC, and then XOR that value with 0x6731. Fortunately it's easy enough to use IDA's calculator feature (press '?' in the disassembly listing) to perform these computations. I.e., that snippet writes 0x619D, or in bytes, 9D 61. From here you can look the bytes up in the Intel processor opcode maps, or if you're lazy, find some alignment bytes in the binary, use IDA's Edit->Patch Program->Change Bytes.. feature, write the bytes, and then turn them into code to have IDA automatically disassemble them for you.
10.3.1 Unconditional Jumps
The unconditional branch instruction also makes use of dynamically-generated code, despite not needing to do so. Specifically, it writes the following bytes to the VM stack area: E9 02 F8 B0 F9 B8 [0x004033C9] FF E0, where the value in brackets is a sample-specific value that refers to an address in the .text section that contains code.
If you were to disassemble the sequence of x86 machine code just given, you would find that the first five bytes are an x86 long relative unconditional jump. Then you would stop and scratch your head, since if you write a relative jump with a fixed displacement to an unpredictable address (as the FinSpy VM stack base address is dynamically allocated, thus can change across runs, and is hence unpredictable), the result is also an unpredictable address. Surely, then, this instruction must crash? My original disassembly for this instruction was "CRASH", until I saw how frequently it occurred in the listing of the disassembled program, which forced me to take a closer look.
.text:00403398 lea ecx, [ebx+VMContext.CurrentInsn.InsnData] ; ECX := &Instruction->Data[0] .text:004033D1 mov edi, [ebx+VMContext.pScratch] ; EDI := dynamic code generation stack .text:00403237 mov eax, [ebx+VMContext.SavedESP1] ; EAX := host ESP .text:00403219 and eax, 2Fh .text:00403350 lea edi, [eax+edi-4AEDE7CFh] ; Stupid obfuscation on the value of EDI .text:00403244 mov dword ptr [edi+4AEDE7CFh], 0B0F802E9h ; [EDI] := E9 02 F8 B0 .text:00403266 mov word ptr [edi+4AEDE7D3h], 0B8F9h ; [EDI+4] := F9 B8 .text:00403382 call $+5 .text:00403387 pop eax .text:00403253 lea eax, [eax+42h] ; 0x004033C9 .text:00403305 mov [edi+4AEDE7D5h], eax ; [EDI+6] := 0x004033C9 .text:00403229 mov word ptr [edi+4AEDE7D9h], 0E0FFh ; [EDI+10] := FF E0 .text:004032A1 mov al, [ecx] ; al = first byte of instruction data .text:004032CA mov [edi+4AEDE7CFh], al ; [EDI] := al, overwriting E9 .text:00403412 mov eax, [ebx+VMContext.SavedESP1] ; EAX := host ESP .text:004033B6 lea edi, [edi+4AEDE7CFh] ; EDI := beginning of code we just wrote .text:0040332F push dword ptr [eax] ; Push saved flags .text:004032E2 popf ; Restore flags .text:0040331E jmp edi ; Jump to the code we just generated
Upon closer inspection, the value of the first byte -- previously described as E9 -- is overwritten on line 004032CA with the first byte from the VMInstruction's data array. So I found an instance of this instruction within the decompressed VM bytecode -- opcode 0x06 in the sample -- and looked at the value of the first byte within the instruction's data, which was 0xEB. (In fact, every VM instruction with an opcode of 0x06 had 0xEB as its first data byte.) Then, substituting EB in place of E9, we end up with a more sensible disassembly listing:
.text:0041EFBC EB 02 jmp short loc_41EFC0 .text:0041EFBC .text:0041EFBC ; -------------------------------- .text:0041EFBE F8 db 0F8h ; ° .text:0041EFBF B0 db 0B0h ; ¦ .text:0041EFC0 ; -------------------------------- .text:0041EFC0 .text:0041EFC0 loc_41EFC0: .text:0041EFC0 F9 stc ; Set carry flag .text:0041EFC1 B8 C9 33 40 00 mov eax, offset loc_4033C9 .text:0041EFC6 FF E0 jmp eax
Now we can analyze the code at the location referenced in the snippet above, namely loc_4033C9:
.text:00403371 jb short loc_4032FD ; JB will be taken, since carry flag was set previously ; JB path ; The code here is identical to the VM conditional branch taken re-entry sequence ; JNB path ; No real point in analyzing this, as the JB will always be taken .text:0040327C add [ebx+VMContext.pCurrInsn], size VMInstruction .text:00403426 mov eax, [ebx+VMContext.fpVMEntry] .text:004033E6 mov esp, [ebx+VMContext.SavedESP1] .text:00403345 jmp [ebx+VMContext.fpVMReEntryToFuncPtr]
如有侵权请联系:admin#unsafe.sh